
Dear friends,
I recently met an engineer at a large travel agency who had built a fun ML project for sending guests greetings. This was one of the company’s first forays into ML. The project did not generate any revenue, and their managers discouraged them from doing more work on ML.
I couldn’t disagree more with their managers’ decision. Even building a fun project that generates no revenue can be a valuable learning experience for you and the company, and may give you practice on everything from data cleaning to model building to putting a system into production. I’ve seen many people “practice” ML by initially building small, hackathon-like projects, and this allowed them to gain skills and subsequently scale to larger projects.
Learning to identify significant ML opportunities is also a hard and valuable skill, and if you see a giant opportunity for ML, by all means go do that! But if you don’t see such opportunities yet, you should still jump in and get your hands dirty, since that’s how you scale to working on bigger opportunities over time.
Keep learning!
Andrew
News

Wiring the Brain for AI
Chips that connect the human brain to outboard equipment have given paralyzed patients rudimentary control over robotic limbs. Elon Musk envisions brain-computer interfaces that wouldn’t just rehabilitate people but link them to artificial intelligence.
What’s new: Musk took the stage in San Francisco to show off a prototype from Neuralink, his secretive brain-computer interface company.
How it works: Neuralink makes conductive threads that can be woven into the brain using a machine that resembles a cross between a microscope and a sewing machine (shown in the video above).
- The threads are between 4 and 6 micrometers in diameter, half the width of a hair you might find on a newborn’s pillow.
- Each one terminates in 32 electrodes. Threads can be implanted in arrays of 96.
- The connections tap brain currents and route them to and from external devices.
Why it matters: The current industry standard in brain-machine interfaces, the Utah array, bristles with tiny spikes. They can be dangerous as the brain shifts within the skull, and they spur formation of scar tissue that interferes with connections. Neuralink claims its threads will reach more neurons, deeper in the brain, without causing damage or scarring.
What’s next: Musk hopes to put the system in people suffering from paralysis by the end of 2020.
- The operation entails drilling four holes, 8 millimeters wide, in the skull.
- Three devices would be threaded in the brain’s motor area for control signals, and another in the somatosensory region for feedback.
- If the company receives FDA approval to treat brain-related conditions, non-paralyzed people could follow, presumably lured by the prospect of plugging into artificial neural networks.
What he's saying: “Even under a benign AI, we will be left behind. With a high-bandwidth, brain-machine interface, we will have the option to go along for the ride.” — Elon Musk, CEO, Neuralink.
Yes, but: Helping paralyzed individuals is a wonderful mission. But for healthy people, the need for a higher bandwidth brain-machine interface isn't proven. We can already flash text much faster than people can read, and many can touch-type faster than they can organize their thoughts. The bottleneck may be the brain's ability to process information, not the speed at which we can give it input.
We’re thinking: Musk is a showman, but his visions for technology sometimes come true — though not always on his preferred schedule.

Do GANs Dream of Moving Pictures?
Generative adversarial networks make amazingly true-to-life pictures, but their output largely has been limited to still images — until now. Get ready for generated videos.
What’s new: A team from DeepMind offers Dual Video Discriminator GAN, a network that produces eerily lifelike videos out of thin air.
Key insight: DVD-GAN generates both realistic levels of detail and amounts of movement. Aidan Clark, Jeff Donahue, and Karen Simonyan accomplish these twin goals by dedicating a separate adversarial discriminator to each.
How it works: DVD-GAN modifies the state-of-the-art architecture for single images called BigGAN to produce a coherent series of frames. It includes a generator to create frames, a spatial discriminator that makes sure frames look good, and a temporal discriminator that makes sure successive frames go together. As in any GAN, the discriminators attempt to distinguish between real videos and generated videos while the generator tries to fool the discriminators.
- A recurrent layer transforms input noise into shape features to feed the generator. It learns to adjust the features incrementally for each frame, ensuring that the frames follow a naturalistic sequence rather than a succession of random images.
- The spatial discriminator tries to distinguish between real and generated frames by examining their content and structure. It randomly samples only eight frames per video to reduce the computational load.
- The temporal discriminator analyzes the common elements like object positions and appearances from frame to frame. It shrinks image resolution to further economize on computation. The downsampling doesn’t degrade details, since the spatial discriminator scrutinizes them separately.
- The generator is trained adversarially against both discriminators, learning to produce high detail frames and a realistic sequence.
Results: DVD-GAN generates its most realistic results based on the Kinetics dataset of 650,000 brief video clips focusing on human motion. Nonetheless, on the smaller UCF-101 set of action clips, it scores 33 percent higher than the previous state-of-the-art inception score, a measure of generated uniqueness and variety.
Yes, but: The current version maxes out at 4 seconds, and it generates lower-resolution output than conventional GANs. “Generating longer and larger videos is a more challenging modeling problem,” the researchers say.
Why it matters: GANs have led the way to an exciting body of techniques for image synthesis. Extending this to video will open up still more applications.

Africa Rising
Africa isn’t known as a tech hub, but the continent’s embrace of AI is putting it in the spotlight.
What’s happening: African researchers lately have turned to AI to tackle everything from crop failure to bureaucratic red tape. A story in MIT Technology Review details how global AI companies are fostering homegrown talent to take on local challenges:
- Google AI's lab in Accra, Ghana, is expanding the company’s Translate service to accommodate Africa’s roughly 2,000 spoken languages.
- Google researchers also developed an AI-powered smartphone app to help farmers in rural Tanzania diagnose diseased crops.
- IBM Research in Johannesburg, South Africa, trained a model to label hospital pathology reports, cutting the time it took to process data on cancer rates.
- The International Conference on Learning Representations will host its 2020 conference in Addis Ababa, Ethiopia.
Behind the news: Africa's AI community draws on local roots. Data Science Africa began in 2013 as a hub for machine learning experts across the continent to connect, share data, and encourage research. Another group, Deep Learning Indaba, hosts annual TED-like conferences to spread the growth.
Why it matters: Africa holds 54 countries and more than a billion inhabitants with unique challenges. Homegrown experts with local knowledge seem more likely than outsiders to apply AI effectively to these issues. In any case, AI needs talent centers worldwide to achieve its promise.
We’re thinking: We love Silicon Valley, but we're also rooting for the Great Rift Valley.
A MESSAGE FROM DEEPLEARNING.AI

Object detection, art generation, and face recognition are based on convolutional neural networks. But how do you build a CNN? Learn techniques like pooling and convolutions in Course 4 of the Deep Learning Specialization.
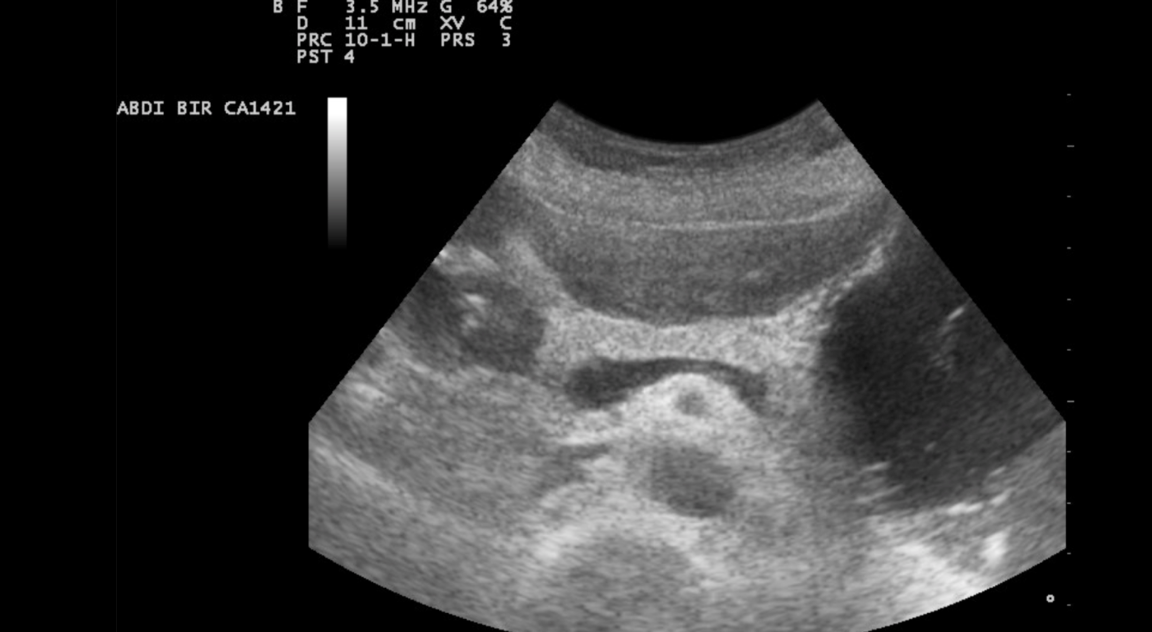
Closing in On Cancer
For all the research attention paid to cancer, there’s still no foolproof way to catch it early. Now AI is homing in on tumors that doctors previously missed.
What's new: Researchers at Johns Hopkins University developed CompCyst, a machine learning model capable of diagnosing early-stage pancreatic cancer better than previous methods.
How it works: The system interprets several data types to recognize precursors to pancreatic cancer.
- The model bases its predictions on the patient’s symptoms, genetic factors, ultrasound images, and fluid taken from the pancreas.
- It was trained on data from 800 patients who had already been treated by Johns Hopkins and had their tumors analyzed after removal.
- The model cuts the misdiagnoses between 60 and 74 percent, depending on the cyst type.
Behind the news: 800,000 Americans are diagnosed with pancreatic cysts annually, but only a small fraction of those will develop a cancerous tumor. Because the pancreas is buried deep in the body, it’s often impossible to tell tiny, pre-cancerous cysts from benign lumps. Fear drives a lot of these patients to pursue very aggressive treatments.
Why it matters: About 95 percent of people diagnosed with pancreatic cancer die from it. One reason is that most patients are diagnosed very late in the disease’s progress. On the other hand, up to 5 percent of patients die from the most common pancreatic surgery, so it’s not safe to be overly cautious, either. In either case, better diagnostics could save many lives.
We’re thinking: When it comes to many cancers, early intervention can either save a life or disrupt one that wasn’t in danger. If the FDA clears CompCyst for new patients, it could open the door to a slew of similar models that make a cancer diagnosis less of a gamble.
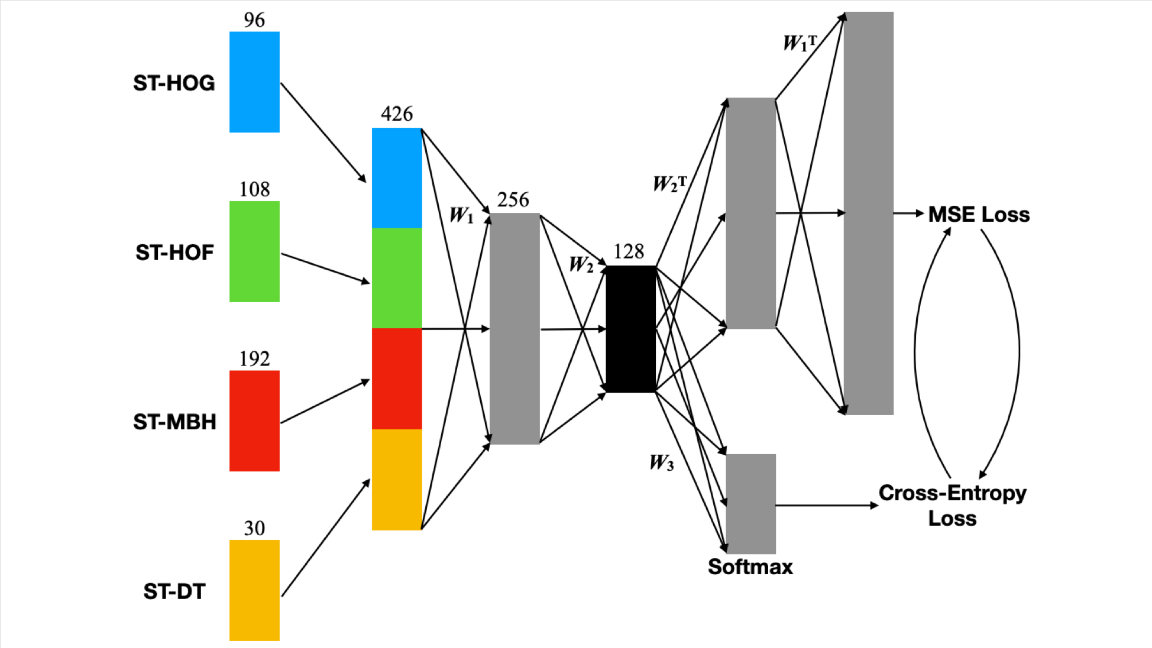
Who Robowatches the Robowatchmen?
Do security cameras make your local bank or convenience store safer? These devices monitor countless locations around the clock, but it takes people watching to evaluate their output — an expensive, exhausting, and error-prone solution. Researchers at iCetana and the University of Western Australia took a step toward detecting critical events without humans in the loop.
What's new: Lei Wang, Du Q. Huynh, and Moussa Reda Mansour developed a lightweight architecture (one that can be trained on a MacBook Pro in half a day!) that differentiates between human motion and background movement like trees swaying, rain falling, and camera shaking in videos of outdoor scenes.
Key insight: Features belonging to the same class flock together in multi-dimensional vector space, yet typical methods of reducing the number of dimensions can lose this clustering information. The authors proposed a novel training procedure that shrinks dimensionality without interfering with the ability to group similar classes.
How it works: Loss Switching Fusion Network (LSFNet) fuses the handcrafted features known as dense trajectories, which are commonly used to detect people moving in videos, in a way that retains clustering information. Then it’s simple to distinguish videos that have human motion from those that show rain, trees waving, camera shaking, shifting illumination, and noisy video.
- LSFNet consists of two parts: an autoencoder to fuse dense trajectories and a neural network to classify different kinds of motion. During the first phase of training, the system alternates between optimizing loss functions corresponding to the autoencoder and the neural network.
- In training phase 2, the authors pass the dense trajectories through the pretrained autoencoder to get a 128-dimensional feature vector. This feature vector is reduced in dimension and hashed into a 64 (or lower) dimensional representation.
- During testing, they compare the lower-dimension feature of each test example with that of each training video. Then they find the likelihood that a given example falls into a particular class by soft voting on the K most similar training videos.
Results: Features processed by LSFNet produce visibly better classification compared to those produced by standard autoencoders or PCA. They outperform all state-of-the-art background- and foreground-motion classification techniques.
Why it matters: It’s hard to keep an eye on a half-dozen security-camera screens at once. AI that distinguishes between human activity and innocuous background motions could make video surveillance more effective in real time.
We're thinking: AI-equipped security systems likely will lead to legitimate concerns about privacy. But it may also mean more effective crime detection. AI companies can take the lead by addressing concerns proactively while working to maximize the benefits.