
Dear friends,
My stash of new blank notebooks just arrived in the mail.
I have a weakness for stationery. I always feel that if only I had the perfect pen and notebook, I might have better ideas. (Hasn’t worked so far. :-)

More seriously, though, we know that taking handwritten notes increases retention. If you’re studying an online course or book or listening to a talk, and you want to remember it, take notes by hand. Several studies (e.g., this one) have shown that the process of synthesizing what you’re hearing into handwritten notes causes you to retain better. So even if I doubt I’ll ever refer to my notes, I will often still take them. I hope you will too.
And if you ever find the perfect pen and notebook, let me know!
Keep learning!
Andrew
News

Upping the Ante
Artificial intelligence has bested humanity at chess, Go, even StarCraft II. But those games are played against a single opponent in one sitting. Poker requires neural nets to learn skills like tracking a table full of players and maximizing winnings over many games.
What’s new: Researchers at Facebook and Carnegie Mellon University developed Pluribus, a deep learning model that plays No-Limit Texas Hold 'Em against a table full of players. The model fleeced a dozen professional gamblers over 12 days and 10,000 hands.
How the game is played: Pluribus learned by playing hundreds of thousands of hands against versions of itself.
- Rather than beat its opponents in a single game, the program aims to make the most money over a series of games.
- After each play — check bet, raise, call, or fold — Pluribus predicts how the action will affect the next two or three players’ actions.
- By strategizing only a few moves at a time rather than computing the end-of-game outcome, it economizes compute cycles.
- In the trial, the algorithm figured out how to bluff. It became more predictable; for instance, placing big bets on hands to psych out human players.
A chip and a chair: Pluribus didn’t win every hand, but it did win roughly $1,000 an hour. The researchers didn’t calculate the human players' rate, but the software's accumulation of chips — especially late in the trial — indicates that it maintained a steady advantage.
Behind the news: Ever since IBM Deep Blue’s 1997 chess victory over world champion Garry Kasparov, engineers have used strategy games to hone machine intelligence. In 2015, AlphaGo, developed by Google’s DeepMind, defeated champion Lee Sedol using strategies nobody had ever seen before. DeepMind struck again earlier this year, taking down a string of StarCraft II pros.
Why it matters: Authors Noam Brown and Tuomas Sandholm believe their technology could be useful in negotiations. Poker mirrors a variety of real-world scenarios, especially in business, which typically involves more than two people, each of whom has hidden motives, with stakes that are rarely sum-zero.
Win more, spend less: Pluribus’ winnings at the table are impressive, but so are its savings at the server. The model was trained using an off-the-shelf laptop with 512 gigabytes of memory. The authors estimate the training cost using cloud computing at around $144. Compare that with the $10,000-plus it can take to train a state-of-the-art language model.
We’re thinking: Pluribus proves that lightweight models are capable of heavy-duty decision making. This could be a boon for resource-strapped developers — and a bane for online gamblers.
The GAN Reveals Its Knowledge
Generative adversarial networks clearly learn to extract meaningful information about images. After all, they dream up pictures that, to human eyes, can be indistinguishable from photos. Researchers at DeepMind tapped that power, building a GAN that generates feature vectors from images.
What’s new: Jeff Donahue and Karen Simonyan adapted the state-of-the-art BigGAN image synthesizer for representation learning. They modified its discriminator, which learns to differentiate between artificially generated images and training images, and added an encoder network from the unrelated model BiGAN. The new network, dubbed BigBiGAN, not only generates superb images but also learns feature vectors that help existing image recognition networks do a better job.
Key insight: An encoder coupled with a powerful generator makes an effective representation learner.
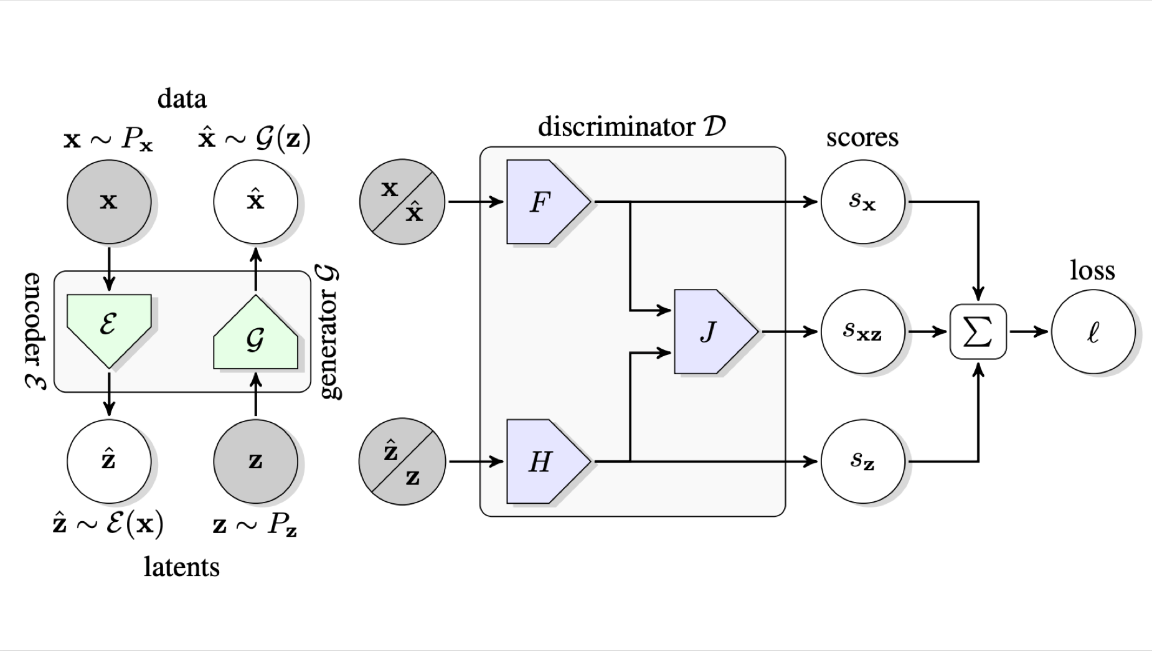
How it works: BigBiGAN consists of three main components: generator, encoder, and discriminator.
- The generator learns to create an image from noise sampled from a learned distribution. Its goal is to generate an image realistic enough to fool the discriminator.
- Working in parallel with the generator, the encoder learns a mapping from an input image to its feature vector through a neural network such as ResNet-50.
- The discriminator takes in an image and a feature vector from both the generator and encoder. It outputs a single probability score indicating whether or not the discriminator reckons the image is real.
- The discriminator provides other outputs as well: a score dependent on the images and another dependent on their feature vectors. This helps ensure that the network learns the distributions of the images and feature vectors individually, in addition to their joint distribution.
Results: Used by an image classifier via transfer learning, features from BigBiGAN match the best unsupervised representation learning approach in ImageNet classification. Used as an image generator, it sets a new state of the art for inception score (similarity between original images and their generated counterparts) and Fréchet inception distance (difference between the feature maps of original and generated images).
Why it matters: Representation learning with GANs can take advantage of the world’s massive amounts of unlabeled data. BigBiGAN demonstrates that representations learned by GANs are transferable to tasks beyond image generation.
Takeaway: BigBiGAN takes us one step closer to bridging the gap between what models understand and how they can express that understanding to us.
Emotional Intelligence
Nobody wants to sound like a robot over the phone. But maybe a computer can help you bring more humanity to your phone manner.
What’s happening: Cogito makes deep-learning software that coaches customer service representatives through phone calls in real time. The Boston-based startup has raised more than $70 million and sold its technology to at least three dozen call centers across the U.S., according to an article in Time.
Automating empathy: Cogito's software was trained on vocal signals beyond the strictly verbal content of conversation: things like tone, pitch, talking speed, rambling, interruption frequency, and relative length of time spent talking.
- If the software senses a conversation going awry, it offers corrective suggestions on how to communicate more clearly, empathetically, and successfully.
- If a rep is talking too fast and too much, the program prompts them to slow down, finish their thought, and then ask an open-ended question to pass the floor back to the caller.
- The algorithm also detects customer frustration and asks the representative to sympathize and offer advice on how to sound more caring.
Behind the news: In the early 2000s, MIT’s Sandy Pentland began collecting a database of non-linguistic speech features by tapping the cell phones of 100 students and faculty — with their consent, of course. He co-founded Cogito in 2007 and the following year wrote a book, Honest Signals, arguing that nonverbal cues can predict the outcome of a social interaction, perhaps even better than the words themselves. The company built a medical app before pivoting to its current product.
Why it matters: More than a third of call-center employees move on within a year, according to an industry group. That attrition incurs hiring costs. It also affects customers whose problems are handled by inexperienced or burned-out operators. AI-driven coaching can help on both ends, Cogito claims, by training green representatives and mitigating burnout.
Takeaway: AI is developing the capacity to recognize and respond to human emotions. That bodes well in contexts where humans and computers must collaborate under stressful conditions — not just in customer-service scenarios but, say, high-stakes emergency situations.
A MESSAGE FROM DEEPLEARNING.AI
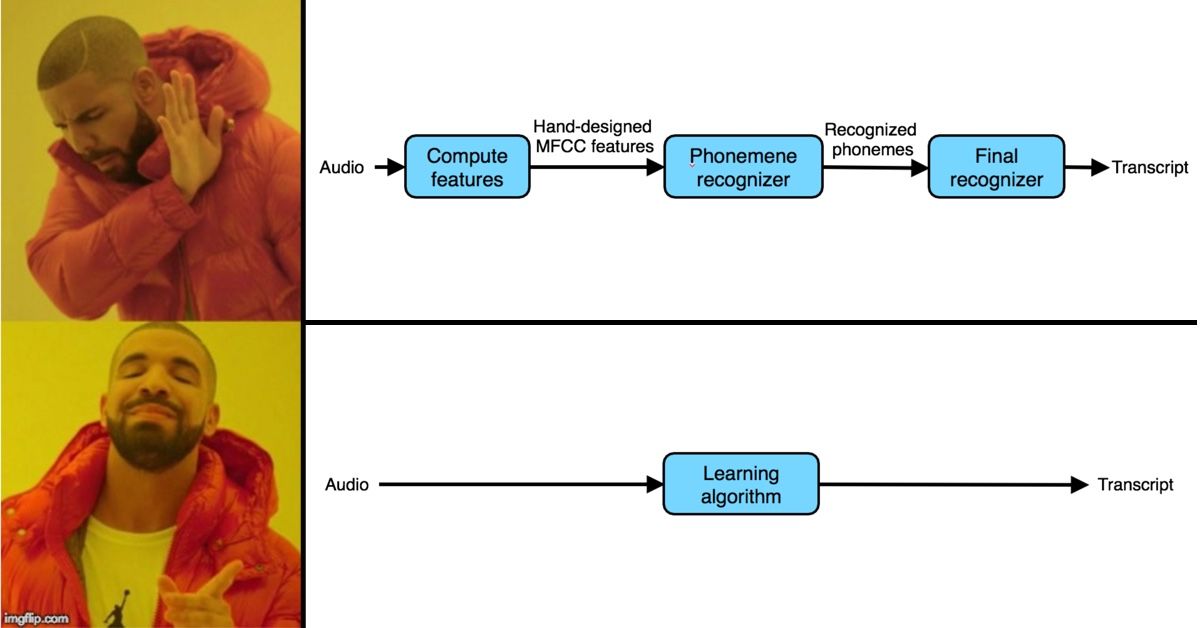
When is an end-to-end algorithm a better choice than a pipeline system? Learn the pros and cons of both in Course 3 of the Deep Learning Specialization.

Excitement Recognition
Video highlights are as integral to sports as endorsement deals for star athletes. Now AI is picking the most exciting moments and compiling them quicker than humans.
What’s new: Since 2017, the All England Lawn Tennis & Croquet Club — host of the world-famous Wimbledon Championships — has used IBM’s Watson technology to choose clips of the best serves, rallies, and points. This year, Big Blue debuted tools that mitigate the system’s bias toward highly animated players, among other things.
Robofan: Watson monitors matches live, grading each moment in terms of excitement. The criteria come from audio and video cues — such as a player pumping a fist or the crowd erupting into cheers — which Watson sorts into classes such as player gestures or crowd reactions. By weighing each moment relative to others in a match, the algorithm recommends which highlights are worth assembling into video summaries. Watson chooses the clips, cuts them together, and passes them to a human editor for review.
Net effect: The new tools are meant to make sure the system treats all players fairly.
- A hometown crowd may cheer more loudly for a highly-ranked athlete, or a crowd suffering under a midday sun may be subdued. So Watson weighs factors like player rank, time of day, and court number.
- The system listens for the distinctive pop of a ball hitting a racket. That way, it can crop clips tightly, eliminating dull moments that drag down a match summary.
Behind the news: More video views mean more eyes on advertisements — not to mention logos visible around the court. Sporting organizations are businesses, and they’re eager to take advantage of anything that helps them capitalize on fan attention.
Why it matters: Watson has had a rough time in its primary field of medicine. Its work at Wimbledon suggests it may have a brighter future in sportscasting. Viewership of the championship’s highlight videos rose dramatically when Watson took over editing duties: The clips garnered 14.4 million more views compared to the year before, an IBM engineer told Computerworld.
We’re thinking: AI has proven its ability to write routine news articles on sports, corporate earnings, and real estate. Now it's gaining skill at video editing. If only it could do something about the Game of Thrones finale . . . .
More Learning From Less Data
Neural networks surpass human abilities in many tasks, with a caveat: Typical supervised learning requires lots of labeled data. New research is pushing back that threshold.
What’s new: Emerging semi-supervised learning methods use a smaller amount of labeled data along with plenty of unlabeled data. Meanwhile, data augmentation multiplies labeled examples by distorting them to create variants. A team effort between Google Brain and Carnegie Mellon University combines the two approaches. Their approach, Unsupervised Data Augmentation, turns in excellent performance in both image recognition and language generation tasks.
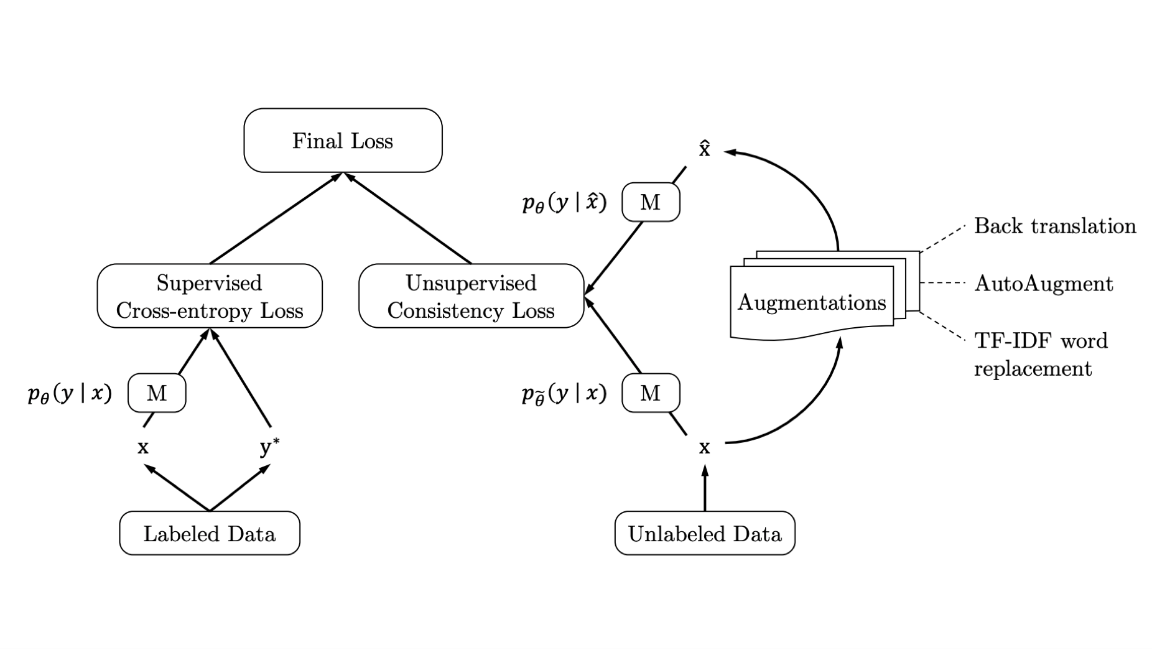
Key insight: UDA encourages models to make similar predictions for original inputs and their altered versions, a technique known as smoothness enforcing. Unlike prior smoothness enforcing algorithms, UDA uses data augmentation to multiply labeled and unlabeled examples.
How it works: UDA trains a neural network by calculating two loss functions: one derived from labeled data, the other from unlabeled data. Then it optimizes both losses through gradient descent on subsets of labeled and unlabeled data.
- The labeled loss focuses on improving the model’s accuracy, just like fully supervised training.
- For a given set of unlabeled inputs, the model predicts a set of labels.
- At this point, any state-of-the-art data augmentation algorithm can be used to transform the input. The model re-predicts labels for the newly transformed data.
- The unlabeled loss measures the difference in distribution between predictions for raw and transformed input.
- The final loss is the sum of labeled and unlabeled losses.
Why it matters: Neural networks often fail to generalize after supervised learning with limited labeled data. Troughs of unlabeled data may exist, but there may not be enough time or resources for humans to label it. UDA takes advantage of this bounty, promising impressive results even with few labeled examples.
Results: UDA achieves state-of-the-art performance in natural language tasks, specifically with the BERT model. It beats the best fully supervised model on the IMDb dataset — trained on only 20 labeled examples! Similarly, UDA exceeds the previous record on a restricted ImageNet from which labels were removed from 90 percent of the images.
Takeaway: Deep learning pioneer Yann LeCun considers semi-supervised learning an essential technique for AI to gain common sense. As the state-of-the-art semi-supervised training algorithm, UDA may be one of the small steps toward AI’s next great leap.