
Dear friends,
I’ve seen many new technologies go through a predictable process on their journey from idea to large scale adoption.
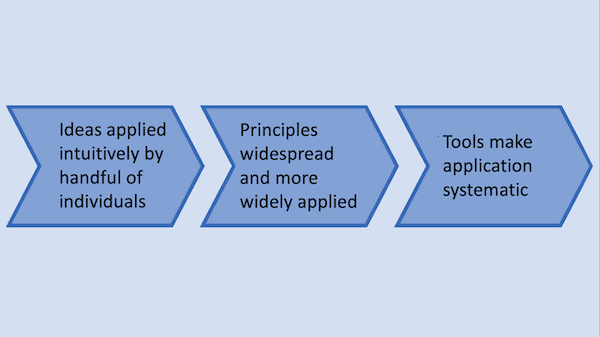
- First, a handful of experts apply their ideas intuitively. For example, 15 years ago, a handful of individuals were building neural networks from scratch in C++. The work was error-prone, and only a small number of people knew how to get such models to work.
- As the ideas become more widespread and publications describe widely applicable principles, more people can participate. In the example above, around five years later, a growing number of people were able to code up deep learning models in C++. It was still error-prone, but knowledge of how to do it became more widespread.
- Eventually, developer tools make it much easier for many people to take part. For instance, frameworks like TensorFlow and PyTorch made building neural networks simpler and more systematic, and implementations were much less likely to fail due to a stray C++ pointer.
The data-centric AI movement is going through such a process. Data-centric AI is the growing discipline of systematically engineering the data needed to build successful AI systems. This contrasts with the model-centric approach, which focuses on inventing and tuning machine learning model architectures while holding the data fixed.
Experienced machine learning practitioners have been engineering data by hand for decades. Many have made learning algorithms work by improving the data — but, even when I was doing it years ago, I didn’t have the language to explain why I did things in a certain way.
Now more and more teams are articulating principles for engineering data. I’m seeing exciting processes for spotting data inconsistencies, accelerating human labeling, applying data augmentation, and crowdsourcing more responsibly. Finally, just as TensorFlow and PyTorch made building neural networks more systematic, new tools are starting to emerge. Landing AI (where I am CEO) is building a platform for computer vision applications, and I expect many more tools to be built by different companies for different applications. They will enable teams to take what once was an ad hoc set of ideas and apply the right process at the right time.
The tech community has gone through this process for code versioning (leading to tools like git) and transfer learning (where GPT-3, which was pre-trained on a massive amount of text, represents an early version of a tool). In less mature areas like reinforcement learning, I believe we’re still developing principles.
If you’re interested in learning more about the principles and tools of data-centric AI, we’re holding a workshop at NeurIPS on December 14, 2021. Dozens of great researchers will present poster sessions and lectures on cutting-edge topics in the field.
Keep learning!
Andrew