
Dear friends,
A first for my three-month-old daughter Nova: an outing to the park. As my mother and I watched her staring at a tree. I realized what a novel experience it must be to see a tree close-up for the first time. For humans and AI both, there is a first time seeing a tree!
While most of AI's practical value today is through supervised learning, much of human learning appears to be unsupervised. When I speculate about the future of unsupervised learning, I believe it will still be necessary to train much larger networks, and on much more data than we use today — and that will be very time-consuming without much faster computers.
I'm grateful for all of you at Intel, Nvidia, Qualcomm, AMD, and various startups working on faster chips. The DL world is nowhere near maxing out our ability to use compute!
Keep learning,
Andrew
News

Hope For the Fashion-Challenged
Need a quick wardrobe upgrade? Image generation to the rescue! This research project automatically visualizes small changes to clothing that make the wearer look more fashionable.
What’s new: Researchers built a neural net to answer the question: Given an outfit, what small changes would make it more fashionable? Fashion++ renders improvements, from rolling up sleeves to adding an accessory to replacing garments. This video explains.
How it works: Given a full-body image, the model:
- Evaluates various body regions (face, hair, shirt, pants, and so on)
- Scores fashionability per region separately for shape (fit and presentation such as whether or not a shirt is tucked in) and texture (color, pattern, and material)
- Finds higher-scoring alternatives
- Updates shapes as 2D segmentation maps and textures as 3D feature maps
- Renders a series of updated outfits balancing higher scores with minimal change.
Can AI have fashion sense? To train the fashionability classifier, Wei-Lin Hsiao and her collaborators represented high fashion using the Chictopia photo set. They created degraded alternatives automatically by swapping in dissimilar garments (as measured by Euclidean distance on CNN features). Judges on Mechanical Turk found 92% of most-changed to be more fashionable.
Takeaway: Fashion++ has the kind of smarts generally thought to be the province of humans. It has clear commercial uses in ecommerce. And who couldn’t use a style assist?

Old MacDonald Had a Bot
A California grocer is stocking produce grown by robots, a sign of AI’s growing presence in agriculture.
What’s new: Iron Ox, a startup that grows greens in robot-tended warehouses, is supplying three vegetable varieties to Bianchini’s Grocery of San Carlos, CA. The producer grows 26,000 heads of lettuce and other greens annually in an 8,000 square foot space — 30 times more space-efficient than conventional farming with less chemical runoff and greenhouse gases.
How it works: The automated farm relies on human labor for planting and packaging. In between, machines are in charge:
- Computers control nutrients for optimal growth
- Plants are grown in hydroponic vats
- Robot arms move plants from vat to vat as they grow
- Autonomous carts ferry plants around the space.
Reality check: It’s not clear whether Iron Ox’s operation can be cost-effective. Bianchini’s sells its basil for a price on par with that of conventionally farmed options, the San Francisco Chronicle reports. But its baby lettuce goes for a lot more, according to The Verge.
Takeaway: The cost of farm labor is ballooning, and growers of many crops are scoping out automated alternatives. Iron Ox is betting that robotic agriculture ultimately will cost less in a smaller environmental footprint.
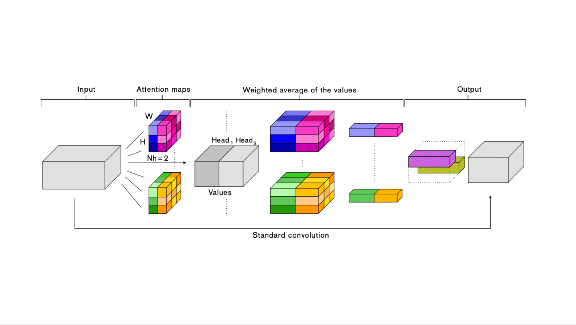
Convolution Plus
The technique known as attention has yielded spectacular results in speech and natural language tasks. Now researchers have shown that it can improve image recognizers as well.
What’s new: A residual neural network incorporating self-attention layers beat the state of the art accuracy on ImageNet classification by 1.3% over a ResNet50 baseline, according to a new paper. It also beat the best Common Objects in Context object detection score over a RetinaNet baseline. This is not the first use of attention in vision tasks, but it outperforms earlier efforts.
How it works: Quoc Le and his colleagues augmented convolution layers with multi-headed self-attention layers. The resulting network uses attention in parallel with convolution and concatenates the outputs produced by each. Attention extends a network’s awareness beyond the data it’s processing at a given moment. Adding it to a convolutional neural network enables the model to consider relations between different areas of an image.
Why it matters: The attention networks generally require fewer parameters than convolution layers to achieve an accuracy target. That makes it possible to improve performance in a same-sized model.
Bottom line: Image recognizers based on CNNs already achieve high accuracy and sensitivity, and adding attention makes them even sharper.
A MESSAGE FROM DEEPLEARNING.AI

Still debating whether to get into deep learning? Check out the techniques you'll learn and projects you'll build in the Deep Learning Specialization. Learn more
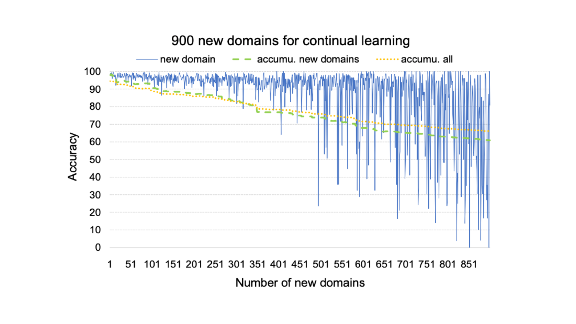
Alex, Open . . . Something
If digital assistants had feet, their Achilles heel would be requiring users to remember commands that invoke new skills. Amazon proposes a way to train systems like Alexa to learn new domains incrementally, so they can parse intent in a phrase like “call a car” even if the skill itself — say, Uber/Lyft/Grab/etc.— isn’t named.
What’s new: Amazon’s proposal, called Continuous Domain Adaptation or CoNDA, maintains previously learned parameters while updating those relevant to a new domain. This strategy teaches new skills in far less time than retraining a model from scratch. It also avoids the catastrophic forgetting problem, in which the new learning displaces old.
The results: CoNDA achieved 95.6 percent accuracy over 100 new domains and 88.2 percent accuracy for all domains after the new ones have been added. That’s only 3.6 percent lower than if the model had been retrained from scratch.
How it works: Devised by Han Li and his colleagues, CoNDA is a variation on the Shortlister classifier, which comprises three modules. An LSTM-based encoder maps verbal commands to vector representations. A second module generates summarization vectors, freezing parameter weights when a new domain is added and updating only those relevant to new training data. It adds a regularization term to the loss function to avoid overfitting. Finally, a feed-forward network predicts the classification using cosine normalization. A negative sampling procedure maintains known domains to alleviate catastrophic forgetting.
Takeaway: The new training method promises relief to digital assistants struggling to recall dozens of invocations. More important, it opens new doors for continuous learning — an essential capability as AI systems are deployed in ever more dynamic environments.

Deep Motion
The usual ways to plot a course from one place to another typically entail a trade-off between economy of motion and computation time. Researchers instead used deep learning to find efficient paths quickly.
What’s new: The researchers propose a recurrent neural network that generates good motion plans in a fixed time regardless of the complexity of the environment. This video gives an overview.
Why it’s better: Their system’s performance scales almost linearly with higher dimensions, outperforming algorithms like A* and RRT* that bog down in larger or more complex spaces. It proved 10 times faster with a three-link robot, 20 times faster with four links, and 30 times faster controlling a three link arm in six dimensions.
How it works: Known as OracleNet, the model mimics the stepwise output of an oracle algorithm (one that can generate efficient paths to or from any spot in a given space). At each waypoint, the network uses the current position and the goal location to decide on the position of the next waypoint. It uses an LSTM to preserve information over several steps.
Why it matters: Robotic control is devilishly hard, and typical solutions impose severe limitations. This research offers an inkling of what neural networks can accomplish in the field.
What’s next: Researchers Mayur Bency, Ahmed Qureshi, and Michael Yip suggest that active learning could enable OracleNet to accommodate dymnamic environments. Further variations could enable it to navigate unfamiliar or changing environments.