
Dear friends,
Last week, I wrote about the limitation of using human-level performance (HLP) as a metric to beat in machine learning applications for manufacturing and other fields. In this letter, I would like to show why beating HLP isn’t always the best way to improve performance.
In many machine learning problems, labels are determined by a person who evaluates the same sort of input as a learning algorithm would. For instance, a human labeler may look at a picture of a phone to determine if it’s scratched, and an algorithm would examine a similar picture to learn to detect scratches. (Note that this is not always the case. A human labeling a cancer diagnosis on an X-ray image may also rely on a tissue biopsy from the patient, while an algorithm would use the resulting dataset to learn to diagnose cancer based on images alone.)
In cases where labels were determined by a human by looking at the same input that an algorithm would, what are we to make of situations in which HLP is well below 100 percent? This just means that different people labeled the data differently. For example, the ground-truth labeler who created a test set may have labeled a particular phone as scratched, while a different labeler thought the same phone was not scratched, and thus made a mistake in marking this example. If the second labeler disagreed with the ground-truth labeler on 1 out of 10 examples, then HLP in this task would be 90 percent.

In this situation, rather than trying to build a learning algorithm that achieves 91 percent accuracy, it would be better to look into how the two labelers formed their judgements and try to help them make their labels more consistent.
For example, all labelers may agree that scratches smaller than 1 mm are not significant (y=0), and scratches greater than 3 mm are significant (y=1), but they label scratches between 1 mm and 3 mm inconsistently. If we can spot this problem and get the labelers to agree on a consistent standard — say, that 1.5 mm is the point at which the labels should switch from y=0 to y=1 — then we’ll end up with less noisy labels.
Setting standards that make labels more consistent will actually raise HLP, because humans now agree with one another more frequently. At the same time, having more consistently labeled data will result in better machine learning performance. This improvement is more important in many practical applications than the academic question of whether an algorithm beat HLP.
HLP does have a role to play in establishing baseline performance for estimating irreducible, or Bayes, error, which in turn helps with error analysis. You can learn more about this in Deep Learning Specialization Course 3 and Machine Learning Yearning.
But the message I hope you’ll take away from this letter is that, when a human labeler has created the class labels that constitute ground truth and HLP is significantly less than 100 percent, we shouldn’t just set out to beat HLP. We should take the deficit in human performance as a sign that we should explore how to redefine the labels to reduce variability.
Keep learning!
Andrew
News

Unsupervised Prejudice
Social biases are well documented in decisions made by supervised models trained on ImageNet’s labels. But they also crept into the output of unsupervised models pretrained on the same dataset.
What’s new: Two image classification models learned social biases from ImageNet photos, according to a study by researchers Carnegie Mellon and George Washington University.
How it works: The authors measured the extent to which Google’s SimCLRv2 and OpenAI’s iGPT associated types of people with certain attributes.
- Using images from CIFAR-100 and Google Images, they assigned each picture either a category (such as man, woman, white, black, or gay) or an attribute (such as pleasant, unpleasant, career, or family).
- Then they fed the images to the model to generate features.
- They compared the features generated in response to different types of people (say, men or women) with features of opposing pairs of attributes (say, pleasant and unpleasant). In this way, they could determine the degree to which the model associated men versus women with those attributes.
Results: Features generated by both models showed social biases such as associating white people with tools and black people weapons. While SimCLRv2 tended to associate stereotyped attributes with certain categories more strongly, iGPT showed such biases toward a broader range of categories. For instance, features generated by iGPT associated thin people with pleasantness and overweight people with unpleasantness, and also associated men with science and women with liberal arts.
Behind the news: ImageNet 2012 contains 14 million images annotated by human workers, who passed along their prejudices to the dataset. ImageNet creator Fei-Fei Li is spearheading an effort to purge the dataset of labels that associated genders, races, or other identities with stereotypes and slurs.
Why it matters: When unsupervised models pick up on biases in a dataset, the issue runs deeper than problematic labels. The authors believe that their models learned social stereotypes because ImageNet predominantly includes images of people in stereotypical roles: men in offices, women in kitchens, and non-white people in general excluded from images showing situations that have positive associations such as weddings. Machine learning engineers need to be aware that a dataset’s curation alone can encode common social prejudices.
We’re thinking: Datasets are built by humans, so it may be impossible to eliminate social biases from them completely. But minimizing them will pay dividends in applications that don’t discriminate unfairly against certain social groups.
Retailers Adjust to the Pandemic
Covid-19 wreaked havoc with models that predict retail sales — but China’s biggest annual e-commerce event showed that they’re back in business.
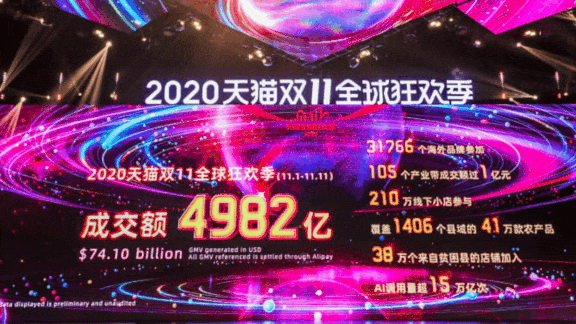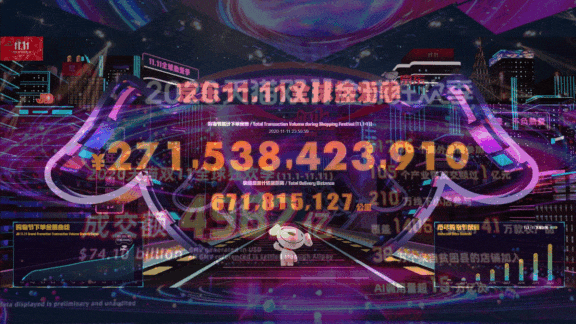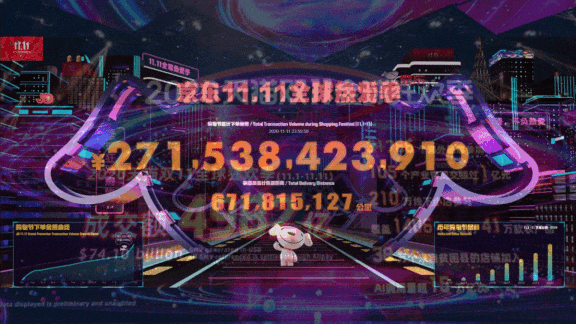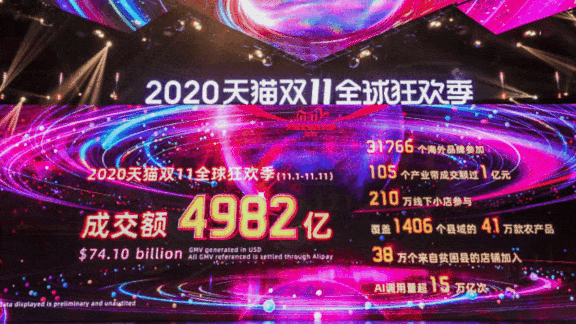
What’s new: China’s two biggest retailers, Alibaba and JD, used AI models trained on pandemic-era consumer behavior to make sure warehouses were stocked and deliveries arrived on time during the annual Singles Day shopping bonanza, according to MIT Technology Review. Alibaba’s sales of $74.1 billion doubled those of last year, while JD’s $40.9 billion exceeded the 2019 take by 33 percent.
Revised models: Covid-19 hit China just before the surge of holiday shopping for Chinese New Year, on January 25. Normally, major retailers use sales data from that day to prepare their models for Singles Day. Instead of gifts, however, consumers were making runs on pandemic essentials like masks, toilet paper, and hand sanitizer, throwing the models off kilter.
- Alibaba’s logistics subsidiary Cainiao refined its models to rely less on seasonal shopping patterns, and instead focused on short-term forecasting based on factors such as sales from the week before a major promotion, and the number of active Covid-19 cases in a given province.
- Social media influencers have become more important than ever during the pandemic. So for Singles Day, Alibaba tailored models to predict how fans would respond to promotions by hired influencers.
- JD adapted its models to factor in data from public health officials, the news, and social media.
Behind the news: The pandemic has driven an ecommerce boom worldwide even as it has taken a tragic toll on people across the globe. Online sales across China jumped 17 percent for Singles Day in 2020 over last year. In the U.S., online sales during this year’s holiday shopping season are already 21 percent higher than the same period in 2019.
Why it matters: These companies’ moves show the critical role AI can play in helping businesses respond to today’s fast-changing, utterly unprecedented market conditions.
We’re thinking: Covid-19 has accelerated digitization in retail, and is intensifying a division of the sector into AI haves and have-nots. Retailers that are struggling to survive lack resources to invest in AI and tech; those that are doing well are doubling down on their AI investments. Unfortunately, we think this will accelerate concentration of power.
A MESSAGE FROM DEEPLEARNING.AI

We’re thrilled to announce the launch of our TensorFlow: Advanced Techniques Specialization, available now on Coursera! Enroll now
Selective Attention
Large transformer networks work wonders with natural language, but they require enormous amounts of computation. New research slashes processor cycles without compromising performance.
What’s new: Swetha Mandava and a team at Nvidia reduced the number of self-attention layers in transformer-based language models. Their Pay Attention When Required (Par) approach achieves results comparable to those of Transformer-XL and Bert in substantially less time.
Key insight: The self-attention layers in transformer networks are notoriously inefficient. Some of them can be replaced by higher-efficiency feed-forward layers.
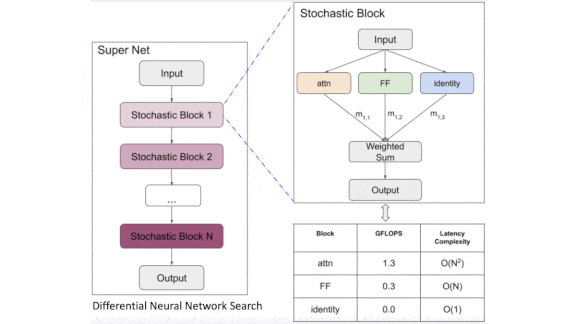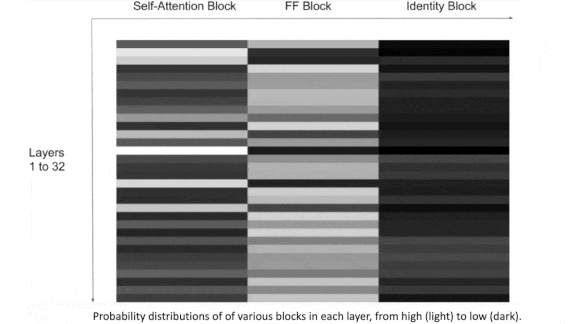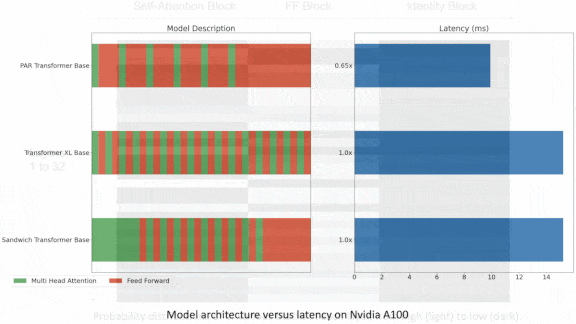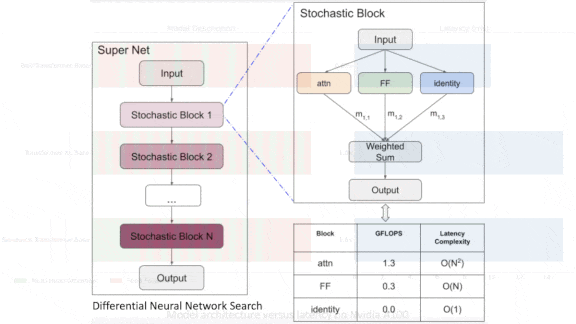
How it works: The authors used differential neural architecture search (DNAS), following earlier work to optimize both error and processing latency. For each layer in a network, DNAS starts with a user-defined set of blocks and finds the likelihood that a particular block is the best choice for that layer. The authors searched for optimal networks of 32 and 24 layers, the numbers of layers in Transformer XL and Bert.
- Each layer included three block types: feed-forward, self-attention, and identity.
- The authors trained their 32-layer network on Transformer-XL’s training corpus, WikiText-103. They trained their 24-layer model on Bert’s training corpus, Wikipedia+Books.
- The training yielded a decision about the most effective block for each layer. The authors built optimized versions accordingly and dubbed them Par-Transformer and Par-Bert.
Results: Par-Transformer matched Transformer-XL in perplexity (a measure of a language model’s predictive accuracy). It used roughly one-third as many self-attention blocks and executed in one-third less time, making decisions in 9.9 milliseconds versus 15.2 milliseconds running on Nvidia A100 GPUs. Par-Bert similarly matched Bert’s perplexity in a slimmer model while cutting latency to 5.7 milliseconds from 8.6 milliseconds.
Why it matters: Improving the runtime performance of transformer architectures could encourage their use in novel tasks.
We’re thinking: Transformer networks have come a long way in a short time and continue to improve rapidly. What an exciting time for deep learning!
Charting the AI Patent Explosion
A new study used AI to track the explosive growth of AI innovation.
What’s new: Researchers from the U.S. Patent and Trademark Office deployed natural language processing to track AI’s increasing presence in four decades of patent data. They found that the technology is involved in one out of six current applications.
What they did: The researchers trained an LSTM to analyze the text of nearly 12 million technology patents filed between 1976 and 2019 for language that described subcategories of AI including computer vision, language modeling, and evolutionary algorithms.
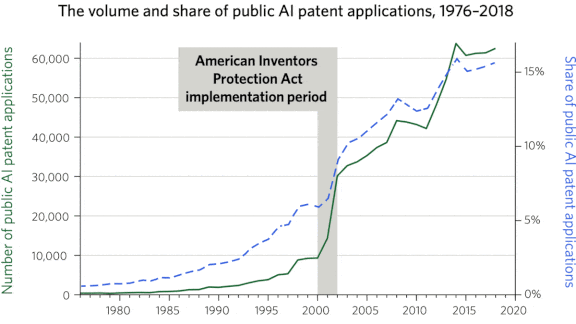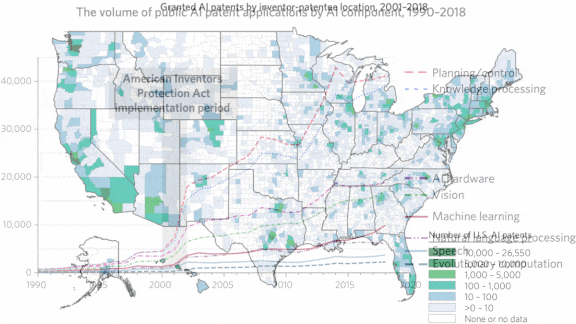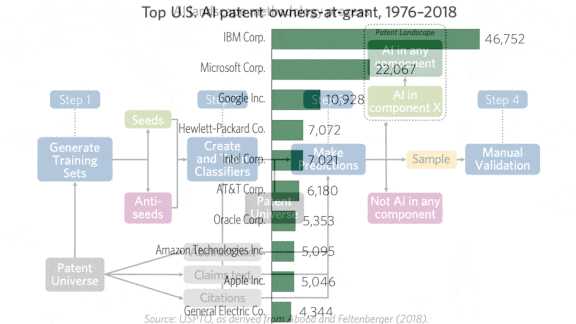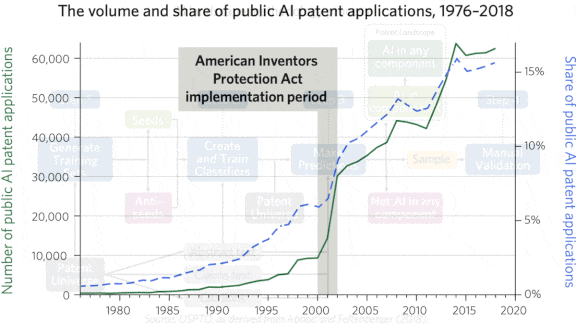
- The number of patents that include some form of AI grew slowly in the latter half of the 20th century, then surged. The annual tally of AI-related patent filings, currently over 60,000, has more than doubled since 2002.
- The researchers developed their own list of AI subcategories. The most popular were planning/control — processes that identify, create, and execute activities to achieve specific goals — and knowledge processing — used to streamline or automate tasks, for instance by detecting accounting errors. Each showed up in about 40,000 patent applications per year. Hardware and computer vision were next, with mentions in 10,000 to 20,000 filings a year.
- IBM, which has operated for more than a century, leads the U.S. in total AI-related patents, with 46,752 granted. Microsoft, which started in 1975, trails with less than half that amount. Google, founded in 1998, holds third place.
Behind the news: A 2019 report from the World Intellectual Property Organization found that 50 percent of machine learning patents globally were issued since 2013. China leads the world in AI patents, followed closely by the U.S.
Why it matters: These numbers give a concrete sense of the speed of innovation in AI and the ever-wider range of applications in which it’s used.
We’re thinking: We’re fans of AI technology!