
Dear friends,
In last week’s issue of The Batch, Yoshua Bengio, Alon Halevy, Douwe Kiela, Been Kim, and Reza Zadeh shared their hopes for AI in 2023. I also asked people on LinkedIn and Twitter about their hopes for AI this year. Rather than focusing on the latest buzzy topics in the news, many offered an amazing diversity of answers.
In addition to hopes for further technical advances, common themes include:
- Societal matters. Fairness, bias, and regulation are top concerns. Progress in responsible AI remains important, and with the rise of technologies like generative AI, we need new techniques to make them responsible as well. (For instance, how do we stop image generators from producing unwanted sexualized images of women?) Regulators worldwide are also struggling to keep up.
- Progress in application areas including agriculture, biology, climate change, healthcare, scientific discovery, and many more. It feels like the number of applications still outstrips the number of people we have! I'm glad the AI community continues to grow.
- More open sharing and open source. Many people appreciate the open sharing of ideas and code and hope it continues. With respect to open source, personally, I hope that teams will release code under licenses approved by the Open Source Initiative, which permit broad use, rather than more restrictive licenses.

- Training in AI and data literacy for many more people. AI capabilities and the availability of data are rising rapidly, so the potential for value creation via AI and data science grows every year. But most of the world is able to access this value only through systems built by someone else, usually a large tech company. Better training will enable people to solve a wider variety of problems, enriching society.
- Personal growth including learning more and/or finding a job. Many individuals want to keep learning, advance their skills, and build a career. The opportunities are out there, so I’m glad that so many of us are working to better ourselves to meet the opportunities!
That we all have so many different dreams for AI is a sign of how large our community has become and the broad footprint of our impact. It also means more fun technologies to learn about and more people we can learn from and collaborate with.
I found the comments inspiring and am grateful to everyone who responded. If you’re looking for AI inspiration, take a look at the discussion and perhaps you’ll find ideas that are useful in your work. If you find the variety of comments overwhelming, consider writing software that clusters them into topics and share your results with me!
Keep learning!
Andrew
News
Will We Have Enough Data?
The world’s supply of data soon may fail to meet the demands of increasingly hungry machine learning models.
What’s new: Researchers at Epoch AI found that a shortage of text data could cause trouble as early as this year. Vision data may fall short within a decade.
How it works: The authors compared the future need for, and availability of, unlabeled language and vision data. To evaluate language data, the authors focused on text from sources like Wikipedia, Arxiv, and libraries of digital books. These sources are subject to editorial or quality control, which makes them especially valuable for training large language models. With respect to vision data, they averaged the number of digital images produced and video uploaded to YouTube, Instagram, Snapchat, WhatsApp, and Facebook.
- The authors forecast future supplies of unlabeled data by estimating the current sizes of high-quality data sources. They projected each source’s growth rate based on either global population growth, internet penetration, or economic growth (assuming that research and development consumes a fixed percentage of the global economy). Then they summed the sizes of all sources.
- Previous work had found the optimal dataset size for a given processing budget. The authors projected the size of datasets required to train future models based on an earlier projection of processing budgets for machine learning.
- Considering projected data supplies and the dataset sizes required to train future models, they determined when the two would intersect; that is, when available data would fail to meet demand.
Results: Dataset sizes needed to train large models will grow much faster than data supplies, the authors concluded.
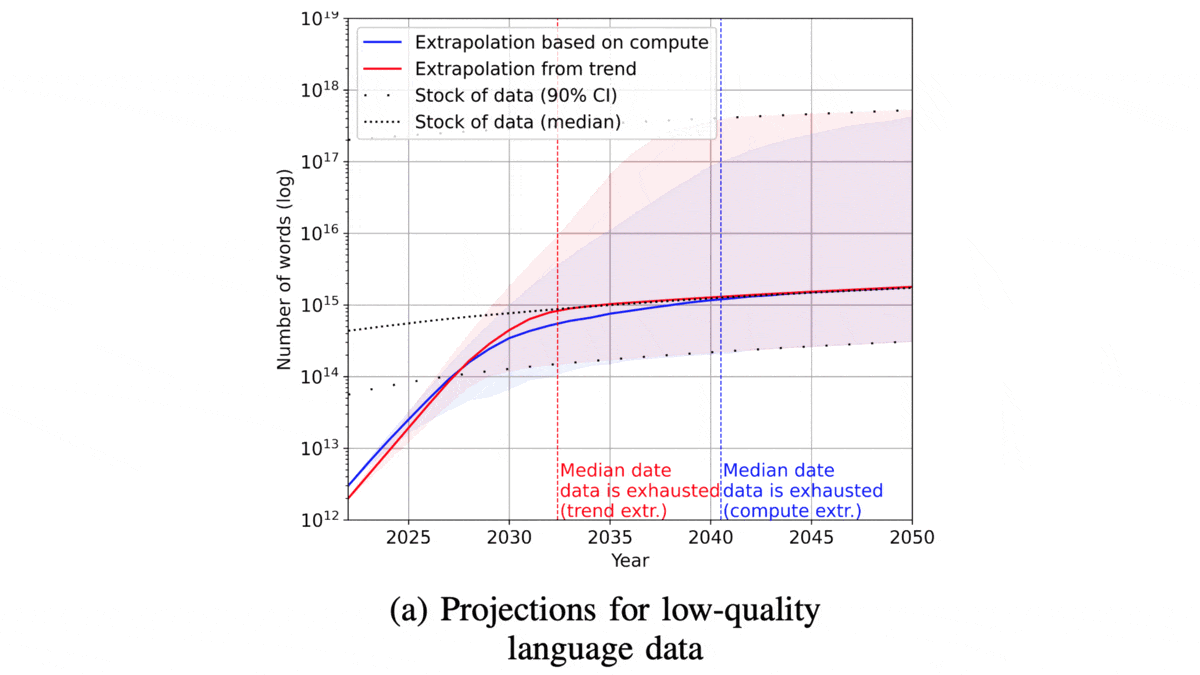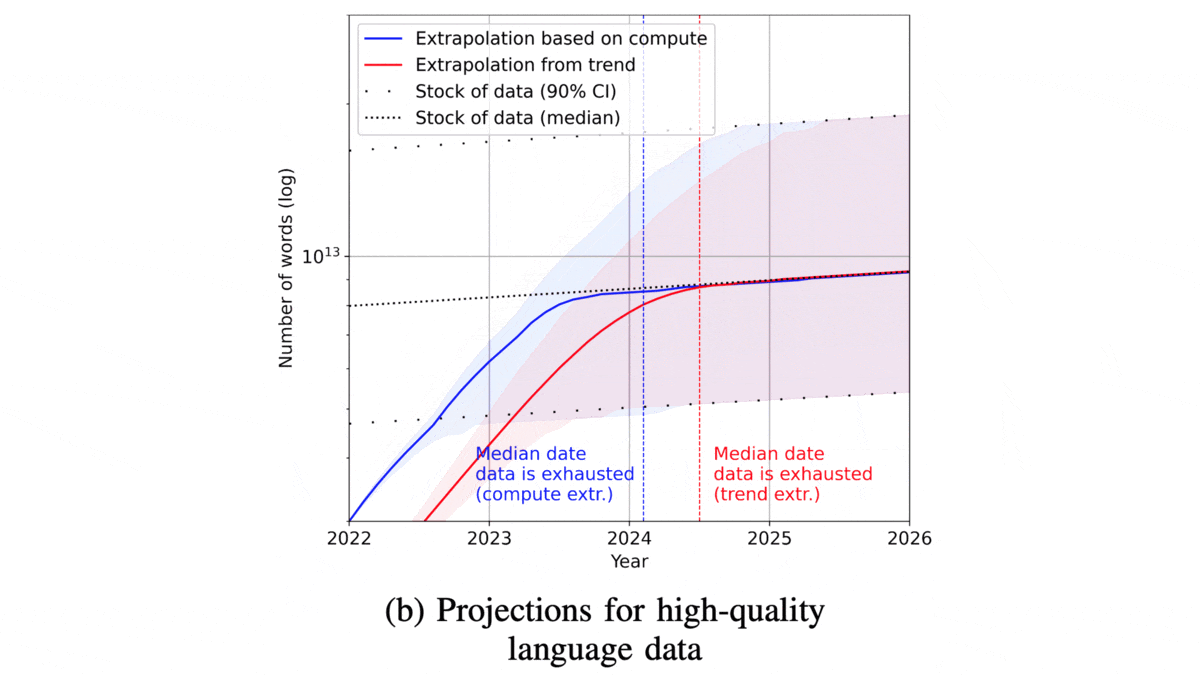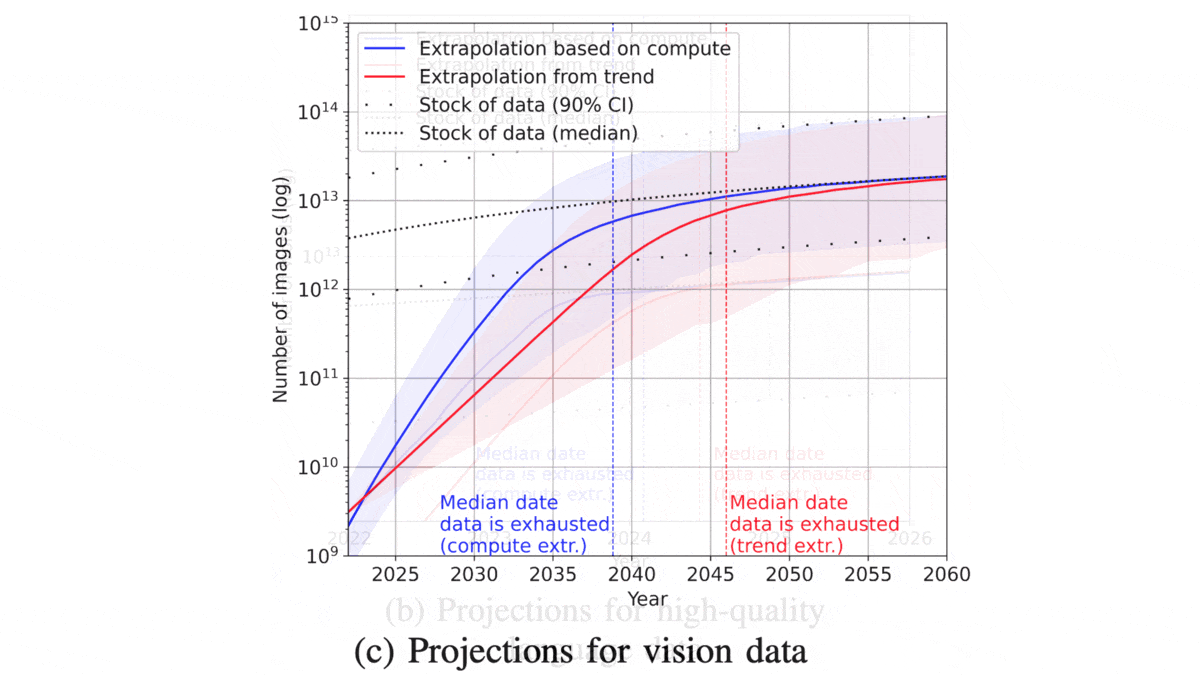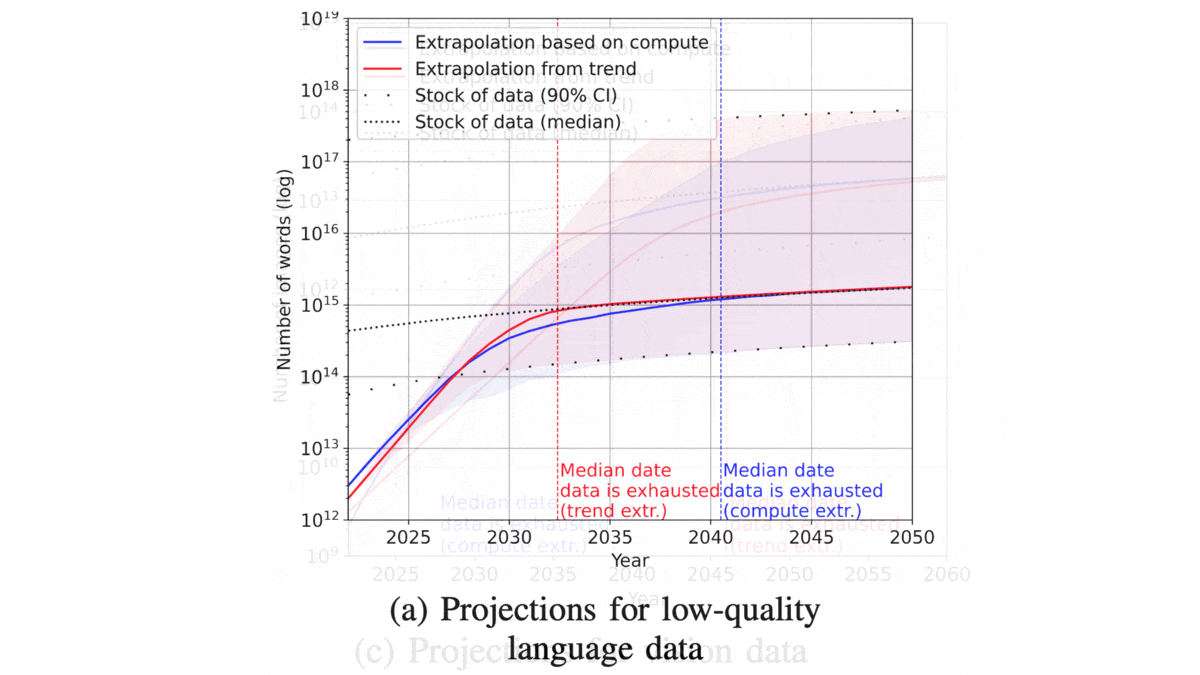
- The current supply of high-quality language data amounts to 1012 to 1013 words, growing at 4 to 5 percent annually. Today’s largest high-quality text datasets, like Pile-CC, already contain roughly 1012 words, a figure that will need to double about every 11 to 21 months to keep pace. Thus the supply is likely to fall short between 2023 and 2027.
- Developers of language models can gain a few years of runway by compromising on data quality. The supply of language data rises to around 1014 to 1015 words if it includes unedited sources like social media posts, transcribed human speech, and Common Crawl. The authors expect this expanded pool to grow between 6 and 17 percent each year, which could delay the shortage to sometime between 2030 and 2040.
- The supply of vision data amounts to 1012 to 1013 images, growing by about 8 percent annually. The largest vision datasets comprise around 109 total images and will need to double every 30 to 48 months to keep up. Given those growth rates, the authors expect vision data to fall short between 2030 and 2060.
Behind the news: Epoch previously calculated the size and historical growth of training datasets.
- The largest high-quality text datasets have grown, on average, 0.23 orders of magnitude a year for three decades, increasing from 105 words in 1992 to 1012 words in 2022.
- Vision datasets have grown more slowly, increasing around 0.11 orders of magnitude per year. For much of the 2010s, the largest vision datasets were based on ImageNet (106 images). Since 2016, however, much larger image datasets have appeared such as Google’s JFT-3B (109 images).
Yes, but: The authors’ estimates have large margins of error, making for very imprecise estimates of time left before data might tap out. Moreover, they mention a number of events that could throw their projections off. These include improvements to the data efficiency of models, increases in the quality of synthetic data, and commercial breakthroughs that establish new sources of data; for instance, widespread use of self-driving cars would produce immense amounts of video.
Why it matters: Despite gains in small data, training on a larger quantity of high-quality data, if it’s available, is a reliable recipe for improved performance. If the AI community can’t count on that improvement, it will need to look elsewhere, such as architectures that don’t require so much data to train.
We’re thinking: Many AI naysayers have turned out wrong when technical innovation overran their imaginations, and sometimes the innovator has thanked the naysayer for drawing attention to an important problem. Data-centric methods improve the quality of data that already exists, enabling models to learn more from less data. In addition, novel training techniques have enabled less data-hungry models to achieve state-of-the-art results. And we might be surprised by the clever ways researchers find to get more data.

Precision-Guided Image Generation
Typical text-to-image generators can generate pictures of a cat, but not your cat. That’s because it’s hard to describe in a text prompt precisely all the things that distinguish your pet from other members of the same species. A new approach guides diffusion models in a way that can produce pictures of your darling Simba.
What's new: Rinon Gal and colleagues at Nvidia and Tel-Aviv University devised a method to make a diffusion-based, text-to-image generator produce pictures of a particular object or in a particular style.
Basics of diffusion models: During training, a text-to-image generator based on diffusion takes a noisy image and a text description. A transformer learns to embed the description, and a diffusion model learns to use the embeddings to remove the noise in successive steps. At inference, the system starts with pure noise and a text description, and iteratively removes noise according to the text to generate an image. A variant known as a latent diffusion model saves computation by removing noise from a small, learned vector of an image instead of a noisy image.
Key insight: A text-to-image generator feeds text word embeddings to an image generator. Adding a learned embedding that represents a set of related images can prompt the generator to produce common attributes of those images in addition to the semantic content of words.
How it works: The authors used a text-to-image generator based on a latent diffusion model. The system was pretrained on 400 million text-image pairs scraped from the web. Its weights were frozen.
- The authors fed the system three to five images that shared an object (in different rotations or settings) or style (depicting different objects). They also gave it a text description of the images with a missing word denoted by the characters S∗. Descriptions included phrases like “a painting of S∗” or “a painting in the style of S∗”.
- The transformer learned an embedding of S∗, which represented attributes the images had in common.
- Given a prompt that included “S∗” — for instance, “a grainy photo of S∗ in Angry Birds” — the transformer embedded the words and S∗. The latent diffusion model took the embeddings and produced an image.
Results: The authors evaluated their model’s output by comparing embeddings, generated by CLIP, of original and generated images. They measured similarity on a scale from 0 to 1, where 1 signifies two identical inputs. The model scored around 0.78. Images generated using human-crafted descriptions of up to 12 words — without reference to S∗ — scored around 0.6. Images generated using longer descriptions of up to 30 words scored around 0.625.
Why it matters: The authors’ method offers a simple way for users of diffusion-based, text-to-image generators to steer the output toward specific attributes of content or style without retraining the model.
We’re thinking: Could this approach be extended to encompass multiple learned vectors and allow users to combine them as they like? That would make it possible to control image generation in even more precise ways.
A MESSAGE FROM DEEPLEARNING.AI

"You don’t have to be a mathematician to have a feel for numbers," said mathematician John Forbes Nash, Jr. Get a feel for the numbers with Mathematics for Machine Learning and Data Science, our new specialization. Join the waitlist
AI as Officemate
Many workers benefit from AI in the office without knowing it, a new study found.
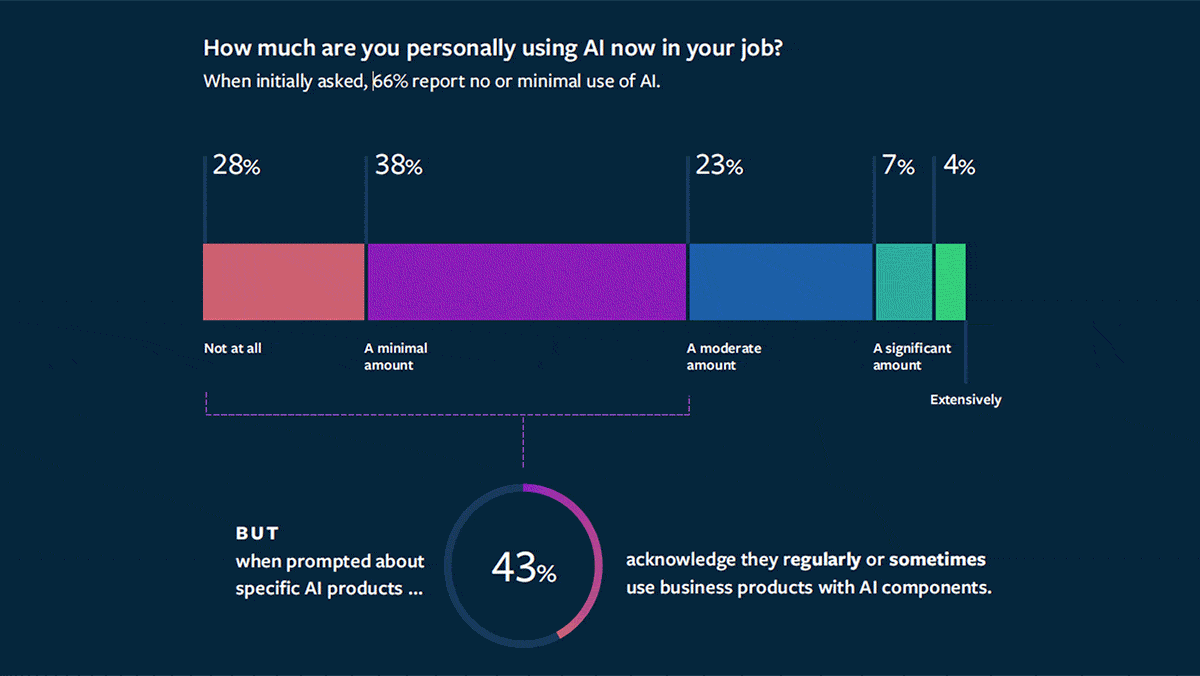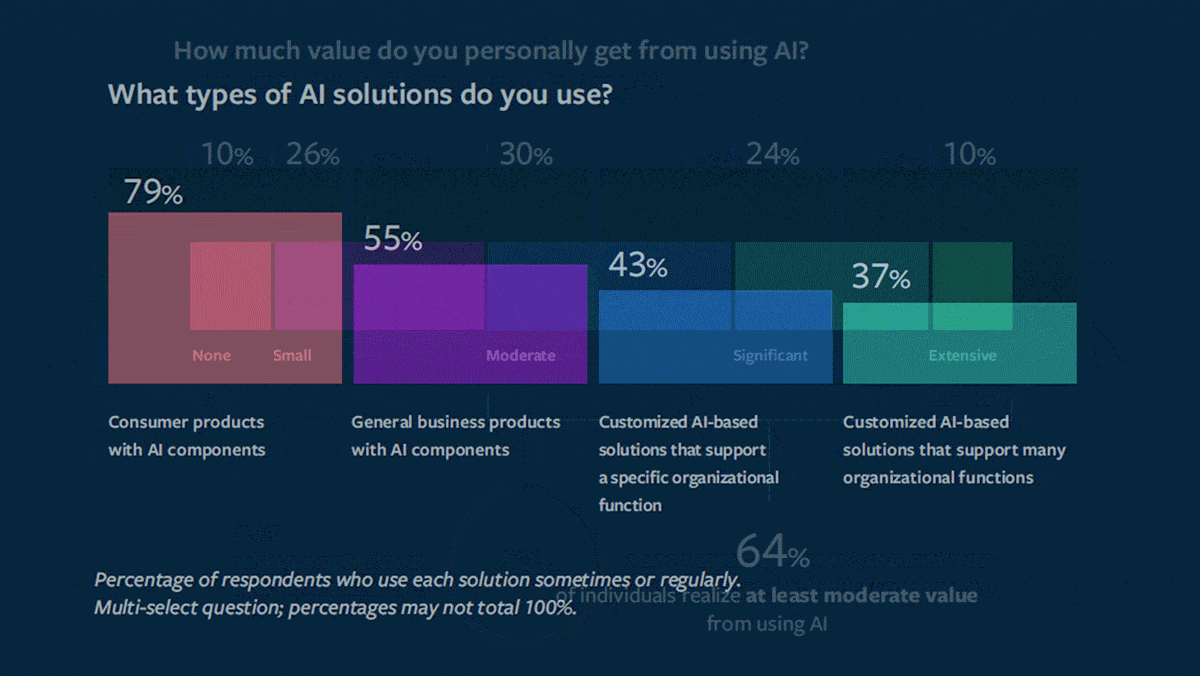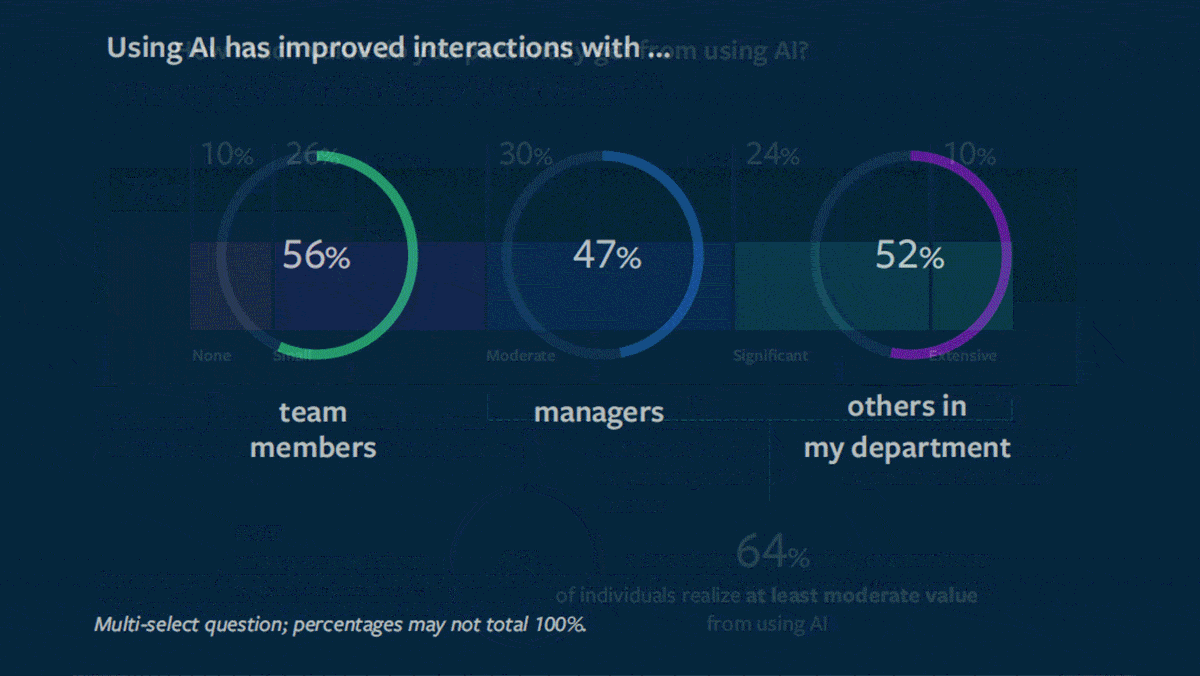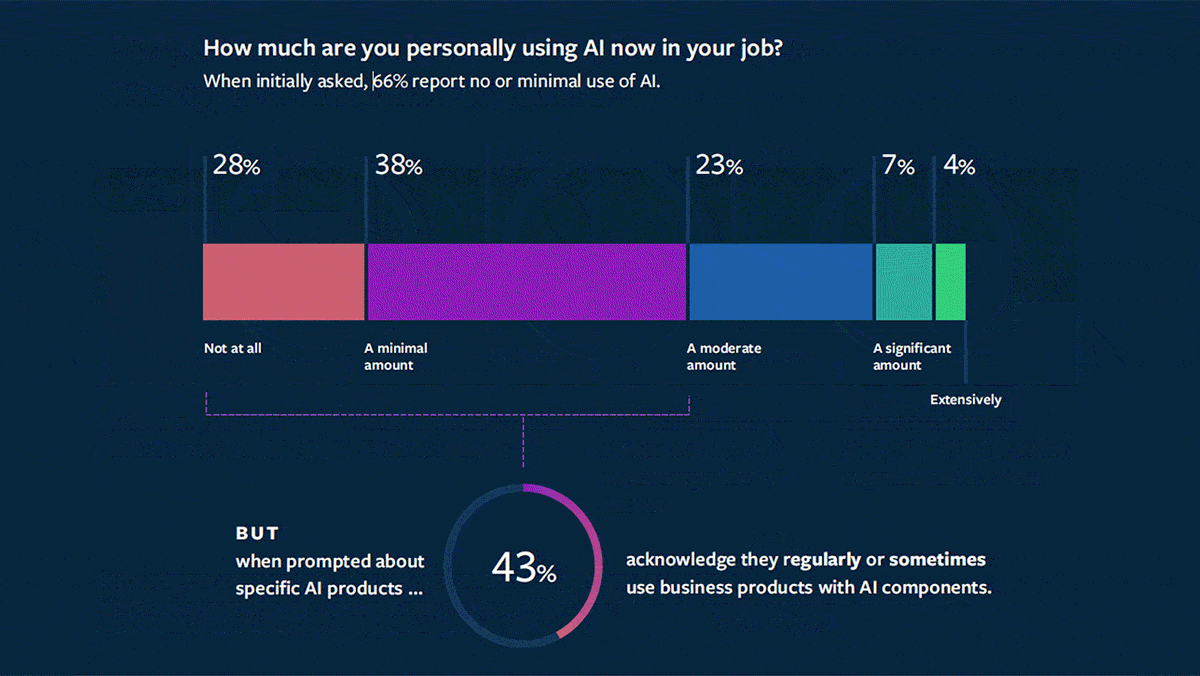
What’s new: MIT Sloan Management Review and Boston Consulting Group surveyed employees on their use of AI in their day-to-day work. Their findings: The technology offers benefits to individuals and organizations, but employers may need to educate and direct workers to realize them.
What it says: The authors surveyed 1,741 respondents in over 20 industries and 100 countries. They also interviewed 17 executives about how AI is used in their organizations.
- Many workers didn’t realize they were using the technology. 34 percent of respondents said they used AI at least “a moderate amount.” When they were prompted about specific AI products, though, an additional 28 percent said they used the products “regularly” or “sometimes.”
- 64 percent of respondents said they got “moderate,” “significant,” or “extensive” value from AI, while 10 percent said they got no value. Respondents who said they received value were 3.4 times more likely to be satisfied in their jobs than those who didn’t.
- Respondents who said they trusted AI were two times more likely to use it regularly. Those who were required to use AI at work were three times more likely to use it regularly and 1.4 times more likely to see value in it.
- Perceived value to organizations and individuals went hand-in-hand. Of respondents who said their organizations got “moderate,” “significant,” or “extensive” value from AI, 85 percent also said they personally obtained value from the technology.
Consumer vs. pro products: The authors polled respondents on their use of AI products in four categories.
- 79 percent used consumer products like Grammarly and Siri.
- 55 percent used business products including customer relationship management systems like Microsoft Dynamics 365 and off-the-shelf imaging tools for radiology.
- 43 percent used customized algorithms that perform a specific task, such as a tool from shipping firm DHL that optimizes loads on cargo planes.
- 37 percent used customized algorithms that perform multiple tasks, such as an Amazon program that automatically sets prices, forecasts demand, and manages inventory.
Behind the news: A recent study supports the notion that AI bolsters workers more than it replaces them. Employment rates rose between 2008 and 2018 in a number of professions subject to AI-powered automation including fast food worker, translator, and financial advisor.
Why it matters: Many workers justifiably worry that AI will make their jobs obsolete. This survey suggests instead that AI is broadly enhancing many workers’ jobs.
We’re thinking: It's not necessarily bad that many people don’t recognize AI’s role in their everyday lives. Successful technology often disappears into the background. We talk about turning on lights, not electric lights, because electricity works so well that we take it for granted. If AI is the new electricity, we can expect it to be taken for granted, too.

Transparency for AI as a Service
Amazon published a series of web pages designed to help people use AI responsibly.
What's new: Amazon Web Services introduced so-called AI service cards that describe the uses and limitations of some models it serves. The move is an important acknowledgment of the need to describe the workings of machine learning models available to the general public.
How it works: The company documented three AI models: Rekognition for face matching, Textract AnalyzeID for extracting text from documents, and Transcribe for converting speech to text.
- A section on intended use cases describes applications and risks that confound the model’s performance in each of those applications. For instance, the card for Rekognition lists identity verification, in which the model matches selfies to images in government documents, and media applications, which match faces found in photos or videos to a set of known individuals.
- A section on the model’s design explains how it was developed and tested and describes expectations for performance. It provides information on explainability, privacy, and transparency. It also describes the developer’s efforts to minimize bias. For example, this section for Textract AnalyzeID describes how the developers curated training data to extract text in documents from a wide range of geographic regions.
- A section on deployment offers best practices for customers to optimize the model’s performance. This section for Transcribe suggests that users keep close to the microphone and reduce background noise. It also explains how customers can deploy custom vocabularies to help the model transcribe regional dialects or technical language.
- Amazon will update each service card in response to community feedback. It provides resources for customers who build models using SageMaker to create their own cards.
Behind the news: In 2018, researchers including Margaret Mitchell and Timnit Gebru, who were employed by Google at the time, introduced the concept of model cards to document a model’s uses, biases, and performance. Google implemented a similar approach internally the following year.
Why it matters: Model cards can help users take advantage of AI responsibly. Hundreds of thousands of people use cloud services that offer AI functions including prebuilt models. Knowing what the models were intended to do, what their limitations are, and so on can help users deploy them effectively and avoid misuses that could lead them into ethical or legal trouble.
We're thinking: We applaud Amazon’s efforts to increase transparency around their models. We look forward to service cards for more models and, hopefully, tools that help developers increase the transparency of their own models.