
Dear friends,
Machine learning engineers routinely use Jupyter Notebooks for developing and experimenting with code. They’re a regular feature in DeepLearning.AI’s courses. But there’s another use of Jupyter Notebooks that I think is under-appreciated: communicating concepts to others.
For example, once I was experimenting with a new way to build a neural network in which the input features were engineered a specific way, and I wanted to explain my ideas to colleagues. Writing a text document would have been a reasonable approach, but using a Jupyter Notebook allowed me to format text using its Markdown feature and include an implementation of the idea in code. That way, readers could execute it, experiment with hyperparameters, and add further code to delve more deeply into what the algorithm was doing.
When we use a Jupyter Notebook to build a piece of code, the ultimate reader is a computer, whose job is to faithfully execute the program. But when using a Notebook to communicate with people, the goal is to convey an idea and illustrate it with code. The interactive nature of notebooks — which lets you run code snippets to generate outputs, and also lets you add formatted text, equations, graphs, and images — makes this a much richer medium than merely writing code that contains comments.
A team I work with recently used a Jupyter Notebook to model their revenue projections. While other tools such as spreadsheets could have served a similar purpose, a Notebook can include prose that articulates underlying assumptions such as the rates of sales growth and customer churn. Further, it invites readers to play with these parameters to deepen their understanding of how they affect the business.
I write and send a lot of documents and enjoy written communication. But if you’re trying to explain a scientific or mathematical equation, simulating a business or other system, or presenting your analysis of data, consider sending your audience a Jupyter Notebook. This flexible tool even makes a great alternative to a slide deck. It’s great not only for writing code to communicate with your computer but also for crafting a story to communicate with other people.
Keep learning!
Andrew
News
The Hammer Drops
The U.S. government punished an app vendor for building an algorithm based on ill-gotten data.
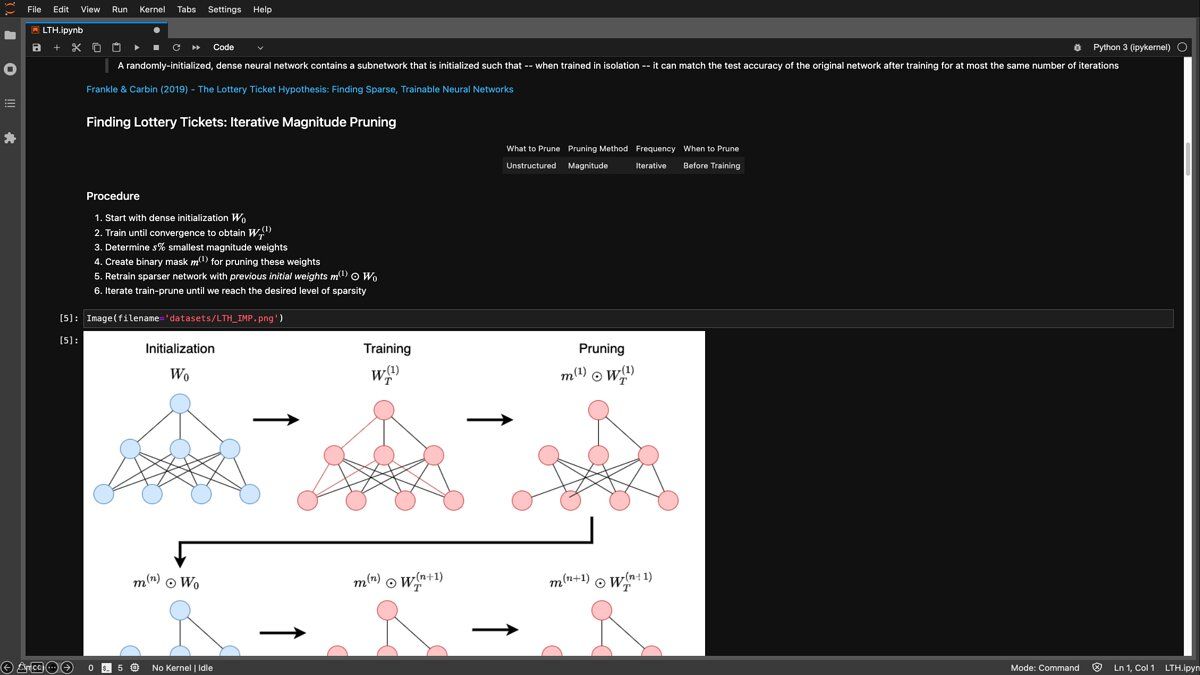
What’s new: The Federal Trade Commission (FTC), the U.S. agency in charge of consumer protection, ruled that an app developed by WW International (formerly Weight Watchers) violated data-collection laws. In a settlement, the company agreed to pay a fine, destroy data, and deactivate the app, the tech-news website Protocol reported.
How it works: The FTC is empowered to take action against companies that engage in deceptive business practices. Combined with other laws that protect specific classes of people — in this case, children — the agency exercised its authority to combat misuse of data.
- WW International launched Kurbo in 2019 in a bid to help children between ages 8 and 17 develop healthy eating habits.
- The app collected personal information such as age, gender, height, weight, and lifestyle choices. Upon registering, users were asked to identify themselves as either an adult or signing up with an adult’s permission. However, the app didn’t verify this input.
- The lack of verification violated a 1998 law that restricts collecting data from children younger than 13 without permission from a parent or guardian.
- The app already had drawn criticism from parents and healthcare professionals who decried its potential to encourage eating disorders.
Behind the news: The FTC has punished companies for using improperly collected data twice before. In 2021, it forced the developer of photo-sharing app Everalbum to destroy models it developed using images uploaded by users who hadn’t consented to face recognition. Two years earlier, it demanded that Cambridge Analytica, a UK political consultancy, destroy data it had collected illegally from Facebook users.
Why it matters: The U.S. lacks comprehensive national privacy laws that protect consumer data, but that doesn’t mean it won’t act against companies that abuse personal data. The FTC can prosecute algorithmic abuse based on several interrelated laws, and lately it has done so with increasing frequency.
We’re thinking: If the public is to trust the AI community, it’s necessary to respect privacy and obtain permission for any data that goes into building a model. If the FTC’s willingness to prosecute developers of unruly algorithms provides further incentive, so be it.

Animal Animations From Video
A video game studio is looking to machine learning to cut the effort and expense of populating three-dimensional scenes with animated animals.
What’s new: Ubisoft showed off ZooBuilder, a pipeline of machine learning tools that converts videos of animals into animations. The system is a prototype and hasn’t been used in any finished games.
How it works: In the absence of an expensive dataset that depicts animals in motion, researchers at Ubisoft China and elsewhere generated synthetic training data from the company’s existing keyframe animations of animals. They described the system in an earlier paper.
- Given a rendered keyframe animation, the team used virtual cameras to capture the animal’s image from a variety of perspectives. They composited photorealistic backgrounds behind the animals and augmented the images by flipping, changing contrast, adding noise, and converting color to grayscale.
- For each animation frame and perspective, they extracted 3D coordinates of each of 37 joints and converted them into 2D coordinates. These procedures provided 2D and 3D labels for their dataset.
- They fine-tuned a pretrained OpenPose (which originally was developed for human figures) on the 2D data. Given a 2D image, it learned to extract 2D joint coordinates.
- To track the temporal relationships between connected joints, they fine-tuned a pretrained 2D-to-3D human pose estimator on the extracted 2D data. It learned to map the joints in five consecutive rendered frames to their corresponding 3D coordinates.
- At inference, the system accepts a video of an animal in the wild along with a skeleton (collection of joints), 3D mesh, and skin. It uses a pretrained YOLOv3 object detector to locate animals within bounding boxes and crops the video frames accordingly. OpenPose finds 2D coordinates and Pose_3D translates them into a sequence of 3D coordinates. The system converts the 3D coordinates into an animation file, applies it to the mesh, covers the mesh with skin, and outputs an animation. Human animators refine the result.
Yes, but: ZooBuilder initially was limited to cougars and had trouble tracking them when parts of their bodies were occluded or out of the frame, and when more than one creature was in the frame. Whether Ubisoft has overcome these limitations is not clear.
Behind the news: Machine learning is playing an increasing role in 3D graphics.
- Kinetix offers an internet-based tool that converts uploaded videos of humans in motion into animated 3D models. The company has partnered with Adobe to accept models and animations from Mixamo, which uses machine learning to automate 3D animation.
- Disney researchers used StyleGAN2 to create realistic animated faces.
Why it matters: It can take months of person-hours to animate a 3D creature using the typical keyframe approach. Automated systems like this promise to make animators more productive and could liberate them to focus on portraying in motion the fine points of an animal’s personality.
We’re thinking: There’s face recognition for cows, speech recognition for birds, sentiment analysis for pigs, and now OpenPose for cougars. What will the animals steal from us next?!
A MESSAGE FROM DEEPLEARNING.AI

Learn how to apply machine learning to concrete problems in medicine — including diagnosis, prognosis, and treatment — with the AI for Medicine Specialization! Enroll today

Learning After Overfitting
When a model trains too much, it can overfit, or memorize, the training data, which reduces its ability to analyze similar-but-different inputs. But what if training continues? New work found that overfitting isn’t the end of the line.
What's new: Training relatively small architectures on an algorithmically generated dataset, Alethea Power and colleagues at OpenAI observed that ongoing training leads to an effect they call grokking, in which a transformer’s ability to generalize to novel data emerges well after overfitting.
Key insight: It takes a lot of computation to study how learning progresses over time in models with billions of parameters that train on datasets of millions of examples. It’s equally revealing — and more practical — to study models with hundreds of thousands of parameters that train on thousands of examples. Models on that scale can train through many more steps in far less time.
How it works: The authors trained a set of transformers to classify the solutions to each of 12 two-variable equations, mostly polynomials.
- For each equation, they plugged in the possible values for both variables to find all possible solutions. This yielded roughly 10,000 input-output pairs per expression to be divided between training, test, and validation sets.
- To feed an equation into a transformer, they represented each equation in a form similar to 2*3=6 but substituted each token with a symbol; say, a for 2, m for *, b for 3, q for =, and so on.
- They continued training well beyond the point where training accuracy increased while validation accuracy decreased, a typical indicator for overfitting.
Results: As the models trained, validation accuracy rose, fell, and — after the number of training steps continued to rise by a factor of 1,000 — rose a second time. (In the case of modular division, validation accuracy improved from nearly 5 percent to nearly 100 percent). In experiments using reduced datasets, the authors found that the smaller the training set, the more training was needed to achieve the second increase. For instance, when training on 30 percent as many examples, roughly 45 percent more training steps were required.
Why it matters: Grokking may be the way that double descent, in which a model’s performance improves, worsens, and improves again as the number of parameters or training examples increases, plays out with small models and datasets. That said, this work provides evidence that we've been mistaken about the meaning of overfitting. Models can continue to learn after they overfit and can go on to become quite capable.
We're thinking: The authors discovered this phenomenon in a petri dish. Now we need to find out whether it holds with life-size models and datasets.
Slime Pays
A new machine learning technique is boosting algae as a renewable, carbon-neural source of fuel for airplanes and other vehicles typically powered by fossil fuels.
What’s new: Researchers at Texas A&M and the National Renewable Energy Laboratory developed a system that helps algae farmers keep an algal colony growing at top speed.
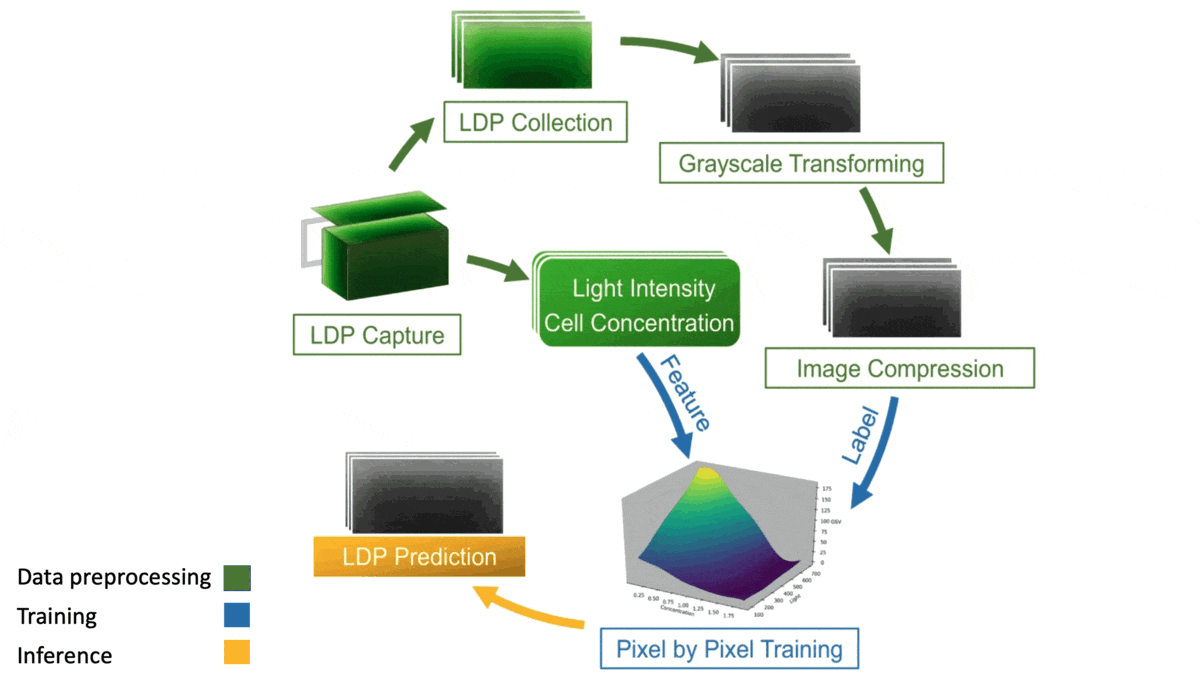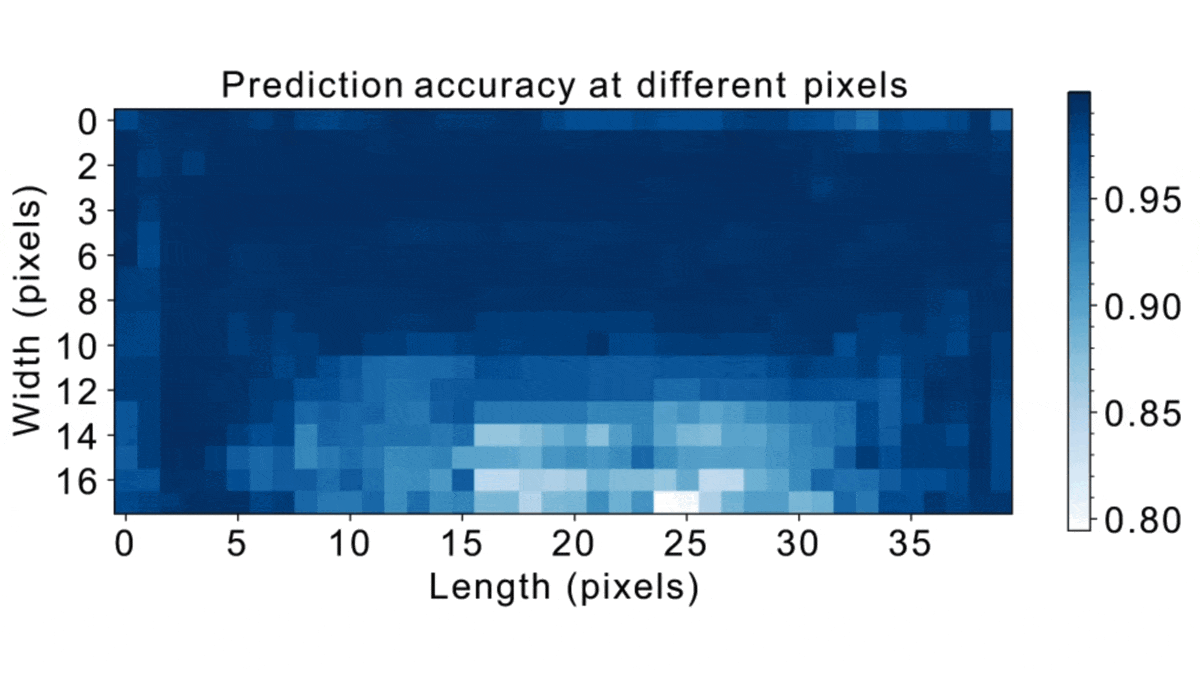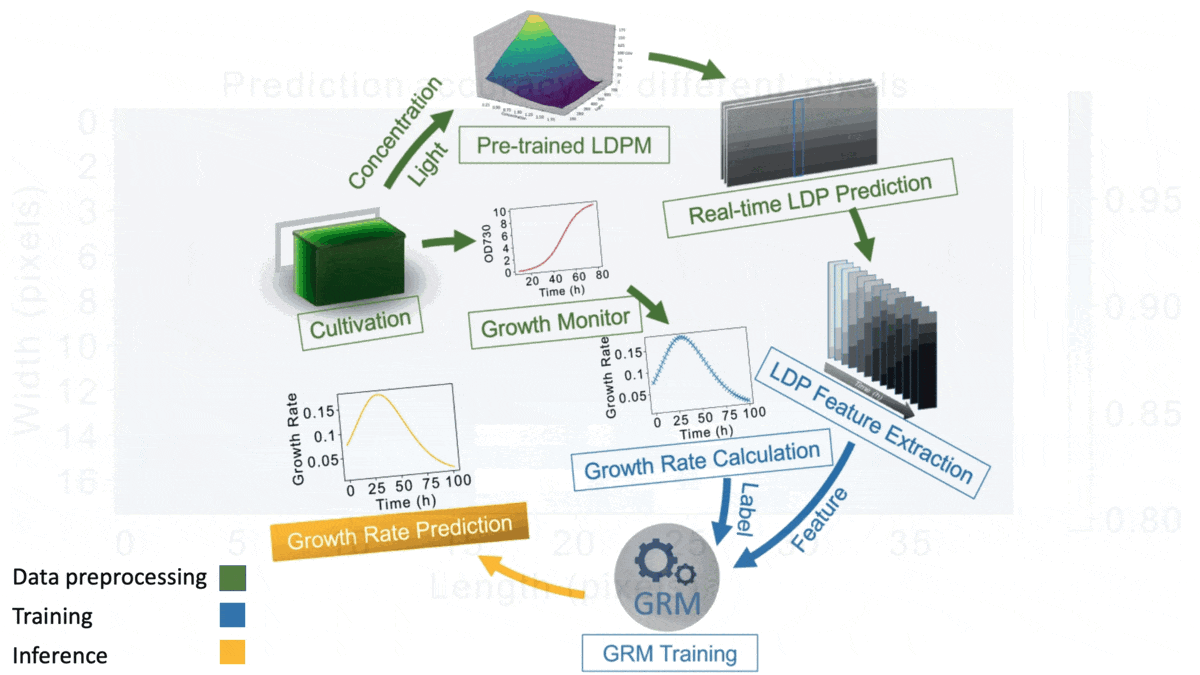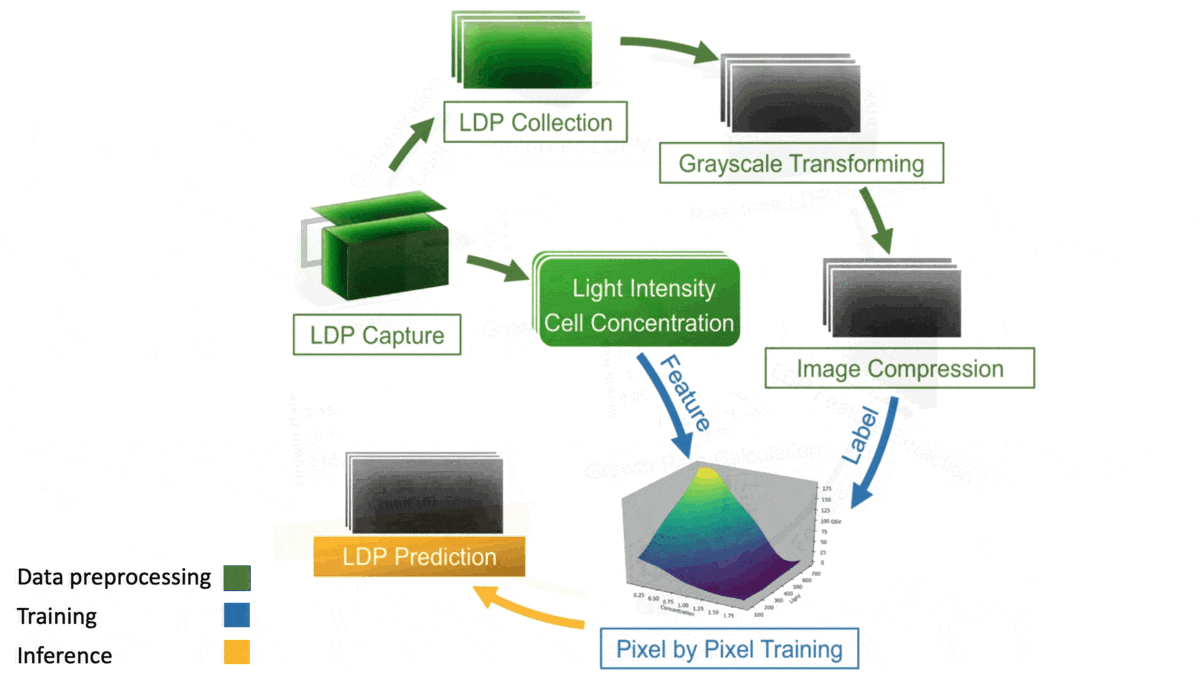
How it works: Individual algae cells shade out their neighbors if they grow too densely, keeping the colony from taking full advantage of available light. The authors built an algal growth simulator that lets farmers know when to harvest algae to optimize the colony’s density for growth. The training data consisted of grayscale images of algal colonies under six lighting conditions and at 23 intervals over time. Each example included its average algal concentration, and each pixel was labeled with the light intensity.
- The authors trained a separate support-vector regression (SVR) model for each pixel to estimate the light intensity.
- They further labeled each pixel with the SVR’s estimated light intensity and used the relabeled images to train a random forest to predict the average growth rate.
- At inference, these techniques combined to predict algal growth. Given a picture of a colony and its initial algal concentration, the SVRs estimated light intensities per pixel, and the random forest used the estimates to determine how the algae would grow.
Results: The authors found that growth rates across all lighting conditions were at their highest when pixels darkened by algal growth accounted for between 43 percent and 65 percent of an image. They used their system to determine when to harvest indoor and outdoor algae farms. The outdoor farm produced 43.3 grams of biomass per day, the indoor pond 48.1 grams per day. A commercial operation using the authors’ method would produce a biofuel sale price of $281 per ton. That’s comparable to the $260-per-ton price of ethanol derived from corn, which requires expensive processing that algae doesn’t.
Behind the news: Depending on the species and processing method, algae can be turned into a variety of fuel products including diesel, alcohol, jet fuel, gasoline, hydrogen, and methane. It was first proposed as a source of fuel in the 1950s and has been a growing area of sustainable-energy research since the 1970s. However, algal fuels have made little commercial headway due largely to low yields and the cost of processing harvested biomass.
Why it matters: Converting algae into fuel is attractive because the biomass is renewable, absorbs as much atmospheric carbon as it emits, and works with internal-combustion engines. To date, it hasn’t scaled well. If machine learning can make it more productive, it could revitalize this approach to alternative energy.
We’re thinking: Between this work, Fraunhofer Institute’s similar algal growth system, and Hypergiant’s AI-powered algae bioreactor, machine learning applications for algae are blooming!