
Dear friends,
Benchmarks have been a significant driver of research progress in machine learning. But they've driven progress in model architecture, not approaches to building datasets, which can have a large impact on performance in practical applications. Could a new type of benchmark spur progress in data-centric AI development?
Remember: AI System = Code (model/algorithm) + Data
Most benchmarks provide a fixed set of Data and invite researchers to iterate on the Code. This makes it possible to compare algorithms: By running many models on the same dataset, we can find the ones that perform best. To spur innovation on data-centric AI approaches, perhaps it’s time to hold the Code fixed and invite researchers to improve the Data.
A huge amount of innovation — in algorithms, ideas, principles, and tools — is needed to make data-centric AI development efficient and effective.

When AI was shifting toward deep learning over a decade ago, I didn’t foresee how many thousands of innovations and research papers would be needed to flesh out core tenets of the field. But now I think an equally large amount of work lies ahead to support a data-centric approach. For example, we need to develop good ways to:
- Surface and address inconsistencies in data labels
- Detect and address data drift and concept drift
- Help developers with error analysis
- Select and apply the most effective data augmentation techniques
- Decide what additional data to collect (rather than collecting more of everything)
- Merge inconsistent data sources
- Track data provenance and lineage, so we can address problems in the data, such as bias, that may be discovered later
Benchmarks and competitions in which teams are asked to improve the data rather than the code would better reflect the workloads of many practical applications. I hope that such benchmarks also will spur research and help engineers gain experience working on data. The Human Computer Interface (HCI) community also has a role in designing user interfaces that help developers and subject-matter experts work efficiently with data.
I asked for feedback on the idea of a data-centric competition on social media (Twitter, LinkedIn, Facebook). I’ve read all the responses so far — thanks to all who replied. If you have thoughts on this, please join the discussion there.
Keep learning!
Andrew
News
 |
Face Recognition for the Masses
A secretive start-up matches faces online as a free service.
What’s new: Face recognition tech tends to be marketed to government agencies, but PimEyes offers a web app that lets anyone scan the internet for photos of themself — or anyone they have a picture of. The company says it aims to help people control their online presence and fight identity theft, but privacy advocates are concerned that the tool could be used to monitor or harass people, The Washington Post reported. You can try it here.
How it works: PimEyes has extracted geometric data from over 900 million faces it has found online. It claims not to crawl social media sites, but images from Instagram, Twitter, and YouTube have shown up in its results.
- The company compares the geometry of faces in pictures uploaded by users to those in its database and returns any matches.
- Anyone can search for free. Paying subscribers can see the web address of any images found and receive alerts when the system finds new matches. The company claims its accuracy is around 90 percent.
- The service doesn't verify user identities, leaving it ripe for abuse. Cyberstalkers on 4Chan have used it to stalk women photographed in public, and activists on Twitter have used it to try to identify people who stormed the U.S. Capitol on February 6.
- PimEyes, which is registered in the Seychelles, has declined interviews with several news outlets. It does not identify any of its personnel, and it answers questions via email through an anonymous spokesperson.
Behind the news: Free online face matching is part of a broader mainstreaming of face recognition and tools to counter it.
- Google’s FaceNet, released in 2015, has become the basis of many face recognition tools.
- The Russian app FindFace, which is used by government officials to track political dissidents, earned notoriety in 2016 when people used it to identify women who had appeared anonymously in pornography.
- Exposing.AI uses face recognition to warn users when their Flickr images are used to train an AI model.
Why it matters: The widespread ability to find matches for any face online erodes personal privacy. It also adds fuel to efforts to regulate face recognition, which could result in restrictions that block productive uses of the technology.
We’re thinking: We’re all poorer when merely posting a photo on a social network puts privacy at risk. The fact that such a service is possible doesn’t make it a worthy use of an engineer’s time and expertise.
 |
Double Check for Defamation
A libel-detection system could help news outlets and social media companies stay out of legal hot water.
What’s new: CaliberAI, an Irish startup, scans text for statements that could be considered defamatory, Wired reported. You can try it here.
How it works: The system uses custom models to assess whether assertions that a person or group did something illegal, immoral, or otherwise taboo meet the legal definition of defamation.
- The company’s cofounder created a list of potentially defamatory statements such as accusations of murder, adultery, or drunkenness. A team of linguists expanded the list into a larger training dataset.
- A model based on BERT learned to score input sentences from 0 to 100. Statements that score 60 or higher are sent to human reviewers to determine, for instance, whether the accusation is true. (A statement is not defamatory if it can be shown to be true.)
- A separate BERT model singles out sentences that make what the company calls harmful statements that denigrate particular groups.
Behind the news: News organizations are finding diverse uses for natural language processing.
- Canada’s Globe and Mail newspaper uses a model to fill its homepage with stories likely to convert casual readers into subscribers.
- Los Angeles, California, radio station KPCC is developing a system to sort listener questions about Covid-19 by topic.
- The nonprofit Knight Foundation granted $3 million to develop automated tools for journalists. Recipients include Associated Press, Columbia University, New York City Media Lab, and Partnership on AI.
Why it matters: A defamation warning system could help news organizations avoid expensive, time-consuming lawsuits. That’s especially important in Europe and other places where such suits are easier to file than in the U.S. Social media networks may soon need similar tools. Proposed rules in the EU and UK would hold such companies legally accountable for defamatory or harmful material published on their platforms. U.S. lawmakers are eyeing similar legislation.
We’re thinking: Defamation detection may be a double-edged sword. While it has clear benefits, it could also have a chilling effect on journalists, bloggers, and other writers by making them wary of writing anything critical of anyone.
A MESSAGE FROM DEEPLEARNING.AI
 |
The first two courses in our Machine Learning Engineering for Production (MLOps) Specialization are live on Coursera! Enroll now
 |
Bias By the Book
Researchers found serious flaws in an influential language dataset, highlighting the need for better documentation of data used in machine learning.
What’s new: Northwestern University researchers Jack Bandy and Nicholas Vincent investigated BookCorpus, which has been used to train at least 30 large language models. They found several ways it could impart social biases.
What they found: The researchers highlighted shortcomings that undermine the dataset’s usefulness.
- BookCorpus purportedly contains the text of 11,038 ebooks made available for free by online publisher Smashwords. But the study found that only 7,185 of the files were unique. Some were duplicated up to five times. Nearly 100 contained no text at all.
- By analyzing words related to various religions, the researchers found that the corpus focuses on Islam and Christianity and largely ignores Judaism, Hinduism, Buddhism, Sikhism, and Atheism. This could bias trained models with respect to religious topics.
- The collection is almost entirely fiction and skews heavily toward certain genres. Romance novels, the biggest genre, comprise 26.1 percent of the dataset. Some of the text in those books, the authors suggest, could contain gender-related biases.
- The dataset’s compilers did not obtain consent from the people who wrote the books, several hundred of which include statements that forbid making copies.
Behind the news: The study’s authors were inspired by previous work by researchers Emily Bender and Timnit Gebru, who proposed a standardized method for reporting how and why datasets are designed. The pair outlined in a later paper how lack of information about what goes into datasets can lead to “documentation debt,” costs incurred when data issues lead to problems in a model’s output.
Why it matters: Skewed training data can have substantial effects on a model’s output. Thorough documentation can warn engineers of limitations and nudge researchers to build better datasets — and maybe even prevent unforeseen copyright violations.
We’re thinking: If you train an AI model on a library full of books and find it biased, you have only your shelf to blame.
 |
What Machines Want to See
Researchers typically downsize images for vision networks to accommodate limited memory and accelerate processing. A new method not only compresses images but yields better classification.
What’s new: Hossein Talebi and Peyman Milanfar at Google built a learned image preprocessor that improved the accuracy of image recognition models trained on its output.
Key insight: Common approaches to downsizing, such as bilinear and bicubic methods, interpolate between pixels to determine the colors of pixels in a smaller version of an image. Information is lost in the process, which may degrade the performance of models trained on them. One solution is to train separate models that perform resizing and classification together.
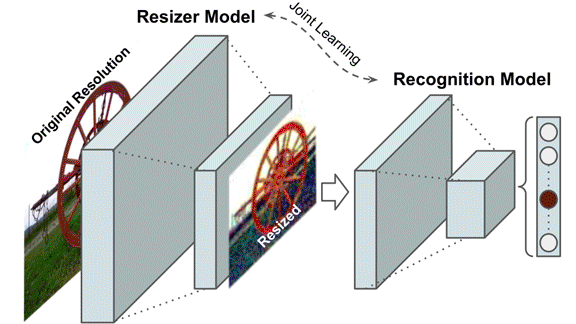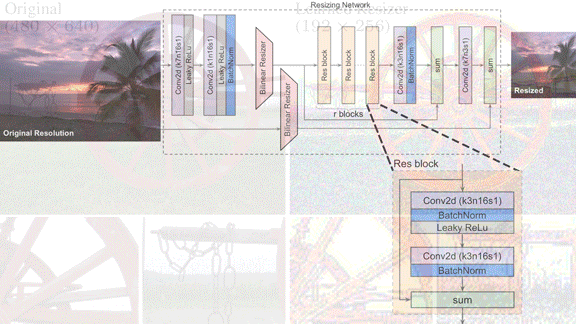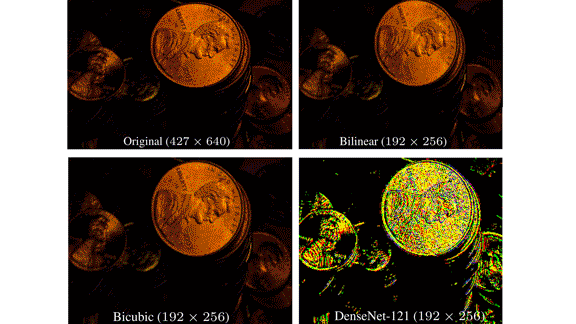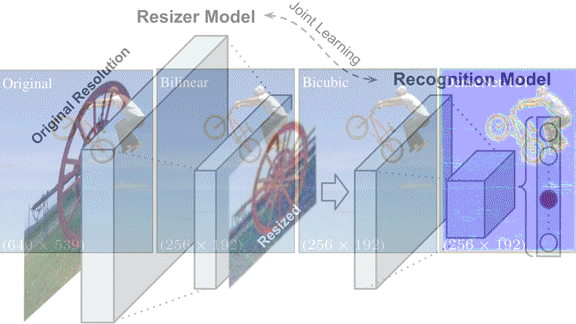
How it works: The network comprises a bilinear resizer layer sandwiched between convolutional layers to enable it to accept any input image size.
- The authors downsized ImageNet examples to 224x224 using a garden-variety bilinear resizer and used them to train a DenseNet-121. This resizer-classifier pair served as a baseline.
- They further trained the DenseNet-121 while training their resizer jointly, optimizing for both classification accuracy and input size.
Results: The authors’ approach achieved top-5 error on ImageNet of 10.8 percent. The baseline model achieved 12.8 percent.
Yes, but: The proposed method consumed 35 percent more processing power (7.65 billion FLOPS) than the baseline (5.67 billion FLOPS).
Why it matters: Machine learning engineers have adopted conventional resizing methods without considering their impact on performance. If we must discard information, we can devise an algorithm that learns to keep what’s the most important.
We’re thinking: In between training vision networks, you might use this image processor to produce mildly interesting digital art.