
Dear friends,
I’ve heard this conversation in multiple companies:
Machine learning engineer: Look how well I did on the test set!
Business owner: But your ML system doesn’t work. This sucks!
Machine learning engineer: But look how well I did on the test set!
Why do AI projects fail? Last week, I addressed this question at our Pie & AI meetup. We had a spirited discussion with a live audience in 10 cities from London to Berlin, Ghent (Belgium) to Logroño (Spain).

I remain as optimistic as ever about the AI industry, but I also see many AI projects struggle. Unlike software engineering, the process of engineering AI systems is immature, and teams have not yet learned about the most common pitfalls and how to avoid them.
Common pitfalls fall under the headings: robustness, small data, and workflow. You can increase your odds of success by analyzing your AI project in terms of these issues. I’ll flesh out my thoughts on this in coming weeks. Stay tuned.
Keep learning!
Andrew
DeepLearning.ai Exclusive

Breaking Into AI: DevOps to MLE
Daniel Barbosa quit his job managing cloud infrastructure to self-study machine learning full-time. Learn how Daniel landed his first ML job.
News

Cube Controversy
OpenAI trained a five-fingered robotic hand to unscramble the Rubik’s Cube puzzle, bringing both acclaim and criticism.
What’s new: The AI research lab OpenAI trained a mechanical hand to balance, twist, and turn the cube.
How it works: The system learned the manual skills to unscramble the cube using reinforcement learning. It determined the sequence of moves using a pre-existing formula known as Kociemba’s algorithm.
- The researchers designed a simulated environment where a virtual hand could manipulate a virtual cube. The model spent the equivalent of 13,000 years learning to twist simulated cubes.
- They altered the simulation’s parameters from game to game, for instance, changing the cube’s size or mass, or changing the friction between fingers and cube. This procedure, known as automatic domain randomization, eased the robot’s eventual transition from the simulation to the real world: Indeed, it was able to work the cube with two fingers tied together and while wearing a glove, though it hadn’t encountered that condition in the simulation.
- Once trained, the model controlled a physical hand from Shadow Robot Company, modified with LEDs to improve motion capture, rubber pads to improve grip, and more durable components.
Results: The researchers considered an attempt a failure if the hand stalled or dropped the cube. The hand had a 60 percent success rate when the cube needed 15 rotations or fewer to solve the puzzle. That rate dropped to 20 percent when the solution required 26 rotations or more.
Yes, but: Although OpenAI’s report focused mostly on robotic dexterity, critics accused the company of overstating its claim to have taught the robot to solve Rubik’s Cube. Kociemba’s algorithm is more than a decade old and doesn’t involve learning, they pointed out, and the cube included Bluetooth and motion sensors that tracked its segments. Moreover, despite training for virtual millennia, the robot can’t do anything more than manipulate the puzzle.
Behind the news: Robots purpose-built or -coded to unscramble a Rubik’s Cube — no learning involved — are a venerable tradition. Guinness World Records recognizes a system that did the job in 0.637 seconds. Independent engineers later shaved the time to 0.38 seconds. Universal Robots programmed two industrial-bot arms to collaborate on the task.
We’re thinking: OpenAI has a knack for choosing important problems, solving them in elegant ways, and producing impressive results. It also has been criticized for presenting its work in ways that lead the general public to mistake incremental developments for revolutionary progress. It’s important to set realistic expectations even as we push the boundaries of machine intelligence.

Public Access, Private Faces
One of the largest open datasets for training face recognition systems has its roots in a popular photo-sharing service. Companies that have used this data could find themselves liable for millions in legal recompense.
What’s new: Many Flickr users were surprised and upset when reporters informed them their likeness, or that of their children and other family members, was part of a public database used to train face recognition algorithms, according to the New York Times. Such training may violate an Illinois digital privacy law that’s currently being tested in court.
Tracing the data: MegaFace, which depicts 672,000 individuals in nearly 4 million photos, comprises images from Flickr that their creators licensed for commercial use under the Creative Commons intellectual property license.
- Yahoo owned Flickr between 2007 and 2017. In 2014, the web giant released 100 million Flickr photos for training image classifiers.
- The following year, University of Washington researchers started distributing the MegaFace subset.
- Since then, MegaFace has been used to train face recognition software by Amazon, Google, Mitsubishi, SenseTime, Tencent, and others.
Legal jeopardy: In 2008, Illinois passed the Biometric Information Privacy Act, which prevents commercial entities from capturing, purchasing, or otherwise obtaining a private individual’s likeness without the person’s consent. Individuals whose faces have been used without permission are entitled to between $1,000 and $5,000 per use.
Court action: The Illinois law already is fueling a $35 billion class action lawsuit against Facebook for the way it stores and uses data to automatically identify faces in photos.
- Facebook argued that the people pictured have no grounds to sue because its software didn’t cause them financial harm.
- The 9th U.S. Circuit Court overruled the objection, citing an earlier Illinois Supreme Court ruling that invasion of privacy alone is enough to break the law.
- The case will be decided by a jury before the federal court, on a schedule that hasn’t yet been announced.
Why it matters: MegaFace is still available, and at least 300 organizations have used it to train their models, according to a 2016 University of Washington press release. Any group that has used this data to make money is liable under the Illinois law.
We’re thinking: With 50 states in the U.S. and around 200 countries in the world, regulatory mismatches among various jurisdictions seem inevitable. User privacy and data rights are important, and legal requirements must be as clear and coherent as possible to advance the technology in a positive way.
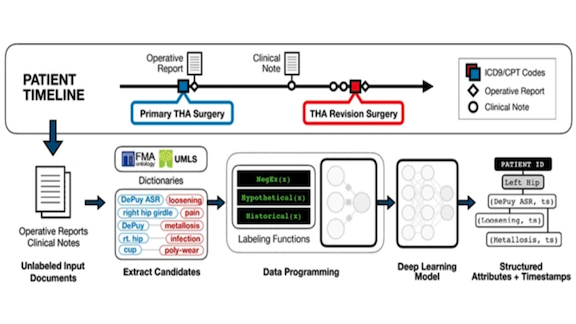
Cracking Open Doctors’ Notes
Weak supervision is the practice of assigning likely labels to unlabeled data using a variety of simple labeling functions. Then supervised methods can be used on top of the now-labeled data. Researchers used this technique to search electronic health records (EHRs) for information squirreled away in unstructured text.
What’s new: Complications from hip replacement surgery tend to be under-reported because they’re recorded in EHRs as notes rather than check-marked in a standard list. Researchers at Stanford used weak supervision to label such notes and then extracted information related to hip implants. Their method brought to light complications that hadn’t been tracked explicitly.
Key insight: Alison Callahan and collaborators divided the problem of finding references to post-surgical issues in notes into two parts: identifying the implant’s make and model, and spotting mentions of pain and complications. This made it possible to use weak supervision to label data separately for each subproblem.
How it works: Snorkel is a framework that provides a modular way to define and combine labeling functions. The model works as follows:
- Domain experts construct labeling functions to find the implant maker and type, mentions of pain and the anatomy affected, and mentions of the implant close to the complication it led to. For instance, a labeling function may spot a pain-related word adjacent to a body part and mark the corresponding sentence as evidence of pain. These functions assign labels for each subproblem in every sentence.
- A probabilistic model (graphical model) learns the relative accuracy of the labeling functions based on mutual overlaps and conflicts of their label assignments on the training data. These metrics are then used to combine labels from each labeling function into a single label for each subproblem in every sentence.
- An LSTM with attention is trained on the newly labeled data to spot complications arising from certain implants and map pain to body parts.
Results: The researchers trained the system on records of about 6,000 hip-replacement patients treated between 1995 and 2014. Learning the relationships between the various labeling functions uncovered twice as many patients facing complications as majority voting on their predictions (61 percent versus 32 percent). Overall, the system made it possible to assess the likelihood that a particular implant would lead to complications.
Why it matters: This analysis could help doctors to match patients with appropriate implants, and help implant manufacturers design their products to minimize bad outcomes.
Takeaway: This approach extracts useful information from EHRs, and it looks as though it would generalize to other text-labeling tasks.
A MESSAGE FROM DEEPLEARNING.AI

How can you use gradient descent to train your model? Learn about other optimization algorithms how in Course 1 of the Deep Learning Specialization.

Robot Tanks on the March
A new generation of battlebots is gaining momentum.
What’s new: The Army is at least two years ahead of schedule in its plan to deploy self-driving (and self-aiming) transports, jeeps, and tanks, said Richard Ross Coffman, director of Next Generation Combat Vehicles, in an interview with Breaking Defense.
Rolling thunder: The NGCV program features three phases of testing for vehicles of graduated firepower and autonomy.
- In Phase One, beginning in early 2020, the Army will test autonomous-driving hard- and software on Vietnam-era armored transports. The vehicles will be remote-controlled by soldiers in M2 Bradley transports.
- In 2021, Phase Two will test the same hardware on custom-built vehicles. Half of these four-wheeled prototypes will be lightweight models (less than 10 tons) and carry machine guns and anti-tank missiles. The other half will be medium-weight (up to 12 tons) and able to carry bigger weaponry.
- Heavyweight autonomous tanks weighing up to 20 tons and mounted with 120mm cannons will roll out in 2023 for Phase Three.
- Coffman envisions systems that enable one human to control a dozen tanks in 2035 or later. Even then, a flesh-and-blood soldier will oversee firing.
Behind the news: The U.S. Army has spent billions on robotic fighting machines that never came to fruition. In 2009, the service cancelled a previous autonomous war-fighting effort, the $20 billion Future Combat Systems program, after six years in development. That program was nixed partly because the technology didn’t progress as quickly as expected and partly due to a shift from warfare to counterterrorism.
Why it matters: Robot vehicles could act as decoys, drawing fire meant for human troops. They could also infiltrate enemy lines and call in artillery strikes, gather information, screen for obstacles, and wade into areas affected by nuclear, chemical, or biological weapons.
What they’re saying: “Anywhere that a soldier is at the highest risk on the battlefield, and we can replace him or her with a robot, that’s what we want to do.” — Richard Ross Coffman, Director, Next Generation Combat Vehicles, U.S. Army.
We’re thinking: How is the Army, which must cope with irregular terrain, intermittent explosions, and the fog of war, ahead of schedule when the automotive industry, navigating smooth surfaces and relatively orderly traffic, has fallen behind its initial projections? The military faces very different problems, some harder to navigate than urban environments, some easier. Its emphasis on remote control also could make a significant difference.
Bottom line: Like many people, we’re unsettled by the combination of AI and fighting machines. We strongly support proposals for an international ban on autonomous weapons.

New Materials Courtesy of Bayes
Would you like an umbrella that fits in your pocket? Researchers used machine learning to invent sturdy but collapsible materials that might lead to such a fantastical object.
What’s new: Researchers at the Netherlands’ Delft University of Technology used a Bayesian model to find arrangements of brittle polymers that are sturdy, lightweight, compressible, and able to spring back to their original shape. The machine learning algorithm made it possible to design and produce materials without conducting the usual trial-and-error physical experiments.
How it works: Principal investigator Miguel Bessa designed a mock-up with two disks connected by flexible poles, or longerons, that fold in a spiral pattern when the dishes are pressed together.
- In a simulator, Bassa assembled 100,000 different materials in structures that mimicked his mock-up.
- Then he used the model to classify the arrangements that fit his criteria, primarily those whose longerons coiled in spiral shapes when compressed and recovered when pressure was released.
- He settled on two designs and built prototype compressible masts at microscopic and human scales.
Results: The microscopic prototype — built for strength — was fully compressible and able to withstand intense pressure without buckling. For the human-scale version, it was important that it spring back into its original shape, which it did even when compressed nearly flat by a machine press.
Why it matters: Scientists working on metamaterials (structural arrangements of existing materials that exhibit characteristics not found in nature) alter material geometries, shapes, sizes, and orientations to produce novel properties. Typically this requires lots of trial and error. Machine learning can curate arrangements likely to have the right properties, enabling researchers to focus on the most promising candidates.
We’re thinking: From materials science to drug design, brute force experimentation still plays a large role in bleeding-edge science. AI-driven screening is beginning to help researchers find shorter routes to Eureka.
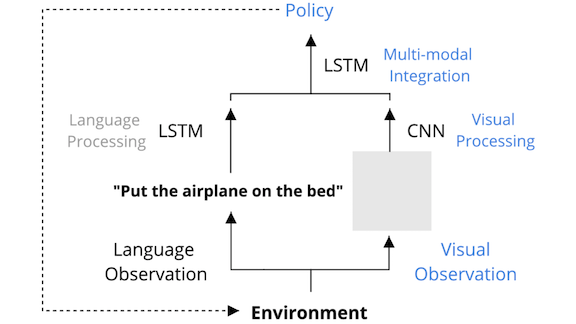
How Neural Networks Generalize
Humans understand the world by abstraction: If you grasp the concept of grabbing a stick, then you’ll also comprehend grabbing a ball. New work explores deep learning agents’ ability to do the same thing — an important aspect of their ability to generalize.
What’s new: Psychologists call this kind of thinking systematic reasoning. Researchers at DeepMind, Stanford, and University College London studied this capability in deep reinforcement learning models trained to interact with an environment and complete a task.
Key insight: Felix Hill and colleagues trained a model to put object 1 on location 1 with an example of that action being performed. At test time, they asked the model to put object 2 on location 2. Object 2 and location 2 weren’t in the training set, so the model’s ability to execute the task would indicate a generalized understanding of putting.
How it works: The model receives a view of the environment along with a task description (an instruction to put or find a given object). The model processes these elements separately, then combines its understanding of each to determine a series of actions to complete the task.
- The model comprises three components (the usual choices for image processing, text understanding, and sequence decisions): A CNN processes the environment view, an LSTM interprets the task description, and the CNN and LSTM outputs merge in a hidden LSTM layer to track progress toward completing the task.
- The model learns to associate various objects with their names by executing put [object] or find [object] tasks.
- The researchers separate objects into test and training sets. Then they train the model to put or lift objects in the training set.
- To measure systematic reasoning, they ask it to lift or put objects in the test set.
Results: The researchers trained copies of the model in simulated 2D and 3D environments. It was over 91 percent successful in lifting novel objects either way. However, success at putting novel objects dropped to about 50 percent in both environments.
Yes, but: Removing the task description and LSTM component didn’t degrade performance much. That is, while words such as put and find may help humans understand how neural networks operate systematically, language apparently isn’t critical to their performance.
Why it matters: Neural networks are able to generalize, but our understanding of how they do it is incomplete. This research offers a way to evaluate the role of systematic reasoning. The results imply that models that reason systematically are more likely to generalize.
Takeaway: The recent run of pretrained language models acquire knowledge that enables them to perform a variety of tasks without retraining from scratch. Understanding systematic reasoning in neural networks could lead to better performance in domains outside of natural language.