
Dear friends,
Last week, I wrote about switching roles, industries, or both as a framework for considering a job search. If you’re preparing to switch roles (say, taking a job as a machine learning engineer for the first time) or industries (say, working in an AI tech company for the first time), there’s a lot about your target job that you probably don’t know. A technique known as informational interviewing is a great way to learn
An informational interview involves finding someone in a company or role you’d like to know more about and informally interviewing them about their work. Such conversations are separate from searching for a job. In fact, it’s helpful to interview people who hold positions that align with your interests well before you’re ready to kick off a job search.
- Informational interviews are particularly relevant to AI. Because the field is evolving, many companies use job titles in inconsistent ways. In one company, data scientists might be expected mainly to analyze business data and present conclusions on a slide deck. In another, they might write and maintain production code. An informational interview can help you sort out what the AI people in a particular company actually do.
- With the rapid expansion of opportunities in AI, many people will be taking on an AI job for the first time. In this case, an informational interview can be invaluable for learning what happens and what skills are needed to do the job well. For example, you can learn what algorithms, deployment processes, and software stacks a particular company uses. You may be surprised — if you’re not already familiar with the data-centric AI movement — to learn how much time most machine learning engineers spend iteratively cleaning datasets.

Prepare for informational interviews by researching the interviewee and company in advance, so you can arrive with thoughtful questions. You might ask:
- What do you do in a typical week or day?
- What are the most important tasks in this role?
- What skills are most important for success?
- How does your team work together to accomplish its goals?
- What is the hiring process?
- Considering candidates who stood out in the past, what enabled them to shine?
Finding someone to interview isn’t always easy, but many people who are in senior positions today received help when they were new from those who had entered the field ahead of them, and many are eager to pay it forward. If you can reach out to someone who’s already in your network — perhaps a friend who made the transition ahead of you or someone who attended the same school as you — that’s great! Meetups such as Pie & AI can also help you build your network.
Finally, be polite and professional, and thank the people you’ve interviewed. And when you get a chance, please pay it forward as well and help someone coming up after you. If you receive a request for an informational interview from someone in the DeepLearning.AI community, I hope you’ll lean in to help them take a step up! If you’re interested in learning more about informational interviews, I recommend this article from the UC Berkeley Career Center.
I’ve mentioned a few times the importance of your network and community. People you’ve met, beyond providing valuable information, can play an invaluable role by referring you to potential employers. Stay tuned for more on this topic.
Keep learning!
Andrew
News
AI Regulations Proceed Locally
While the United States doesn’t explicitly regulate AI at the national level, many parts of the country have moved to limit the technology.
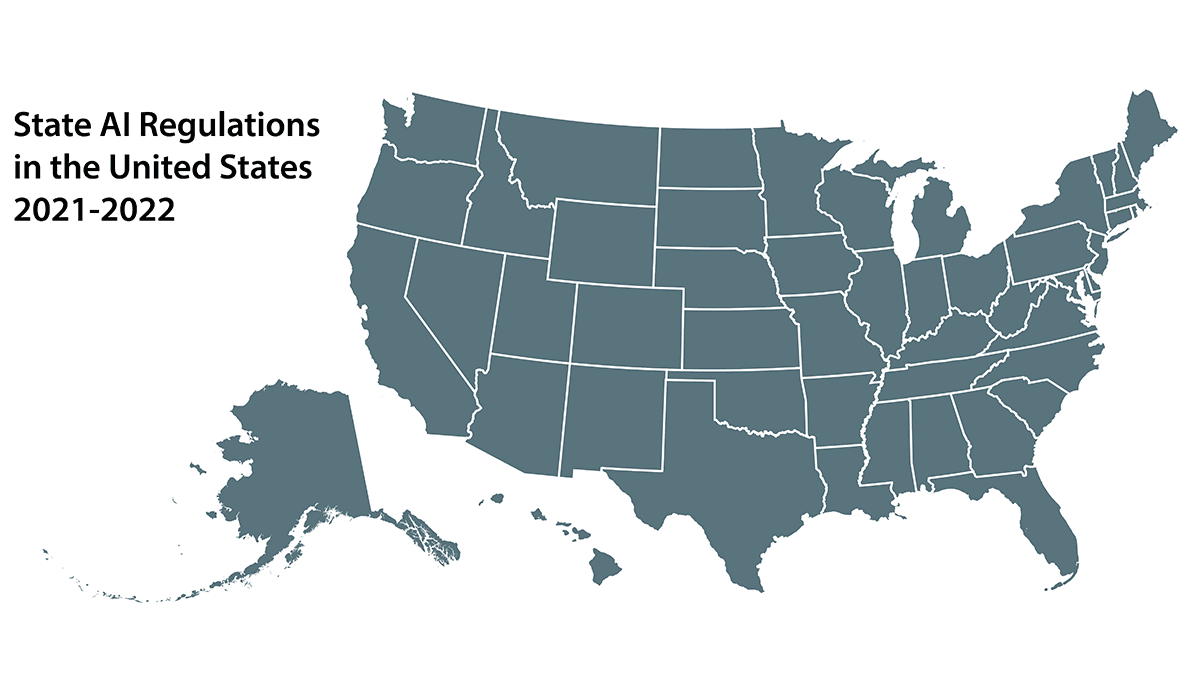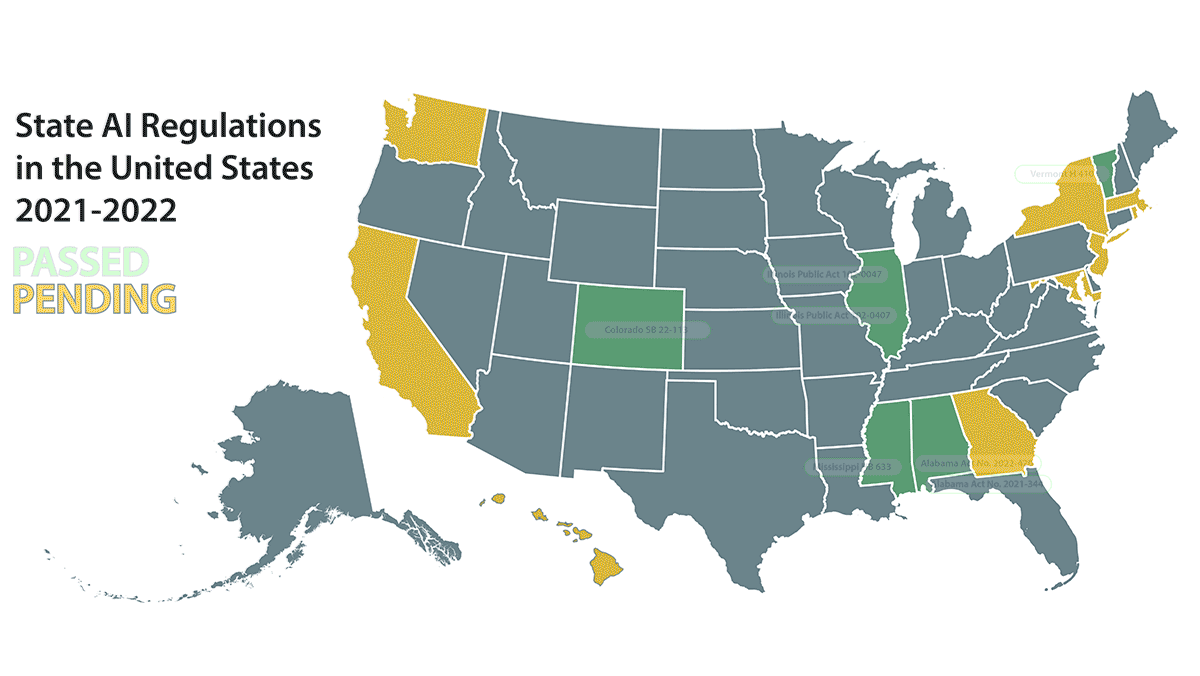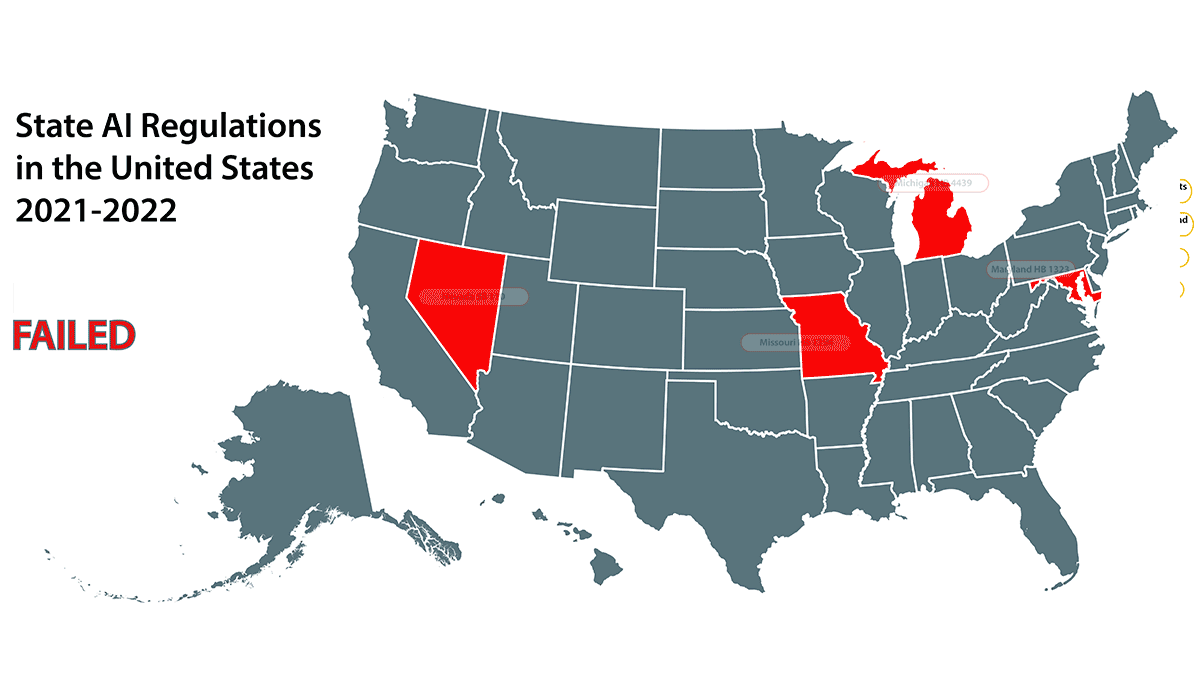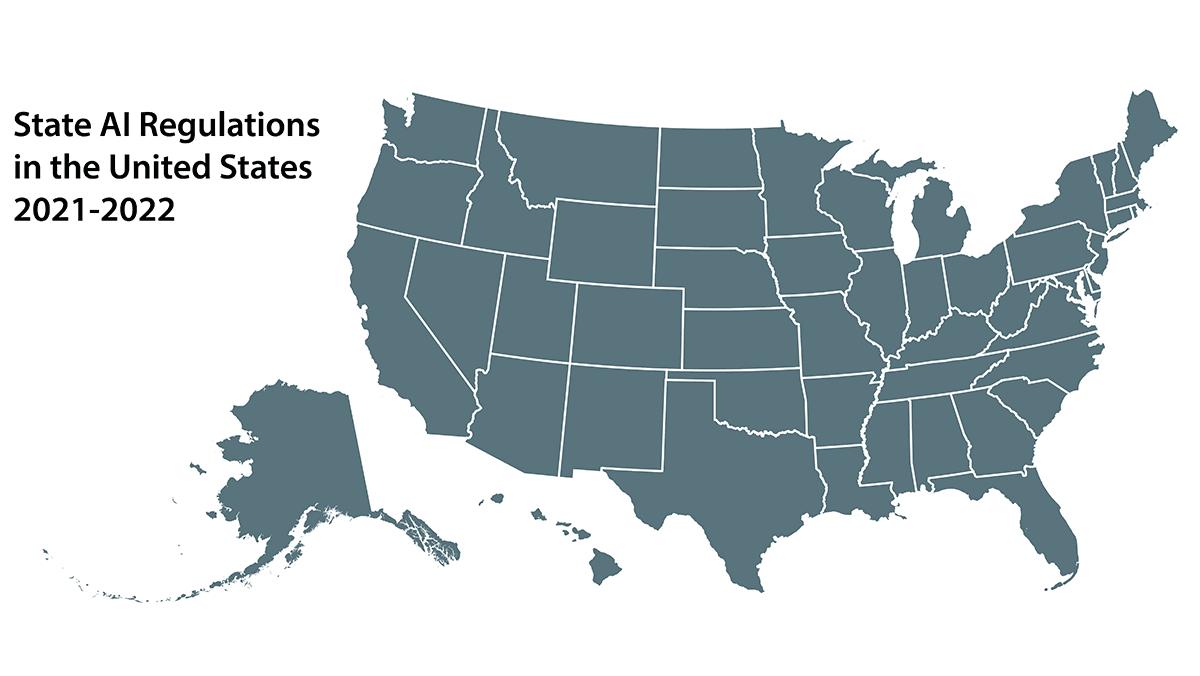
What’s new: The Electronic Privacy Information Center published The State of State AI Policy, a summary of AI-related laws that states and cities considered between January 2021 and August 2022.
Passed: Seven laws were enacted that regulate a variety of AI applications and activities.
- Face recognition: Two states and two cities restricted face recognition. (a) Alabama prohibited law enforcement agencies from using the technology to establish probable cause during a criminal investigation or when trying to make an arrest. (b) Colorado instituted a similar law that bars state and local government agencies from using it to identify, surveil, or track individuals without a warrant. The same state banned face recognition from all public schools and mandated that government agencies that seek to use the technology provide training and file regular reports. (c) The city of Baltimore, Maryland banned all private and non-police government officials from using face recognition within city limits. (d) Bellingham, Washington, prohibited law enforcement from using face recognition or predictive policing tools.
- Automated decision-making: Two states and one city limited automated hiring. (a ) Vermont established an agency to review state uses of AI. (b) Illinois employers that use automated hiring software are required to report the race and ethnicity of both successful and unsuccessful applicants. (c) Employers in New York City that use such tools are required to notify job applicants and audit such tools before using them.
- AI education: Mississippi passed a law directing the state’s education department to produce an artificial intelligence and machine learning curriculum for public schools.
- AI business development: Two states established government oversight of the technology. (a) Alabama established a council to advise lawmakers on the use and development of automation within the state. (b) Illinois formed a task force to forecast the impact of AI and other technologies on employment, wages, and skill requirements for jobs in the state.
Pending: Thirteen more laws are currently in progress in nine states and Washington DC. Bills would establish advisory bodies to study the impacts of AI in California, Georgia, Maryland, Massachusetts, New Jersey, New York, and Rhode Island. California lawmakers propose mandating processes to minimize algorithmic bias. Hawaii lawmakers propose a tax credit for AI businesses.
Why it matters: AI increasingly affects U.S. society, sometimes in alarming ways (and at the expense of public trust). Yet it remains largely unregulated at the national level. State and local legislation are filling the gap. However, a patchwork legal landscape could be a headache for companies that aim to do business in multiple states.
We’re thinking: A yawning gap separates leaders in technology and government. Many tech executives hold the stereotype that politicians don't understand technology. Meanwhile, politicians widely regard tech executives as being hostile to the government and primarily out to make a buck. It will take effort on both sides to overcome these stereotypes and forge a shared understanding that leads to better regulations as well as better AI.

Taming Spurious Correlations
When a neural network learns image labels, it may confuse a background item for the labeled object. For example, it may learn to associate the label “camel” with desert sand and then classify a cow on a beach as a camel. New research has trained networks to avoid such mistakes.
What’s new: A team at Stanford and Northeastern University led by Michael Zhang proposed Correct-N-Contrast (CNC), a training method that makes neural networks more robust to spurious correlations, in which features and labels are associated but not causally related.
Key insight: A neural network likely has learned a spurious correlation when it produces dissimilar representations of two images with the same label. When learning representations of two images of a cow, for example, the error may manifest as a representation of a grassy field in one image and a representation of a beach in the other. A contrastive loss function can help a neural network avoid such errors by encouraging it to learn similar representations for similar objects against different backgrounds.
How it works: The authors trained models to classify examples and identified examples the models got wrong, possibly owing to spurious correlations. Then they trained a second neural network to classify them correctly using a contrastive loss function.
- The authors trained or fine-tuned a neural network to classify a dataset. They used a pretrained LeNet to classify handwritten numbers, a ResNet-50 to classify celebrities’ hair color in CelebA and classify water birds versus land birds, and BERT to recognize toxic social media comments.
- They trained or fine-tuned a second neural network using a weighted sum of two loss terms. One term encouraged the network to classify examples correctly. The second, contrastive term pushed together representations of the same labeled object but with dissimilar network output and pulled apart representations of objects with different labels that resulted in similar output.
Results: The authors evaluated their models’ accuracies on groups of examples known to be difficult to classify. Their approach outperformed EIIL, which first trains a model to infer related groups of examples and then trains a second model to classify examples using the group IDs, both on average and on individual tasks. For instance, the ResNet-50 trained on CelebA with CNC achieved 88.8 percent accuracy, while training with EIIL achieved 81.7 percent accuracy. Across all tasks, the authors’ approach achieved 80.9 percent average accuracy while EIIL achieved 74.7 percent average accuracy.
Yes, but: Group DRO, which provides additional information during training such as a description of the background of an image or the gender of a depicted person, achieved 81.8 percent average accuracy.
Why it matters: Previous approaches to managing spurious correlations tend to expand training datasets to capture more variability in data. This work actively guides models away from representing features that reduce classification accuracy.
We’re thinking: A self-driving car must detect a cow (or a person or another vehicle) whether it stands on a meadow, a beach, or pavement.
A MESSAGE FROM DEEPLEARNING.AI

Nektarios Kalogridis was a software developer in finance. He saw the growing impact of AI on the industry, so he took Andrew Ng’s Machine Learning course. Today, he’s a senior algorithmic trading developer at one of the world’s largest banks. Enroll in the Machine Learning Specialization!

One Cool Robot
Autonomous robots are restocking the refrigerated sections in corner stores.
What’s new: FamilyMart, a chain of Japanese convenience stores, plans to employ robots to fill shelves with beverage bottles at 300 locations.
How it works: The TX SCAR from Tokyo-based firm Telexistence includes an arm and camera. It shuttles along a rail in between stock shelves and the rear of a customer-facing refrigerator, moving up to 1,000 containers a day.
- The arm is controlled by a program that scans customer-facing shelves and determines whether an item needs to be restocked. If so, the software directs the arm to grab bottles or cans and move them appropriately. It also analyzes sales patterns — for instance, which items tend to sell at what times of day or times of year — and adapts its behavior accordingly.
- If a robot encounters an unfamiliar item or obstruction, a remote human operator can pilot it via a virtual reality headset.
- FamilyMart and Telexistence began testing the system at a Tokyo store in November 2021.
Behind the news: FamilyMart also operates grab-and-go stores in which AI models recognize items as shoppers put them into carts and ring up sales automatically as they exit. Amazon has similar stores in the United Kingdom and United States.
Why it matters: Japan faces an aging workforce with no end in sight. People over 65 years old make up around a quarter of the population, which is expected to have the world’s highest average age for decades. Embracing robot labor is one solution, along with matching older workers with appropriate jobs and extending the retirement age.
We’re thinking: From making french fries to restocking shelves, the jobs that once were rites of passage for young adults are increasingly automated. Will the next wave of after-school gigs involve debugging code and greasing servos?

What a Molecule’s Structure Reveals
Two molecules can contain the same types and numbers of atoms but exhibit distinct properties because their shapes differ. New research improves machine learning representations to distinguish such molecules.
What’s new: Xiaomin Fang, Lihang Liu, and colleagues at Baidu proposed geometry-enhanced molecular representation learning (GEM), an architecture and training method that classifies molecules and estimates their properties.
Key insight: Chemists have used graph neural networks (GNNs) to analyze molecules based on their atomic ingredients and the types of bonds between the atoms. However, these models weren’t trained on structural information, which plays a key role in determining a molecule’s behavior. They can be improved by training on structural features such as the distances between atoms and angles formed by their bonds.
GNN basics: A GNN processes datasets in the form of graphs, which consist of nodes connected by edges. For example, a graph might depict customers and products as nodes and purchases as edges. This work used a vanilla neural network to update the representation of each node based on the representations of neighboring nodes and edges.
How it works: The authors trained a modified GNN on 18 million molecules whose properties were unlabeled to estimate structural attributes of molecules. They fine-tuned it to find molecular properties.
- The model processed two graphs in sequence: a bond-angle graph in which nodes were bonds and edges were bond angles and an atom-bond graph in which nodes were atoms and edges were bonds between them.
- First it updated the representations of each bond in the bond-angle graph. Having learned the bond representations, it used them to represent bonds in the atom-bond graph and updated the representations of each atom there.
- Using these representations, separate vanilla neural networks learned to estimate bond lengths, bond angles, distances between each atom in the molecule, and molecular fingerprints (bit-strings that encode which atoms are connected).
- The authors fine-tuned the system on 15 tasks in a benchmark of molecular properties such as classifying toxicity and estimating properties for water solubility.
Results: GEM achieved state-of-the-art results on 14 tasks, surpassing GROVER, a transformer-GNN hybrid that learns to classify a molecule’s connected atoms and bond types but not structural attributes. For example, when estimating properties that are important for solubility in water, it achieved 1.9 root mean square error, while the large version of GROVER achieved 2.3 root mean squared error. On average, GEM outperformed GROVER on regression tasks by 8.8 percent and by 4.7 percent on classification tasks.
Why it matters: This work enabled a GNN to apply representations it learned from one graph to another — a promising approach for tasks that involve overlapping but distinct inputs.
We’re thinking: How can you trust information about atoms? They make up everything!