
Dear friends,
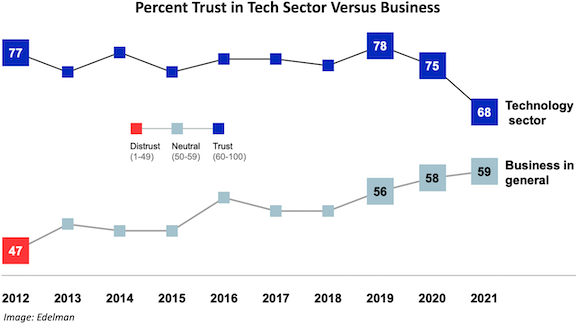
Each year, the public relations agency Edelman produces a report on the online public’s trust in social institutions like government, media, and business. The latest Edelman Trust Barometer contains a worrisome finding: While technology was ranked the most trusted industry in the U.S. last year, this year we plunged to ninth place. Trust in the tech industry fell to new lows in the majority of 27 countries surveyed.
Tech can be a huge force for moving the world forward, but many well meaning efforts will run into headwinds if we aren’t able to gain others’ trust. It’s more urgent than ever that we collectively act in a way that is genuinely deserving of the rest of society’s trust.
Trust is much harder to build than to destroy. One company that hypes AI can do more damage than 10 others that speak about it responsibly. One company that makes misleading statements can do more damage than 10 that speak honestly.
How can we regain trust? Several steps are needed, but to my mind, chief among them are:
- Straight talk. I think we’re all tired of hearing tech companies say they’re fighting for small businesses when they’re just fighting for their own bottom line. I realize that no company can address every issue under the sun, but when we speak about something, we owe it to the public to tell it like it is.
- Take responsibility. Tech’s influence on what people see and hear has a huge impact on their perception of reality. Our collective influence on automation has a huge impact on jobs. I hope that each organization will acknowledge the power it has and use it to benefit society.
- Engage and empathize. When someone who is honest and well meaning has a problem with what we do, our first step should be to try to understand their point of view, not to dismiss their concerns. Society has reasonable worries about tech’s concentration of power, fairness, and impact on jobs. Whether we agree or disagree in a certain instance, let's acknowledge the concern and see if we can address it honestly.
Trying to fool the public and government officials doesn’t work. We often read in the news about politicians who know little about tech, and say things that reflect their lack of understanding. But let me tell you this: Every large government has at least a handful of people who are tech-savvy enough to see through the spin to the heart of an issue. Companies shouldn’t try to fool people and instead do the harder — but more effective — work of solving problems thoughtfully.
On the plus side, 62 percent of respondents to Edelman’s survey agreed that employees have the power to force corporations to change. CEO aren’t the only people responsible for what companies do. All employees have a responsibility to help build trustworthy businesses. Wherever you work, I hope you’ll support straight talk, taking responsibility, and engaging and empathizing.
Keep learning!
Andrew
News

De-Facing ImageNet
ImageNet now comes with privacy protection.
What’s new: The team that manages the machine learning community’s go-to image dataset blurred all the human faces pictured in it and tested how models trained on the modified images on a variety of image recognition tasks. The faces originally were included without consent.
How it worked: The team used Amazon’s Rekognition platform to find faces in ImageNet’s nearly 1.5 million examples.
- Rekognition drew a bounding box around each of over 500,000 faces. (Some images contained more than one face.) Crowdsourced workers checked the model’s work and corrected errors where necessary. Then the team applied Gaussian blur to the area within bounding boxes.
- The authors trained 24 image recognition architectures on the original ImageNet and copies of the same architectures on the blurred version, and compared their performance. The models trained on the blurred images were, on average, less accurate by under 1 percent. However, the decline was severe with respect to objects typically found close to a face, such as masks (-8.71 percent) and harmonicas (-8.93 percent).
- They tested the blurred data’s effect on transfer learning by pretraining models using the unmodified and modified ImageNet and fine-tuning them for object recognition, scene recognition, object detection, and facial attribute classification (whether a person is smiling, wearing glasses, and the like). The models trained on blurred images performed roughly as well as those trained on unmodified ImageNet.
- The face-blurred ImageNet will become the new official version, according to VentureBeat.
Behind the news: This work is part of a wider movement toward protecting privacy in machine learning data. For instance, papers submitted to CVPR in recent years proposed models to automatically blur faces and license plates in Google Street View as well as data for training autonomous vehicles, and action recognition models.
Why it matters: Machine learning datasets need not violate privacy. We can develop datasets that both protect privacy and train good models.
We’re thinking: Any loss of accuracy is painful, but a small loss is worthwhile to protect privacy. There’s more to life than optimizing test-set accuracy! We expect that most ImageNet-trained applications won’t suffer from the change, as they don’t involve objects that typically appear near to faces. Fine-tuning on a dataset obtained with permission might help for the rest.
.gif?upscale=true&name=SEER%20(1).gif)
Pretraining on Uncurated Data
It’s well established that pretraining a model on a large dataset improves performance on fine-tuned tasks. In sufficient quantity and paired with a big model, even data scraped from the internet at random can contribute to the performance boost.
What’s new: Facebook researchers led by Priya Goyal built SElf-supERvised (SEER), an image classifier pretrained on a huge number of uncurated, unlabeled images. It achieved better fine-tuned ImageNet accuracy than models pretrained on large datasets that were curated to represent particular labels.Key insight: Large language models pretrained on billions of uncurated documents found in the wild, such as GPT-3, have achieved state-of-the-art performance after fine-tuning on a smaller dataset. Computer vision should benefit likewise from such scale.
How it works: The authors used a 1.3-billion parameter RegNet, a convolutional neural network architecture similar to ResNet, pretrained on 1 billion images randomly scraped from Instagram.
- The pretraining procedure followed SwAV, which was devised by several of the same researchers. SwAV receives representations — in this case, from the RegNet — and learns to group related images into a number of clusters by emphasizing similarities among them (similar to contrastive learning).
- The authors fine-tuned the model on over 1 million images from ImageNet.
Results: SEER achieved 84.2 percent top-1 accuracy on the ImageNet test set, 1.1 percent better than the best previous self-supervised, pretrained model (a ResNet of 795 million parameters pretrained on ImageNet using SimCLRv2). It was 4.3 percentage points better than a 91-million parameter ViT pretrained on JFT-300M, a curated dataset of 300 million images from Google Search. SEER also excelled at few-shot learning: Fine-tuned on 10 percent of ImageNet, it achieved 77.9 percent accuracy, 2.2 percentage points lower than a SimCLRv2 model pretrained on 100 percent of ImageNet and fine-tuned on 10 percent of ImageNet.
Why it matters: Scraping the internet could be as productive in computer vision as it has been in language processing. Just keep in mind that training models on such data risks violating privacy and consent as well as absorbing the various biases — including objectionable social biases — inherent on the internet.
We’re thinking: This paper suggests a tradeoff between the costs of building a curated dataset and training on a larger corpus plucked from the wild. If the cost of curation is high for your application, maybe you can cut it and spend more on training.

Would Your Doctor Take AI’s Advice?
Some doctors don’t trust a second opinion when it comes from an AI system.
What’s new: A team at MIT and Regensburg University investigated how physicians responded to diagnostic advice they received from a machine learning model versus a human expert.
How it works: The authors recruited doctors to diagnose chest X-rays.
- The physicians fell into two groups: 138 radiologists highly experienced in reading X-rays and 127 internal or emergency medicine specialists with less experience in that task.
- For each case, the doctors were given either accurate or inaccurate advice and told that it was generated by either a model or human expert.
- The physicians rated the advice and offered their own diagnosis.
Results: The radiologists generally rated as lower-quality advice they believed was generated by AI. The others rated AI and human advice to be roughly of equal quality.
Both groups made more accurate diagnoses when given accurate advice, regardless of its source. However, 27 percent of radiologists and 41 percent of the less experienced offered an incorrect diagnosis when given inaccurate advice.
Behind the news: AI-powered diagnostic tools are proliferating and becoming more widely accepted in the U.S. and elsewhere. These tools may work about as well as traditional methods at predicting clinical outcomes. Those that work well may only do so on certain populations due to biased training data.
Why it matters: It’s not enough to develop AI systems in isolation. It’s important also to understand how humans use them. The best diagnostic algorithm in the world won’t help if people don’t heed its recommendations.
We’re thinking: While some doctors are skeptical of AI, others may trust it too much, which also can lead to errors. Practitioners in a wide variety of fields will need to cultivate a balance between skepticism and trust in machine learning systems. We welcome help from the computer-human interface community in wrestling with these challenges.
A MESSAGE FROM DEEPLEARNING.AI
-1.png?upscale=true&name=The%20Batch%20(1)-1.png)
We've updated our Deep Learning Specialization with the latest advances. The new program covers TensorFlow 2 as well as advanced architectures like U-Net, MobileNet, and EfficientNet. Stay tuned for transformers! Enroll now
New Life for Old Songs
Neural networks can tease apart the different sounds in musical recordings.
What’s new: Companies and hobbyists are using deep learning to separate voices and instruments in commercial recordings, Wired reported. The process can improve the sound of old recordings and opens new possibilities for sampling, mash-ups, and other fresh uses.
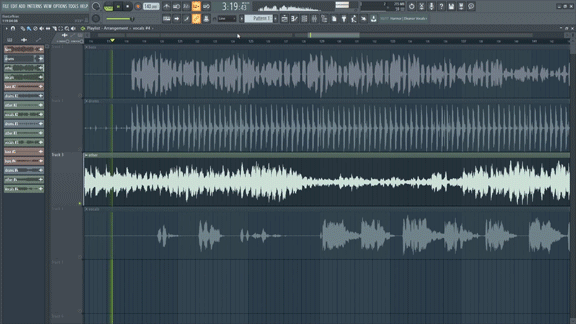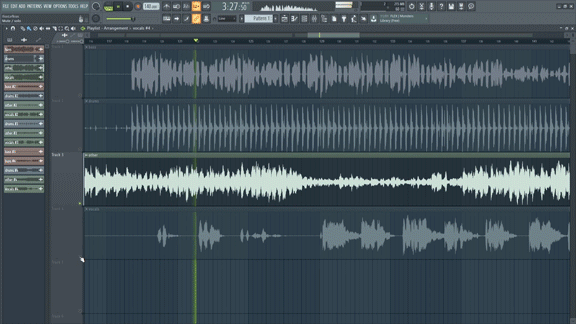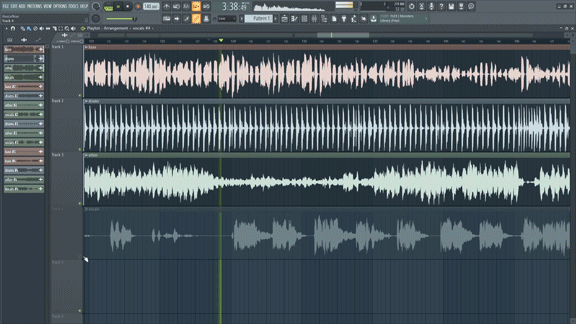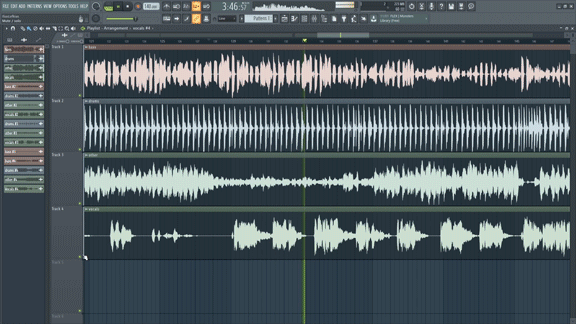
How it works: Finished recordings often combine voices, instruments, and other sounds recorded in a multitrack format into a smaller number of audio channels; say, one for mono or two for stereo. The mingling of signals limits how much the sonic balance can be changed afterward, but neural networks have learned to disentangle individual sounds — including noise and distortion — so they can be rebalanced or removed without access to the multitrack recordings.
- Audio Research Group was founded by an audio technician at Abbey Road Studios, who developed a deep learning system to remix the Beatles’ 1964 hit, “She Loves You,” which was produced without multitracking.
- Audionamix separates mono recordings into tracks for vocals, drums, bass guitar, and other sounds. The service has been used to manipulate old recordings for use in commercials and to purge television and film soundtracks of music, inadvertently playing in the background, that would be expensive to license.
- French music streaming service Deezer offers Spleeter, an open-source system that unmixes recordings (pictured above). Users have scrubbed vocals to produce custom karaoke tracks, create oddball mashups, and cleanse their own recordings of unwanted noises.
Why it matters: Many worthwhile recordings are distorted or obscured by noises like an audience’s cheers or analog tape hiss, making the quality of the musicianship difficult to hear. Others could simply use a bit of buffing after decades of improvement in playback equipment. AI-powered unmixing can upgrade such recordings as well as inspire new uses for old sounds.
We’re thinking: Endless remixes of our favorite Taylor Swift tracks? We like the sound of that!
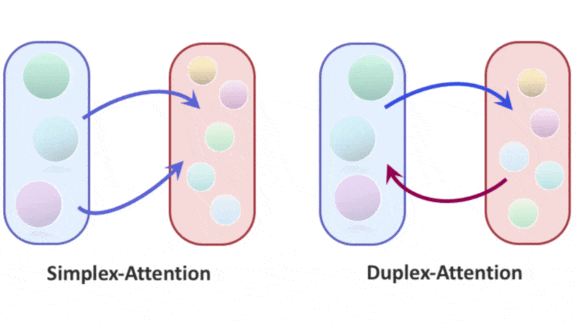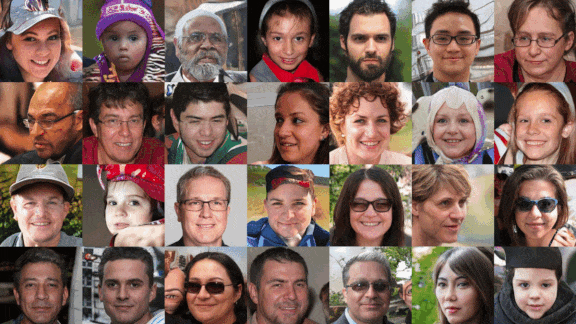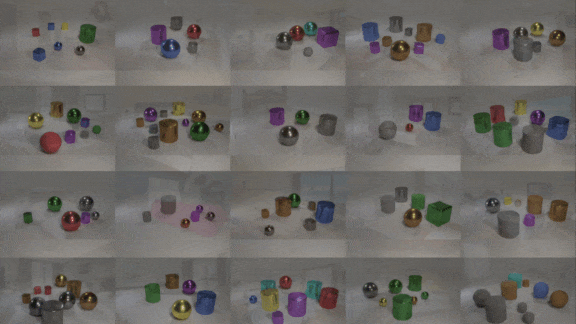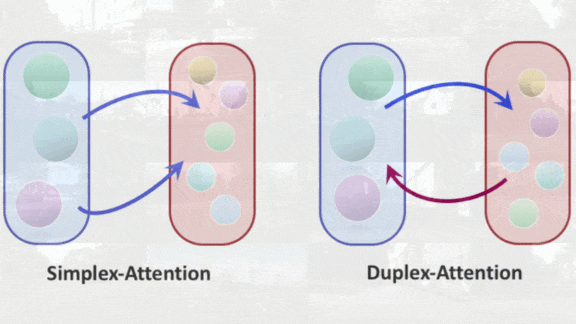
Attention for Image Generation
Attention quantifies how each part of one input affects the various parts of another. Researchers added a step that reverses this comparison to produce more convincing images.
What’s new: Drew A. Hudson at Stanford and C. Lawrence Zitnick at Facebook chalked up a new state of the art in generative modeling by integrating attention layers into a generative adversarial network (GAN). They call their system GANsformer.
Key insight: Typically, a GAN learns through competition between a generator that aims to produce realistic images and a discriminator that judges whether images are generated or real. StyleGAN splits the generator into (a) a mapping network and (b) a synthesis network, and uses the output of the mapping network to control high-level properties (for example, pose and facial expression) of an image generated by the synthesis network. The output of the mapping layer can be viewed as a high-level representation of the scene, and the output of each layer of the synthesis network as a low-level representation. The authors devised a two-way version of attention, which they call duplex attention, to refine each representation based on the other.
How it works: GANsformer is a modified StyleGAN. The authors trained it on four types of subject matter: faces in FFHQ; scenes composed of cubes, cylinders, and spheres in CLEVR; pictures of bedrooms in LSUN; and urban scenes in Cityscapes.
- Given a random vector, the mapping network produced an intermediate representation via a series of fully connected layers. Given a random vector, the synthesis network produced an image via alternating layers of convolution and duplex attention.
- The authors fed the mapping network's intermediate representation to the synthesis network’s first duplex attention layer.
- Duplex attention updated the synthesis network’s representation by calculating how each part of the image influenced the parts of the intermediate representation. Then it updated the intermediate representation by calculating how each of its parts influenced the parts of the image. In this way, the system refined the mapping network’s high-level view according to the synthesis network’s low-level details and vice versa.
- The discriminator used duplex attention to iteratively hone the image representation along with a learned vector representing general scene characteristics. Like the synthesis network, it comprised alternating layers of convolution and duplex attention.
Results: GANsformer outperformed the previous state of the art on CLEVR, LSUN-Bedroom, and Cityscapes (comparing Fréchet Inception Distance based on representations produced by a pretrained Inception model). For example, on Cityscapes, GANsformer achieved 5.7589 FID compared to StyleGAN2’s 8.3500 FID. GANsformer also learned more efficiently than a vanilla GAN, StyleGAN, StyleGAN2, k-GAN, and SAGAN. It required a third as many training iterations to achieve equal performance.
Why it matters: Duplex attention helps to generate scenes that make sense in terms of both the big picture and the details. Moreover, it uses memory and compute efficiently: Consumption grows linearly as input size increases. (In transformer-style self-attention, which evaluates the importance of each part of an input with respect to other parts of the same input, memory and compute cost grows quadratically with input size.)
We’re thinking: Transformers, which alternate attention and fully connected layers, perform better than other architectures in language processing. This work, which alternates attention and convolutional layers, may bring similar improvements to image processing.