
Dear friends,
When a researcher works for a company, what rights should they have to publish their work, and what rights should the company that sponsored the work have? This issue has come up many times in the AI community across many companies, most recently around Timnit Gebru’s very public departure from Google, which involved a disagreement over research she was preparing to publish.
Researchers and companies often share a desire to contribute ideas that move AI forward. At the same time, they can also have completely legitimate interests that may differ. Researchers may want to make their work available to the community, while the organizations that fund that work may want to keep certain inventions secret or patent them. Researchers and companies may be willing or unwilling, to varying degrees, to point out inconvenient truths that need to be addressed.
It’s not always obvious how to balance these interests. For example:
- Should researchers be allowed to release any technology they wish, as long as they don’t publish confidential information?
- Alternatively, should companies (and universities) have the final say, including the right to stop publication of papers when it’s in their interest to do so? (This is the de facto policy in many companies today.)
- Should a company be responsible for ensuring the quality of research published under its name, or should this be left only to peer review? Conversely, If a researcher publishes a scientifically flawed paper, does the fault lie with the researcher, or with both the researcher and the company?
- What would be a reasonable prepublication review process within companies, and how can we ensure that it is applied fairly and consistently?
- What rights and responsibilities do researchers and companies have with respect to patent filings of inventions in which they both played a part?

I’ve submitted publications for review, and I’ve set policies that govern how others’ work should be reviewed. As a co-author, I’ve also pulled publications when I felt they were not up to standard. These experiences have shown me that the answers to these questions may differ, depending on the parties involved.
What is clear, though, is that researchers and companies need to set clear expectations ahead of time, and then abide by them consistently. Both parties have an interest in avoiding situations where a researcher spends substantial time and energy working on ideas with the intent to publish them, only to be surprised that they’re unable to do so.
I would like to see the AI community get together and establish a fair set of rules that balance everyone’s interests. Every researcher, company, and university is different, and possibly no one-size-fits-all answer will work for everyone. But if we set expectations collectively, we might be able to nudge companies toward a balanced set of policies around publications.
What rules do you think would be fair? Let me know via social media or by sharing your ideas here.
Keep learning!
Andrew
News
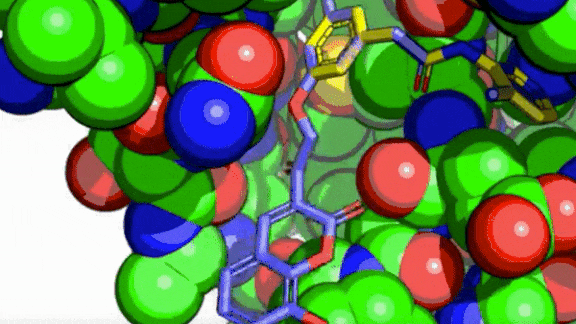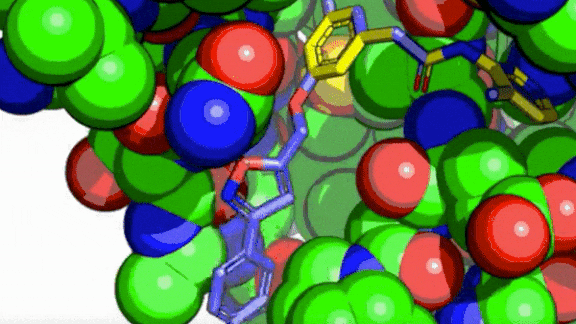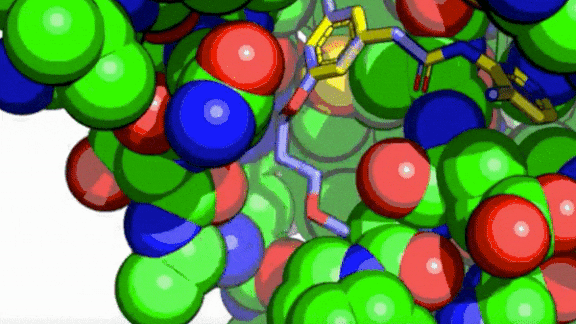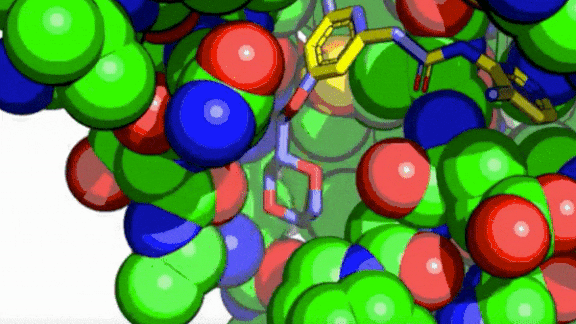
Crowdsourcing Against Coronavirus
Covid Moonshot, an open source project to vet potential medicines using machine learning, is closing in on compounds that might help curb Covid-19.
What’s new: Four new antiviral drugs identified by the project are ready to advance to animal trials, according to IEEE Spectrum. Unlike vaccines, which prevent infection, antivirals treat people who are already infected.
How it works: Last spring, PostEra, a UK chemistry company, invited scientists to submit designs for molecules with potential to thwart the virus. It used a semisupervised deep learning platform to analyze more than 14,000 submissions. You can read our earlier report on the project here.
- More than 30 teams from industry, academia, and independent labs synthesized 1,000 of the most promising compounds.
- Of those, the project’s organizers determined that four related compounds had the most potential.
- Volunteers iteratively adjusted the molecules and re-analyzed them to improve their potency.
- In lab tests, at least one candidate killed the virus without damaging human cells.
Behind the news: Covid Moonshot does not seek to profit from its effort. If any of its compounds successfully complete animal trials, which could happen by mid-2021, they will enter human clinical trials. If they pass that test, they will be made available to drug makers at no cost to manufacture and distribute.
Why it matters: Antivirals typically are far less expensive to produce and easier to distribute than vaccines. These drugs could help keep the pandemic in check while inoculations make their way through the global population.
We’re thinking: Although vaccines are beginning to roll out, now is no time to relax. Keep social distancing and hand washing until public-health experts say otherwise.

Robotaxi Reimagined
A new breed of self-driving car could kick the autonomous-vehicle industry into a higher gear.
What’s new: Zoox unveiled its first product, an all-electric, driverless taxi designed fully in-house.
How it works: The vehicle has no driver’s seat, steering wheel, or pedals — just four inward-facing passenger seats. It’s capable of driving in either direction and uses lidar, radar, and cameras to guide its navigation and collision avoidance systems. It can go for 16 hours on single charge.
- The car’s perception system locates itself within a defined driving area and classifies other vehicles, bicyclists, pedestrians and other objects. The vision subsystem mocks up pedestrian skeletons to classify behaviors such as pushing a stroller, looking at a phone, stepping out of a vehicle, and using a hand to signal stop or go.
- A prediction system extrapolates what surrounding objects will do next, while a planning and control system handles navigation decisions like speed and lane changes.
- If the vehicle encounters a difficult situation, a remote human operator can step in to, say, suggest a new route or relabel obstacles. Zoox adds these situations to its training simulation to improve the system.
Behind the news: Founded in 2014 and acquired by Amazon in July, Zoox has been road testing its self-driving technology in San Francisco and Las Vegas using cars built by other manufacturers. The company is just one part of Amazon’s self-driving portfolio. The retail giant also has invested in autonomous vehicle makers Aurora and Rivian.
Are we there yet? Despite years of hype and billions of dollars spent on research and development, self-driving cars are a long way from replacing human drivers. So far, they’re considered safe enough only to operate in relatively small, well mapped environments.
- EasyMile started operating commercially in 2017 and has ferried passengers around airports, college campuses, and business parks in several countries.
- Waymo last year debuted the first commercial autonomous taxi service, which is available in parts of Phoenix, Arizona.
- Voyage, which focuses on ferrying passengers in retirement communities, is road testing its driverless G3 robotaxi and plans to release a commercial version by the middle of next year.
Why it matters: Self-driving car companies have pulled back their early, grandiose promises. By proving the technology in constrained environments, they can improve safety on the open road while building trust with the public. With the Amazon juggernaut behind it, Zoox could be a significant milestone on the road to practical vehicular autonomy.
We’re thinking: Zoox’s announcement received a rapturous reception in the press, but the company has only just begun producing vehicles and doesn’t expect to operate commercially until at least 2022.
A MESSAGE FROM DEEPLEARNING.AI

All three courses of our GANs Specialization are available on Coursera! Join more than 12,000 learners who have gained the knowledge and skills to take advantage of this powerful technology. Enroll now
Physics Simulations Streamlined
Computer simulations do a good job of modeling physical systems from traffic patterns to rocket engines, but they can take a long time to run. New work takes advantage of deep learning to speed them up.
What’s new: Youngkyu Kim and a team at University of California and Lawrence Livermore National Lab developed a technique that uses a neural network to compute the progress of a fluid dynamics simulation much more quickly than traditional methods.
Key insight: Changes in the state of a simulation from one time step to the next can be expressed as a set of differential equations. One of the faster ways to solve differential equations is to calculate many partial solutions and combine them into an approximate solution. A neural network that has been trained to approximate solutions to differential equations also can generate these partial solutions. Not every neuron is important in calculating a given partial solution, so using only the subnetwork of neurons required to calculate each one makes this process much more efficient.
How It works: They used an autoencoder made up of two single-hidden-layer neural networks, an encoder and a decoder. The decoder’s output layer was sparsely connected, so neurons received input from only a few neurons in the previous layer. The authors trained the autoencoder to reproduce thousands of states of Burgers’ Equation, which simulates the location and speed of fluids in motion.
- At inference, the encoder encoded a solution at a given time step and passed it to the decoder.
- The authors divided the autoencoder’s output vector into partial solutions using an unnamed sampling algorithm. Then they traced the neurons involved in each one, defining subnetworks.
- For each subnetwork, they calculated the partial derivative of all its weights and biases. They took the integral of the partial derivatives to calculate partial solutions of the next timestep.
- They combined the partial solutions into a prediction of the simulation’s new state via the recently proposed algorithm SNS, which uses the method of least squares to approximate a solution.
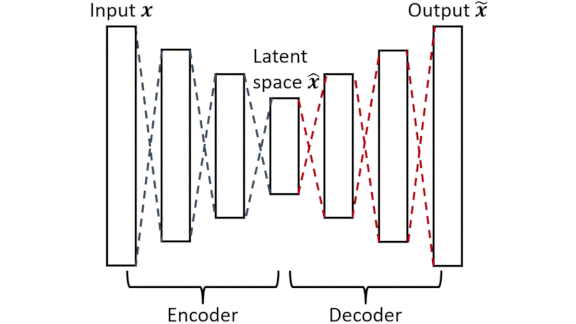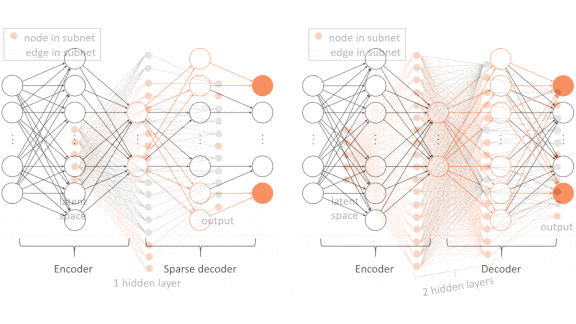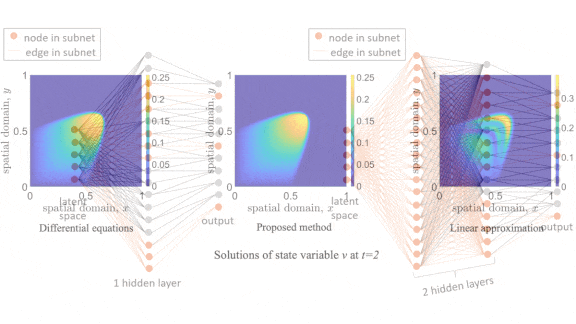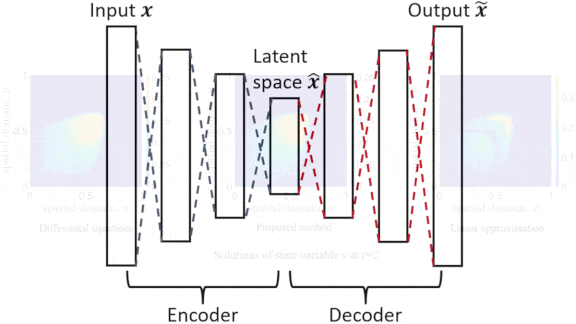
Results: On the Burgers’ Equation that involves one spatial dimension, their method solved the problem 2.7 times faster than the usual approach with only 1 percent error. On the two-dimensional Burgers’ Equation, their method solved the problem 12 times faster with less than 1 percent error. Given the speed increase between one- and two-dimensional Burgers’ Equations, the authors suggest that acceleration may rise with the number of equations a simulation requires.
Why it matters: Our teams have seen a number of problems, such as airfoil design or optimization of nuclear power plants, in which an accurate but slow physics sim can be used to explore options. The design pattern of using a learning algorithm to approximate such simulations more quickly has been gaining traction, and this work takes a further step in that direction.
We’re thinking: In approximating solutions to a Burgers’ Equation, neural networks clearly meat expectations. Other approaches wouldn’t ketchup even if the authors mustard the effort to keep working on them.

Written by Quill, Read by Computer
The secrets of history are locked in troves of handwritten documents. Now a machine learning platform is making them amenable to digital search.
What’s new: Transkribus, a program developed by the University of Innsbruck, is transcribing centuries-old records en masse and making them available to scholars worldwide. The system has rendered letters between the Brothers Grimm, manuscripts by English philosopher Jeremy Bentham, and Amsterdam’s city archives.
How it works: Since handwriting varies so much, the platform trains a bespoke transcription model for each individual scribe.
- The system’s key component is a handwriting recognition module that correlates a writer’s scrawl with letters of the alphabet. The recognizer stacks LSTM layers atop convolutional layers, Transkribus co-creator Günter Mühlberger told The Batch.
- To train a model, users manually transcribe and upload around 15,000 words in any language — that’s 50 to 100 pages — penned by the target author. After training, they can upload new documents by the same author for automatic transcription.
Behind the news: Transkribus launched in 2015 as a collaboration between 17 archives, universities, and research groups across Europe. Some 45,000 users have trained 7,700 models so far.
Why it matters: Most optical character recognition approaches perform poorly on the millions of handwriting styles represented in historical archives. By transcribing and making these documents searchable and sortable, machine learning is helping to deepen our understanding of past people and events.
We’re thinking: This platform could also be a gift to amateur historians with shoeboxes full of their forebears’ diaries, documents, and love letters.