
Dear friends,
Last week, I talked about how best practices for machine learning projects are not one-size-fits-all, and how they vary depending on whether a project uses structured or unstructured data, and whether the dataset is small or big. Another dimension that affects best practices is which phase of development a project is in: proof of concept or production.
During the proof of concept (POC) phase, the primary goal is to determine if a system is worth building and deploying. During this phase, you might ask:
- For a visual inspection system, can we build a model that matches the performance of human inspectors?
- For face detection, can we build an edge (on-device) implementation that’s nearly as accurate as the cloud version while avoiding an unacceptable level of bias?
- For a sales-lead scoring application, how much will estimated revenue increase by using machine learning to prioritize leads?
When building a POC, my goal is to move fast. We’ve all been told we should build replicable, robust, and scalable systems — but when I haven’t even determined if a project is technically feasible, I often trade replicability for speed. I hope I don’t get too much hate mail for this, but if it buys you speed, it is okay to hard-code parameters, compute key variables in a Jupyter notebook, use local copies of data, and operate with lightweight code review or versioning processes.
If you already have a platform for experimentation, you may be able to build POCs in a systematic and robust way without sacrificing speed. But if you don’t, avoid over-investing in infrastructure at this stage. Instead, focus on getting the key information you need: whether this project is worth taking to production.

(Those of you who are familiar with the lean startup philosophy will see the parallel to building a minimum viable product, which is often a clunky piece of software that helps validate or falsify a hypothesis.)
In contrast, during the production phase, the goal is to build and deploy a system that generates practical value. I might go back to the messy POC and make sure that every step is replicable and documented. I put a lot of thought into scalable data pipelines, monitoring systems, and reliability.
For example, if a researcher wrote preprocessing routines (say, a sequence of scripts and regexps to remove data associated with spam accounts), these now need to be documented, tested, and incorporated into the system. You’ll likely want to document everything to make sure models can be replicated and maintained: hyperparameters, model choices, data provenance (where the data came from), data lineage (how it was processed). During this phase, tools like TensorFlow Transform and Apache Beam can be lifesavers.
If you’re building a project, don’t confuse the POC and production phases! Both are important, but the best practices depend on whether you’re deciding as quickly as possible if a project is worth putting into production or building a system that delivers real results to real users.
Keep learning!
Andrew
News
The Language of Viruses
A neural network learned to read the genes of viruses as though they were text. That could enable researchers to page ahead for potentially dangerous mutations.
What’s new: Researchers at MIT trained a language model to predict mutations that would enable infectious viruses — including the SARS-CoV-2 virus that causes Covid-19 — to become even more virulent.
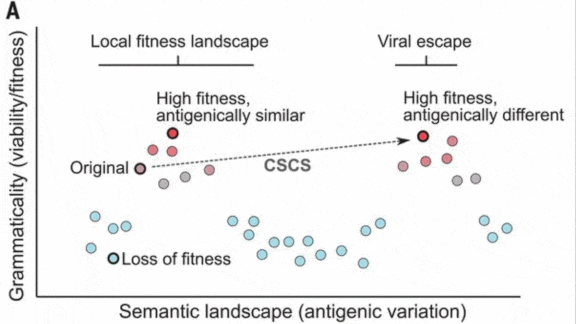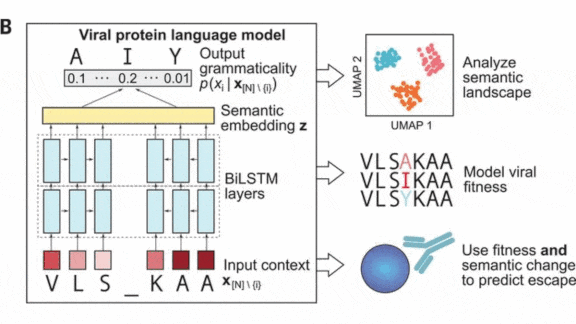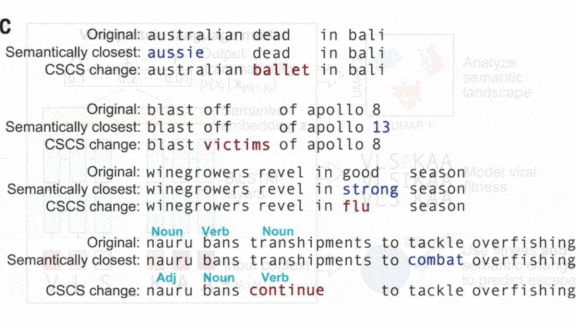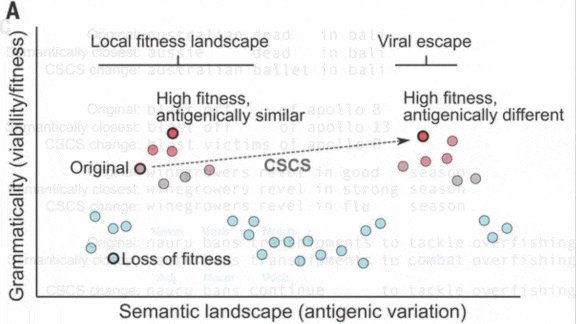
Key insight: The authors suggest that the immune system’s response to viruses is similar to the way people understand natural language. A virus that causes infection has a “grammar” that’s biologically correct, and it also has a semantic “meaning” to which the immune system does or doesn’t respond. Mutations can enhance these worrisome qualities.
How it works: The authors trained a bidirectional LSTM on the genetic equivalent of making a language model guess a missing word in a sentence. The training set included gene sequences from a variety of infectious bugs: 45,000 variants of influenza, 60,000 of HIV, and 4,000 of SARS-CoV-2.
- The researchers trained the biLSTM to fill in a missing amino acid in a sequence. Along the way, the model generated embeddings that represent relationships among sequences.
- Then they generated mutated sequences by changing one amino acid at a time.
- To rank a given mutation, they took a weighted sum of the likelihood that the mutated virus retained an infectious grammar and the degree of semantic difference between the original and mutated sequence’s embeddings.
Results: The researchers compared their model’s highest-ranked mutations to those of actual viruses according to the area under curve (AUC), where 0.5 is random and 1.0 is perfect. The model achieved 0.85 AUC in predicting SARS-CoV-2 variants that were highly infectious and capable of evading antibodies. It achieved 0.69 AUC for HIV, and 0.77 AUC and 0.83 AUC respectively for two strains of influenza.
Behind the news: Other researchers have also explored similarities between language and gene sequences. For example, Salesforce researchers trained a language model to treat amino acids like words and build grammatically correct “sentences” of functional proteins that could be used in medicine.
Why it matters: Discovering dangerous viral mutations typically takes weeks, as scientists must analyze DNA taken from patients. The ability to predict harmful mutations could help them find dangerous variants sooner, helping epidemiologists update their models and giving researchers a head start on vaccines and therapies.
We’re thinking: The Batch is grammatically correct but not infectious. Though we wouldn’t mind if it went viral!

Quake Watch
Detecting earthquakes is an important step toward warning surrounding communities that damaging seismic waves may be headed their way. A new model detects tremors and provides clues to their epicenter.
What’s new: S. Mostafa Mousavi and colleagues at Stanford and Georgia Institute of Technology built EQTransformer to both spot quakes and measure characteristics that help seismologists determine where they originated.
Key insight: Language models based on transformer networks use self-attention to track the most important associations among tokens, such as words, in a sentence. The authors applied self-attention to seismic waves globally to track the most important associations among their features. Since clues to a quake’s epicenter appear in portions of the waveform, they also used self-attention locally to find patterns over shorter periods of time.
How it works: The authors passed seismic waves through an encoder that fed three decoders designed to detect earthquakes and spot two types of location signal. The authors trained and tested the system using the Stanford Earthquake Dataset (STEAD), which contains over one million earthquake and non-earthquake seismographs. They augmented the data by adding noise, adding earthquake signals to non-quake waves, and shifting quake start times.
- Self-attention requires a great deal more computation as the input’s size grows, so the encoder, which comprised convolutional and LSTM layers, compressed the input into a high-level representation. A pair of transformer layers were included to focus on earthquake signals.
- In the detection decoder, convolutional layers determined whether an earthquake was occurring.
- The other two decoders tracked the arrival of p-waves (primary waves that push and pull the ground) and s-waves (secondary waves that move the ground up and down or side to side). The difference in these arrival times indicates distance from a quake’s epicenter. These decoders used LSTM and local self-attention layers to examine small windows of time, which fed convolutional layers that detected the signals.
Results: EQTransformer outperformed state-of-the-art models in both detecting earthquakes and tracking p- and s-waves. In detection, EQTransformer achieved an F1 score of 1.0, a 2 percent improvement over the previous state of the art. In tracking p-waves, it improved mean absolute error over the earlier state of the art in that task from 0.07 to 0.01. With s-waves, it improved mean absolute error from .09 to .01. The training dataset didn’t include seismographs from Japan, so the authors tested their model’s ability to generalize on aftershocks from a Japanese quake that occurred in 2000. In this test, EQTransformer’s ability to spot the arrival of p-waves varied from human performance by an average .06 seconds, while its ability to spot the arrival of s-waves varied from human performance by an average .05 seconds.
Why it matters: Applied at both global and local scales, self-attention could be useful in tasks as diverse as forecasting weather, product demand, and power consumption.
We’re thinking: We applaud this earth shattering research!
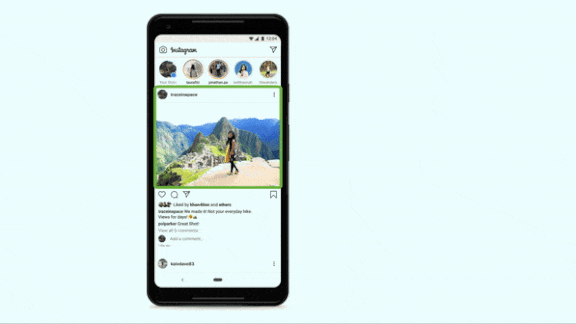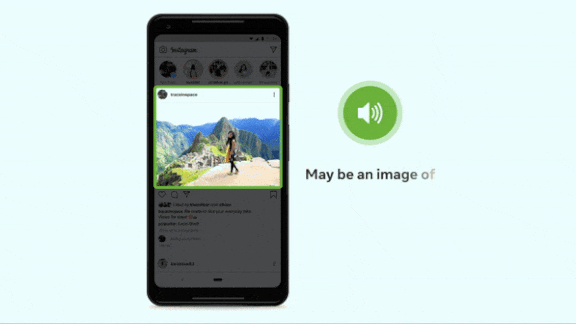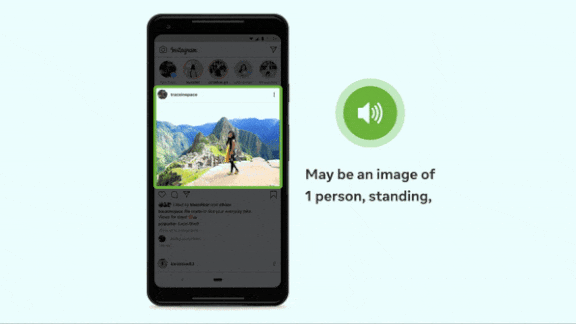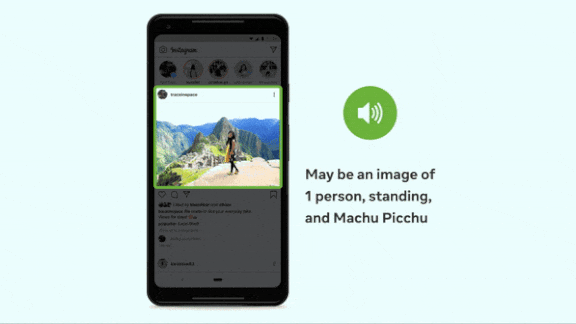
Every Picture Tells a Story
Facebook expanded a system of vision, language, and speech models designed to open the social network to users who are visually impaired.
What’s new: A Facebook service that describes photos in a synthesized voice now recognizes 1,200 visual concepts — 10 times more than the previous version. Known as automatic alternative text, the system can recognize and explain what’s happening in a picture, including the relative size and position of people and objects, in any of 45 languages.
How it works: Launched in 2016, the system initially learned from hand-labeled data to recognize 100 common concepts, like tree and mountain. Facebook added face recognition the following year, allowing users to opt into a more personalized experience. The new upgrade extends automatic alternative text in several ways:
- Facebook engineers used a weakly supervised approach to train ResNeXt image recognition models on 3.5 billion Instagram images and 17,000 hashtags that users put with them. Using a similar architecture, they applied transfer learning to train linear classification heads to recognize concepts including selfies, national monuments, and foods like rice and French fries.
- They used an existing object detection library to build a Fast R-CNN that recognizes the number, size, and position of various items in an image and determines its primary subject.
- The system starts each description with the humble phrase, “May be…,” and it doesn’t describe concepts that it can’t identify reliably. Users can request extra details, and the model will display a page that itemizes a picture’s elements by their position (top, middle, left, or bottom), relative size (primary, secondary, or minor), and category (people, activities, animals, and so on).
Behind the news: Facebook, along with other popular websites, has struggled with how to serve visually impaired users. Some have complained that the site doesn’t work well with common accessibility equipment like screen readers that speak text aloud. For instance, earlier versions of automated alternative text didn’t inform users when the images it described were advertisements. However, some users have applauded Facebook’s use of face recognition with automatic alternative text, which can tell them when a photo depicts a friend or loved one.
Why it matters: Around 285 million people worldwide are visually impaired and 39 million are blind, the World Health Organization estimates. People who don’t see well are as reliant on information as anyone — and they represent a sizable market.
We’re thinking: Disabled web users in the U.S. file hundreds of lawsuits annually against Internet companies that don’t make their services accessible. Increasingly, online accessibility is recognized as a right, not a privilege.
A MESSAGE FROM DEEPLEARNING.AI

Become a thought leader in your industry by combining your domain expertise with AI! We’re proud to offer AI+X, a virtual event series featuring AI experts from different industries, in partnership with Workera. Join us on February 4, 2021, for “AI+X: Don’t Switch Careers, Add AI.”

Drones Unleashed
U.S. regulators for the first time allowed commercial operators of autonomous aerial vehicles to fly out of operators’ sight.
What’s new: The U.S. Federal Aviation Administration generally requires people on the ground to keep an eye on drones, but it authorized drone maker American Robotics to fly without requirement.
How it works: The company’s 20-pound quadcopters travel predetermined paths and automatically avoid collisions with birds, aircraft, and other obstacles.
- When they’re not in the air, the drones charge their battery in a weatherproof launch pad, which also houses computing horsepower for navigation.
- An acoustic sensing system recognizes the presence and direction of airborne objects. It commands the robot to descend if it detects an object flying within a two-mile perimeter.
- A human technician must run through a safety checklist and inspect drones before takeoff, but these functions can be performed remotely. Flights are limited to daylight hours, altitudes under 400 feet, and limited areas in Kansas, Massachusetts, and Nevada, according to The Verge.
Behind the news: Companies can apply to the FAA for a waiver of the line-of-sight rule. American Robotics became the first company to receive one after four years of testing.
- The agency recently issued rules governing flights in populated areas and at night — a step toward a full regulatory framework for drone delivery services.
- Last August, the agency granted Amazon and Wing limited permission to deliver packages via drones.
- The U.S. approach to drone regulations is relatively permissive. Most countries restrict flights to an operator’s line of sight.
Why it matters: The ability to operate without a human in visual contact is a critical step to making drone flights easier to manage and more economical to operate.
We’re thinking: Andrew used to work with Pieter Abbeel, Adam Coates, and others on reinforcement learning to get autonomous helicopters to fly stunts. He crashed quite a few copters in the process! (Safely, of course, in empty fields.) With drones now flying out of an operator’s line of sight, it’s more important than ever to subject their hardware and software to robust safety testing and verification.

Images From Noise
Generative adversarial networks and souped-up language models aren’t the only image generators around. Researchers recently upgraded an alternative known as score-based generative models.
What’s new: Yang Song and Stefano Ermon at Stanford derived a procedure for selecting hyperparameter values for their earlier score-based generator, which produces images from noise. Finding good hyperparameters enabled the authors to generate better images at higher resolution.
Key insight: Score-based image generation uses a model that learns how to change images corrupted by additive noise to reproduce the original pictures, and an algorithm that executes the changes to produce fresh images. The earlier work relied on manual tuning to find good values for hyperparameters such as how much noise to add to training images. Real-world data distributions are hard to analyze mathematically, so, in the new work, the authors approximated them with simplified distributions. Given the simpler scenario, they could analyze how each hyperparameter would affect both training and inference, enabling them to derive methods to compute hyperparameter values.
About score-based generation: The process starts with producing many versions of each training dataset by adding various magnitudes of noise. A modified RefineNet is trained to minimize the difference between its prediction of the way, and the actual way, to change a noisy example into a clean one. RefineNet learns a vector field: Given a point in space that corresponds to an image, it returns a vector that represents the direction toward a more realistic image. Then an algorithm based on Langevin dynamics (a set of equations developed to model the way molecules interact in a physical system) moves the point in that direction. The process of finding a vector and moving in that direction repeats for a finite number of steps.
How it works: The authors followed their score-based procedure but used new methods to compute hyperparameters that governed the noise added to the training dataset and the size and number of steps computed by Langevin dynamics. We’ll focus on the noise hyperparameters in this summary.
- Very noisy datasets are needed to train the network to produce an image from noise. However, too many highly noisy training examples make it hard for the network to learn. So it’s necessary to balance noisy and less-noisy examples carefully.
- What’s the greatest amount of noise to add? To train the network to generate images that reflect the entire training data distribution, Langevin dynamics must be able to transition between any two training examples. So the greatest noise, as measured by the Euclidean distance between noisy and noise-free examples, should be equal to the maximum distance between any pair of noise-free training examples.
- What should be the difference between the greatest and next-greatest amounts of noise added, and how many increments should there be? The authors examined a scenario with only one training example. For RefineNet to supply good directions, it must learn to chart a path from any point in the vector field to that example. To do that, the added noise must leave no areas where, randomly, noisy data doesn’t occur. Based on that principle, they derived an equation to determine how many noisy datasets to produce and what increments of noise to apply.
Results: The authors evaluated their new model’s output using Frechet Inception Distance (FID), a measure of how well a generated data distribution resembles the original distribution, where lower is better. Trained on 32×32 images in CIFAR-10, the model achieved 10.87 FID, a significant improvement over the earlier model’s 25.32 FID. It also beat SNGAN, which achieved 21.7 FID. The paper doesn’t compare competing FID scores at resolutions above 32×32 and omits FID scores altogether at resolutions higher than 64×64. It presents uncurated samples up to 256×256.
Why it matters: GANs often don’t learn to produce good images because the objectives of their generator and discriminator are at odds. Score-based generative models optimize for only one objective, which eliminates this risk. That said, they may fail to converge for other reasons.
We’re thinking: We love the idea of using mathematical reasoning to derive optimal hyperparameter values: More time to develop good models!