
Dear friends,
Thinking about the future of machine learning programming frameworks, I recently reread computer scientist Fred Brooks’ classic essay, “No Silver Bullet: Essence and Accidents of Software Engineering.” Three decades after its initial publication, it still holds important lessons for software engineers building ML tools.
Despite progress from typewriters to text editors, why is writing still hard to do? Because text editors don’t address the most difficult part: thinking through what you want to say.
Programming tools have the same limitation. I’m glad to be coding in Python rather than Fortran. But as Brooks points out, most advances in programming tools have not reduced the essential complexity of software engineering. This complexity lies in designing a program and specifying how it should solve a given problem, rather than in expressing that design in a programming language.

Deep learning is revolutionary because it reduces the essential complexity of building, say, a computer vision system. Instead of writing esoteric, multi-step software pipelines comprising feature extractors, geometric transformations, and so on, we get data and train a neural network. Deep learning hasn’t just made it easier to express a given design; it has completely changed what we design.
As we work on ML programming frameworks, we should think about how to further reduce the essential complexity of building ML systems. This involves not just specifying an NN architecture (which is indeed waaay easier to do in TensorFlow or PyTorch than C++), but also deciding what is the problem to be solved and designing all the steps from data acquisition to model training to deployment.
I don’t know what will be the key ideas for reducing this essential complexity, but I suspect they will include software reuse, ML model reuse (such as libraries of pretrained models) and tools not just for code versioning and reuse (like github) but also for data versioning and reuse. Breakthroughs in unsupervised and other forms of learning could also play a huge role.
Even as I occasionally struggle to get an ML system to work (it’s not easy for me either), I am excited to see how our community is pioneering this discipline.
Keep learning!
Andrew
P.S. My best learning creation so far, seven month-old Nova, just said her first words! 🙂
News
Quantum Leap
A leaked paper from Google’s quantum computing lab claims “supremacy” over conventional computers.
What’s new: The U.S. space agency NASA, whose scientists are collaborating with Google on a quantum computer, accidentally published a paper describing the breakthrough. The Financial Times snagged a copy before it was taken down, naming machine learning, chemistry, and materials science as likely uses for the technology. Google declined to comment pending the paper’s official release.
How it works: Google designed the special-purpose system, called Sycamore, to determine whether sets of randomly generated numbers were truly random. Researchers estimate that it would have taken the world’s fastest conventional supercomputer, IBM’s Summit, 10,000 years to solve the problem. Sycamore solved it in 3 minutes and 20 seconds, an early demonstration of the capability known as quantum supremacy.
- Instead of bits, quantum computers process information using qubits that can hold the values 1 and 0 simultaneously.
- Qubits can be entangled with one another to represent the totality of all the states of a system’s qubits.
- For example, two qubits can represent 11, 10, 01, and 00 at once. Three qubits can represent 111, 110, 100, 000, 001, 011, 101 simultaneously, and so on. Sycamore has 53 qubits.
- A major challenge is keeping quantum processors cold enough to prevent ambient heat from disturbing the fragile qubits.
Behind the news: Physicist Paul Benioff wrote a paper in 1980 describing how quantum-mechanical phenomena like superposition and entanglement could be applied to computing. Google, IBM, Intel, and Microsoft lately have made substantial progress in implementing those ideas.
Why it matters: Quantum computing’s promise of exponentially faster processing in particular applications has many in the AI community excited to apply it to tasks like search and pattern matching. There’s no telling when quantum AI will emerge, but when it does, it probably will require new types of models tailored to the peculiar nature of qubits.
We’re thinking: The problem Sycamore solved doesn’t have much practical value, as computer scientist Scott Aaronson points out in his excellent quantum-supremacy FAQ. It’s more “like the Wright Brothers’ flight” circa 1903, he says: The technology works, but it will be a while before actual users can climb aboard.

Anonymous Faces
A number of countries restrict commercial use of personal data without consent unless they’re fully anonymized. A new paper proposes a way to anonymize images of faces, purportedly without degrading their usefulness in applications that rely on face recognition.
What’s new: Researchers from the Norwegian University of Science and Technology introduced DeepPrivacy, a system that anonymizes images of people by synthesizing replacement faces. They also offer the Flickr Diverse Faces dataset, 1.47 million images of faces with supplemental metadata, which they used to train DeepPrivacy.
Key insight: The original images are never exposed to the face generator. Authors Håkon Hukkelås, Rudolf Mester, and Frank Lindseth argue that this strategy preserves privacy more effectively than traditional anonymization techniques like pixelizing and blurring.
How it works: DeepPrivacy is a conditional generative adversarial network that synthesizes novel images similar to previously observed ones. A discriminator classifies images as real or generated, while a generator based on the U-Net architecture is optimized to create images that fool the generator.
- Single Shot Scale Invariant Face Detector detects faces in images.
- For each face, Mask R-CNN locates keypoints for eyes, nose, ears, and shoulders.
- Then the faces are replaced with random values.
- The generator architecture receives keypoints, which define the deleted face’s orientation, and the corresponding faceless images. From these inputs, it learns to create replacement faces that the discriminator can’t distinguish from real-world images in the training data.
Results: The researchers processed the WIDER-Face dataset (roughly 32,000 images containing around 394,000 faces) using DeepPrivacy as well as traditional anonymization methods. Subjected to traditional techniques, Dual Shot Face Detector retained 96.7 percent of its usual performance. With DeepPrivacy, it retained 99.3 percent. The researchers don’t provide metrics to evaluate the relative degree of anonymity imparted by the various methods.
Why it matters: Laws like the European Union’s General Data Protection Regulation set a high bar for data-driven applications by placing tight limits on how personal data can be used. DeepPrivacy transforms photos of people into a less identifiable format that still contains faces recognizable to neural networks.
Yes, but: DeepPrivacy addresses the privacy implications of faces only. An image purged of faces but still containing, say, clothing with identifiable markings, such as an athlete’s number, would allow a sophisticated model to infer the wearer’s identity.
We’re thinking: Machine learning’s reliance on data is both a gift and a curse. Aggregation of data has allowed for great progress in the field. Yet privacy advocates are inclined to keep personal data under wraps. DeepPrivacy is an intriguing step toward a compromise that could satisfy both AI engineers and users alike.
Nothing but (Neural) Net
Basketball coaches often sketch plays on a whiteboard to help players get the ball through the net. A new AI model predicts how opponents would respond to these tactics.
What’s new: A team of researchers in Taiwan trained a conditional generative adversarial network on data from National Basketball Association games. They trained their network to show how players on the opposing team likely would move in response to human-drafted plays.
How it works: The researchers built a two-dimensional simulation of a half court complete with a three-point line and a net. A coach can draw motion paths for five players represented by dots, as well as ball movements including passes and shots. No dunking, however.
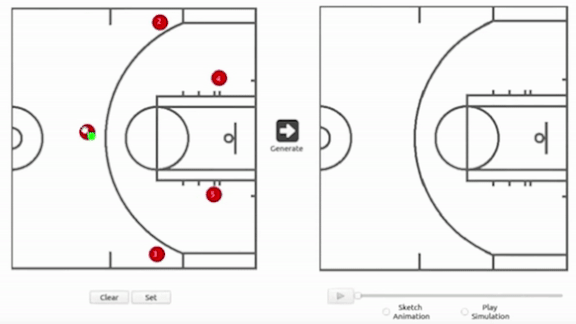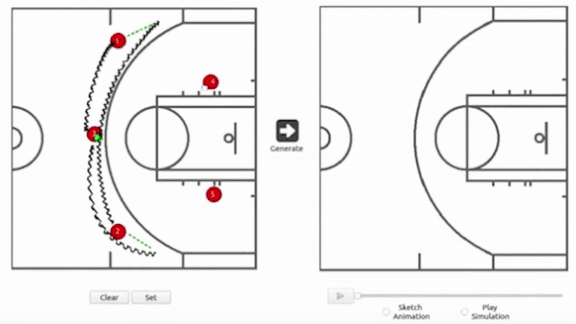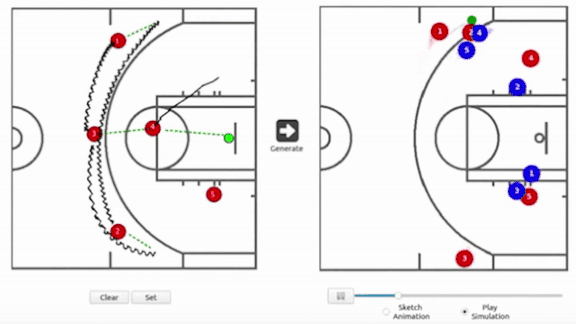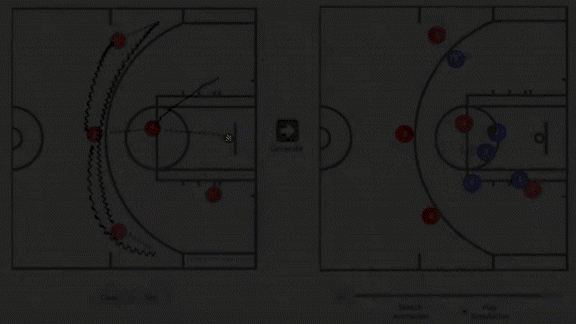
- Once a coach has drawn a play, a generator determines how the five defensive players would react.
- A discriminator evaluates these movements to make sure they match realistic gameplay.
- The model then displays the coach’s play and the defensive maneuvers.
Results: A cohort of NBA pros, basketball fans, and basketball non-fans evaluated the generated defenses for realism. While the non-pro fans and non-fans had a hard time spotting the computer’s defensive plays, the NBA pros could tell they were not designed by a human coach.
Behind the news: Stat SportVU has collected real time player motion data for the NBA since 2011. The system uses six cameras to collect each player’s position and track who has possession of the ball, 25 times per second. It uses machine learning to identify events like dribbles and passes, and play types like drives, isolations, and screens.
Why it matters: Pro sports is a high-stakes industry that has embraced technology to optimize performance. It’s conceivable that a neural network someday might generate AlphaGo-like winning tactics that no human had envisioned.
We’re thinking: This model isn’t a slam-dunk, given that the pros weren’t fooled. However, it appears to be sophisticated enough to help teach beginners how to think strategically off the court.
A MESSAGE FROM DEEPLEARNING.AI

Don’t know how to play an instrument but love to code? Improvise your own jazz solo using LSTMs in Course 5 of the Deep Learning Specialization! Enroll now
Amazon Prepares for a Crackdown
Amazon is writing what it hopes will become U.S. law governing use of face recognition technology.
What happened: At a press event announcing new features for Amazon’s Alexa smart-home service, Jeff Bezos told a reporter that his company’s lawyers are drafting a statutory framework to guide what he views as an inevitable federal crackdown on face recognition. Amazon sells the cloud-based face recognition service Rekognition, whose use by law enforcement agencies has raised alarm among civil liberties advocates.
What it says: The company has released no details about the model legislation in progress. However, in February, Amazon VP of Global Public Policy Michael Punke published a blog that could provide clues to the company’s aims.
- Face recognition should be used in accordance with existing laws, Punke writes in the post proposing ethical guidelines for the technology. He points out that the U.S. Constitution’s Fourth Amendment and Civil Rights Act of 1964 explicitly outline an individual’s right to privacy and freedom from discrimination.
- Law enforcement groups, government agencies, and businesses using face recognition should be held to high standards of transparency, the post says.
- Law enforcement should be allowed to use the technology only to narrow down groups of suspects, and only when a model is at least 99 percent confident in its prediction. Models should never be used as the final arbiter of a person’s guilt or innocence.
Behind the news: Face recognition’s rapid proliferation has spawned a widespread backlash in the U.S. cities. San Francisco and Oakland, California, and Somerville, Massachusetts, have banned the technology. California’s legislature is considering a statewide ban. Several bills restricting its use are wending their way through Congress, and two representatives have vowed to propose further legislation.
We’re thinking: Punke’s guidelines are sound, and Amazon is well situated to understand how the technology could be abused. When industries propose their own regulations, though, legislators need to take special care to make sure any resulting laws benefit society as a whole.
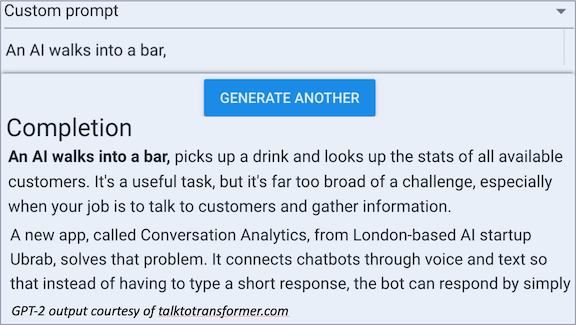
Putting Text Generators on a Leash
Despite dramatic recent progress, natural language generation remains an iffy proposition. Even users of the muscular GPT-2 text generator have to press the button a number of times to get sensible output. But researchers are figuring out how to exert greater control over generated text.
What’s new: Pre-trained text generators generally require fine-tuning for a specific sort of output. A team at Salesforce developed a model aptly named CTRL that lets users determine the output genre, from news story to horror script, without further training.
Key insight: The model is guided by control codes, human-written text tags that describe a desired output genre — including, yes, jokes. The model learns relationships between a given code and the intended style and content.
How it works: CTRL, like the state-of-the-art language model BERT, is a modified transformer network trained in an unsupervised fashion on large-scale text corpora. Its training data include Wikipedia, Reddit, and Project Gutenberg’s library of digitized books.
- CTRL predicts the next word in a sequence based on learned relationships among words.
- During training, each input sequence comes with a control code. For example, material drawn from a contract would be coded Legal.
- During generation, one of these codes directs the model to produce text similar to the associated subset of the training data.
Results: The researchers provide qualitative results demonstrating that control codes generate different styles of text in response to the same prompt. For example, given the prompt “the knife,” the Reviews code produces “a knife is a tool and this one does the job well,” while the Horror code yields “a knife handle pulled through the open hole in the front.” The paper offers no quantitative evaluation.
Why it matters: The ideal text generator would produce diverse, relevant passages appropriate to a wide variety of uses. CTRL suggests that a single model with unsupervised training could meet this requirement.
We’re thinking: Many people including GPT-2’s creators worry that more-capable text generators invite misuse. Could a CTRL-style approach reduce abuse by suppressing certain genres (say, blatant political disinformation) as well as supporting more effective text generation?
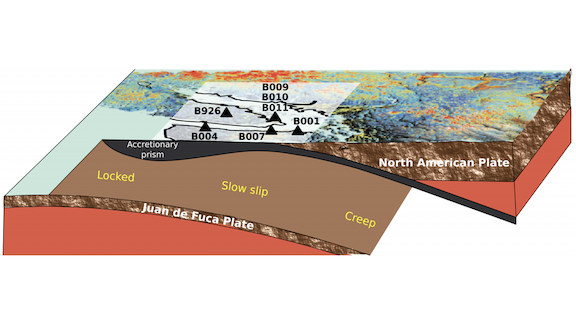
Prelude to a Quake?
Geologists call them slow slips: deep, low-frequency earthquakes that can last a month but have little effect on the surface. A model trained to predict such events could help with forecasting potentially catastrophic quakes.
What’s new: French and American seismologists trained a model to recognize acoustic patterns associated with slow slips where one tectonic plate slides beneath another. Some seismologists believe that slow slips shift stress from deep in a geological fault up to the Earth’s brittle crust, presaging potentially catastrophic quakes.
How it works: The authors began by simulating slow slips in the lab using two sheets of synthetic material, like acrylic plastic, separated by a thin layer of a granular, sandy medium. The video above is a microscopic view of the sheets in action.
- The researchers recorded the acoustic signals emitted by the sheets and granular layer as they compressed. Then they divided the recording into short segments and fed them into a random forest model.
- The model found that the signal’s gradual variance from mean — rather than big, sudden jumps just before a slip — was the best predictor that the sheets were about to experience a laboratory version of a slow slip.
- Having ingested seismic data from the tectonic plate that runs from Canada to California between 2007 and 2013, the model predicted four of the five slow slips that occurred between 2013 and 2018.
We’re thinking: Seismologists already provide short-term risk assessments for a given location and time span. This research could lead to long-term forecasts, months or years out, allowing planners to expedite earthquake safety upgrades that otherwise may be delayed due to their cost.