
Dear friends,
As we were working on the latest course of the deeplearning.ai TensorFlow Specialization, instructor Laurence Moroney messaged me his LSTM-generated poetry, created by learning from a database of roughly 100 Irish song lyrics:
Andrew sang a sad old song
Fainted through Miss Milliner
[...]
Punch and wine for the same party
As red as a jig rose painted of runctions.
Laurence tells me "runctions" is Irish slang mischief!
So now I'm ready to announce my new list of reasons why you should work in AI:
- Work on meaningful projects.
- Have an intellectually exciting job.
- Get customized Irish poetry.
If you want to learn how to build such models yourself, check out the TensorFlow Specialization.
Keep learning,
Andrew
News

Tight Fit
If you’re pointing out an object, you don’t describe the background. Yet most object detection algorithms focus on a rectangle surrounding the object, not its precise boundary. New research offers a way to turn those boxes into tightly fitted curves.
What’s new: Researchers at the University of Toronto and Nvidia achieved state-of-the-art accuracy in boundary detection with Semantic Thinning Edge Alignment Learning. STEAL is a new approach that augments existing boundary detection networks.
Key insights: Human-drawn boundaries are often imprecise because people are impatient and emphasize quantity over quality. But we can use them as a starting point.
- STEAL overcomes human inaccuracy by learning to infer the true boundary from a hastily hand-drawn version.
- It pushes precision higher with a so-called thinning layer. This layer replaces a wide predicted boundary with a narrower version.
How it works: Given a human-drawn boundary, STEAL predicts the boundary a human would draw given more time. Then, given a boundary detection network, STEAL forms a new network by appending a thinning layer to the original network’s output. The new network is trained to reconstruct STEAL’s inferred boundaries, not the human-drawn ones.
- During training, STEAL learns to infer boundaries from human annotations while holding constant the parameters, and thus the output, of the boundary detection network.
- At the same time, the boundary detection network learns to predict STEAL's inferred boundaries.
- STEAL learns to infer boundaries by optimizing an equation describing all possible boundaries arising from the human-drawn version.
- Without STEAL, boundary detection networks confidently predict boundary pixels that aren’t part of the true boundary but are adjacent to it. STEAL's thinning layer works by identifying such pixels by examining directions perpendicular to the predicted boundary along every pixel in the boundary.
- A separate classifier is used to determine how far to move each point along the boundary detection network's predicted boundary, in a direction perpendicular to this predicted boundary.
Why it matters: STEAL achieves a new state of the art, finding boundaries up to 18.6 percent more precise than its predecessor, CASENet SEAL, on hand-drawn and refined test sets. Looking at the output confirms that STEAL produces tight, accurate boundaries.
Takeaway: Object detection has a multitude of uses: image caption generation, face detection, and autonomous navigation to name a few. All these tasks have shown impressive results with object detection based on bounding boxes. Using STEAL’s more precise boundaries could reduce errors and further boost accuracy in these fields.

Seeing Through Poor Uses of AI
Worries over deepfake technology have concentrated on the potential impact of computer-generated media on politics. But image-generation technology also can have a malign impact on private citizens. Consider DeepNude, an app that generates naked images from photos of clothed women.
What’s new: Motherboard reported on DeepNude, which had been quietly gaining traction since it was released in March. The exposé set off a firestorm of criticism. Within 24 hours, the developer withdrew the app. It had been downloaded more than 500,000 times.
How it works: The anonymous developer explained that the app was inspired by old comic book ads for X-Ray Spex, a toy that purported to let the wearer see through clothing.
- DeepNude is based on the open-source pix2pix generative adversarial network, Motherboard reports.
- The free version puts a watermark over generated images.
- The $50 version stamps a “Fake” label in the upper left corner, where it can be easily cropped out.
The reaction: The developer announced the decision to delete the app with a message on Twitter that concluded, “The world is not yet ready for DeepNude.” In the ensuing thread, people expressed outrage and disgust that the app was developed at all:
- "I think what you meant to say is 'We programmed a deeply offensive, creepy as f*** app that is basically an invitation to be abusive & violate people's privacy and we're sorry,'" said one commenter.
- "don't blame others for your sociopathic, disrespectful morals. You knew exactly what your software will be used for and you don't care about the potential victims and what it does to their life. On par with revenge porn," said another.
Our take: Some users regard the app as harmless fun, like an Instagram filter that adorns human faces with a cartoonish dog nose. Such an attitude willfully ignores that representing any person without clothing and without permission is an attack on their privacy and autonomy. A fake nude can create false impressions and reinforce negative stereotypes, leading to embarrassment at best, sexual violence at worst. AI is a tool: Use it constructively, and you have a chance to make the world a better place. Wield it as a weapon, and you’ll leave a trail of pain and destruction.
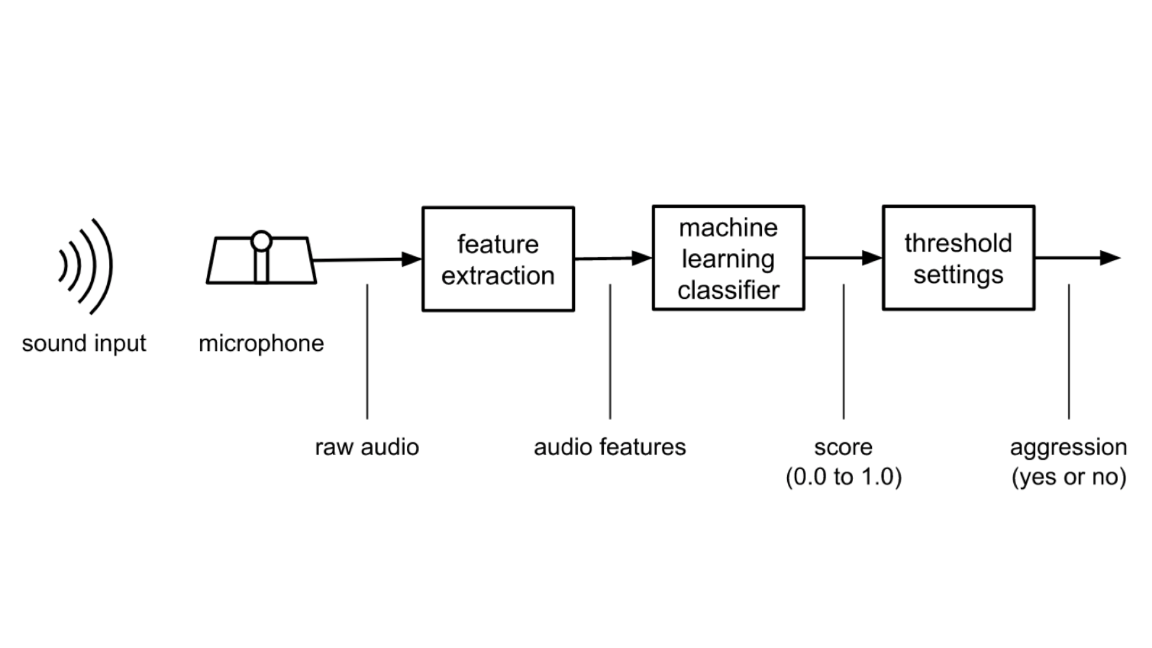
Hearing Problems
Schools, prisons, and other public places have been relying on AI-enhanced microphones to detect signs of trouble. They may have been better off putting their money elsewhere.
What’s new: ProPublica and Wired jointly investigated a widely-used system designed to listen to the surrounding environment and report sounds that indicate aggression in progress. They found the technology prone to false positives. For instance, a cough triggered an alert, as did a classroom full of students cheering for pizza. Yet it failed to register screams in more than 50 percent of trials.
Smart security: The Dutch firm Sound Intelligence developed the system, which uses machine learning models to detect “sound patterns associated with duress, anger, or fear.”
- The company touts it as an early warning system that can alert security personnel to impending incidents before they explode.
- Its products monitor more than 100 facilities in the U.S. and 1,000 worldwide.
Mixed reviews: A hospital in Fort Myers, Florida, said Sound Intelligence devices alerted its guards to unruly visitors, allowing them to intervene before situations escalated. However, another hospital in Ridgewood, New Jersey, cancelled its $22,000 pilot program after efforts to calibrate the system culminated in an incident that required six security officers to resolve.
What the company says: Sound Intelligence CEO Derek van Der Vorst acknowledged the reporters’ findings and admitted the devices aren't perfect. “I wouldn’t claim that we could prevent a crazy loony from shooting people,” he told ProPublica.
What experts say: “Happy or elated speech shares many of the same signatures as hot anger,” said Shae Morgan, an audiologist at the University of Louisville’s medical school. He pointed out that many acts of aggression — for example, the 2018 school shooting in Parkland, Florida— are preceded by nothing but cold silence.
We’re thinking: One of the biggest non-technical challenges facing AI is providing the public with a realistic assessment of its capabilities. It can work beautifully in a lab staffed by clear-eyed engineers yet fail in a room packed with gleeful kids. Developers need to be rigorous in devising real-world tests, and their colleagues in sales need to recognize that hype can do more harm than good.
A MESSAGE FROM DEEPLEARNING.AI
Want to understand the key parameters of a neural network’s architecture? Learn foundational deep learning concepts and the technologies driving them in the Deep Learning Specialization. Enroll here

What You See is What You Say
Teaching a computer meaningful associations between words and videos typically requires training on tens of thousands of videos painstakingly annotated by hand. That’s both labor-intensive and prone to inconsistency due to the often abstract relationship between video imagery and soundtrack. Researchers at the École Normale Supérieure and elsewhere devised an effective shortcut.
What’s new: A team led by Antoine Miech and Dimitri Zhukov assembled 136 million video clips from narrated instructional videos to produce the HowTo100M data set. This large corpus, in which the words correspond closely to the images, enables new models to be trained that yield stellar results in a variety of tasks.
Key insights: Previous research has taken advantage of the tight semantic correspondence between words and imagery in instructional videos. But that work has extracted only a small number of labels rather than analyzing complete transcriptions. Miech et al. found that:
- Systematic pruning of topics and auto-generating captions make it feasible to put together large video-text datasets.
- Large datasets are crucial to performance. Accuracy didn’t plateau when the researchers upped clip count from 20,000 to over 1 million. More training examples likely would further boost performance.
How it works: The researchers found instructional videos on YouTube. Their model consists of a collection of pretrained subnetworks to extract video and word features. It's trained to maximize the similarity between video and word vectors belonging to the same video.
- The researchers collected narrated instructional videos in domains associated with actions (like cooking) rather than ideas (finance). They focused on visual tasks (baking a cake) rather than abstract tasks (choosing a gift).
- They used an existing speech recognition model to generate video captions from the narration.
- To extract video feature vectors, the researchers used pretrained 2D ResNet-52 and 3D ResNeXt-101 models.
- To encode word vectors, they trained a 1D CNN with pretrained Word2Vec embeddings as inputs.
- The model is trained on an objective function that maximizes the cosine of the angle between a pair of corresponding word and video vectors.
Results: The team bettered the previous state of the art by as much as 50 percent on several clip retrieval benchmarks. Models pretrained on HowTo100M and fine-tuned on other data showed significant improvements in the target task compared to models trained from scratch.
Why it matters: At 136 million clips, HowTo100M is the largest video-text public data set, dwarfing previous efforts by orders of magnitude. The resulting video-text embeddings could dramatically improve the accuracy of neural networks devoted to tasks like video captioning, scene search, and summarizing clips.
Takeaway: HowTo100M widens the intersection of computer language and vision. It could lead to better search engines that retrieve relevant scenes described in natural language, or systems that generate artificial videos in response to natural-language queries. More broadly, it’s a step closer to machines that can talk about what they see.
Rules For Medical AI
The U.S. Food and Drug Administration regulates medical devices from stents to diagnostic systems. Once approved, those things don’t change much. Now the agency is formulating standards for medical devices that take advantage of AI that's constantly learning.
What’s new: The first public comment period for the FDA’s draft framework on AI-based medical devices ended in June. The National Law Review pored over the comments. NLR reports that the AI community is pushing for tighter definitions and clearer understanding between industry and government, even as it broadly supports that agency’s effort.
The issue: Current rules for software in medical devices require manufacturers to submit programs for review with each significant update. That works for algorithms that are locked and updated periodically, say, in a system that monitors people for signs of stroke. But it’s not a great fit for models that learn from use, like a system that spots cancer more accurately with increasing exposure to real-world data.
Moving target: The FDA wants to establish a lifecycle approach to AI-based medical devices. According to the guidelines, the agency would ask developers to submit a roadmap of expected changes in a model’s output as it learns. Developers also would describe how they expect to manage any risks that might arise as the model adjusts to new data.
Public opinion: Businesses, professional groups, and concerned individuals who submitted comments generally liked the approach but requested a number of tweaks:
- Many commenters wanted the agency to describes the types of AI models it expects the framework to govern. For instance, what constitutes a “continuously learning” AI?
- Some wanted the FDA to explain what kinds of changes would trigger a review.
- Others called on regulations to harmonize their guidelines with those engineers have adopted on their own. For instance, the IEEE’s standard for Transparency of Autonomous Systems calls for designing models so they can be evaluated independently for compliance with external protocols (like the FDA’s).
What’s next: The process is bound to wind through many more steps. Expect another draft framework, further rounds of public feedback, and internal reviews before the rules are finalized.
Our take: Regulation is messy. That goes double for medicine, and perhaps triple for AI. Still, it's critical to protect patients without squelching innovation. Government, industry, and researchers all have an important role to play in hammering out the final rules.

Where the Robots Will Land
Automatons will take 20 million manufacturing jobs globally by 2030 even as they drive substantial economic growth, according to a new study. Humans can get ahead of the curve by distributing the benefits where they’ll be needed most.
What’s new: UK business analytics firm Oxford Economics issued How Robots Change the World, which the authors call an “early warning system” of coming social impacts. The report compares investment data from the International Federation of Robotics with statistics tracking employment, wages, and GDP across a number of job sectors, countries, and demographics.
Industries hit: Manufacturing has seen the highest degree of automation so far. The researchers expect that trend to continue, but they also expect robots soon to begin a grand takeover of the service industry. For instance, automated vehicles will curb professional drivers from Lyft to long-haul.
U.S outlook: Poor populations and rural regions that rely on manufacturing will be hit hardest:
- Oregon is most vulnerable due to its high concentration of factories in the Willamette Valley near Portland.
- Manufacturing hubs including Louisiana, Indiana, and Texas come next.
- States with predominantly white collar jobs, dense urbanization, or lots of tourism are least vulnerable.
- Hawaii will see the least impact, at least until someone invents a droid that can drape a garland of flowers around a person's neck.
The big picture: A similar pattern is expected to play out internationally:
- China will likely accelerate its transformation into an industrial cyborg, adding up to 14 million new industrial robots.
- South Korea, Japan, and Europe will also add significant numbers of robot workers.
The bright side: The impacts won't be entirely negative:
- More efficient markets generate more revenue, which investors pour into new ventures, generating new jobs.
- Should robotification replace 30 percent of the industrialized workforce, it will also add $5 trillion to the gross world product (currently around $88 trillion).
- The jobs most likely to disappear are repetitive, low-skill work non-robots describe as soul-crushing. The jobs that replace them are likely to require more brainpower.
Our take: Even if new jobs appear as quickly as old ones evaporate, the robot revolution will disrupt human lives. Some people won't take well to retraining. Others might not live where new jobs arise. Policymakers in manufacturing-heavy regions can mitigate the worst impacts by fostering industries less prone to automation — technology, communications, healthcare, finance, tourism — and providing training so people will be ready for those jobs when they come.