
Dear friends,
Today Landing AI, where I am CEO, launched LandingLens, an AI-powered platform that helps manufacturers develop computer vision solutions that can identify defective products. For AI to benefit a wide range of industries, we need platforms that enable experts in a variety of fields to build and deploy models. LandingLens is a step in this direction, and it’s available to manufacturers immediately.
A major challenge to taking advantage of AI throughout the economy is the sheer amount of customization needed. To use computer vision to inspect manufactured goods, we need to train a different model for each product we want to inspect: each smartphone model, each semiconductor chip, each home appliance, and so on. How can Landing AI build models for thousands of products without hiring thousands of machine learning engineers? It’s much better to empower the manufacturers to build and deploy these models themselves.
LandingLens enables experts in manufacturing — rather than experts in machine learning — to collect data, train models, deploy them, and carry out continuous learning. It helps them make sure their models work and scale up deployments. If the test data distribution drifts and the algorithm’s performance suddenly degrades, they’re empowered to collect new data and retrain the model without being beholden to an outside team.

Here are a few unique features of LandingLens:
- Rather than holding the training set fixed and trying to improve the model, we hold the model fixed and help manufacturers improve the training set. We’ve found that this approach leads to faster progress in production settings.
- Rather than focusing on building models that recognize defects better than humans can, our tools aim to improve human-level performance. The better humans can recognize defects, the more consistently they’ll label those defects in training data, and the better the trained models will be. This is a very different philosophy from usual in AI research, where the goal often is to beat human-level performance.
Having led AI teams at large consumer internet companies, I believe it’s time to take AI beyond the technology industry, to all industries. We’ve been building this platform for over a year, and I’m excited to be able to talk about it publicly. I hope that LandingLens — and other verticalized AI development platforms to come — will lower the bar for industrial deep learning and spread the benefits of AI throughout the economy.
Keep learning!
Andrew
News
Pushing for Reproducible Research
Controversy erupted over the need for transparency in research into AI for medicine.
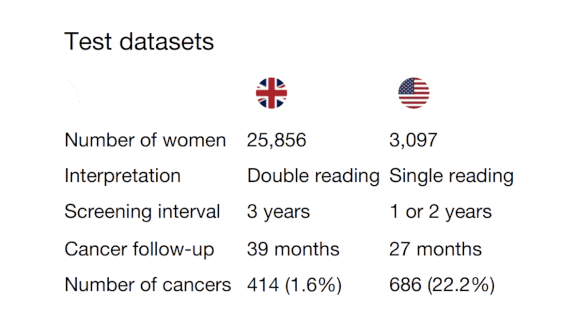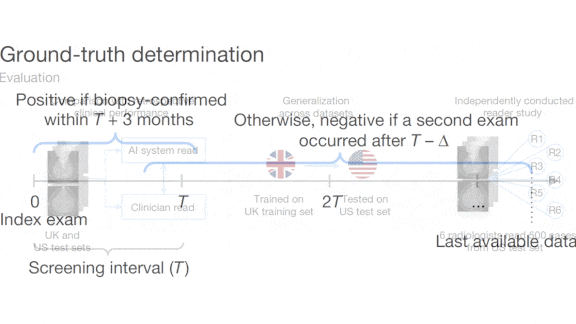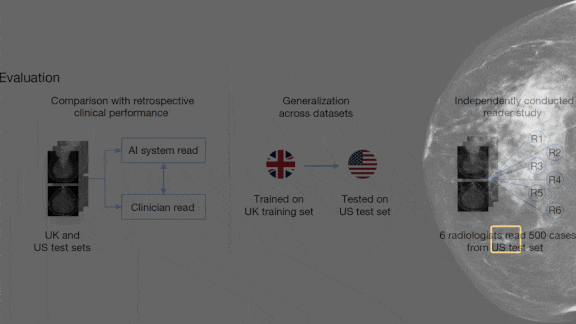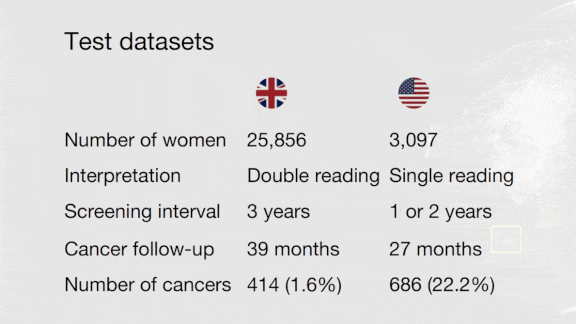
What’s new: Google Health introduced a system that purportedly identified breast cancer more accurately than human radiologists. But the search giant’s healthcare division failed to disclose details that would have enabled others to reproduce its results, dozens of critics wrote in a letter to Nature (also published on Arxiv).
The critique: Researchers at Harvard, University of Toronto, Vector Institute, and elsewhere argue that AI systems used to diagnose life-threatening conditions should meet high standards of transparency. The Google research fell short on several counts:
- The authors didn’t release the trained model for others to verify their results.
- Although they mentioned the framework and libraries used, they omitted training details such as learning rate, type of optimizer, number of training epochs, and data augmentation techniques. That’s like listing the ingredients in a cake recipe without disclosing the amounts, Benjamin Haibe-Kains of the University of Toronto, who co-authored the critique, told The Batch.
- One dataset used in the study, Optimam, is readily available. However, the authors also used patient data that remains private. In lieu of that dataset, the critics argue, the authors should have disclosed labels and model predictions that would allow for independent statistical analysis.
- Other details were also missing, leading to questions such as whether the model trained on a given patient’s data multiple times in a single training epoch.
The response: In a rebuttal published in Nature, the Google researchers said that keeping the model under wraps was part of “a sustainable venture to promote a vibrant ecosystem that supports future innovation.” The training details omitted are “of scant scientific value and limited utility to researchers outside our organization,” they added. They held back the proprietary dataset to protect patient privacy.
Behind the news: AI researchers are struggling to balance trade secrets, open science, and privacy. The U.S. Food and Drug Administration hosted a workshop earlier this year aimed at developing best practices for validating AI systems that interpret medical images.
Why it matters: Transparency makes it possible for scientists to verify and build on their colleagues’ findings, find flaws they may have missed, and ultimately build trust in the systems they deploy. Without sufficient information, the community can’t make rapid, reliable progress.
We’re thinking: There are valid reasons to withhold some details. For instance, some datasets come with limitations on distribution to protect privacy. However, outside of circumstances like that, our view is that researchers owe it to each other to make research findings as reproducible as possible.
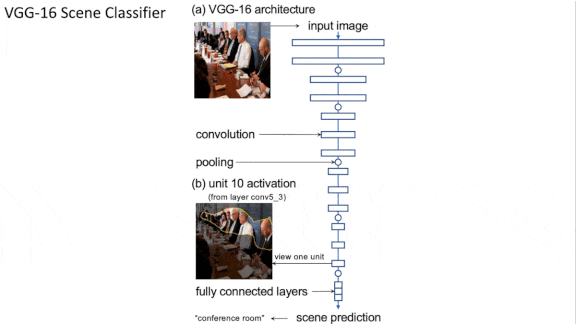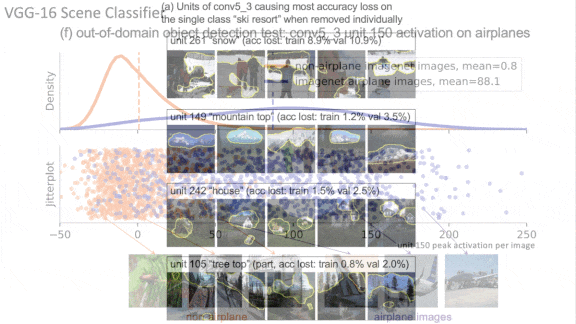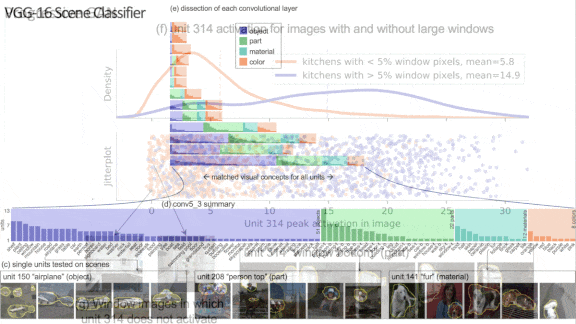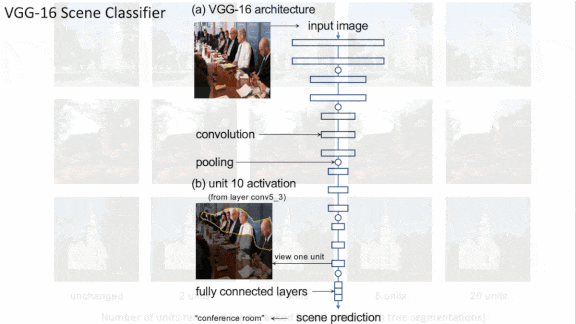
What One Neuron Knows
How does a convolutional neural network recognize a photo of a ski resort? New research shows that it bases its classification on specific neurons that recognize snow, mountains, trees, and houses. Zero those units, and the model will become blind to such high-altitude playgrounds. Shift their values strategically, and it will think it’s looking at a bedroom.
What’s new: Network dissection is a technique that reveals units in convolutional neural networks (CNNs) and generative adversarial networks (GANs) that encode not only features of objects, but the objects themselves. David Bau led researchers at Massachusetts Institute of Technology, Universitat Oberta de Catalunya, Chinese University of Hong Kong, and Adobe Research.
Key insight: Previous work discovered individual units that activated in the presence of specific objects and other image attributes, as well as image regions on which individual units focused. But these efforts didn’t determine whether particular image attributes caused such activations or spuriously correlated with them. The authors explored that question by analyzing relationships between unit activations and network inputs and outputs.
How it works: The authors mapped training images to activation values and then measured how those values affected CNN classifications or GAN images. This required calculations to represent every input-and-hidden-unit pair and every hidden-unit-and-output pair.
- The authors used an image segmentation network to label objects, materials, colors, and other attributes in training images. They chose datasets that show scenes containing various objects, which enabled them to investigate whether neurons trained to label a tableau encoded the objects within it.
- Studying CNNs, the authors identified images that drove a given unit to its highest 1 percent of activation values, and then related those activations to specific attributes identified by the segmentation network.
- To investigate GANs, they segmented images generated by the network and used the same technique to find relationships between activations and objects in those images.
Results: The authors trained a VGG-16 CNN on the places365 dataset of photos that depict a variety of scenes. When they removed the units most strongly associated with input classes and segmentation labels — sometimes one unit, sometimes several — the network’s classification accuracy fell an average of 53 percent. They trained a Progressive-GAN on the LSUN dataset’s subset of kitchen images. Removing units strongly associated with particular segmentation labels decreased their prevalence in the generated output. For example, removing a single unit associated with trees decreased the number of trees in generated images by 53.3 percent. They also came up with a practical, if nefarious, application: By processing an image imperceptibly, they were able to alter the responses of a few key neurons in the CNN, causing it to misclassify images in predictable ways.
Why it matters: We often think of neural networks as learning distributed representations in which the totality of many neurons’ activations represent the presence or absence of an object. This work suggests that this isn’t always the case. It also shows that neural networks can learn to encode human-understandable concepts in a single neuron, and they can do it without supervision.
Yes, but: These findings suggest that neural networks are more interpretable than we realized — but only up to a point. Not every unit analyzed by the authors encoded a familiar concept. If we can’t understand a unit that’s important to a particular output, we’ll need to find another way to understand that output.
We’re thinking: In 2005, neuroscientists at CalTech and UCLA discovered a single neuron in a patient’s brain that appeared to respond only to the actress Halle Berry: photos, caricatures, even the spelling of her name. (In fact, this finding was an inspiration for Andrew’s early work in unsupervised learning, which found a neuron that encoded cats.) Now we’re dying to know: Do today’s gargantuan models, trained on a worldwide web’s worth of text, also have a Halle Berry neuron?

RL Agents: SOS!
A new multimedia experience lets audience members help artificially intelligent creatures work together to survive.
What’s new: Agence, an interactive virtual reality (VR) project from Toronto-based Transitional Forms and the National Film Board of Canada, blends audience participation with reinforcement learning to create an experience that’s half film, half video game. The production, which runs on VR, mobile, and desktop platforms, debuted at the 2020 Venice Biennale exhibition of contemporary art. It’s available for download from Steam.
How it works: Five cute, three-legged creatures live atop a tiny, spherical world. They must learn to work together to grow giant flowers for food without throwing the planet off-balance. Players can simply watch them work or play an active role in the story by planting flowers or moving agents around.
- Players can let the agents interact under control of a rules-based algorithm or turn on a reinforcement learning (RL) model that drives them to seek rewards, such as bites of fruit, and avoid repeating mistakes, such as falling off the edge of the world.
- The agents were pre-trained in a stripped-down version of the game world using a method called proximal policy optimization, which makes RL less sensitive to step size without the tradeoffs incurred by other approaches. The game’s creators settled on PPO because it was quickest at training the agents to solve the game’s physical challenges, such as learning to balance their weight to keep the world from spinning, technical director Dante Camarena told The Batch.
- The developers are collecting data on how users interact with the agents. They’ll use the information to update the training simulation monthly.
Behind the news: Agence director Pietro Gagliano received an Emmy in 2015 for a VR experience in which viewers encountered the Headless Horseman from the Sleepy Hollow TV series.
Why it matters: Agence represents a new type of medium in which the audience members collaborate with AI to create unique, immersive experiences. It offers new possibilities for user input and interactive storytelling that — whether or not Agence itself catches on — seem destined to transform electronic entertainment.
We’re thinking: Video game opponents driven by rules can be challenging, but imagine trying to outsmart the cops in Grand Theft Auto if they could learn from your past heists.
A MESSAGE FROM DEEPLEARNING.AI

Have you completed courses 1 and 2 of the Generative Adversarial Networks Specialization? Course 3 will be available on Coursera next week! Pre-enroll here
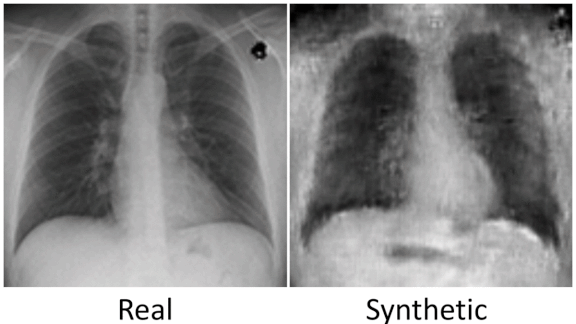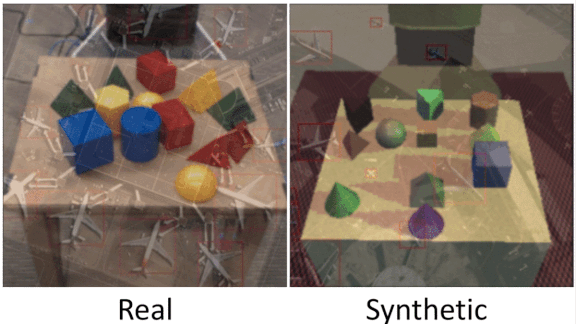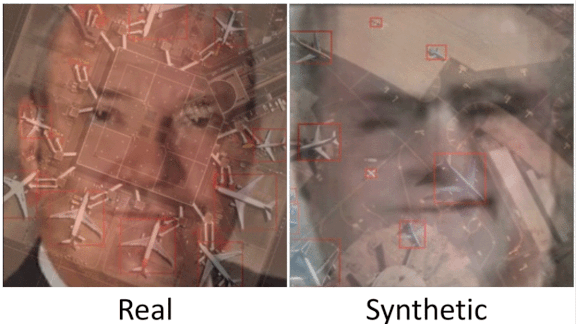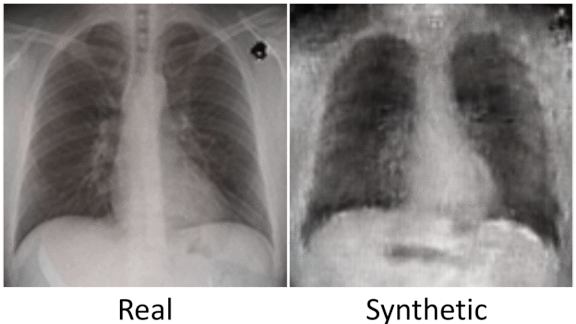
Battling Bias in Synthetic Data
Synthetic datasets can inherit flaws in the real-world data they’re based on. Startups are working on solutions.
What’s new: Generating synthetic datasets for training machine learning systems is a booming business. Companies that provide such datasets are exploring ways to avoid perpetuating biases in the source data.
How it works: The cost of producing a high-quality training dataset is beyond the reach of some companies, and in situations where sufficient real-world data isn’t available, synthetic data may be the only option. But such datasets can echo and even amplify biases including potentially harmful social biases. Vendors like AI.Reverie, GenRocket, Hazy, and Mostly AI are looking for ways to adjust their synthetic output — “distorting reality,” as Hazy’s chief executive put it — to minimize the risk that models trained on their wares will result in unfair outcomes.
- In a recent experiment, Mostly AI generated a dataset based on income data from the 1994 U.S. census, in which men who earned more than $50,000 outnumbered women who earned that amount by 20 percent. To generate a more even distribution of earning power, the company built a generator that applied a penalty when the ratio of synthetic high-earners who were male versus female became lopsided. That approach narrowed the gap to 2 percent.
- The company also generated a dataset based on the infamous Compas recidivism dataset, which has been shown to lead models to overestimate the likelihood that a Black person would commit a crime and underestimate that likelihood for a White person. The initial synthetic dataset skewed toward Black recidivism by 24 percent. The company adjusted the generator using the same parity correction technique and reduced the difference to 1 percent.
Why it matters: Social biases in training datasets often reflect reality. It’s true that altering synthetic datasets to change the balance of, say, men and women who earn high incomes is trading one type of bias for another, rather than eliminating it altogether. The aim here is not necessarily to generate accurate data but to produce fair outcomes.
We’re thinking: We need data, but more than that, we need to build models that result in fair outcomes.
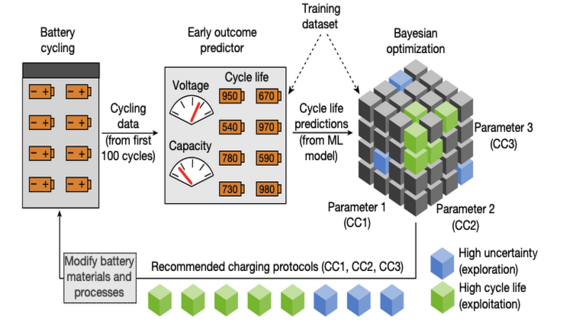
Getting a Charge From AI
Machine learning is helping to design energy cells that charge faster and last longer.
What’s new: Battery developers are using ML algorithms to devise new chemicals, components, and charging techniques faster than traditional techniques allow, according to Wired.
How it works: Designing better batteries involves tweaking variables such as electrode architecture, chemical composition, and patterns of current and voltage during charging. Typically, researchers change one at a time and can’t analyze the results until a battery dies. AI lets them test many at once and get results while the battery still has juice.
- Researchers from MIT, Stanford, and the Toyota Research Institute test the longevity of prospective designs in machines that discharge and recharge them repeatedly. They trained a model on data from these rigs to find better ways to recharge lithium-ion batteries without degrading their working lifetime. The model enabled them to complete in 16 days experiments that ordinarily would have required 500.
- A model at Argonne National Laboratory is sifting through a massive molecular database to find energy-storing chemicals. The model’s creators are also developing a platform that would let researchers and companies train their models using other people’s data without compromising anyone’s intellectual property.
- A machine learning platform developed by California-based Wildcat Technologies helped InoBat, a Slovakian startup, develop a lithium-ion battery that purportedly increases the range of electric vehicles by almost 20 percent. InoBat plans to begin producing the batteries by the end of 2021.
Behind the news: In recent years, machine learning has also helped researchers discover new molecules that improve energy density, predict how batteries will perform in different electric vehicles, test how well capacitor designs store energy, and advanced battery research in many other ways.
Why it matters: Batteries that last long, charge fast, and cost little are a key enabler for devices from self-driving cars to brain implants.
We’re thinking: In our recent Heroes of NLP interview, Chris Manning joked that “electricity is the new AI.” Maybe he was right! You can watch the whole thing here.