
Dear friends,
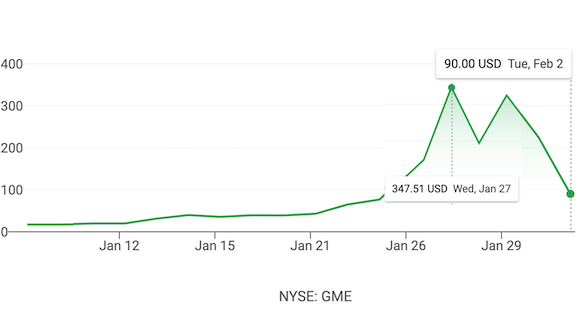
The price of shares in video game retailer GameStop (NYSE: GME) gyrated wildly last week. Many people viewed the stock’s rapid ascent as a David-versus-Goliath story: Tech-savvy individual retail investors coordinated their trades online to push up the price and “stick it to” large hedge funds that had shorted the stock. Sadly, the reality is very different.
Some retail investors in GameStop made money last week. But automated trading driven by AI now surpasses the speed and knowledge of most retail investors. I believe that wild swings in share price like the one driven by the GameStop crowd actually tend to result in a net transfer of wealth from retail investors to the hedge funds with the best AI teams.
Hedge funds that use AI to trade stocks make decisions based on a multitude of features including financial indices, social media chatter, and other forms of public or licensed data. Compared to a retail investor who reads r/wallstreetbets, they have access to far more information. They also have natural language processing and financial prediction tools to process all that information. Because of this, a typical human trader today can no more outperform an AI trader than beat a good reinforcement learning algorithm at an Atari game.
I differentiate between trading and investing. Human investors who choose stocks because they believe the underlying company is fundamentally valuable, and hold those stocks to realize that value, can do very well. Allocating capital to deserving companies can also help them grow, and thus make everyone involved better off. That’s different from trading, in which the aim is to buy shares solely to sell them to someone else at a higher price. Ultimately, trading creates little, if any, net wealth. When there are so many opportunities to grow the pie, why would we work so hard on activities that keep the pie the same size but squeeze out a bigger piece for ourselves at others’ expense?
In The Washington Post, Helaine Olen wrote about how the volatility in GameStop’s stock price wasn’t just the story of a get-rich-quick scheme. It was also a tale of inequality, as young people who can’t find a good job dream of gaming the system. I’m glad that some traders will use their GameStop winnings to improve their lives. But I am fearful for those who will lose their savings playing a game they’re unlikely to win. For example, those who bought at GameStop’s January 27 peak and might end up incurring substantial losses they can ill afford.
When you decide what AI projects to work on, I hope you will pick something that enriches not only yourself but society as a whole. Let’s also do what we can to make sure that whatever wealth we create is fairly and widely shared.
Keep learning!
Andrew
News
Pain Points in Black and White
A model designed to assess medical patients’ pain levels matched the patients’ own reports better than doctors’ estimates did — when the patients were Black.
What’s new: Black people who suffer from osteoarthritis, or loss of cartilage in the joints, tend to report higher levels of pain than White patients who have the same condition. To understand why, researchers at Microsoft, Stanford University, and other institutions trained a model to predict the severity of a patient’s pain from a knee x-ray. The model predicted self-reports by Black patients more accurately than a grading system commonly used by radiologists.
How it works: The researchers began with a ResNet-18 pretrained on ImageNet. They fine-tuned it to predict pain levels from x-rays using 25,049 images and corresponding pain reports from 2,877 patients. 16 percent of the patients were Black.
- The researchers evaluated x-rays using their model and also asked radiologists to assign them a Kellgren-Lawrence grade, a system for visually assessing the severity of joint disease.
- Compared with the Kellgren-Lawrence grades, the model’s output showed 43 percent less disparity between pain reported by Black and White patients.
- The researchers couldn’t determine what features most influenced the model’s predictions.
Behind the news: The Kellgren-Lawrence grade is based on a 1957 study of a relatively small group of people, nearly all of whom were White. The system often underestimates pain levels reported by Black patients.
Why it matters: Chronic knee pain hobbles millions of Americans, but Black patients are less likely than White ones to receive knee replacement surgery. Studies have shown that systems like the Kellgren-Lawrence grade often play an outsize role in doctors’ decisions to recommend surgery. Deep learning offers a way to narrow this gap in care and could be adapted to address other healthcare discrepancies.
We’re thinking: Algorithms used in healthcare have come under scrutiny for exacerbating bias. It’s good to see one that diminishes it.
Language Models Want to Be Free
A grassroots research collective aims to make a GPT-3 clone that’s available to everyone.
What’s new: EleutherAI, a loose-knit group of independent researchers, is developing GPT-Neo, an open source, free-to-use version of OpenAI’s gargantuan language model. The model could be finished as early as August, team member Connor Leahy told The Batch.
How it works: The goal is to match the speed and performance of the fully fledged, 175 billion-parameter version of GPT-3, with extra attention to weeding out social biases. The team successfully completed a 1 billion-parameter version, and architectural experiments are ongoing.
- CoreWeave, a cloud computing provider, gives the project free access to infrastructure. It plans eventually to host instances for paying customers.
- The training corpus comprises 825GB of text. In addition to established text datasets, it includes IRC chat logs, YouTube subtitles, and abstracts from PubMed, a medical research archive.
- The team measured word pairings and used sentiment analysis to rate the data on gender, religion, and racial bias. Examples that showed unacceptably high levels of bias were removed.
Behind the news: In 2019, when OpenAI introduced GPT-2, the company initially refused to release the full model, citing fears that it would set off a flood of disinformation. That motivated outside researchers, including Leahy, to try to replicate the model. Similarly, OpenAI’s decision to keep GPT-3 under wraps inspired EleutherAI’s drive to create GPT-Neo.
Why it matters: GPT-3 has made headlines worldwide, but few coders have had a chance to use it. Microsoft has an exclusive license to the full model, while others can sign up for access to a test version of the API. Widespread access could spur growth in AI-powered productivity and commerce.
We’re thinking: If talk is cheap, AI-generated talk might as well be free!
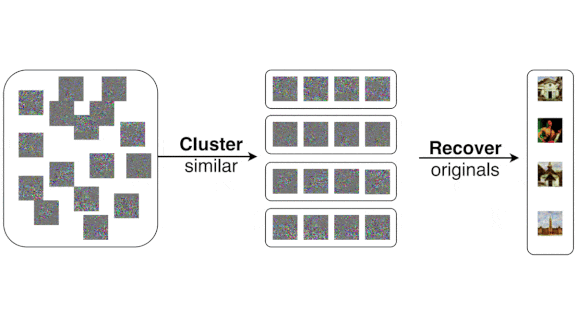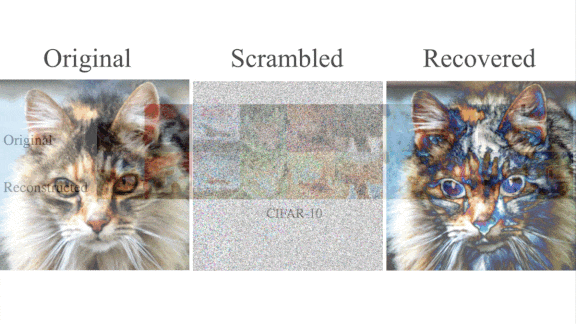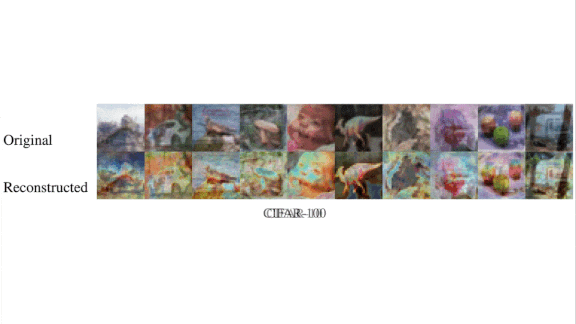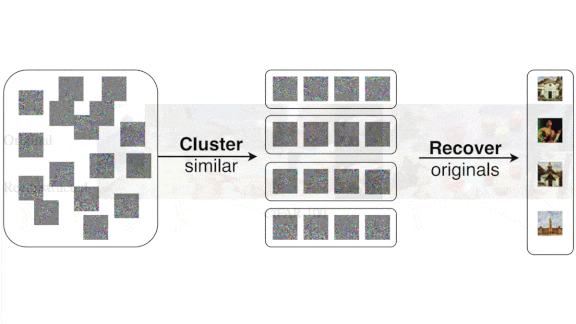
A Privacy Threat Revealed
With access to a trained model, an attacker can use a reconstruction attack to approximate its training data, including examples that impinge on privacy, such as medical images. A method called InstaHide recently won acclaim for promising to make such examples unrecognizable to human eyes while retaining their utility for training. Researchers cracked it in short order.
What’s new: InstaHide aims to scramble images in a way that can’t be reversed. Nicholas Carlini and researchers at Berkeley, Columbia, Google, Princeton, Stanford, University of Virginia, and University of Wisconsin defeated InstaHide to recover images that look a lot like the originals.
Key insight: InstaHide can be viewed as a linear equation that scrambles images by summing them (typically two sensitive and four public images chosen at random) using random weights, then randomly flipping the sign of each pixel value. But summing is reversible, and changing signs doesn’t effectively obscure values. Consequently, a linear equation can be devised to reverse this process.
How it works: The authors applied InstaHide to produce targets. CIFAR-10, CIFAR-100, and STL-10 stood in for sensitive datasets. ImageNet served as their non-sensitive dataset. Then they undid the effects of the InstaHide algorithm in reverse order.
- The attack first takes the absolute value of a scrambled image to make all pixel values positive. This sets up the data for the model used in the next step.
- The authors trained a Wide ResNet-28 to determine whether any two scrambled images come from the same original.
- They constructed a graph in which every vertex represented an image, and the images at either end of an edge had at least one common parent.
- Knowing which scrambled images shared a parent image, the authors formulated a linear equation to reconstruct the parents. (In this work, common parents were highly unlikely to be non-sensitive due to ImageNet’s large number of examples. The equation accounts for such images as though they were noise.)
Results: The authors tested their approach using the CIFAR-10 and CIFAR-100 test sets as proxies for sensitive data. Subjectively, the reconstructed images closely resembled the originals. They also tried it on the InstaHide Challenge, a collection of 5,000 scrambled versions of 100 images published by the InstaHide team. They found an approximate solution in under an hour, and InstaHide’s inventors agreed that they had met the challenge.
Why it matters: Once personally identifiable information is leaked, it’s impossible to unleak. Machine learning must protect privacy with the utmost rigor.
We’re thinking: The authors show that their method can work well if the scrambled training images are available. It remains to be seen whether it works given access only to a trained model.
A MESSAGE FROM DEEPLEARNING.AI

Only a few hours left to register for our first AI+X event — “Don’t Switch Careers, Add AI” — in partnership with Workera! Join us for a virtual discussion with experts at Accenture and Illumina on Thursday, February 4, 2021, at 10 a.m. Pacific Standard Time.
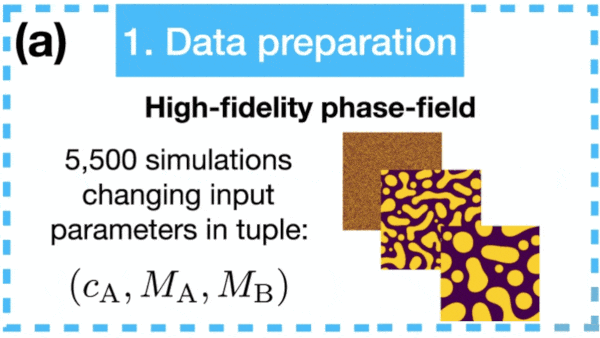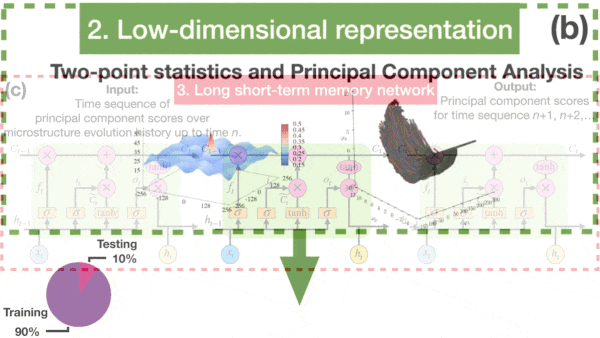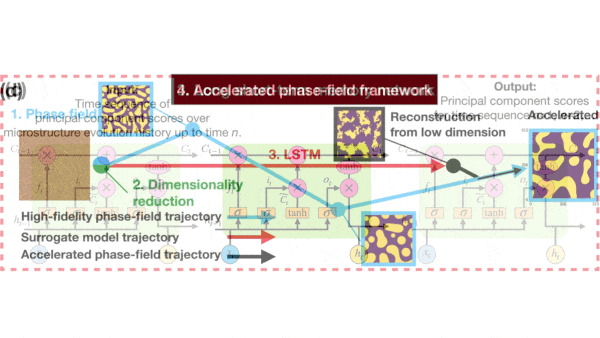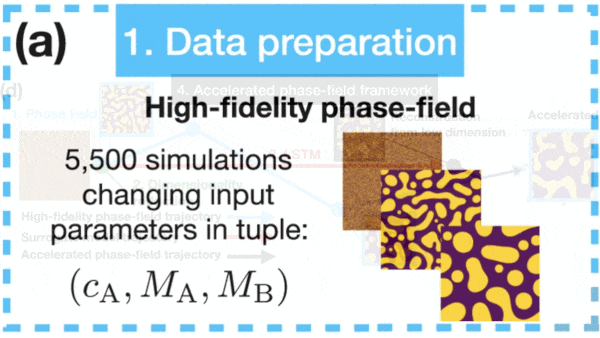
Materials Science Gets a Boost
Neural nets could speed up development of new materials.
What’s new: A deep learning system from Sandia National Laboratories dramatically accelerated simulations that help scientists understand how changes to the design or fabrication of a material — say, the balance of metals in an alloy — change its properties.
How it works: The researchers trained an LSTM to predict how the properties of a material evolve during the process known as spinodal decomposition, in which a material separates into its constituents in the presence or absence of heat.
- The authors trained their model using 5,000 simulations, each comprising 60 observations over time, of the microscopic structure of an alloy undergoing spinodal decomposition.
- They simplified these observations from 262,144 to the 10 most important using principal component analysis.
- Fed this simplified representation, the LSTM learned to predict how the material would change in subsequent time steps.
Results: In tests, the model simulated thermodynamic processes, such as the way a molten alloy congeals as it cools, more than 42,000 times faster than traditional simulations: 60 milliseconds versus 12 minutes. However, the increased speed came at a cost of slightly reduced accuracy, which fell by 5 percent compared to the traditional approach.
Behind the news: Machine learning has shown promise as a shortcut to a variety of scientific simulations.
- Alphafold figures out 3D protein structures, a capability that could accelerate drug development.
- DENSE has sped up physical simulations in fields including astronomy, climate science, and physics.
Why it matters: Faster simulations of materials can quicken the pace of discovery in areas as diverse as optics, aerospace, energy storage, and medicine. The Sandia team plans to use its model to explore ultrathin optical technologies for next-generation video monitors.
We’re thinking: From Gorilla Glass to graphene, advanced materials are transforming the world. Machine learning is poised to help such innovations reach the market faster than ever.
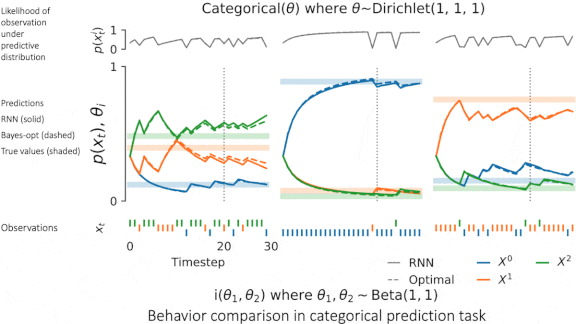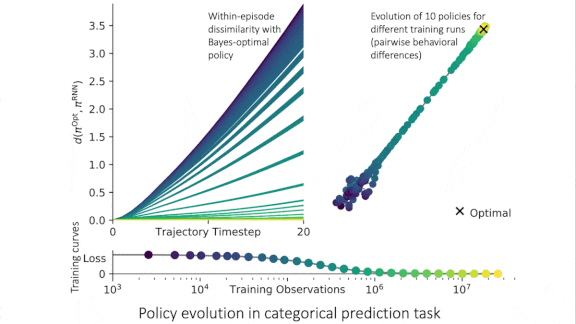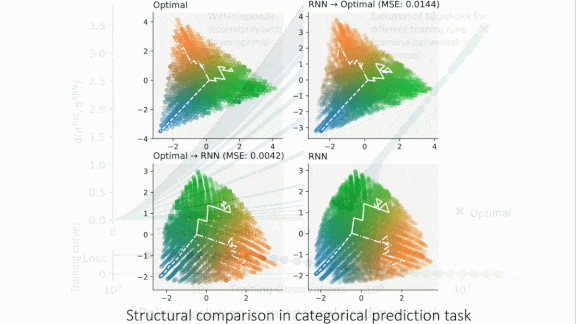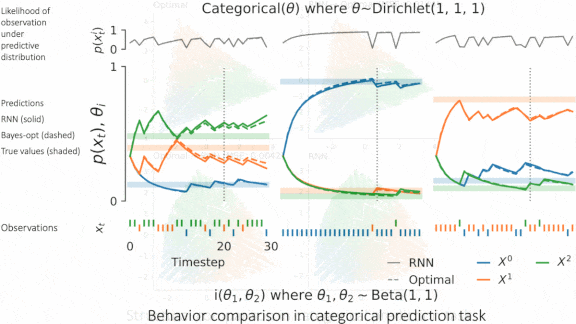
Performance Guaranteed
Bayes-optimal algorithms always make the best decisions given their training and input, if certain assumptions hold true. New work shows that some neural networks can approach this kind of performance.
What’s new: DeepMind researchers led by Vladimir Mikulik showed that recurrent neural nets (RNNs) with meta-training, or training on several related tasks, behave like Bayes-optimal models.
Key insight: Theoretically, memory-based models like RNNs, given sufficient meta-training, become Bayes-optimal. To test this hypothesis, the researchers compared outputs and the internal states of both types of model.
How it works: The researchers meta-trained 14 RNNs on various prediction and reinforcement learning tasks. For instance, to predict the outcome of flipping a biased coin, the model observed coins with various biases. Then they compared each RNN to a known Bayes-optimal solution.
- Each RNN comprised a fully connected layer, an LSTM layer, and a final fully connected layer. The authors trained the RNNs for 20 time steps, altered variables specific to the task at hand (such as the bias of the flipped coin), and repeated the process for a total of 10 million time steps. The corresponding Bayes-optimal models consisted of simple rules.
- The authors fed the same input to RNN and Bayes-optimal models and compared their outputs. For prediction tasks, they compared KL divergence, a measure of similarity between two probability distributions. For reinforcement learning tasks, they compared cumulative reward.
- To compare models’ internal representations, the authors recorded their hidden states and parameter values and used principal component analysis to reduce the RNNs’ dimensions to match the Bayes-optimal models. Then they trained two fully connected models to map RNN states to Bayes-optimal states and vice-versa, and measured their difference using mean-squared error.
Results: All RNNs converged to behave indistinguishably to their Bayes-optimal counterparts. For instance, the RNN that learned to predict biased coin flips achieved a KL divergence of 0.006 compared to 3.178 before meta-training. The internal states of RNNs and Bayes-optimal models matched nearly perfectly, differing in most tasks by a mean-squared error of less than 0.05.
Why it matters: Bayesian models are reputed to be provably optimal and interpretable. Compared to neural nets, though, they often require more engineering and vastly more computational power. This work involved toy problems in which a Bayes-optimal model could be written by hand, but it’s encouraging to find that meta-trained RNNs performed optimally, too.
We’re thinking: Maybe RNNs will become more popular here in the San Francisco Bayes Area.