
Dear friends,
I just replaced my two-year-old phone with a new one and figured out how to take long-exposure photos of Nova even while she’s asleep and the lights are very low. This piece of technology brought me a surprising amount of joy!
I wrote about ethics last week, and the difficulty of distilling ethical AI engineering into a few actionable principles. Marie Kondo, the famous expert on de-cluttering homes, teaches that if an item doesn’t spark joy, then you should throw it out. When building AI systems, should we think about whether we’re bringing joy to others?
This leaves plenty of room for interpretation. I find joy in hard work, helping others, increasing humanity’s efficiency, and learning. I don’t find joy in addictive digital products. I don’t expect everyone to have the same values, but perhaps you will find this a useful heuristic for navigating the complicated decision of what to work on: Is your ML project bringing others joy?
This isn’t the whole answer, but I find it a useful initial filter.
Keep learning!
Andrew
News
Autonomous Drones Ready to Race
Pilots in drone races fly souped-up quadcopters around an obstacle course at 120 miles per hour. But soon they may be out of a job, as race organizers try to spice things up with drones controlled by AI.
What’s new: The Drone Racing League, which stages contests to promote this so-called sport of the future, recently unveiled an autonomous flier called RacerAI. The new drone includes Nvidia’s Jetson AGX Xavier inference engine, four stereoscopic cameras, and propellers that deliver 20 pounds of thrust.
What’s happening: RacerAI serves as the platform for AI models built by teams competing in AlphaPilot, a competition sponsored by the DRL and Lockheed Martin.
- 420 teams entered and tested their models on a simulated track.
- Virtual trials whittled the teams down to nine, which will compete in four races throughout fall 2019.
- Team USRG from Kaist University in South Korea won the first race on October 8. The second is scheduled for November 2 in Washington D.C.
- The series winner will take a $1 million prize. In early 2020, that model will face a top-rated human pilot for an additional $250,000 purse.
Behind the news: Drone Racing League pilots use standardized drones built and maintained by the league, and train on the same simulator used to train RacerAI. Races are typically a mile long and take place in event spaces across the U.S. and Europe.
Why it matters: Drone racing is fun and games, but the skills learned by autonomous racing models could be transferable to real-world applications like automated delivery.
We’re thinking: A recent DRL video shows that current models have a way to go before they graduate from passing through rings to making high-speed maneuvers. Human pilots still have a significant edge — for now.
High Accuracy, Low Compute
As neural networks have become more accurate, they’ve also ballooned in size and computational cost. That makes many state-of-the-art models impractical to run on phones and potentially smaller, less powerful devices. A new technique makes convolutional neural networks much less computationally intensive without significantly degrading their performance.
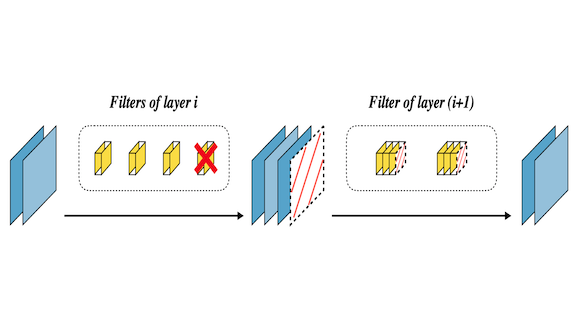
What’s new: Zhonghui You and colleagues at Peking University and Momenta, an autonomous-vehicle startup, propose a way to remove parameters that aren’t critical to a model’s performance: Gate Decorator.
Key insight: The new technique removes functional groups of parameters (specifically convolutional filters), rather than individual parameters.
How it works: Gate Decorator adds to the model a scaling factor that represents each filter’s importance to the model’s output. It ranks filters by their impact on the model’s loss function. Then it removes the least effective ones.
- The model processes a subset of training data to learn the scaling factor’s value for each filter. The original model’s parameters retain their existing values.
- The scaling factors are randomly initialized. For each filter, the model is encouraged to learn the smallest scaling factor that, multiplied by the filter’s output, takes the least toll on performance.
- A user-specified fraction of filters with the smallest scaling factor are deleted. The pruned network is fine-tuned on the entire training set.
- The process is repeated for a user-defined number of iterations.
Results: The researchers compared the accuracy and computational cost of original and pruned networks. Gate Decorator cut the computational cost of an ImageNet-trained ResNet by 55 percent and a CIFAR-trained ResNet by 70 percent. Accuracy for these models decreased by 0.67 percent and increased by 0.03 percent, respectively. That’s state-of-the-art accuracy for such a reduction in computational cost.
Why it matters: Unlike most weight-pruning techniques, Gate Decorator’s efficiency gains are straightforward to achieve in practice, not just in theory. A model shorn of filters can still run existing algorithms, while removing weights from a densely connected neural network ultimately requires specialized algorithms that we don’t yet have.
We’re thinking: A pruning method like this might work with other parameter groupings to cut the computational demand of architectures beyond CNNs. The resulting models could be further compressed using other methods such as quantization.

Clash of the Frameworks
Most deep learning applications run on TensorFlow or PyTorch. A new analysis found that they have very different audiences.
What’s new: A researcher at Cornell University compared references to TensorFlow and PyTorch in public sources over the past year. PyTorch is growing rapidly within the research community, while TensorFlow maintains an edge in industry, according to a report in The Gradient. (deeplearning.ai, which publishes The Batch, provides the TensorFlow Specialization course available on Coursera.)
Findings: Horace He used proxy data to determine whether users were from the research or business community.
- To represent the research community, he surveyed abstracts submitted to five top AI conferences in 2018. He found an average increase of 275 percent in researchers using PyTorch, and an average decrease of roughly 0.5 percent for TensorFlow, over the year.
- To track business users, he analyzed 3,000 job listings. Businesses looking for experience in TensorFlow outnumbered those asking for experience in PyTorch. He also surveyed articles on LinkedIn and found a ratio of 3,230 to 1,200 in favor of TensorFlow.
- TensorFlow also outnumbered PyTorch in terms of GitHub stars used by coders to save repositories for later use. He considers this a key metric for tracking projects in production.
Competitive strengths:
- TensorFlow has a large, well established user base, and industry is typically slower to pick up on new technologies.
- TensorFlow is much more efficient than PyTorch. Even modest savings in model run times can help a company’s bottom line.
- PyTorch integrates neatly with Python, making the code simple to use and easy to debug.
- According to He, many researchers prefer PyTorch’s API, which has remained consistent since the framework’s initial release in 2016.
We’re thinking: If there is to be a reckoning between the two top frameworks, it could happen soon. The newly released TensorFlow 2.0 adds many of the benefits PyTorch users love, particularly Python integration and making Eager mode the default for execution. However, deep learning is driven largely by research, so today’s students may bring PyTorch with them as they trickle into the job market.
A MESSAGE FROM DEEPLEARNING.AI

Learn how to detect edges with convolution operations. Build a convolutional neural network in Course 4 of the Deep Learning Specialization. Start today
Power of Babel
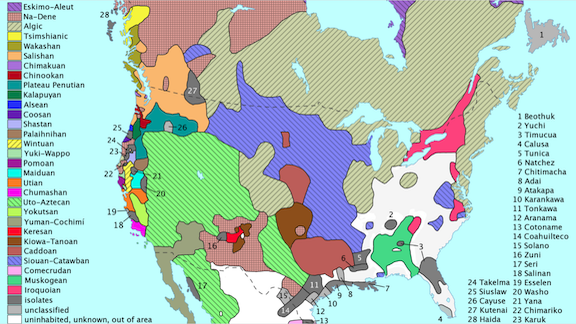
More than 900 indigenous languages are spoken across the Americas, nearly half of all tongues in use worldwide. A website tracks the growing number of resources available for natural language processing researchers interested in studying, learning from, and saving these fading languages.
What’s happening: Naki collects NLP efforts involving indigenous American languages.
What’s inside: Researchers at the National Autonomous University of Mexico noticed a distinct rise in NLP papers focused on Native American languages over the past five years. They organized all the papers and research tools they could find.
- The researchers found NLP tools for 35 languages.
- North American languages receive the most research attention, despite having fewer speakers on average than those in Mesoamerica and South America.
- Native American tongues offer a diversity of dialects within an individual language. That makes it difficult for NLP models to develop standardized dictionaries and syntaxes.
Behind the news: Language families are linguistic groupings with similar origins and closely related syntax and definitions, such as Indo-European, or Sino-Tibetan. The Americas are home to more than 70 such groups, according to some researchers.
Why it matters: The resources collected on Naki are part of a growing effort to apply NLP to less common languages. The effort poses fundamental research problems. Like other rare tongues, Native American languages suffer from small written datasets — while NLP is very data-hungry — as well as broad variation from speaker to speaker and high complexity. For example, like Mandarin, many languages from Central Mexico shift vocal pitch to give identical words different meanings. NLP could benefit immeasurably by solving these problems.
We’re thinking: While it’s valuable to study rare languages for their own sake, there’s a huge opportunity in giving people who rely on them access to capabilities that much of the world takes for granted: voice recognition, speech to text, automatic translation, and the like. The usual techniques won’t get us there, but working with these languages could lead researchers to the necessary breakthroughs.
Two Steps to Better Summaries
Summarizing a document using original words is a longstanding problem for natural language processing. Researchers recently took a step toward human-level performance in this task, known as abstractive summarization, as opposed to extractive summarization consisting of sentences drawn from the input text. “We present a method to produce abstractive summaries of long documents,” their abstract reads — quoting words generated by the model they propose.
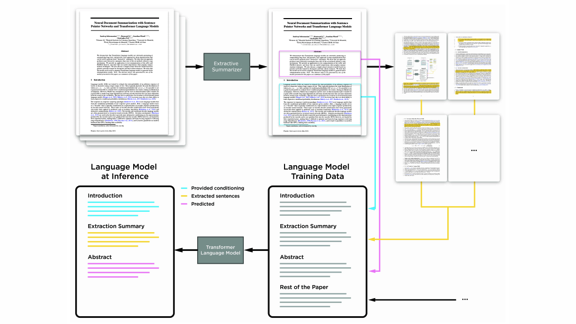
What’s new: Rather than generating abstractive summaries directly, researchers from Element AI and Montreal Institute for Learning Algorithms started with an extractive summary that guides the generated language.
Key insight: Providing an extractive summary along with source text can help a pre-trained language model generate a higher-quality abstractive summary.
How it works: Summarization proceeds in two steps: extraction and abstraction.
- The researchers trained a neural network to identify the most important sentences in a document. In essence, they assign a real-valued score to each sentence based on relationships among all sentences (in terms of content and style, for example). The highest-scoring sentences form an extractive summary.
- A GPT-like architecture, trained on ground-truth abstractive summaries, generates an abstractive summary by predicting words in a sequence. The model receives the extractive summary after the source document, so the summary has greater influence over its output.
Results: The authors tested four corpora, all of which include human-written summaries: arXiv (research papers), PubMed (medical research papers), bigPatent (patent documents) and Newsroom (news articles). The authors compared summarization quality using ROUGE scores, which capture the overlap between generated and ground-truth summaries. For three out of the four datasets, the proposed method achieved state-of-the-art summarization quality without copying entire sentences from the input. Extractive summarization models yielded the best ROUGE scores for the Newsroom corpus.
Why it matters: The ability to generate high-quality abstractive summaries could boost worker productivity by replacing long texts with concise synopses.
We’re thinking: Yikes! We hope this doesn’t put The Batch team out of a job.