
Dear friends,
Experience gained in building a model to solve one problem doesn’t always transfer to building models for other problems. How can you tell whether or not intuitions honed in one project are likely to generalize to another? I’ve found that two factors can make the difference: the size of the training set and whether the data is unstructured or structured.
For instance, I’ve heard blanket statements like, “you should always have at least 1,000 examples before tackling a problem.” This is good advice if you’re working on a pedestrian detector, where data is readily available and prior art shows that large datasets are important. But it’s bad advice if you’re building a model to diagnose rare medical conditions, where waiting for 1,000 examples might mean you’ll never get started.
Unstructured data includes text, images, and audio clips, which lend themselves to interpretation by humans. Structured data, on the other hand, includes things like transaction records or clickstream logs, which humans don’t process easily.
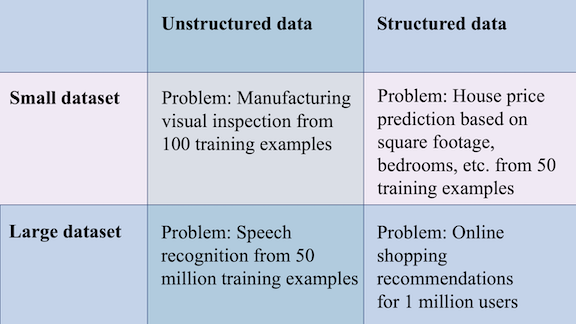
This difference leads to very different strategies for training and deploying models:
- Unstructured data: Because the examples are easy for humans to understand, you can recruit people to label them and benchmark trained models against human-level performance (HLP). If you need more examples, you might be able to collect them by capturing more text/images/audio or by using data augmentation to distort existing examples. Error analysis can take advantage of human intuition.
- Structured data: This class of data is harder for humans to interpret, and thus harder for humans to label. Algorithms that learn from structured data often surpass HLP, making that measure a poor benchmark. It can also be hard to find additional examples. For instance, if the training dataset comprises records of your customers’ purchases, it’s hard to get data from additional customers beyond your current user base.
Dataset size has implications as well:
- Small dataset: If the dataset includes <1,000 examples, you can examine every example manually, check if the labels are correct, and even add labels yourself. You’re likely to have only a handful of labelers, so it’s easy to hash out any disagreements together on a call. Every single example is a significant fraction of the dataset, so it’s worthwhile to fix every incorrect label.
- Large dataset: If the dataset is >100,000 examples, it’s impractical for a single engineer to examine every one manually. The number of labelers involved is likely to be large, so it’s critical to define standards clearly, and it may be worthwhile to automate labeling. If a significant number of examples are mislabeled, it may be hard to fix them, and you may have to feed the noisy data to your algorithm and hope it can learn a robust model despite the noise.
If you find yourself in need of advice while working on, say, a manufacturing visual inspection problem with 100 examples, the best person to ask would be someone who has worked on a manufacturing visual inspection problem with 100 examples. But if you can’t find such a person, consider looking for someone with expertise in the same dataset size/type quadrant as the problem you’re working on.
As you develop your career, you might also consider whether you want to stay in one quadrant and develop deep expertise there, or move across quadrants and develop more general skills.
Keep learning!
Andrew
DeepLearning.AI Exclusive

Working AI: Stoking GPU Clusters
As a senior deep learning engineer at Nvidia, Swetha Mandava helps make models run more efficiently on large-scale hardware. Learn about her onramp to AI and how she stays on track. Read more
News

AI Versus Lead Poisoning
An algorithm is helping cities locate pipes that could release highly toxic lead into drinking water.
What’s new: BlueConduit, a startup that focuses on water safety, is working with dozens of North American municipal governments to locate lead water lines so they can be replaced, Wired reported.
How it works: For each city, the company develops a custom model that ranks the likelihood that any given property has lead pipes.
- The company starts by collecting comprehensive data on building locations, ages, market values, occupants, and other variables, BlueConduit executives told The Batch. It works with the local government to gather details from a representative set of properties, including known pipe materials and results of water tests if they’re available.
- It trains a gradient boosted tree on the data, tuning the model to account for uncertainties in the dataset.
- The model’s output is used to produce maps that officials can use to prioritize removal of potentially hazardous pipes and residents can use to request removal.
Behind the news: Founded by faculty at Georgia Tech and University of Michigan, BlueConduit developed its technology to help manage a wave of lead poisoning in Flint, Michigan, between 2014 and 2019. There it achieved 70 percent accuracy in classifying properties with lead pipes. Contaminated water in Flint exposed thousands of people to dangerously high levels of lead.
Why it matters: Lead exposure can impair development in children, and it’s linked to heart, kidney, and fertility problems in adults. Yet digging up older water lines that may use lead pipes can cost thousands of dollars. Cities can save millions if they can focus on the most dangerous locations and avoid replacing pipes in houses that are already safe.
We’re thinking: Flint stopped using BlueConduit’s system in 2018 partly because some residents complained they were being passed over by the AI-driven replacement strategy — a sign of how little they trusted their local government and the unfamiliar technology. The city reinstated the system the following year under pressure from the state and legal actions, but the lesson remains: When you’re deploying a major AI system, establishing trust is as important as tuning parameters.
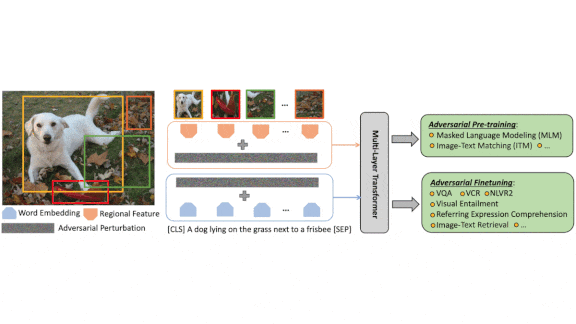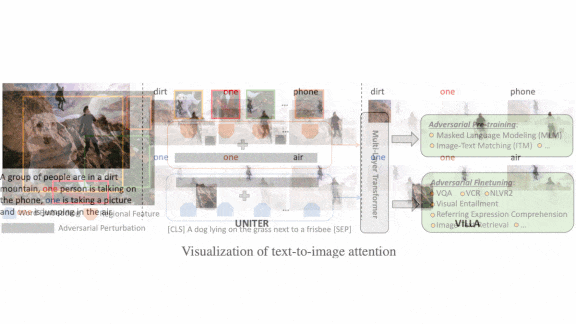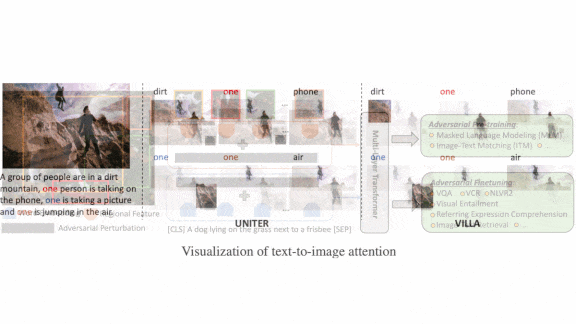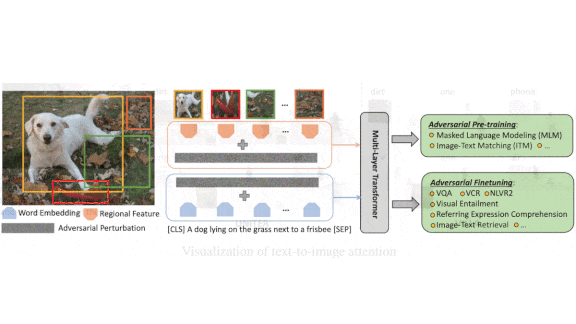
Adversarial Helper
Models that learn relationships between images and words are gaining a higher profile. New research shows that adversarial learning, usually a way to make models robust to deliberately misleading inputs, can boost vision-and-language performance.
What’s new: Vision-and-language models based on transformer networks have shown strong performance on tasks such as answering questions about images. Zhe Gan of Microsoft and colleagues at Microsoft and the University of Maryland improved such models via Vision-and-Language Large-scale Adversarial (VILLA) training.
Key insight: Vision-and-language models often are pretrained, for instance, to fill in blanks in image captions, and then fine-tuned for a specific task, such as answering questions about images. Previous work with language models showed that adversarial fine-tuning — that is, giving the model input that’s designed to fool it and training it not to be fooled — can increase accuracy. The team extended this idea to vision-and-language models in both pretraining and fine-tuning.
How it works: The authors worked with UNITER, which has achieved state-of-the-art performance on several vision-and-language tasks. UNITER embeds images and text separately. Then it feeds the embeddings into a BERT-like model to create a multimodal embedding.
- The authors used a variation on FreeLB, an adversarial training technique. FreeLB perturbs embeddings by learning a small vector that, when added to embeddings, is likely to fool the network, and then training the model to answer correctly regardless.
- The authors perturbed both image and text embeddings, but not at the same time. The model’s objective was threefold: predict the correct answer using unperturbed embeddings, predict the correct answer using perturbed embeddings, and to keep those predictions and confidence in them close to one another.
- They pretrained UNITER to perform masked language modeling (guessing which words are missing from a text passage, usually based on surrounding words, but in this case based on an accompanying image) and image-text matching (guessing whether a text and image are paired). Pretraining involved four large image-and-caption datasets.
- They fine-tuned and tested on several vision-and-language tasks. For instance, visual question answering required answering questions about images like, “what color are her eyes?” Visual commonsense reasoning required answering multiple-choice questions such as, “why is [person4] pointing at [person1]?” followed by “I think so because…”
Results: UNITER trained with VILLA outperformed a standard UNITER in six vision-and-language tasks. In visual question answering, UNITER with VILLA answered 73.67 percent correctly, while the plain model answered 72.91 percent correctly. In the two-stage visual commonsense reasoning task of answering a question and justifying the answer, UNITER with VILLA scored 59.75 percent, while its standard counterpart succeeded 57.76 percent of the time.
Why it matters: We understand the world through several modalities, and that makes us smarter. For instance, to describe a tree, neither an image nor a biological description is sufficient, but together they have a revealing synergy. Current models still struggle to grasp the meaning of images and language individually, but they will always be missing something until they can draw connections between them.
We’re thinking: Vision: check. Language: check. Now sound, aroma, touch . . .
A MESSAGE FROM DEEPLEARNING.AI
All four courses of our TensorFlow: Advanced Techniques Specialization are now available on Coursera! Enroll now

Draw a Gun, Trigger an Algorithm
Computer vision is alerting authorities the moment someone draws a gun.
What’s new: Several companies offer deep learning systems that enable surveillance cameras to spot firearms and quickly notify security guards or police, according to Vice.
No people were harmed in the training of this model: Some developers of gun detection models have gone to great lengths to produce training data.
- Virginia-based Omnilert trained its Gun Detect system using simulations from video game software, scenes from action movies, and thousands of hours of video depicting employees holding toy or real guns.
- Alabama-headquartered Arcarithm, which makes systems for gun detection, produced training data by photographing guns in front of a green screen and compositing them into scenes such as offices. The company created 30,000 to 50,000 images of each of America’s 10 most popular rifles and handguns to train its Exigent-GR software.
- Other companies including Actuate, Defendry, Scylla, and ZeroEyes offer similar systems.
Behind the news: The use of computer vision in such offerings updates earlier systems based on sounds. For instance, ShotSpotter is used by over 100 police departments in the U.S. The system picks up gunshot sounds from acoustic sensors placed around a community and uses machine learning to compare them with an audio database. When it recognizes a gunshot, it triangulates the location and alerts police.
Why it matters: Gun violence is endemic across the U.S, including hundreds of mass shootings. By warning police or security guards before a shooter opens up, AI-powered gun detection could save lives.
We’re thinking: Like any machine learning system applied to the real world, gun detection algorithms aren’t perfect. One such system used in New York state schools was found to mistake broom handles for guns. Such mistakes could be dangerous if they prompt police to enter possible crime scenes with their own weapons drawn and pulses pounding.

Annual Report, Robot Edition
Corporations are tailoring their financial reports to be read by machines.
What’s new: Automated systems download far more company financial reports than humans, according to a study by the U.S. nonprofit National Bureau of Economic Research. Consequently, companies are filling those reports with data that looks good to computers.
What they did: The study analyzed 50 years of quarterly and annual financial reports submitted by public companies to the U.S. Securities and Exchange Commission.
- Drawing on SEC download logs, the authors examined the IP address associated with each download to determine whether a person or a machine initiated it. They found that automated downloads grew from 360,862, or 39 percent of the total, in 2003 to around 165 million, or 78 percent, in 2016.
- Companies that served large numbers of machines-initiated downloads were more likely to make their reports machine-readable by, say, adhering to ASCII standards, separating tables from text, and ensuring that documents contained all the information required to interpret them.
- Moreover, these companies use language more likely to produce positive scores from sentiment-analysis models. For instance, they tend to avoid words associated with negative emotions, lawsuits, or uncertainty.
Behind the news: Computer systems increasingly drive the stock market. Last year, Deutsche Bank estimated that automated systems made buying and selling decisions for 80 percent of equity trading and 90 percent of equity futures trading. Corporate financials are following suit.
Why it matters: The study found that the more easily a computer can digest a company’s financial reports, the faster its stock is traded after a report has been published. This suggests that the market’s pace, already lightning-fast, is bound to accelerate.
We’re thinking: Companies have every incentive to tweak their reports to impress their audience, whether readers consist of wetware or software. But there’s a slippery slope between painting a rosy picture and exaggerating in ways that border on fraud. Regulators, analysts, and AI practitioners alike have a responsibility to guard against market manipulation.