
The power of deep learning is blunted in domains where labeled training data is scarce. But that may be changing, thanks to a new architecture that recognizes images with high accuracy based on few labeled samples.
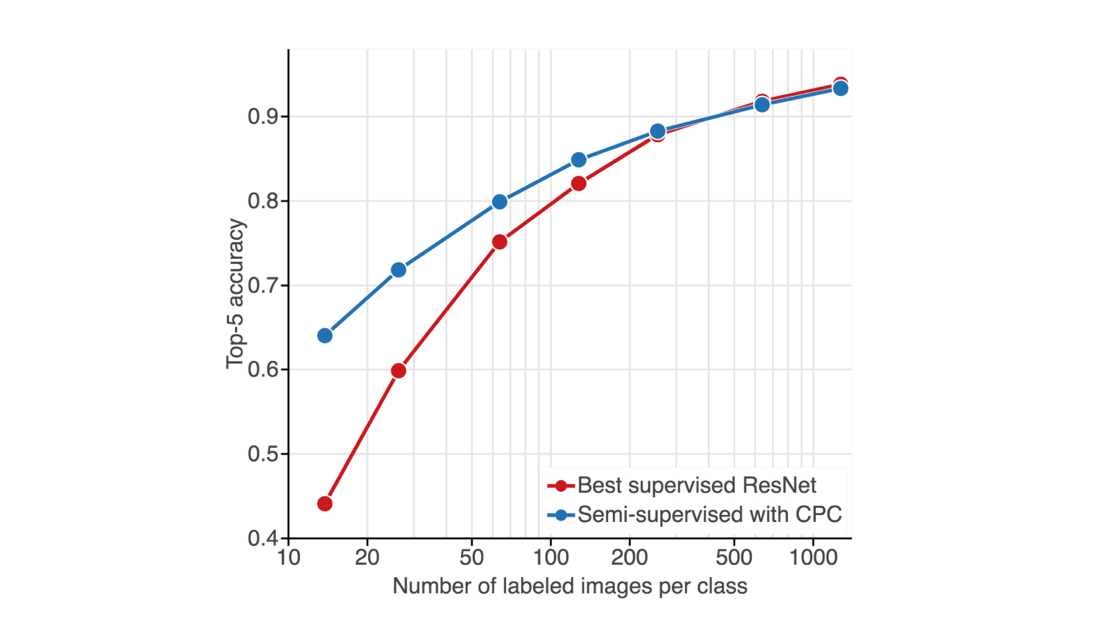
What’s new: Researchers devised a network that, given a small number of labeled images, can learn enough from unlabeled images to outperform a fully trained AlexNet model. Their architecture achieves strong performance with as few as 13 images per class. And performance improves with additional labeled examples, unlike other semi-supervised approaches.
How it works: The trick is a technique called contrastive predictive coding, which learns to predict high-level features of an image from lower-level ones. Olivier J. Hénaff and his colleagues at DeepMind adapted earlier work with CPCs by using an unusually deep and wide residual network, using layer rather than batch normalization, and predicting both lower- and higher-level features. They also messed with image patches to remove low-level cues, forcing the network to focus on high-level structure. The resulting network learns to capture image features at various levels of detail.
Results: With a small number of labeled images, the CPC network beat the state-of-the-art performance of supervised models in ImageNet classification.
Why it matters: Small data is a frontier for deep learning. The new approach opens new territory in tasks like diagnosing rare diseases, spotting defects on a production line, and controlling robots, where few labeled examples may be available.
Takeaway: The Deep Mind team’s accomplishment reduces a barrier to applying deep learning in low-data domains. Watch for evolving small-data techniques to open up exciting new applications in the next few years.