
Dear friends,
Machine learning development is highly iterative. Rather than designing a grand system, spending months to build it, and then launching it and hoping for the best, it’s usually better to build a quick-and-dirty system, get feedback, and use that feedback to improve the system.
The iterative aspect of machine learning applies to many steps. For example:
Data labeling: It’s hard to come up with fully fleshed-out labeling guidelines that result in clean and consistent labels on your first attempt. It might be better to use an initial set of guidelines to label some data, see what problems arise, and then improve the guidelines.
Model training: Building an AI system requires deciding what data, hyperparameters, and model architecture to use. Rather than overthinking these choices, it’s often better to train an initial model, then use error analysis to drive improvements.
Deployment and monitoring: When deploying a machine learning system, you might implement dashboards that track various metrics to try to spot concept drift or data drift. For example, if you’re building a product recommendation system, you might track both software metrics such as queries per second and statistical metrics such as how often the system recommends products of different categories. What metrics should we track? Rather than try to design the perfect set of dashboards before launch, I find it more fruitful to pick a very large set of metrics, evolve them, and prune the ones that prove less useful.
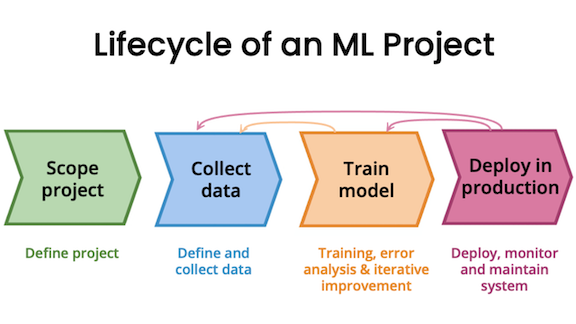
Iteration is helpful in other phases of machine learning development as well. It make sense to take an empirical, experimental approach to decision making whenever:
- Multiple options are available and it's hard to know the best choice in advance.
- We can run experiments to get data quickly about the performance of different options.
These two properties hold true for many steps in a typical ML project.
One implication is that, if we can build tools and processes that enable high-throughput experimentation, we can make faster progress. For instance, if you have an MLOps platform that enables you to quickly train and evaluate new models, this will allow you to improve models more quickly.
This principle applies to other aspects of ML development that are iterative. That’s why time spent optimizing your team's capacity to run many experiments can pay off well.
Keep learning!
Andrew
News

Labeling Errors Everywhere
Key machine learning datasets are riddled with mistakes.
What’s new: Several benchmark datasets are shot through with incorrect labels. On average, 3.4 percent of examples in 10 commonly used datasets are mislabeled, according to a new study — and the detrimental impact of such errors rises with model size.
The research: Curtis Northcutt and Anish Athalye at MIT and Jonas Mueller at Amazon trained a model to identify erroneous labels in popular datasets such as ImageNet, Amazon Reviews, and IMDB.
- Following confident learning, the authors considered an example mislabeled if it met two conditions: The model’s predicted classification didn't match the label, and the model’s confidence in its classification was greater than its average confidence in its predictions of the labeled class over all examples bearing that label.
- Human reviewers vetted the mislabeled examples. They found many obvious mistakes: an image of a frog labeled “cat,” an audio clip of a singer labeled “whistling,” and negative movie reviews misinterpreted as positive. QuickDraw had the highest rate of inaccurately labeled data, 10.1 percent. MNIST had the lowest, 0.15 percent.
- The authors fixed the bad labels and revised the test sets. Then they measured how well different models classified the corrected test sets. Smaller models like Resnet-18 or VGG-11 outperformed larger ones like NasNet or VGG-19.
Why it matters: It’s well known that machine learning datasets contain a fair percentage of errors. Previous inquiries into the problem focused on training rather than test sets, and found that training on a small percentage of incorrect labels didn’t hurt deep learning performance. But accuracy on a test set that’s rife with errors is not a true measure of a model’s ability, and bad labels in the test set have a disproportionate impact on bigger models.
We’re thinking: It’s time for our community to shift from model-centric to data-centric AI development. Many state-of-the-art models work well enough that tinkering with their architecture yields little gain in many problems, and the most direct path to improved performance is to systematically improve the data your algorithm learns from. You can check out Andrew’s recent talk on the subject here. #DataCentricAI
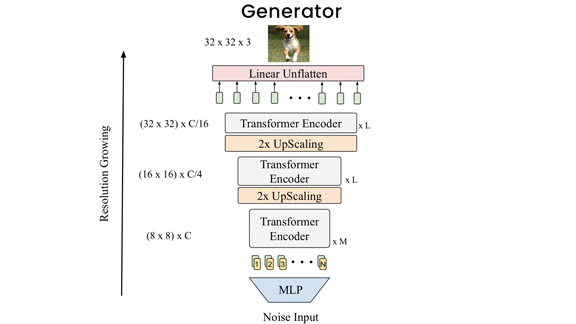
Image Generation Transformed
A recent generative adversarial network (GAN) produced more coherent images using modified transformers that replaced fully connected layers with convolutional layers. A new GAN achieved a similar end using transformers in their original form.
What’s new: Yifan Jiang and collaborators at the University of Texas at Austin and the MIT-IBM Watson AI Lab unveiled TransGAN, a transformer-based GAN that doesn’t use any convolutions.
Key insight: Traditionally, GANs rely on convolutional neural networks, which integrate information in pixels far away from one another only in the later layers. The upshot could be an image of a person with two different eye colors or mismatched earrings. A GAN based on transformers, which use self-attention to determine relationships among various parts of an input, would learn relationships between pixels across an entire image from the get-go. That should enable it to produce more realistic images.
How it works: Like other GANs, TransGAN includes a generator (which, given a random input, generates a new image) and a discriminator (which, given an image, predicts whether or not it’s generated). Both components contain a sequence of transformer layers, each comprising a fully connected layer and a self-attention layer. The authors trained them simultaneously.
- Where a typical GAN’s generator uses convolutions to manipulate a two-dimensional representation, TransGAN uses transformers to manipulate a sequence and project it into a sequence of pixels. To cut the amount of computation required, the generator produces a small number of representations at the first layer and increases the number in subsequent layers.
- Convolutions typically focus on small, adjacent areas of an input to avoid unnaturally abrupt transitions. To encode similar smoothness without convolutions, TransGAN’s generator applied a mask during training that limited attention to neighboring parts of an image. The mask gradually enlarged until it covered the entire image.
- The discriminator receives an image divided into an 8x8 grid, which it converts into a sequence of 64 patches. The sequence passes through the transformer layers, ending with a linear layer that classifies the image.
Results: TransGAN set a new state of the art on the STL-10 dataset, which includes relatively few labeled examples and many unlabeled examples in a similar distribution. It achieved a Fréchet Inception Distance — a measure of the difference in distribution between generated images and training data (lower is better) — of 25.32 FID, compared to the previous state of the art’s 26.98 FID.
Yes, but: On the Celeb-A dataset of relatively high-res celebrity faces, TransGAN achieved a Fréchet Inception Distance of 12.23 FID versus HDCGAN, which is designed for higher-res output and scored 8.44 FID.
Why it matters: The transformer takeover continues! Meanwhile, TransGAN’s expanding training mask gives its output the smooth look of convolutions with better coherence across generated images. Maybe such purposeful training schedules can stand in for certain architectural choices.
We’re thinking: Transformers, with their roots in language processing, might answer the age-old question of how many words an image is worth.
A MESSAGE FROM DEEPLEARNING.AI

Join Fei-Fei Li, Curtis Langlotz, and Andrew Ng to explore the future of AI in healthcare on April 29, 2021, at 10 a.m. Pacific Time. Co-hosted by DeepLearning.AI and Stanford Human-Centered Artificial Intelligence and supported by Stanford Center for Artificial Intelligence in Medicine & Imaging. Sign up and submit questions or topics

Who Watches the Welders?
A robot inspector is looking over the shoulders of robot welders.
What’s new: Farm equipment maker John Deere described a computer vision system that spots defective joints, helping to ensure that its heavy machinery leaves the production line ready to roll.
How it works: Like other manufacturers, John Deere uses robotic welders to assemble metal parts on its machines for farming, forestry, and construction. But industrial-strength welding has a longstanding problem: Bubbles of gas can form inside a joint as it cools, weakening it. An action recognition model developed by Intel spots such defects in real time.
- The model was trained on videos of good and bad welds. The clips were lit only by welding sparks, so that lighting conditions wouldn’t affect the model’s performance.
- The model is deployed on a ruggedized camera perched on the welding gun 12 to 14 inches away from the molten metal.
- When it detects a bad weld, it stops the robot and alerts human workers.
Behind the news: AI-powered quality assurance is gaining ground. Systems from Landing AI (a sister company to DeepLearning.AI) and others recognize defects in a growing number of manufacturing processes.
Why it matters: Skilled human inspectors are in short supply, expensive to hire, and not always able to inspect every joint in a factory full of robotic welders, so defects may go unnoticed until after a subpar part has become part of a larger assembly. A single welded part can cost up to $10,000. By spotting errors as they occur, computer vision can save manufacturers time and money.
We’re thinking: Good to see AI making sure the job is weld done
Large Language Models for Chinese
Researchers unveiled competition for the reigning large language model GPT-3.
What’s new: Four models collectively called Wu Dao were described by Beijing Academy of Artificial Intelligence, a research collective funded by the Chinese government, according to Synced Review.
Power quartet: Wu Dao’s constituent models were developed by over 100 scientists at leading Chinese universities and tech companies. In January, researchers associated with the project told Wired that it could help citizens navigate China’s bureaucracy, including the Beijing Motor Vehicles Administration.
- Wen Yuan is a 2.6 billion parameter language model that matched or exceeded GPT-3’s performance in Chinese- and English-language tasks. The group plans to scale the model up to 100 billion parameters later this year, according to a report in AI Technology Review.
- Wen Lan associates images and video with text. The learning algorithm enabled the researchers to train the model on 50 million image/text pairs containing a high percentage of negative examples: data labeled according to what it is not. The model outperformed CLIP on a text-image retrieval task and beat the previous top scorer on AIC-ICC image captioning by 5 percentage points.
- Wen Hui, with 11.3 billion parameters, is a text-generation model pretrained for general language skills. The team has spun out applications that write poetry, generate videos, and generate images from text prompts (shown above).
- Wen Su, based on BERT, is trained to predict the shapes of biomolecules including proteins and DNA from human blood cells and drug-resistant bacteria.
- The project also includes FastMoE, a method for training models with more than 1 trillion parameters, along with a 2 terabyte Chinese-language database.
Behind the news: The Beijing Academy of Artificial Intelligence was founded in 2018 to help the Chinese government achieve its goal of becoming the global center of AI. Its other projects include research into the cognitive roots of neural networks, a proposal for standardized AI notation, and a program to develop AI-specific computer chips.
Why it matters: This effort reflects China’s growing confidence and capability in AI. Such ambitious projects could also curb China’s AI brain drain, as many of its most talented engineers wind up leaving for work overseas.
We’re thinking: AI has long been dominated by organizations clustered in a few geographic hotspots. China’s effort to shift AI’s center of gravity away from the west could have far-reaching repercussions into the types of systems that get built and how they’re deployed.
Motion Mapper
In some animated games, different characters can perform the same actions — say, walking, jumping, or casting spells. A new system learned from unlabeled data to transfer such motions from one character to another.
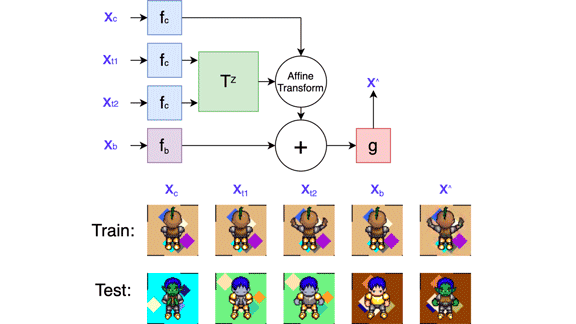
What’s new: Cinjon Resnick at New York University and colleagues at Nvidia, Technical University of Berlin, and Google developed a system designed to isolate changes in the pose of a two-dimensional figure, or sprite, and apply them to another sprite. While earlier approaches to solving this problem require labeled data, the new system is self-supervised.
Key insight: A 2D animation consists of three elements: a sprite, the sprite’s motion and any special effects, and a background (which remains static in this work). Separate neural networks optimizing a variety of loss terms can learn to disentangle these elements, compute their changes from frame to frame, and recombine them to produce a novel frame.
How it works: The system comprises four convolutional neural networks: two encoders, a transformation network, and a decoder. It generates a new frame given an image of a target sprite, a background, and two frames of animation showing a source sprite in motion — say, the initial frame and the one showing the pose, position, or other attributes to be mapped onto the target. During training, the images of the target sprite, background, and first frame of the animation were identical. The training and test sets consisted of several hundred animated video game characters performing various motions.
- One encoder generated a representation of the background based on the background reference image. The other generated separate representations of the target sprite and two animation frames.
- The transformation network used the representations of the two animation frames to generate a matrix describing how the sprite changed. The authors combined the various representations by multiplying the matrix by the target sprite’s representation and adding the background representation.
- The decoder used the result to produce an image of the target sprite, against the background, in the source sprite’s position in the second animation frame.
- The authors trained these components at once using a loss function consisting of three terms. The first term encouraged the background representation to remain constant from frame to frame. The second encouraged the transformed representation of the target sprite — that is, the transformation network’s matrix multiplied by the initial target sprite representation — to be similar to that of the source sprite in the second animation frame. The third minimized the pixel difference between the generated image and the second animation frame.
Results: The authors compared their system with Visual Dynamics. It underperformed the competition, achieving a mean squared error of ~20 versus ~16 — but Visual Dynamics is a supervised system that requires labeled training data.
Why it matters: A collection of networks that study different aspects of a dataset, and then compare and combine the representations they generate, can yield valuable information when labels aren’t available.
We’re thinking: Possibly a useful tool for animators. Definitely a new toy for remix culture.