
Dear friends,
Say you’ve trained a learning algorithm and found that it works well on many examples but performs poorly on a particular subset, or slice, of the data. What can you do?
It is hard to tweak a learning algorithm’s code to improve its performance specifically on one slice of the data. Often, tuning an algorithm changes its performance on everything.
But you can engineer the training and test data for that subset. A data-centric approach to AI development is a powerful tool to improve model performance on one slice, hopefully without degrading its performance on other portions of the data.
The need to improve performance on one slice is a common one. For example:
- A loan-making algorithm has high average accuracy but makes biased decisions on applications from one minority group. How can you fix the performance to provide loans more fairly — especially if membership in that group is not an explicit feature?
- A speech recognition algorithm is accurate for many users but inaccurate when car noise is in the background. How can you improve its performance to recognize words spoken in a moving vehicle?
- A robot is good at grasping many types of household objects, except for monochromatic ones that are uniform in color and texture. How can you enable the robot to fetch that red rubber ball?
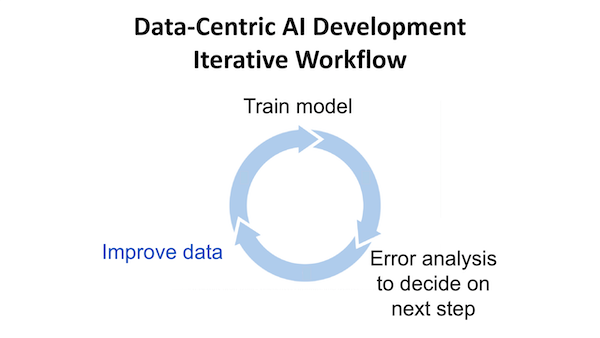
Improving the data is sometimes misunderstood as a pre-processing step performed prior to engineering a machine learning algorithm. Instead, it should be a key step in the iterative loop of model development, in which data is engineered systematically to address problems identified through error analysis.
Specifically, if error analysis identifies a slice of data that yields subpar performance, you might improve the data by:
- Improving the label quality for that slice. For example, you can check if labelers consistently assign the same label y to the same input x and, if not, provide clearer labeling instructions to improve consistency.
- Using data collection, augmentation, or synthesis to add data to the problematic slice. For example, to improve performance on speech with car noise, you might use data augmentation to generate more data with car noise for the algorithm to learn from.
Rather than applying these techniques to all the data — which would be costly and inefficient — you can focus on improving the label quality (y) and/or getting new training examples (x) in the slice you want to improve. This is a much less costly exercise.
Data-centric AI development is especially powerful in the current era of large neural networks. A decade ago, when models were much smaller, adding data in one place would often hurt performance elsewhere. For example, adding data on monochromatic objects might make it hard for an algorithm to recognize other objects if it doesn’t have enough capacity to recognize both types equally well.
There are situations in which adding data can hurt, but for many unstructured data problems (vision, speech, language), as long as the added data is clean and the learning algorithm is large enough, it's possible to add data in a way that improves performance on one slice without hurting performance on others. You’ll find a more nuanced discussion of this topic here.
I also spoke about using data-centric AI development techniques to reduce bias in learning algorithms during DeepLearning.AI’s panel discussion last week. You can watch a recording here.
Keep learning!
Andrew
News

User Privacy Versus Child Safety
Apple, which has made a point of its commitment to user privacy, announced that it will scan iPhones for evidence of child abuse.
What’s new: The tech giant will include a machine learning model on the device to recognize pornographic images of children stored in the photo library. Privacy advocates said the feature could be used to spy on innocent people.
How it works: When a user uploads a photo from their phone to iCloud, a tool called neural match will scan it for known examples of child pornography.
- Neural match compares an image’s digital signature, called a hash, to those of abusive images previously identified and validated by at least two child-welfare groups. Upon detecting an offending image, the system alerts a human reviewer who may notify law enforcement.
- Security experts worry that Apple could expand neural match to process images shared via its messaging app, providing a backdoor into the chat system’s end-to-end encryption.
- On its website, Apple emphasizes that its technology is designed only to search for images of child sexual abuse. Further, it said it would deny government requests for targeted searches of individual users and for data that doesn’t match the system’s original parameters.
Behind the news: Apple’s CEO Tim Cook has called privacy a “fundamental human right,” and the company boasts that its users have the final say over uses of their data.
- Privacy was a theme of the most recent Apple Worldwide Developers Conference, where the company showcased features that stymie email trackers, hide IP addresses, and identify third-party apps that collect data.
- In 2016, Apple resisted U.S. government requests to unlock an iPhone belonging to a suspected terrorist. A commercial cybersecurity firm ultimately unlocked it.
- Nonetheless, Apple can hand over some user data, particularly information stored in iCloud, in response to a legal warrant.
Why it matters: Apple has been a holdout for privacy amid a tech-industry gold rush for user data. Its decision to budge on this issue suggests an inevitable, broader shift away from protecting individuals and toward making society more safe.
We’re thinking: Child abuse is a global problem, and tech companies including Facebook, Google, Microsoft, and others have banded together to fight it. While we support this effort, we worry about the possibility — perhaps driven by government pressure — that scanning photo libraries could turn into scanning other types of content, and that aim of keeping children safe could veer toward less laudable goals.

Outstanding in the Field
One of the world’s largest makers of farm equipment is doubling down on self-driving tractors.
What’s new: John Deere agreed to pay $250 million for Bear Flag Robotics, a California startup that upgrades conventional tractors for full autonomy.
How it works: Deere has offered GPS-enabled tractor guidance systems that aid a human driver for nearly two decades. Bear Flag has adapted self-driving technology developed by the automotive industry to help tractors roam agricultural fields safely without a driver.
- Tractors equipped with Bear Flag tech navigate using a combination of GPS tracking and sensor data. Lidar, radar, and cameras enable the vehicles to see their surroundings. Actuator systems control steering, braking, and a variety of towed implements.
- The system is adapted for farm driving. For instance, the vision algorithm distinguishes between fallen branches that can be driven over and trees that should be avoided.
- The sensors also gather data on the quality of the soil tilled in the tractor’s wake. The information can help growers fine-tune their use of pesticides, herbicides, and fungicides, resulting in reductions of up to 20 percent, the company said.
The system learns the boundaries of a farmer’s property during an initial drive-through. It also identifies roads, waterways, and other obstacles. It can upload the resulting map to a fleet of tractors for remote control and monitoring.
Behind the news: Deere has been pursuing AI capabilities for several years. In 2017, it acquired Blue River Technology, a California-based startup that makes weed-killing robots. The following year, it launched a program to partner with promising startups including some that use deep learning.
Why it matters: In addition to helping the farmers deal with a long-running labor shortage, AI-driven equipment could help increase their productivity and limit environmental impacts such as pesticide runoff.
We’re thinking: Self-driving cars aren’t yet commonly used on public roads, but the technology appears to be good enough for commercial use in constrained environments like farms.
A MESSAGE FROM DEEPLEARNING.AI

Check out our Practical Data Science Specialization! This series of courses will help you develop the practical skills to deploy data science projects and teach you how to overcome challenges using Amazon SageMaker.
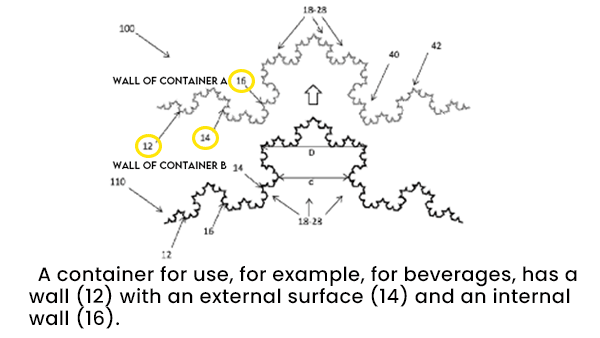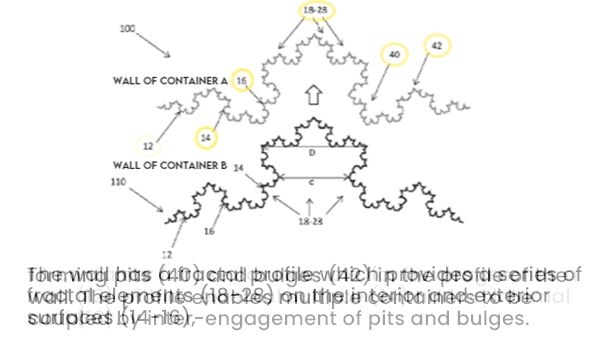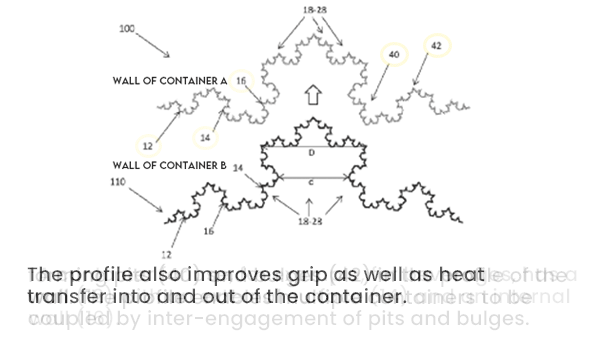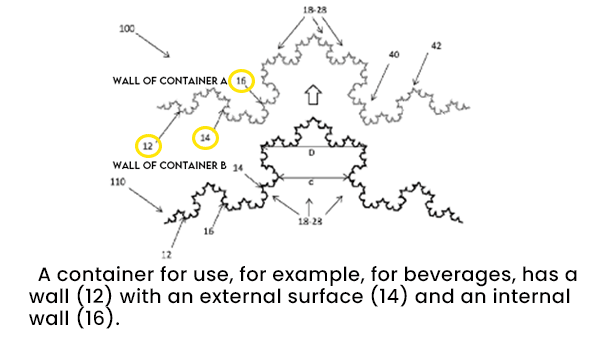
Invented By AI
An algorithm received a patent for its invention.
What’s new: South Africa’s intellectual property office issued a patent that names an AI system as the inventor of a food container with unique properties, IP Watchdog reported.
How it works: South Africa’s Companies and Intellectual Property Commission named Stephen Thaler, who developed the AI system, called Dabus, as the patent owner. Thaler submitted a number of applications to authorities in several countries with help from the Artificial Inventor Project (AIP), an organization of patent attorneys that aims to promote development of algorithms that generate valuable innovations.
- Dabus makes random associations between images, text, and other data. It ranks their novelty by comparing them to databases of existing concepts. When one of these “inventions” exceeds a threshold of novelty, Thaler reviews it, interprets its function, and writes a patent application.
- South Africa’s patent authority did not comment on the award, leading some experts to speculate that it was granted due to an oversight.
- Intellectual property authorities in the U.S., UK, Europe, and Australia rejected AIP’s applications, though an Australian judge recently overturned that country’s initial rejection. The AIP has applications pending in 12 other countries.
Behind the news: South Africa has issued numerous updates to its patent policy in recent years to encourage technological innovation.
Why it matters: This patent could set a significant precedent in the ongoing debate about whether and to what extent an algorithm can be considered the creator of new music, images, and other intellectual properties — a debate with potentially significant financial and legal implications.
We’re thinking: The patent system has been criticized for enabling patent trolls who file or acquire patents for the purpose of litigating rather than advancing a technology or putting a new invention to work. If AI systems can file patents at scale, the whole system might need rethinking to incentivize useful innovation.
Solve RL With This One Weird Trick
The previous state-of-the-art model for playing vintage Atari games took advantage of a number of advances in reinforcement learning (RL). The new champion is a basic RL architecture plus a trick borrowed from image generation.
What’s new: A team led by Florin Gogianu, Tudor Berariu, and colleagues found that spectral normalization, a technique that limits the degree of variation between representations of similar inputs, improved an RL model’s performance more than several recent innovations combined. The team included researchers at Bitdefender, Deepmind, Imperial College London, Technical University of Cluj-Napoca, and University College London.
Key insight: In reinforcement learning, a model observes its environment (say, the Atari game Pong), chooses an action based on its observation (such as moving the paddle), and receives a reward for a desirable outcome (like scoring a point). Learning in this way can be difficult because, as a model selects different actions, its training data (observations and rewards) change. Mutable training data poses a similar problem for generative adversarial networks (GANs), where generator and discriminator networks influence each other even as they themselves change. Spectral normalization has been shown to help GANs learn by moderating these changes. It could also be beneficial in reinforcement learning.
How it works: The authors added spectral normalization to a C51, a convolutional neural network designed for reinforcement learning. The authors trained their model on tasks in the Arcade Learning Environment, a selection of games in which the actions are valid Atari controller movements.
- Given an observation, a C51 predicts a set of distributions of the likely reward for taking each possible action. Then it selects the action that would bring the highest expected reward. During training, it refines its prediction by sampling and comparing predicted rewards to actual rewards.
- Spectral normalization constrains parameter values in network layers, such that the distance between any two predictions is, at most, the distance between the inputs times a constant factor (chosen by the user). The smaller the factor, the more similar a network’s predictions must be. During training, spectral normalization limits the magnitude of a layer’s weights. If an update exceeds that limit, it divides the weights evenly so their magnitude is equal to the limit.
- The authors argue that limiting weight changes is akin to dampening learning rates. They devised an optimization method that lowered the model’s learning rate proportionately to spectral normalization’s limit on the weights. Models trained either way performed nearly equally.
Results: Using spectral normalization on every layer impeded performance, but using it on only the second-to-last layer led the model to achieve a higher median reward. The authors compared their C51 with spectral normalization on the second-to-last layer against Rainbow, the previous state of the art, which outfits a C51 with a variety of RL techniques. In 54 Atari games, the authors’ approach achieved a 248.45 median reward, outperforming Rainbow’s 227.05 median reward.
Why it matters: Applying techniques from one area of machine learning, such as GANs, to a superficially different area, such as RL, can be surprisingly fruitful! In this case, it opens the door to much simpler RL models and perhaps opportunities to improve existing techniques.
We’re thinking: People who have expertise in multiple disciplines can be exceptionally creative, spotting opportunities for cross-fertilization among disparate fields. AI is now big enough to offer a cornucopia of opportunities for such interdisciplinary insight.