
Dear friends,
Over the past weekend, I happened to walk by a homeless encampment and went over to speak with some of the individuals there.
I spoke with a homeless man who seemed to be partially speaking with me, and partially speaking with other people that I could not see. I also spoke with a woman who said she fled her abusive home at the age of 21, and wished that she had a tent — like some of the others — so she could sleep with something over her head rather than be exposed to the elements at night.
I feel grateful and privileged every day to have enough food, to have a place to live, and to even have a modern computer with internet access.
I’m going to come out and say this (knowing some people will disagree): Every one of us has an obligation to serve others.
While we can try to help a handful of people at a time with a meal or a donation — and this is to be celebrated — I don’t know how to systematically help the large and growing number of homeless. But I will keep thinking on this, and am determined to find a way. Even as we build amazing products and technologies, let’s keep thinking about how we can scalably serve the many wonderful, resilient individuals like the ones I met last weekend.
Keep learning!
Andrew
News

Social Engagement vs. Social Good
Facebook’s management obstructed the architect of its recommendation algorithms from mitigating their negative social impact, MIT Technology Review reported.
What’s new: The social network focused on reining in algorithmic bias against particular groups of users at the expense of efforts to reduce disinformation and hate speech, according to an in-depth profile of Joaquin Quiñonero Candela, who designed Facebook’s early recommenders and now leads its Responsible AI team.
The story: The article traces Quiñonero’s effort to balance the team’s mission to build trustworthy technology with management’s overriding priorities: boosting user engagement and avoiding accusations that it favored one political faction over another.
- Quiñonero joined Facebook in 2012 to lead an effort to build models that matched advertisements with receptive users. That effort successfully boosted user engagement with ads, so he designed similar systems to fill news feeds with highly engaging posts, comments, and groups.
- His team went on to build a machine learning development platform, FBLearner Flow, that was instrumental to helping Facebook scale up its AI efforts. It enabled the company to build, deploy, and monitor over a million models that optimize engagement through tasks like image recognition and content moderation, inadvertently amplifying disinformation and hate speech.
- In 2018, Quiñonero took charge of Responsible AI to investigate and resolve such issues. The team developed models that attenuated the flow of disinformation and hate speech, but they diminished engagement, and management redirected and disincentivized that work.
- Facebook’s leadership, under pressure from critics who charged that the network favored left-wing over right-wing political views, directed the team to focus on mitigating bias. The new direction diverted attention away from staunching extremist content and toward tools like Fairness Flow, which measures models’ relative accuracy when analyzing data from different user demographics.
The response: Facebook denied that it interfered with moves to reduce disinformation and hate speech. It also denied that politics motivated its focus on mitigating bias.
- Facebook head of AI research Yann LeCun said the article mischaracterized how Facebook ranks content, Quiñonero’s role, and how his group operates.
- The article made little mention of the company’s efforts to reduce the spread of divisive content, detect hateful memes, and remove hate speech. AI flagged around 95 percent of the hate speech removed from the network between last July and September, according to the company.
- Facebook publicly supports regulations that would govern social media including rules that would limit the spread of disinformation.
Why it matters: Facebook, like many AI companies, is struggling to balance business priorities with its social impact. Teams like Responsible AI are crucial to achieving that balance, and business leaders need to give them authority to set technical priorities and limits.
We’re thinking: The powers of AI can put machine learning engineers in the difficult position of mediating between business priorities and ethical imperatives. We urge business leaders to empower employees who try to do the responsible thing rather than throttling their work, even if it negatively impacts the bottom line.
Old Drugs for New Ailments
Many medical drugs work by modulating the body’s production of specific proteins. Recent research aimed to predict this activity, enabling researchers to identify drugs that might counteract the effects of Covid-19.
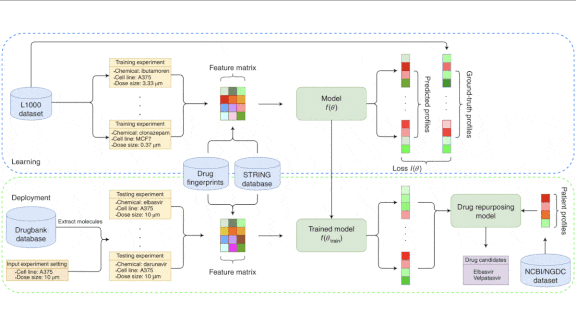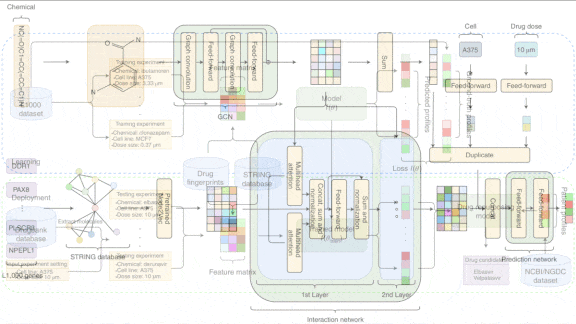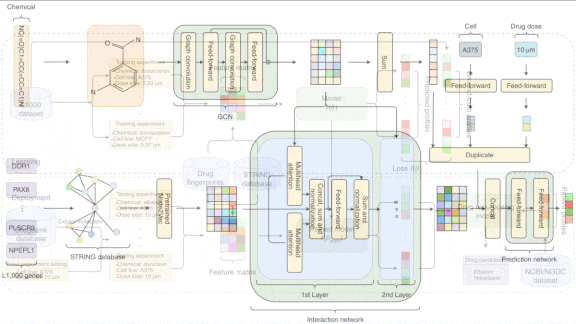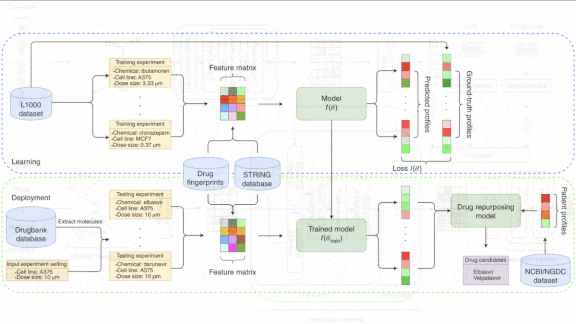
What’s new: Thai-Hoang Pham and colleagues at The Ohio State University and The City University of New York developed DeepCE, a system designed to predict how particular drugs will influence the amounts of RNA, and therefore the amounts of various proteins, produced by a cell.
Key insight: In machine learning, attention layers learn to represent how the various parts of two input sequences interact with one another. In biology, genes mediate the production of RNA, while drugs can affect the action of genes. Given separate embeddings that represent genes and chemical structures of drugs, attention can capture how a drug affects RNA production.
How it works: Given a drug, a dose, and a line of cells cloned from a particular patient, DeepCE predicts the amount of RNA produced by each of roughly 1,000 genes. (Collectively, this information constitutes a gene expression profile). The training and test data included more than 600 drugs for a total of over 4,000 gene expression profiles from seven human cell lines in the L1000 database.
- The authors used the node2vec method to generate embeddings of proteins in a database of relationships among genes and proteins. From these embeddings, they extracted representation of the genes in L1000.
- A chemical can be represented as a graph in which each node stands for an element in the periodic table. The authors used a convolutional graph neural network to generate embeddings of drugs in L1000. The network represented each node of a given compound based on its surrounding nodes.
- Given the gene and drug embeddings, a multi-headed attention network generated a matrix that represented gene-drug and gene-gene interactions. Given information about drug doses and cell lines in L1000, separate feed-forward networks generated embeddings of these factors.
- A fully connected network accepted all of these representations and learned how to predict RNA production.
Results: The authors compared DeepCE’s predictions with those of several baseline methods using the Pearson correlation coefficient, a measure of the correlation between predictions and ground truth. DeepCE outperformed all of them with a score of 0.4907. The next-best method, a two-layer feed-forward network, scored 0.4270. They also used DeepCE to look for existing drugs that might treat Covid-19. They compared the predictions for more than 11,000 drugs with corresponding profiles of Covid-19 patients, looking for the greatest negative correlations — an indicator that the drug would fight the illness. Of 25 drugs surfaced by DeepCE, at least five already had shown potential as Covid-19 treatments; others had been used for different viruses with similar symptoms.
Why it matters: Complex datasets may have features that aren’t processed easily by a single network. By using a different network for each type of input and combining their outputs, machine learning engineers can extract useful information that otherwise might be inaccessible.
We’re thinking: The next blockbuster antiviral (or antidepressant, anti-inflammatory, or heart medicine) may already be on pharmacy shelves. Wouldn’t it be wonderful if deep learning found it?
Who Audits the Auditors?
Auditing is a critical technique in the effort to build fair and equitable AI systems. But current auditing methods may not be up to the task.
What’s new: There’s no consensus on how AI should be audited, whether audits should be mandatory, and what to do with their results, according to The Markup, a nonprofit investigative reporting outfit.
What’s Happening: Auditing firms are doing brisk business analyzing AI systems to determine whether they’re effective and fair. But such audits are often limited in scope, and they may lend legitimacy to models that haven’t been thoroughly vetted.
- HireVue, a vendor of human resources software, used an independent company to audit one of its hiring tools by interviewing stakeholders about possible problems. But the audit stopped short of evaluating the system’s technical design.
- An audit of hiring software made by Pymetrics, which evaluates candidates through simple interactive games (illustrated above), did examine its code and found it largely free of social biases. But the audit didn’t address whether or not the software highlighted the best applicants for a given job.
- AI vendors are under no obligation to have their systems audited or make changes if auditors find problems.
Behind the news: In the U.S., members of Congress and the New York City Council have proposed bills that would require companies to audit AI systems. The laws have yet to be passed.
Why it matters: AI systems increasingly affect the lives of ordinary people, influencing whether they land a job, get a loan, or go to prison. These systems must be trustworthy — which means the audits that assess them must be trustworthy, too.
We’re thinking: Makers of drugs and medical devices must prove their products are effective and safe. Why not makers of AI, when its output can dramatically impact people’s lives? The industry should agree on standards and consider making audits mandatory for systems that affect criminal justice, allocating health care resources, and offering loans.
A MESSAGE FROM DEEPLEARNING.AI

You’re invited to MLOps: From Model-Centric to Data-Centric AI, a special presentation by Dr. Andrew Ng on Wednesday, March 24, 2021. Learn about the fundamental skills required for the next generation of machine learning practitioners.

Your Words, Their Voices
Voice clones — the audio counterpart to deepfaked images — are poised to invade popular media and entertainment.
What’s new: Professionals and amateurs alike are using AI to emulate the voices of human actors, Wired reported.
Cloned like a pro: Game developers and marketers are cloning voices to save money and make their products more immersive.
- Sonantic, a UK-based startup, claims it can reproduce an actor’s voice from less than 20 minutes of training data. Its technology enables media creators to impart a variety of emotional inflections — such as angry, happy, or fearful — at varying levels of intensity. Sonantic shares revenue generated by voice cloning with the human originals.
- U.S.-based Replica Studios trains its system by having actors read 20 short sentences that cover the gamut of English phonetics. The company’s modification of the game Cyberpunk 2077 enables non-player characters to address the player by name. Like Sonantic, Replica shares voice-cloning revenue with human speakers.
- MSCHF, a marketing firm, synthesized the voice of rapper Gucci Mane and put his doppelgänger to work narrating Pride and Prejudice, Don Quixote, and other literary classics.
Remixers join in: Much of the entertainment industry is sorting out who owns which rights to an actor’s voice, but some amateur content creators have embraced the technology with abandon.
- Tim McSmythers, a researcher who goes by the handle Speaking of AI on social media, trained models to mimic the voices of celebrities like Adam Driver, Ellen Degeneres, and Jerry Seinfeld and composite their likenesses into famous movie and TV scenes. Our favorite: Homer Simpson telling Anakin Skywalker the legend of Darth Plagueis the Wise in a clip from Star Wars: The Phantom Menace.
- 15.ai, previously profiled in The Batch, allows users to generate custom dialogue using character voices from My Little Pony, Rick and Morty, and other games and TV shows. (The site is currently on hiatus.)
Why it matters: Voice cloning opens new avenues of creativity and productivity. For instance, generated voices can help developers road-test dialogue before bringing in the human talent and expand the conversational role of background characters. Yet the technology also holds potential for abuse, and guarding against them will require new kinds of vigilance.
We’re thinking: Have you ever been yelled at? We would love to build a system to transcribe the yeller’s words, and then re-synthesize their voice in a more polite tone.
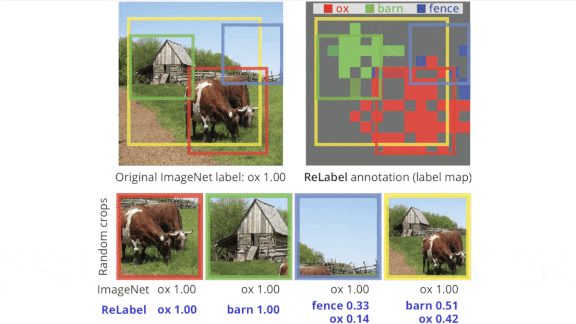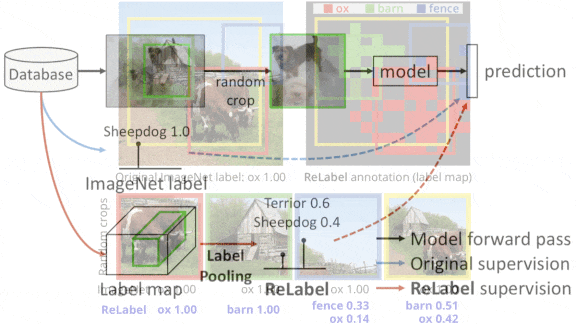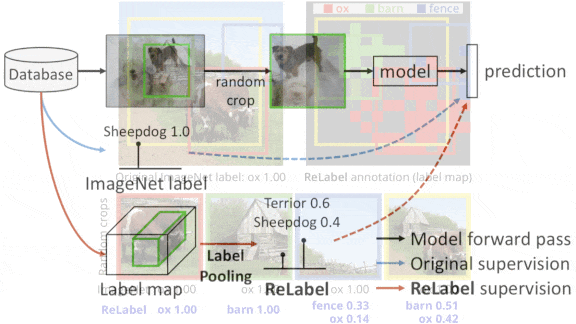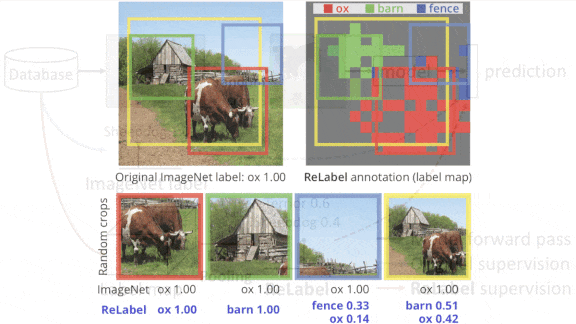
Good Labels for Cropped Images
In training an image recognition model, it’s not uncommon to augment the data by cropping original images randomly. But if an image contains several objects, a cropped version may no longer match its label. Researchers developed a way to make sure random crops are labeled properly.
What’s new: Led by Sangdoo Yun, a team at Naver AI Lab developed ReLabel, a technique that labels any random crop of any image. They showcased their method on ImageNet
Key insight: Earlier work used knowledge distillation: Given a randomly cropped image, a so-called student model learned from labels predicted by a teacher model. That approach requires that the teacher predict a label for each of many cropped versions of a given example. In this work, an image was divided into a grid, and the teacher predicted a label for each grid square, creating a map of regions and their labels that was used to determine a label for any given portion of the image. This way, the teacher could examine each example only once, making the process much more efficient.
How it works: The teacher was an EfficientNet-L2 that had been pretrained on Google’s JFT-300M dataset of 300 million images. The student was a ResNet-50.
- The authors removed the teacher’s final pooling layer, so the network would predict a label for each region in a 15×15 grid instead of one label for the whole image. They used the teacher to predict such a “label map” for every image in ImageNet.
- The researchers trained the student using random crops of images in ImageNet and their corresponding label maps. Given a cropped image, they used RoIAlign to find the regions within the label map that aligned with the crop and pooled the corresponding regions into a vector. Then they used softmax to turn the vector into the probability distribution that is the label.
Results: The researchers compared a ResNet-50 trained on ImageNet using their labels to one trained using the standard labels. The new labels improved test classification accuracy from 77.5 percent to 78.9 percent.
Why it matters: Images on social and photo-sharing sites tend to be labeled with tags, but a tag that reads, say, “ox” indicates only that an ox appears somewhere in the image. This approach could enable vision models to take better advantage of data sources like this.
We’re thinking: A bounding box around every object of interest would ameliorate the cropping problem — but such labels aren’t always easy to get.