
Dear friends,
This special issue of The Batch celebrates the launch of our new Generative Adversarial Networks Specialization!
GANs are among the most exciting technologies to emerge from deep learning. These networks learn in a very different way than typical supervised methods for learning x-to-y mappings. By pitting a discriminator network and a generator network against one another (details below), they produce photorealistic images, medical training data, children’s book illustrations, and other types of output.
Earlier today, we held an online panel discussion on “GANs for Good” with Anima Anandkumar, Alexei Efros, Ian Goodfellow, and our course instructor Sharon Zhou. I was struck by the number of new applications GANs are enabling, and the number that are likely to come.
Ian explained that GAN-generated training examples for a particular application at Apple are one-fifth as valuable as real examples but cost much less than one-fifth as much to produce. Anima described exciting progress on disentanglement and how the ability to isolate objects in images is making it easier to control image generation (“add a pair of glasses to this face”). Alexei talked about the impact GANs are having on art through tools like Artbreeder.
All the speakers talked about alternatives to reading research papers to keep up with the exploding literature. If you missed the live discussion, you can watch a video of the entire event here.
We’re still in the early days of practical GAN applications, but I believe they will:
- Transform photo editing and make it easier to add or subtract elements such as background objects, trees, buildings, and clouds
- Generate special effects for media and entertainment that previously were prohibitively expensive
- Contribute to creative products from industrial design to fine art
- Augment datasets in small data problems in fields from autonomous driving to manufacturing
As an emerging technology, GANs have numerous untapped applications. This is a moment to dream up new ideas, because no one else may be working on them yet.
I hope this technology will spark your hunger to learn more and invent new applications that will make life better for people all over the world.
Keep learning!
Andrew
Special Issue: Generation GAN

Reality Reimagined
Generative adversarial networks, or GANs, are said to give computers the gift of imagination. Competition between a discriminator network, which learns to classify the system’s output as generated or real, and a generator network, which learns to produce output that fools the discriminator, produces fantasy images of uncanny realism. First proposed in 2014, the architecture has been adopted by researchers to extend training datasets with synthetic examples and by businesses to create customized imagery for ads, entertainment, and personal services. But it has a dark side: GANs make it easy and convincing for jilted lovers to graft an ex’s face onto another person’s body, or politicians to misrepresent themselves as able to speak an ethnic minority’s language to win their votes. And it tends to tilt the training data distribution, favoring common examples while ignoring outliers. Researchers are improving the technology at breakneck pace, and developing ways to thwart, or at least detect, egregious uses. We have yet to see the best — and the worst — that GANs have to offer.

A Man, A Plan, A GAN
Brilliant ideas strike at unlikely moments. Ian Goodfellow conceived generative adversarial networks while spitballing programming techniques with friends at a bar. Goodfellow, who views himself as “someone who works on the core technology, not the applications,” started at Stanford as a premed before switching to computer science and studying machine learning with Andrew Ng. “I realized that would be a faster path to impact more things than working on specific medical applications one at a time,” he recalls. From there, he earned a PhD in machine learning at Université de Montréal, interned at the seminal robotics lab Willow Garage, and held positions at OpenAI and Google Research. Last year, he joined Apple as director of machine learning in the Special Projects Group, which develops technologies that aren’t part of products on the market. His work at Apple is top-secret.
The Batch: How did you come up with the idea for two networks that battle each other?
Goodfellow: I’d been thinking about how to use something like a discriminator network as a way to score a speech synthesis contest, but I didn’t do it because it would have been too easy to cheat by overfitting to a particular discriminator. Some of my friends wanted to train a generator network using a technique that would have taken gigabytes of data per image, even for the tiny images we studied with generative models in 2014. We were discussing the problem one night at a bar, and they asked me how to write a program that efficiently manages gigabytes of data per image on a GPU that, back then, had about 1.5GB RAM. I said, that’s not a programming problem. It’s an algorithm design problem. Then I realized that a discriminator network could help a generator produce images if it were part of the learning process. I went home that night and started coding the first GAN.
The Batch: How long did it take?
Goodfellow: By copying and pasting bits and pieces of earlier papers, I got the first GAN to produce MNIST images in only an hour of work or so. MNIST is such a small dataset that, even back then, you could train on it very quickly. I think it trained for tens of minutes before it could produce recognizable handwritten digits.
The Batch: What did it feel like to see the first face?
Goodfellow: That wasn’t as much of a revolutionary moment as people might expect. My colleague Bing Xu modeled face images from the Toronto Face Database, which were only 90 pixels square and grayscale. Because the faces were always centered and looking straight at the camera, even very simple algorithms like PCA could make pretty good faces. The main thing we were surprised by were the images it made of CIFAR10, where there’s a lot of variability. They looked like crap. But we had been looking at crap from generative models for years, and we could tell that this was an exciting, new kind of crap.
The Batch: Has anything surprised you about the way this work has played out?
Goodfellow: In the first GAN paper, we included a list of things that might happen in future work. A lot of them did. The one big category of things I didn’t anticipate was domain-to-domain translation. GANs like CycleGAN from Berkeley. You can take a picture of a horse and have it transformed into a zebra without training on matched pairs of horse and zebra images. That’s very powerful because it can be easy to passively collect data in each domain, but it’s time-consuming and expensive to get data that matches up across domains.
The Batch: What are you most hopeful about in GAN research?
Goodfellow: I’d like to see more use of GANs in the physical world, specifically for medicine. I’d like to see the community move toward more traditional science applications, where you have to get your hands dirty in the lab. That can lead to more things that have more of a tangible, positive impact on peoples’ lives. For instance, in dentistry, GANs have been used to make personalized crowns for individual patients. Insilico is using GANs to design medicinal drugs.
The Batch: How much do you worry about bias in GAN output? The ability to produce realistic human faces makes it a pressing issue.
Goodfellow: GANs can be used to counteract biases in training data by generating training data for other machine learning algorithms. If there’s a language where you don’t have as much representation in your data, you can oversample that. At Apple, we were able to generate data for a gestural text-entry feature called QuickPath. A startup called Vue.ai uses GANs to generate images of what clothing would look like on different models. Traditionally, there may not have been much diversity in who was hired to be a model to try on this clothing. Now you can get a model who looks like you, wearing a specific item of clothing you’re interested in. These are baby steps, but I hope there are other ways GANs can be used to address issues of underrepresentation in datasets.
News

A Good Look for AI
Trying on new makeup is a hassle — apply, inspect, wash off, repeat. Not to mention the tribulation of visiting brick-and-mortar stores during the pandemic. Augmented reality is helping people try on all the makeup they want without leaving home.
What’s new: Modiface, a subsidiary of beauty giant L’Oréal, uses GANs to let customers see how different colors of lipstick, eye shadow, and hair will look on them.
How it works: Modiface’s approach is a hybrid of CycleGAN, StarGAN and StyleGAN, company operations chief Jeff Houghton told The Batch. It uses a CNN to track landmarks on a user’s hair and face. At L’Oreal’s website, users can select different lipsticks, eyeliners, blushes and hair dyes and fine-tune their shade, texture, and gloss. Then they can virtually apply those products to an uploaded selfie or a real-time video of their own faces.
- To train the algorithm, Modiface collected and annotated thousands of images of people wearing and not wearing makeup and hair coloring under various lighting and background conditions.
- A CycleGAN takes as input an image of a user’s face without makeup. When the user selects a specific makeup product, the system generates an image that shows what the selected product looks like when applied.
- Adding new makeup types to the model is as simple as adding a color swatch to the database. Modiface must retrain the model to include new products with properties, such as a metallic sheen, that aren’t represented in the training data.
- Collaborations with Amazon and Facebook enable users to access Modiface directly from those platforms.
Behind the news: Augmented reality applications are reshaping the beauty industry. In 2018, the same year L’Oréal purchased Modiface, American chain Ulta acquired Glamst, a startup specializing in augmented reality. Meitu, a multi-billion dollar Chinese company, uses AI-driven face manipulation to make its users appear more attractive in social media posts, job applications, and other digital venues.
Why it matters: E-commerce is increasingly important to the beauty industry’s bottom line, and the pandemic is driving even more business to the web. Tools like this make it easier for customers to try out products, which may boost sales.
We’re thinking: It seems like we’re spending half our lives in video conferences. Do we still need to apply makeup at all, or can we let a GAN do it instead?
Learn how to build a CycleGAN and control image features in Courses 1 and 2 of the GANs Specialization from DeepLearning.AI, available now on Coursera. Build the powerful StyleGAN in Course 3: Apply GANs, coming soon!
Making GANs More Inclusive
A typical GAN’s output doesn’t necessarily reflect the data distribution of its training set. Instead, GANs are prone to modeling the majority of the training distribution, sometimes ignoring rare attributes — say, faces that represent minority populations. A twist on the GAN architecture forces its output to better reflect the diversity of the training data.
What’s new: IMLE-GAN learns to generate all the attributes of its training dataset, including rare ones. Ning Yu spearheaded the research with colleagues at University of Maryland, Max Planck Institute, University of California Berkeley, CISPA Helmholtz Center for Information Security, Princeton’s Institute for Advanced Study, and Google.
Key insight: A GAN’s discriminator distinguishes whether or not the generator’s output is generated, while the generator learns to produce output that fools the discriminator. Ideally, a generator’s output would mirror the training data distribution, but in practice — since its only aim is to fool the discriminator, and the discriminator typically evaluates only one image at a time — it can learn to favor common types of examples. The authors had their model compare several generated works with examples from the training set, as well as interpolations between generated works, to encourage greater diversity in the output.
How it works: IMLE-GAN enhances a GAN with Implicit Maximum Likelihood Estimation (IMLE). Instead of naively adding the IMLE loss to the usual adversarial loss, the authors modified the default IMLE loss and added a novel interpolation loss to compensate for fundamental incompatibilities between the adversarial and IMLE losses.
- IMLE generates a set of images and penalizes the network based on how different those images are from real images by making nearest-neighbor comparisons. Instead of comparing pixels, like in standard IMLE, the authors compare the images over the feature space. The switch from pixels to features makes the adversarial and IMLE losses more comparable.
- To compute the interpolation loss, the authors create an additional image that is interpolated between two generated images. Then, they compare the interpolated image’s features to those of the two non-generated images that were matched to the generated images during IMLE.
- To increase inclusion of underrepresented attributes, the algorithm samples data from a set of minority examples for the IMLE and interpolation losses, but from all examples for the adversarial loss.
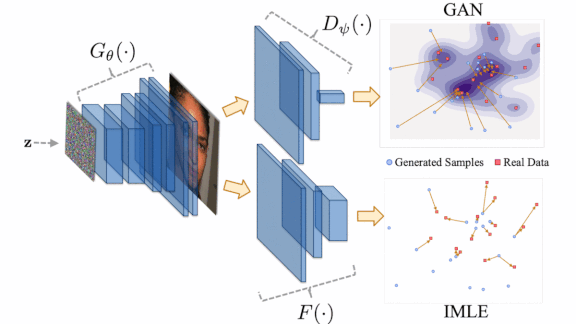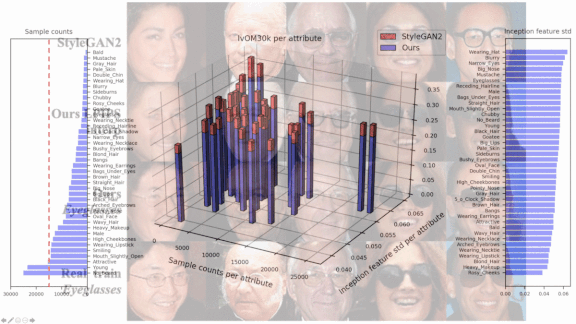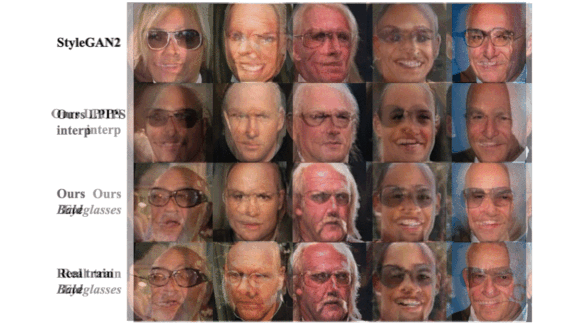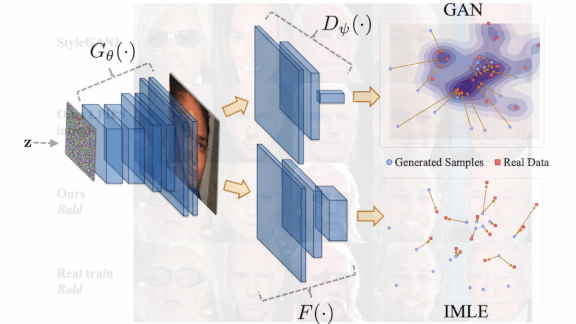
Results: The authors evaluated IMLE-GAN against StyleGAN and a handful of other models using Stacked MNIST, a variation of the MNIST dataset that includes handwritten digits in 1,000 distinct styles. IMLE-GAN reproduced 997 of the styles, while StyleGAN reproduced 940. Trained on CelebA, a large-scale dataset of celebrity faces, IMLE-GAN generated attributes present in less than 6 percent of training examples with increased precision compared to StyleGAN. For instance, it generated wearers of eyeglasses with 0.904 precision, compared to StyleGAN’s meager 0.719.
Why it matters: Much of the time, we want our models to learn the data distribution present in the training set. But when fairness or broad representation are at stake, we may need to put a finger on the scale. This work offers an approach to making GANs more useful in situations where diversity or fairness is critical.
We’re thinking: This work helps counter model and dataset bias. But it’s up to us to make sure that training datasets are fair and representative.
Learn about what to consider when evaluating a GAN for your application and the potential impact of biases in Course 2: Build Better GANs, available now on Coursera.
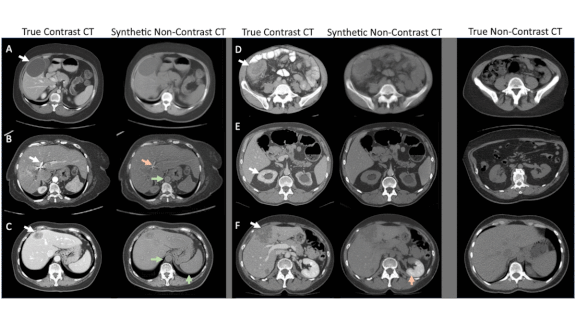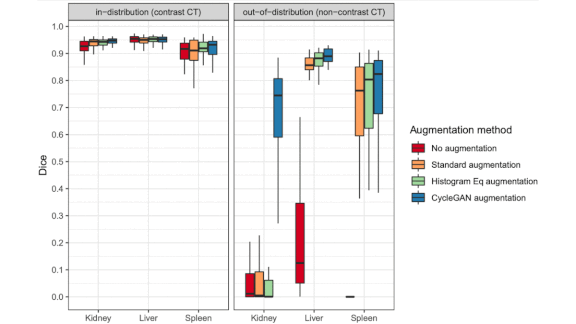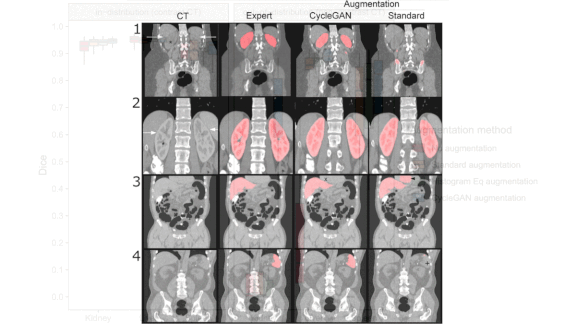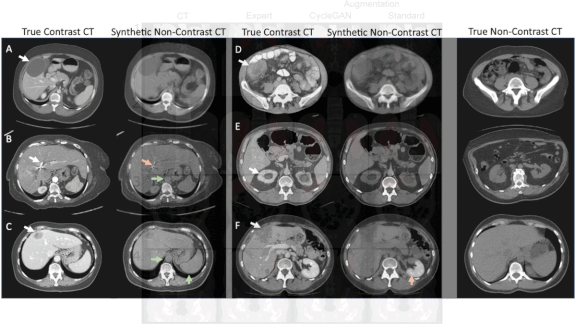
More Data for Medical AI
Convolutional neural networks are good at recognizing disease symptoms in medical scans of patients who were injected with iodine-based dye, known as radiocontrast, that makes their organs more visible. But some patients can’t take the dye. Now synthetic scans from a GAN are helping CNNs learn to analyze undyed images.
What’s new: Researchers from the U.S. National Institutes of Health and University of Wisconsin developed a GAN that generates labeled, undyed computerized tomography (CT) images of lesions on kidneys, spleens, and livers. They added these images to real-world training data to improve performance of a segmentation model that marks lesions in diagnostic scans.
How it works: The work is based on CycleGAN and the DeepLesion dataset of CTs. CycleGAN has been used to turn pictures of horses into pictures of zebras without needing to match particular zebra and horse pics. This work takes advantage of that capability to map between dyed and undyed CTs.
- The authors used a CNN to sort DeepLesion into images of dyed and undyed patients. They trained the GAN on a portion of the dataset, including both dyed and undyed CTs, and generated fake undyed images.
- Using a mix of CycleGAN output and natural images, they trained a U-Net segmentation model to isolate lesions, organs, and other areas of interest.
- To compare their approach with alternatives, they trained separate U-Nets on variations of DeepLesion: dyed images in which the dye had been artificially lightened, images that had been augmented via techniques like rotation and cropping, and the dataset without alterations.
Results: Tested on undyed, real-world CT scans, the U-Net trained on the combination of CycleGAN output and natural images outperformed the others. It was best at identifying lesions on kidneys, achieving a 57 percent improvement over the next-best model. With lesions on spleens, the spread was 4 percent; on livers, 3 percent. In estimating lesion volume, it achieved an average error of 0.178, compared to the next-highest score of 0.254. Tested on the remainder of the dyed DeepLesion images, all four U-Nets isolated lesions roughly equally well.
Behind the news: The researchers behind this model have used it to improve screening for dangerous levels of liver fat and to identify patients with high risk of metabolic syndrome, a precursor to heart disease, diabetes, and stroke.
Why it matters: Medical data can be hard to come by and labeled medical data even more so. GANs are making it easier and less expensive to create large, annotated datasets for training AI diagnostic tools.
We’re thinking: Medical AI is just beginning to be recognized by key healthcare players in the U.S. Clever uses of CycleGAN and other architectures could accelerate the process.
To learn more about using GANs to augment training datasets, including the pros and cons, stay tuned for GANs Specialization Course 3: Apply GANs, coming soon to Coursera.
A MESSAGE FROM DEEPLEARNING.AI

We’re thrilled to announce the launch of our new Generative Adversarial Networks Specialization on Coursera! Enroll now
The Telltale Artifact
Deepfakes have gone mainstream, allowing celebrities to star in commercials without setting foot in a film studio. A new method helps determine whether such endorsements — and other images produced by generative adversarial networks — are authentic.
What’s new: Lucy Chai led MIT CSAIL researchers in an analysis of where image generators fool and where they fail. They developed a technique to detect portions of an image that betray fakery.
Key insight: Large-scale features of generated images are highly varied, but generated textures contain consistent artifacts. Convolutional neural networks (CNNs) are especially sensitive to textures, which makes them well suited to recognizing such artifact-laden areas. A CNN tailored for analyzing small pieces of images can learn to recognize parts dominated by generated textures.
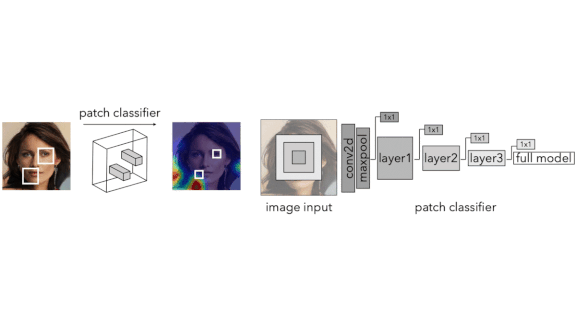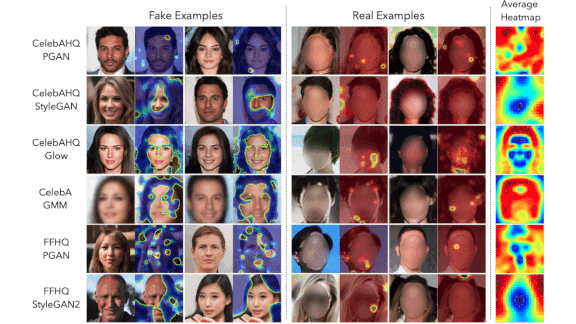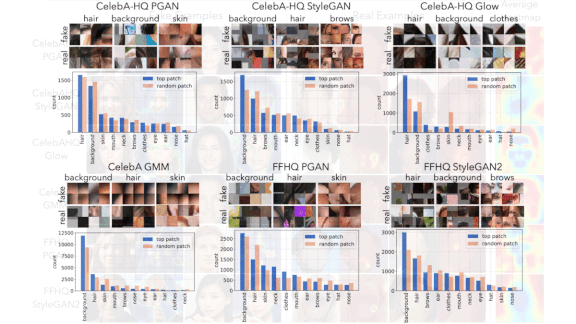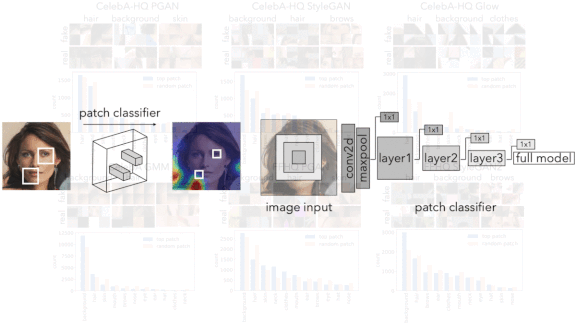
How it works: The authors built classifiers that survey images one patch at a time. They ran the classifiers on output from StyleGAN, Glow, and a generator model based on Gaussian mixture models (GMMs). They averaged the patchwise classifications to analyze each GAN’s vulnerability to detection.
- The authors created a dataset of images generated by a Progressive GAN trained on the CelebA-HQ dataset of celebrity portraits.
- They modified Resnet and Xception architectures to classify patches of user-determined size and trained them on the generated images. They removed the deeper layers, which analyze larger image areas, to concentrate the models on fine details.
- They used the classifications to produce heatmaps of image areas recognized as generated (blue) or not (red). Predominantly blue images were deemed to have been generated.
- By averaging the heatmaps over many images produced by the same GAN, the authors were able to identify the areas where that model is especially prone to leaving artifacts. For instance, StyleGAN and Glow generated high concentrations of artifacts in facial details, while GMM tended to generate them in backgrounds.
Results: The authors’ best classifier achieved 100 percent average precision on StyleGAN output and 91.38 percent on GMM. These scores outperformed non-truncated MesoInception4, Resnet-18, Xception, and CNN models, which achieved average precision between 99.75 and 73.33 percent. On Glow, the authors’ best classifier achieved 95 percent average precision, whereas the best full model scored 97.32 percent.
Why it matters: The better GANs become, the more useful they can be for both good and ill. In shedding light on areas where particular GANs produce more artifacts, this work illuminates pathways for researchers to improve them. But it also provides a map for malefactors to make their activities harder to detect. In fact, when the researchers trained a GAN to fool their classifiers, accuracy fell to less than 65 percent.
We’re thinking: Building a discriminator that recognizes a particular generator’s output is easier than building a good generator. In fact, GAN researchers routinely degrade discriminators to give the generator a fighting chance to fool it. But social media platforms, among others, would like to catch all generated images, regardless of the generator that produced them. Looking for common artifacts offers a promising approach — until a variety of generators learn how to avoid producing them.
Learn how image translation is used to create deepfakes in the upcoming Course 3: Apply GANs, available soon on Coursera.
Style and Substance
GANs are adept at mapping the artistic style of one picture onto the subject of another, known as style transfer. However, applied to the fanciful illustrations in children’s books, some GANs prove better at preserving style, others better at preserving subject matter. A new model is designed to excel at both.
What’s new: Developed by researchers at Hacettepe University and Middle East Technical University, both in Turkey, Ganilla aims to wed photographic content and artistic style for illustrations in children’s books. It converts photos into virtual artwork in the styles of 10 published children’s book illustrators, including favorites like Patricia Polacco and Kevin Henkes, while staying true to scenes in photos.
How it works: Ganilla is almost identical to CycleGAN except for a specially crafted generator.
- The researchers divided their generator into a downsampling stage and an upsampling stage.
- The downsampling stage is a modified Resnet-18 with additional skip connections to pass low-level features, such as textures and edges, from one layer to the next.
- The upsampling stage consists of layers of transposed convolutions that increase the size of the feature map and skip connections from the downsampling stage. The skip connections in this stage help preserve subject matter without overwriting style information.
- The authors trained the model on unpaired images from two datasets. The first contained nearly 5,500 images of landscape scenery, the second hundreds of works by each of 10 illustrators.
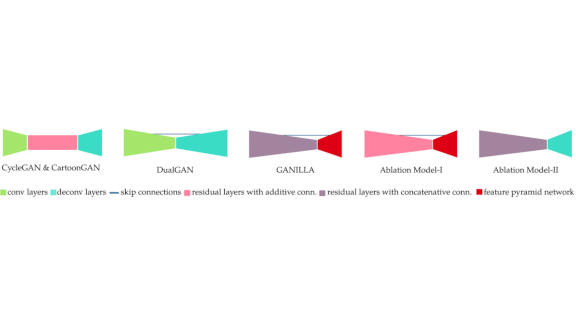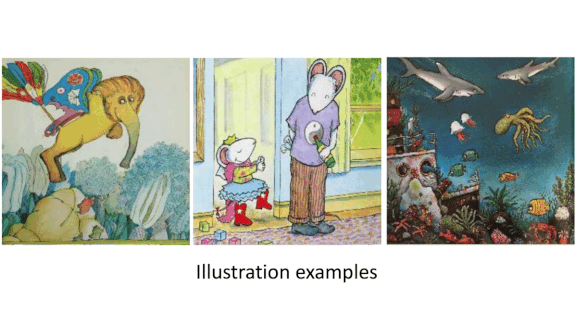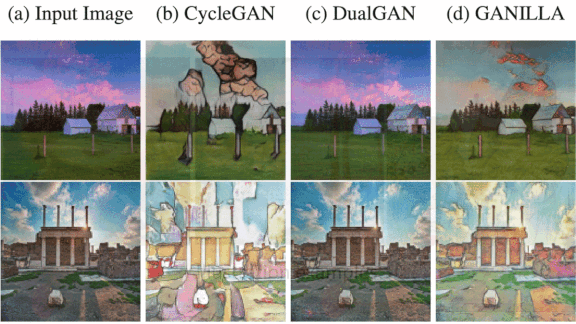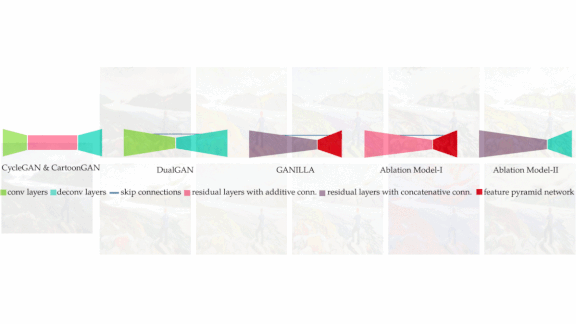
Results: There’s no way to measure objectively how well a model generates landscapes in specific artistic styles, so the authors used quantitative and qualitative approaches to compare Ganilla’s output with that of a CycleGAN, DualGAN, and CartoonGAN trained on the same data.
- They trained a pair of CNNs to assess the GANs’ proficiency at transferring style (trained on small portions of images from each artist) and content (trained on full-size photos). The style classifier scored CycleGAN highest, while the content classifier gave DualGAN the edge. Ganilla ranked highest when style and content scores were averaged.
- The researchers asked 48 people to (a) rate whether each GAN-made illustration looked like the illustrator’s work, (b) describe what they thought the picture showed, and (c) rank generated images in terms of overall appeal. They scored Ganilla’s output highest for mimicking the human illustrators and depicting the source content. However, they rated DualGAN’s output slightly more appealing.
Yes, but: Based on examples in the paper, the training illustrations tended to be heavy on stylized human and animal characters, while the photos contain very few characters. We’re curious to see what Ganilla would do with more photos of people and animals.
Why it matters: GANs are powerful creative tools, and — like printmaking and photography before them — they’re spawning their own adversarial dynamic in the arts. Artists working in traditional media have raised concerns about GANs being trained to make derivatives of their work. Now, digital artists are accusing traditional artists of creative theft for making paint-on-canvas reproductions of their AI-abetted digital compositions.
We’re thinking: When it comes to art, we favor GANs as a creative partner.
Learn about human and algorithmic approaches to evaluating generative adversarial networks in GAN Specialization Course 2: Build Better GANs on Coursera. To build your own CycleGAN for style transfer, stay tuned for Course 3: Apply GANS, coming soon to Coursera!