
Dear friends,
Beating human-level performance (HLP) has been a goal of academic research in machine learning from speech recognition to X-ray diagnosis. When your model outperforms humans, you can argue that you’ve reached a significant milestone and publish a paper! But when building production systems, I’ve found that the goal of exceeding HLP isn’t always as useful. I believe the time has come to rethink it.
Landing AI, where I’m CEO, has been automating visual inspection for manufacturers. We’ve built computer vision systems that can look at photos of products on an assembly line and classify defects such as scratches and dents. But we’ve run into an interesting challenge: Human experts don’t always agree on the appropriate label to describe the damage. “Is this really a scratch?” If even human experts disagree on a label, what is an AI system to do?
In the past, when I built speech recognition systems, I encountered a similar problem. In some audio clips, the person speaking mumbles, or noise in the background overwhelms their words. Despite several listens, no human can transcribe them with confidence. Even when the words spoken are clear, transcriptions can be inconsistent. Is the correct transcription, “Um, today’s weather,” or “Erm . . . today’s weather”? If humans transcribe the same speech in different ways, how is a speech recognition system supposed to choose among the options?

In academic research, we often test AI using a benchmark dataset with (noisy) labels. If a human achieves 90 percent accuracy measured against those labels and our model achieves 91 percent, we can celebrate beating HLP!
But when building commercial systems, I’ve found this concept to be only occasionally useful. For example, if an X-ray diagnosis system outperforms human radiologists, does that prove — via incontrovertible logic — that hospital administrators should use it? Hardly. In practice, hospital administrators care about more than beating HLP on test-set accuracy. They also care about safety, bias, performance on rare classes, and other factors on which beating HLP isn’t feasible. So even if you beat HLP on test-set accuracy, your system isn’t necessarily superior to what humans do in the real world.
I’ve found that there are better ways to use the concept of HLP. Briefly, our goal as machine learning engineers should be to raise, rather than beat, HLP. I’ll expand on that thought in a future letter.
Working on visual inspection, my team has developed a lot of insights into applications of AI in this domain. I’ll keep sharing insights that are generally useful for machine learning practitioners here and in DeepLearning.AI’s courses. But I would like to share manufacturing-specific insights with people who are involved in that field. If you work in ML or IT in manufacturing, please drop me a note at hello@deeplearning.ai. I’d like to find a way to share insights and perhaps organize a discussion group.
Keep learning!
Andrew
News

AI Versus Voters
Major polling organizations took a drubbing in the press after they failed to predict the outcome in last week’s U.S. elections. At least one AI-powered model fared much better.
What’s new: Several companies that offer analytics services used machine learning to predict the next U.S. president. Their results ranged from dead-on to way-off, as reported by VentureBeat.
How they work: The companies analyzed social media posts to determine how large groups of people feel about a particular candidate.
- Expert.AI came closest. It analyzed 500,000 posts and found that challenger Joe Biden was more closely associated with words like “hope” and “success,” while incumbent Donald Trump was often mentioned alongside words like “fear” and “hatred.” Ranking these words according to their emotional intensity and frequency, the system predicted that Biden would win the popular vote by 2.9 percentage points. As of November 11, Biden’s actual margin was 3.4 percent according to The New York Times.
- KCore Analytics drew on a pool of 1 billion Twitter posts by influential users and those containing influential hashtags. It used the popularity of a given user or hashtag as a proxy for a subset of the voting population and scored positive or negative sentiment using an LSTM-based model to predict each candidate’s chance of victory. In July, it predicted Biden would win the popular vote by 8 to 9 percent — nearly triple the actual measure as of November 11 — and wrongly predicted the outcome in several swing states.
- Advanced Symbolics parsed public data from Facebook and Twitter to create a list of 288,659 users it considered a representative sample of U.S. voters. Its method relied on linking the way people talked about certain issues, like crime or Covid-19, to a certain candidate. The company predicted that Biden would sweep the electoral college with 372 electoral votes. The democratic nominee has gained 279 electoral votes as of November 11.
Behind the news: AI systems have made more accurate political predictions in the past. In 2017, Unanimous.AI correctly forecasted that Trump’s public approval rating would be 42 percent on his 100th day in office. KCore last year successfully predicted election results in Argentina, while Advance Symbolics claims to have accurately predicted 20 previous elections.
Why it matters: Human pollsters arguably performed poorly this year. But their jobs aren’t threatened by AI — yet.
We’re thinking: There’s plenty of room for improvement in predictive modeling of elections. But, as we said in last week’s letter, probabilistic predictions — whether they’re calculated by a human or a machine — are intended to convey uncertainty. The better people understand probabilities and how they’re modeled, the more comfortable they’ll be when events don’t match the most likely outcome according to public polls.
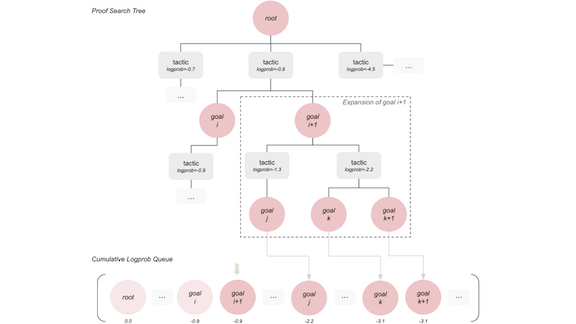
The Proof Is in the Network
OpenAI’s Generative Pre-Trained Transformer (GPT) architecture has created coherent essays, images, and code. Now it generates mathematical proofs as well.
What’s new: Stanislas Polu and Ilya Sutskever at OpenAI premiered GPT-f, a state-of-the-art transformer network that synthesized proofs good enough to impress mathematicians.
Key insight: A proof is a lot like a board game. You start with the pieces on the board (assumptions) and make a sequence of moves (steps) to reach a conclusion (theorem). AlphaGo famously beat world champions of the strategy game Go by iteratively building a tree of possible sequences of moves to find a winner. Similarly, GPT-f builds a tree of possible steps to prove a theorem.
How it works: GPT-f is based on transformers similar to GPT-2 and GPT-3. It outputs pairs of statements (vertices) and steps (edges) in syntax readable by Metamath Proof Explorer, an automated proof verifier, and assembles them into a tree. The authors pretrained it on web data scraped by Common Crawl — the corpus of choice for GPT-3 — as well as arXiv, Github, and Mathematics StackExchange to strengthen its sense of logic. They fine-tuned it on existing proofs verified by Metamath to give it familiarity with that system’s syntax.
- Given a set of assumptions and a statement to prove (called the goal in the figure above), GPT-f generates a candidate for the next statement (the next goal) and steps that prove it (the tactic). For instance, to prove the theorem (A ⇒ B), the model may first prove the tactic (A ⇒ C) and then attempt the next goal (C ⇒ B). It produces up to 32 next-goal and tactic candidates.
- The system uses each next-goal candidate to build a tree of statements provable from the assumptions. If one of those statements is the original goal, then GPT-f has produced a proof.
- The authors used Metamath to label each step correct or incorrect. They fed back Metamath-verified GPT-f proofs into the fine-tuning dataset. As GPT-f generated its shortest proof of a given theorem, it learned to create even shorter ones.
Results: The researchers compared GPT-f to MetaGen-IL, a recurrent neural network and the previous state-of-the-art theorem prover that uses Metamath syntax. Given a test set of theorems proved by Metamath, GPT-f generated valid proofs for 56.22 percent of them, MetaGen-IL 21.16 percent. Active members in the Metamath community were impressed by the economy of GPT-f’s proofs. The model shortened 23 previously verified proofs, which are now part of Metamath’s proof library.
Why it matters: Historically, AI has suffered from a gulf between deep learning and traditional symbolic approaches. This work shows that a sufficiently sophisticated neural network can manipulate symbols and logic as well.
We’re thinking: If this model were to find a solution to the Millennium Problem, the authors could add $1 million to the training budget.

Got Model?
Who needs cows when you can make milk from scratch?
What’s new: NotMilk, a dairy-free milk substitute that was designed with help from a deep learning model, made its debut in American grocery stores, the Wall Street Journal reports.
How it works: Chilean food-tech startup NotCo developed a model called Giuseppe that finds combinations of plant products that mimic the characteristics of animal-derived foods. The model also helped NotCo develop plant-based mayonnaise, ice cream, and hamburgers.
- NotCo scientists fed Giuseppe the molecular characteristics of cow’s milk, the company told The Batch. The model combed a database for plant-based ingredients that combine to replicate the physical and chemical properties of milk. Some of its choices were surprising: NotMilk contains pineapple juice, cabbage juice, chicory root, and coconut.
- Chefs cooked up prototypes, and human testers rated them for flavor, mouth feel, and visual appeal. Then researchers plugged the ratings into the database to refine Guiseppe’s training.
- The company fortified NotMilk with vitamins and vegetable proteins to make it nutritionally similar to cow’s milk. It tested the final product to ensure that it behaved properly in processes like baking and steaming.
Behind the news: NotCo is one of several companies using machine learning to discover new culinary secrets.
- Snack food giant Frito Lay is modeling chemical compounds to enhance the aroma of its products.
- Ingredion, a supplier of food ingredients, uses robots to collect data on texture. Its engineers use the data to model mouth feel for a variety of products.
- Analytical Flavor Systems deployed models that analyze data on consumer preferences to find flavors that appeal to different demographic groups, and then sells its insights to food and beverage companies.
Why it matters: Producing animal-based foods can take enormous quantities of natural resources compared to growing and processing plants. If AI can help the food and beverage industry develop the market for animal-free substitutes — which is expected to grow 14 percent annually over the next five years, according to one analysis —it could reduce the environmental toll.
We’re thinking: We look forward to the day when an AI-powered chef in our AI-augmented kitchen pours us a glass of AI-designed milk.
A MESSAGE FROM DEEPLEARNING.AI

We’re excited to announce that TensorFlow: Advanced Techniques Specialization will launch on November 18! And don’t miss the previous TensorFlow Developer Professional Certificate and TensorFlow: Data and Deployment Specialization.

That Kid Looks Like a Criminal
In Argentina, a municipal face recognition system could misidentify children as suspected lawbreakers.
What’s new: Authorities in Buenos Aires are scanning subway riders’ faces to find offenders in a database of suspects — but the system mixes criminal records with personal information about minors, according to Human Rights Watch. The report follows a lawsuit against the city filed by civil rights activists earlier in the year.
How it works: The system uses two databases. The first, called Conarc, contains details about people who have outstanding arrest warrants, including names, ages, and national ID numbers. It matches these records with faces in a second database that contains pictures of Argentine citizens. The system alerts police when it recognizes a suspect in the crowd.
- Human Rights Watch found 166 minors listed in Conarc, despite international rules protecting the privacy of juveniles. Most were between 16 and 17 years old, but some were as young as one. The group also found errors, such as children listed multiple times under different ID numbers, and questionable charges, including a three-year-old wanted for aggravated robbery.
- Last year, the United Nations concluded that Conarc holds information about dozens of children in violation of the international Convention of the Rights of the Child, which Argentina ratified in 1990. Government officials denied that Conarc contains information about children but admitted that it contains errors.
- Officials credit the system with helping to arrest nearly 10,000 fugitives in the city. In roughly one month last year, it alerted police to 595 suspects, five of whom were misidentified. One person, who was not in the criminal database but shared the same name as a suspect in an armed robbery case, was arrested and held for six days.
- The system is based on technology from NTechLab, a Russian AI company with customers in 20 different countries. The company claims a 98 percent accuracy rate.
Why it matters: Buenos Aires’ system relies on a database that appears to violate international human rights law, making children vulnerable to false arrests and other mishaps. Moreover, studies have shown that current face recognition technology is highly unreliable when used on children.
We’re thinking: The issues swirling around this system highlight the importance of clean, compliant data in machine learning applications: An error-free system that complied with legal requirements may still result in false arrests, but it would be defensible on grounds that it helped bring criminals to justice. The system also illustrates the pressing need to take extra care with machine learning models that bear on social outcomes. People may debate standards of justice, but they should be able to have confidence that models are applying those standards fairly.

Building Sites Meld Real and Virtual
Everyday cameras and computer vision algorithms are digitizing construction projects to keep builders on schedule.
What’s new: Based in Tel Aviv, Buildots maps output from building-site cameras onto simulations of the work in progress, enabling construction managers to monitor progress remotely. At least two large European builders are using the system, according to MIT Technology Review.
How it works: A client supplies to Buildots blueprints and plans, including schedules and lists of parts, for completion of each task involved in a building project. Buildots supplies GoPro 360-degree cameras mounted atop hardhats.
- The company uses the blueprints to build a detailed 3D mockup, known as a digital twin, of the finished building.
- Cameras worn by workers upload pictures to a remote server where image recognition software identifies and tracks as many as 150,000 objects.
- The system determines whether the objects are where they’re supposed to be and whether they’ve been fully installed. Then it updates the mockup appropriately.
- Managers can track progress via an online dashboard. They receive email or text alerts when tasks fall behind schedule.
Behind the news: AI startups are aiming to make the technology as fundamental to the construction industry as steel-toed boots.
- Civdrone accelerates site surveys using drones that place geo-tagged stakes in the ground.
- Smartvid.io helps keep workers safe by tracking whether they are wearing protective gear and — crucial in the Covid-era — observing social-distance protocols.
- Intsite builds systems that help heavy equipment operators balance loads, spot hazards, and choose where to drop their loads.
Why it matters: Mistakes can become delays that add to a construction project’s cost. Market research firm McKinsey estimated that the construction industry could add $1.6 trillion to the global GDP by catching mistakes before they cause serious delays.
We’re thinking: Buildots is bringing new meaning to the phrase “AI architecture.”