
Dear friends,
When a lot of data is available, machine learning is great at automating decisions. But when data is scarce, consider using the data to augment human insight, so people can make better decisions.
Let me illustrate this point with A/B testing. The common understanding of the process is:
- Build two versions of your product. For example, on the DeepLearning.AI website, one version might say, “Build your career with DeepLearning.AI,” and another, “Grow your skills with DeepLearning.AI.”
- Show both versions to groups of users chosen at random and collect data on their behavior.
- Launch the version that results in better engagement (or another relevant metric).
But this is not how I typically use A/B testing. Often I run such tests to gain insight, not to choose which product to launch. Here‘s how it works:
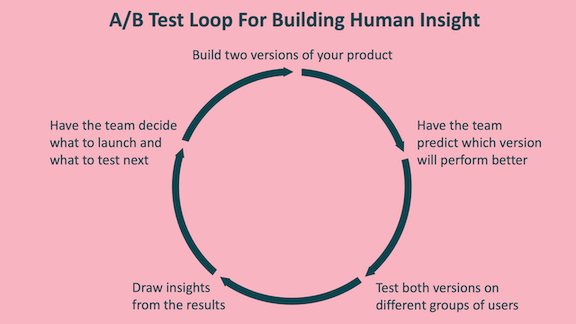
- Build two versions of your product.
- Have the product team make predictions about which version will perform better.
- Test both versions and collect data on user behavior.
- Show the results to the team, and let them influence their beliefs about users and their reactions. If someone says, “Oh, that’s weird. I didn’t realize our users wanted that!” then we’ve learned something valuable.
- Based on the team’s revised intuitions, have them decide what to launch. It could be version A, version B, or something else.
- Repeat until you reach diminishing returns in terms of learning.
On major websites, where the developers may run thousands of automated experiments a day — for example, trying out different ad placements to see who clicks on what — it’s not possible for people to look at every experimental result to hone their intuition. In this case, fully or mostly automated decision making works well. An algorithm can try multiple versions and pick the one that achieves the best metrics (or use the data to learn what to show a given user). But when the number of daily experiments is small, using such experiments to hone your intuition allows you to combine limited trials with human insight to arrive at a better decision.
Beyond A/B testing, the same concept applies to building machine learning systems. If your dataset size is modest, combining data-derived insights with human insights is critical. For example, you might do careful error analysis to derive insights and then design a system architecture that captures how you would carry out the task. If you have a massive amount of data, more automation — perhaps a large end-to-end learning algorithm — can work. But even then, error analysis and human insight still play important roles.
Keep learning!
Andrew
News

Medical AI’s Hidden Data
U.S. government approval of medical AI products is on the upswing — but information about how such systems were built is largely unavailable.
What’s new: The U.S. Food and Drug Administration (FDA) has approved a plethora of AI-driven medical systems. But, unlike drugs, there’s a dearth of publicly available information about how well they work, according to an investigation by the health-news website Stat News.
What they found: The FDA doesn’t require makers of AI systems to provide systematic documentation of their development and validation processes, such as the composition of training and test datasets and the populations involved. The data actually provided by manufacturers varies widely.
- Stat News compiled a list of 161 products that were approved between 2012 and 2020. Most are imaging systems trained to recognize signs of stroke, cancer, or other conditions. Others monitor heartbeats, predict fertility status, or analyze blood loss.
- The makers of only 73 of those products disclosed the number of patients in the test dataset. In those cases, the number of patients ranged from less than 100 to more than 15,000.
- The manufacturers of fewer than 40 products revealed whether the data they used for training and testing had come from more than one facility — an important factor in proving the product’s general utility. Makers of 13 products broke down their study population by gender. Seven did so by race.
- A few companies said they had tested and validated their product on a large, diverse population, but that information was not publicly available.
Behind the news: The rate at which the FDA approves medical AI products is rising and could reach 600 products annually by 2025, according to Stat News.
- Most such products currently are approved under a standard that requires demonstrating “substantial equivalence” in safety and efficacy to similar, already-approved systems. This standard, known as 510(k), was established in 1976 without medical AI in mind.
- A recent FDA action plan for regulating AI aims to compel manufacturers to evaluate their products more rigorously.
Why it matters: Without consistent requirements for testing and reporting, the FDA can’t ensure that AI systems will render accurate diagnoses, recommend appropriate treatments, or treat minority populations fairly. This leaves health care providers to figure out for themselves whether a product works as advertised with their particular equipment and patients.
We’re thinking: If you don’t know how an AI system was trained and tested, you can’t evaluate the risk of concept or data drift as real-world conditions and data distributions change. This is a problem even in drug testing: A vaccine validated against the dominant Covid-19 variant may become less effective as the virus mutates. Researchers are developing tools to combat such drifts in AI systems. Let’s make sure they’re deployed in medical AI.
Facing Failure to Generalize
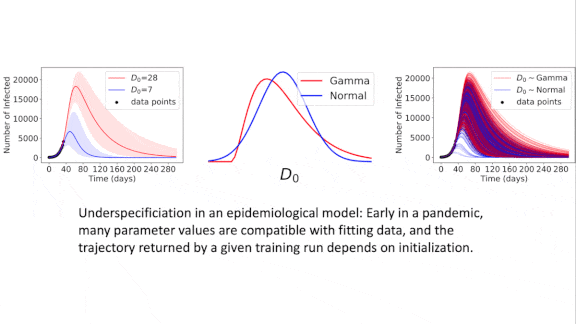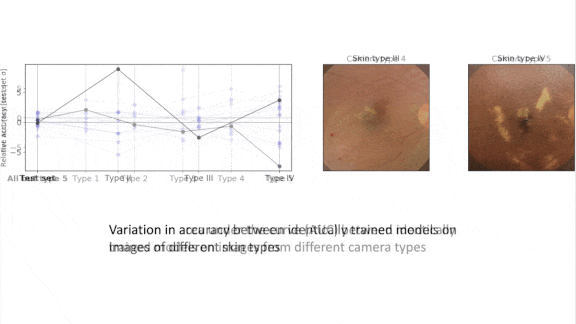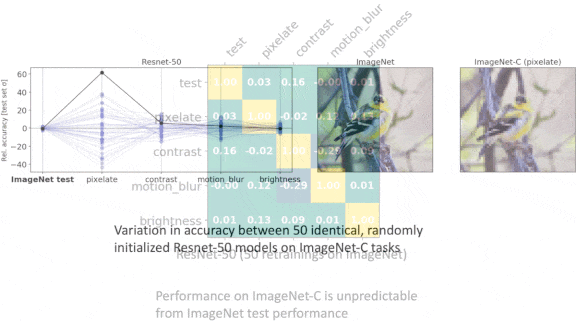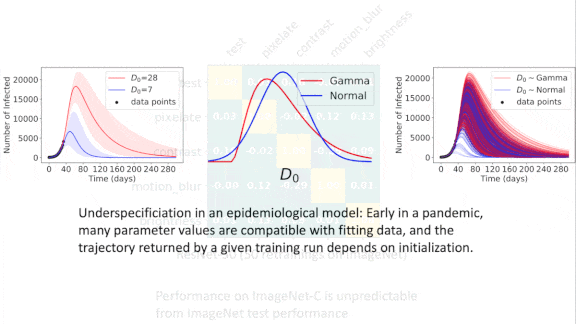
The same models trained on the same data may show the same performance in the lab, and yet respond very differently to data they haven’t seen before. New work finds this inconsistency to be pervasive.
What’s new: Researchers explored this largely unexamined phenomenon, which they call underspecification. The team, led by Alexander D’Amour, Katherine Heller, and Dan Moldovan, spanned Google, MIT, Stanford, University of California San Diego, U.S. Department of Veterans Affairs, Aravind Eye Hospital, and Shri Bhagwan Mahavir Vitreo-Retinal Services.
Key insight: A well specified model pipeline — a model architecture, hyperparameters, training and test sets, and training procedure — should produce models that behave consistently. In practice, though, the same pipeline can produce many distinct models that achieve near-optimal performance, only some of which generalize to real-world conditions. Building a plethora of models and testing each one is the only way to know which is which.
How it works: The authors built many models per pipeline across a range of machine learning applications. Then they compared their performance on an appropriate test set and alternative data. The tests fell into three categories:
- The authors probed whether models produced using the same pipeline performed equally well on particular subsets of a test set. For example, with vision models that were trained to recognize an eye disease, they compared performance on images taken by different cameras.
- They compared performance on an established test set and a similar one with a different distribution. For instance, they compared the performance of ImageNet-trained models on both ImageNet and ObjectNet, which depicts some ImageNet classes from different angles and against different backgrounds.
- They also compared performance on examples that were modified. For instance, using a model that was trained to evaluate similarity between two sentences, they switched genders, comparing the similarity of “a man is walking” and “a doctor is walking” versus “a woman is walking” and “a doctor is walking.”
Results: The authors found highly variable performance in models produced by identical model pipelines for several practical tasks in language, vision, and healthcare. For instance, they trained 50 ResNet-50 models on ImageNet using the same pipeline except for differing random seeds. On ImageNet’s test set, the standard deviation from top-1 accuracy was 0.001. On ImageNet-C, which comprises corrupted ImageNet examples that are still recognizable to humans, the standard deviation was 0.024. A given model’s performance on one dataset didn’t correlate with its performance on the other.
Why it matters: If our models are to be useful and trustworthy, they must deliver consistent results. Underspecification is a significant barrier to that goal.
We’re thinking: This work offers a helpful framework to evaluate the model performance on similar-but-different data. But how can we specify model pipelines to produce consistent models? We eagerly await further studies in this area.
Computation as a National Resource
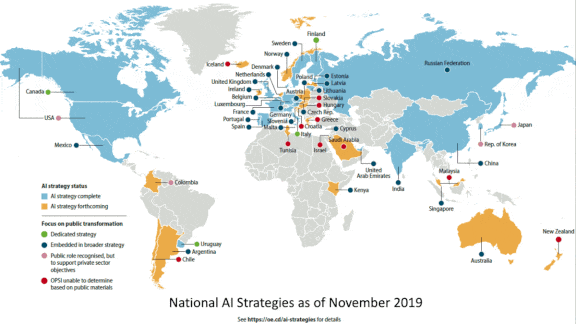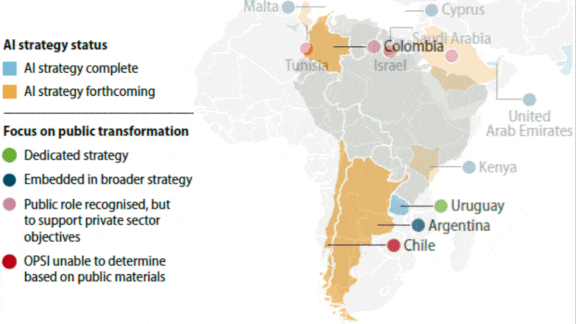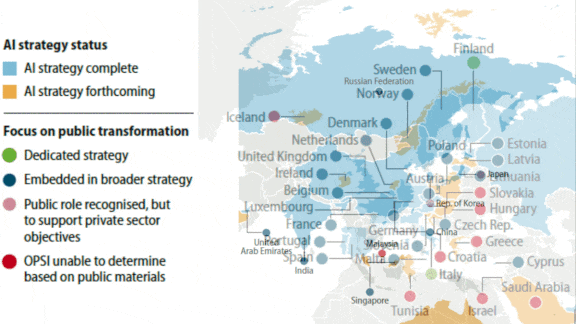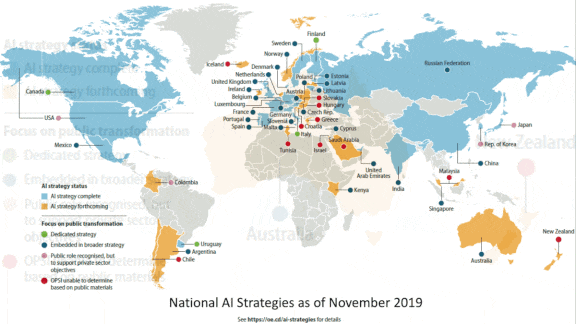
How much processing power do various nations have on hand to drive their AI strategy? An international trade group aims to find out.
What’s new: The Organisation for Economic Co-operation and Development (OECD) is launching an effort to measure the computing capacity available in countries around the world. The organization, which serves 37 member nations, wants to help leaders invest wisely in AI by giving them a sense of their computational assets and how they compare to their peers.
How it works: A task force led by Nvidia vice president Keith Strier will include around 30 policy makers, researchers, hardware experts, and data center operators.
- The task force will develop a framework for benchmarking national and regional processing resources.
- Once the framework is in place, they’ll survey each country, focusing on government agencies and national AI clouds. They will omit military capabilities, commercial services, and edge devices.
- It’s unclear whether the survey will include public-private partnerships, such as Google’s collaboration with Aramco, Saudi Arabia’s state-run oil company, to provide cloud infrastructure for large companies.
Behind the news: The project is part of OECD’s One AI initiative, which also classifies AI systems, develops trustworthy AI, and crafts guidance on AI policies. The organization developed a set of AI principles that 40 nations had signed as of June.
Why it matters: The OECD has cataloged over 300 AI policy initiatives across 60 countries, but the computing power available to each is hugely unequal. A tool that helps policymakers see where investment is most needed could help them set sensible targets.
We’re thinking: Governments have an incentive to improve their standard metrics, such as gross domestic product. Companies that sell processing power have an incentive to encourage governments to boost those metrics by investing in computing infrastructure. If this dynamic provides more resources to AI researchers, we’re all for it.
A MESSAGE FROM DEEPLEARNING.AI

Join us for an Expert Panel, “Optimizing BizOps with AI,” presented in collaboration with FourthBrain on Feb. 25, 2021, at 4 p.m. Pacific Standard Time! Technical leaders at Amazon, Samsung, and Uber will explain how they’re deploying AI to improve business efficiency. RSVP

How Art Makes AI Feel
An automated art critic spells out the emotional impact of images.
What’s new: Led by Panos Achlioptas, researchers at Ecole Polytechnique, King Abdullah University, and Stanford University trained a deep learning system to generate subjective interpretations of art.
How it works: The robot reviewer is a showcase for the authors’ dataset ArtEmis, which combines images with subjective commentary. ArtEmis comprises around 81,500 paintings, photos, and other images from the online encyclopedia WikiArt along with crowdsourced labels that describe the emotional character of each work (“amusement,” “awe,” “sadness,” and so on) and brief explanations of how the work inspired those emotions (to explain amusement, for instance, “His mustache looks like a bird soaring through the clouds.”)
- The researchers trained a model based on Show-Attend-Tell, which combines a convolutional neural network and an LSTM outfitted with attention, to replicate the annotations.
- As a baseline, they used a ResNet-32 pretrained on ImageNet. Given a test image, they used a nearest neighbor search to find the most similar image in the ArtEmis training set. Then they chose one of that image’s captions at random.
Results: Volunteers guessed whether a given caption came from Show-Attend-Tell or a human, and roughly half the model’s captions passed as human-written. Nonetheless, the authors found the model’s output on average less accurate, imaginative, and diverse than the human annotations. The team also compared generated and baseline captions using a number of natural language metrics. Show-Attend-Tell achieved a ROUGE-L score of 0.295 versus the baseline 0.208 (a perfect score being 1.0). It achieved a METEOR score of 0.139 versus the baseline 0.1 (out of a perfect 1.0).
Behind the news: Other AI systems have probed the elusive relationship between images and emotions, especially images of human faces. For instance, a GAN has been built to generate synthetic faces that express one of eight emotions, and some software vendors dubiously claimed to evaluate job candidates based on facial expressions.
Why it matters: When humans look at an image, they perceive meanings beyond the subject matter displayed in the frame. Systems that help people make sense of the world could benefit from the ability to make such subjective judgments, whether they’re evaluating artworks, product recommendations, medical images, or flaws in manufactured goods.
We’re thinking: Show-Attend-Tell’s soft deterministic attention mechanism makes us feel like we’re looking at a dream.
Better Zero-Shot Translations
Train a multilingual language translator to translate between Spanish and English and between English and German, and it may be able to translate directly between Spanish and German as well. New work proposes a simple path to better machine translation between languages that weren’t explicitly paired during training.
What’s new: Danni Liu and researchers at Maastricht University and Facebook found that a small adjustment in the design of transformer networks improved zero-shot translations rendered by multilingual translators that are based on that architecture.
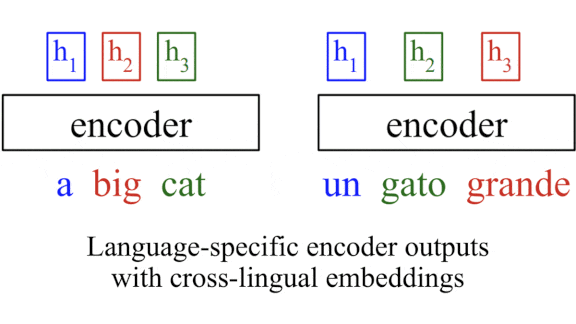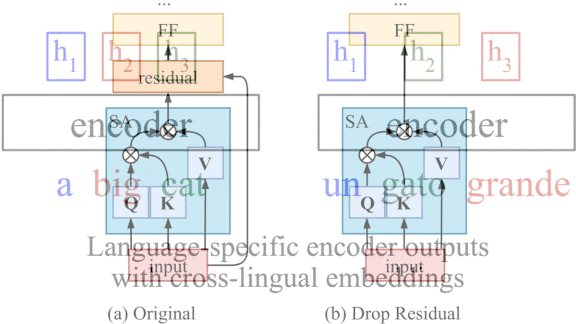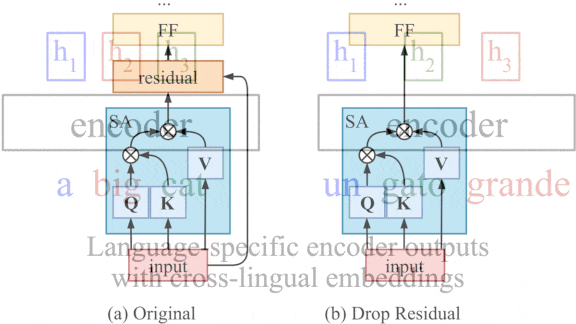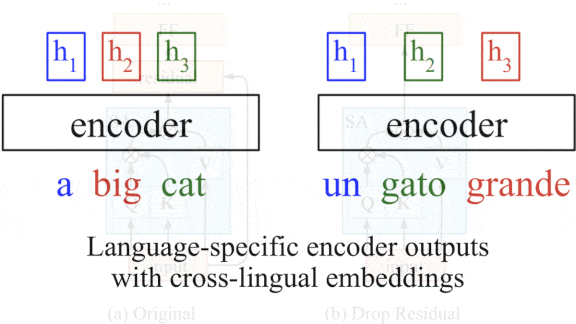
Key insight: Residual connections, which add the inputs of one layer to those of a later layer to prevent vanishing gradients, impose a one-to-one correspondence between the two layers they connect. Transformers use residual connections throughout, which imposes a one-to-one correspondence between the network’s input and output. That correspondence could preserve word order in representations extracted from a languages (for example, remembering that adjectives precede the nouns they describe), which causes problems for zero-shot translation if the output language orders adjectives and nouns differently. Removing residual connections in one layer should break the correspondence while preserving the benefits of residual connections in other layers.
How it works: The authors used a transformer and removed the residual connections from its encoder’s middle layer.
- They trained the model on Europarl v7, IWSLT 2017, and PMIndia, which include texts in various languages paired with human translations into other languages.
- The model learned to translate between 18 language pairs that always included English. Given an input sentence and a target output language, it optimized a loss based on how well each token (generally a word) it produced matched each token in a reference translation.
- The authors tested the model on pairings of the languages used in training except English, giving them 134 zero-shot translation tasks.
Results: The authors compared their model’s zero-shot translations with those of an unmodified transformer using BLEU, a measure of how well a machine translation matches a reference translation (higher is better). On Europarl, removing residual connections boosted the average BLEU score from 8.2 to 26.7. On IWSLT, it raised the average from 10.8 to 17.7. On PMIndia, which includes low-resource languages, it lifted scores from 0.8 to 2.3.
Why it matters: The zero-shot approach opens doors in language translation. Many language pairs lack sufficient training data to train a translator via supervised learning. But if you have enough data for N languages, zero-shot allows for translation between N2 language pairs.
We’re thinking: Residual connections are all you don’t need!

Autonomous Weapons Gain Support
A panel of AI experts appointed by the U.S. government came out against a ban on autonomous weapons.
What’s new: A draft report from the National Security Commission on Artificial Intelligence, led by former Google CEO Eric Schmidt, recommends against a proposed international global prohibition of AI-enabled autonomous weapon systems, an idea that many other countries have agreed to. The report encourages the U.S. to expand its efforts in military AI, which include the weapons-ready Northrop Grumman X-47B drone pictured above.
What they said: The commission acknowledges the risks of autonomous weaponry but concludes that an international ban would be both difficult to enforce and antithetical to America’s interest. Commission member and former deputy defense secretary Robert Work told Reuters that autonomous weapons would make fewer mistakes than humans, resulting in fewer battlefield casualties.
- The members believe that the U.S.’ geopolitical rivals will use AI for intelligence, propaganda, and espionage. Rogue states, terrorists, and criminals will, too. The U.S. must scale up its own AI programs to defend against such threats.
- They recommend that defense agencies build a shared infrastructure for developing AI systems, with access for trusted contractors. Each agency should invest in more tech training for its personnel, too. To accomplish these and other goals, the U.S. government should allocate $32 billion annually by 2026.
- The final version of the report is scheduled for publication in March.
Behind the news: Nongovernmental organizations have been campaigning to ban autonomous weapons for nearly a decade. The United Nations has held meetings on the subject since 2014, and at least 30 countries are in favor.
Why it matters: As the world’s preeminent power in both military force and AI, the U.S.’ decisions will be a major influence on those of other countries.
We’re thinking: National defense policy is full of complicated issues, and simplistic slogans won’t lead to the best decisions. On balance, though, we continue to support a global ban on autonomous weapons.