
Dear friends,
I read an interesting paper comparing the results of traditional passive learning (sitting in a lecture) versus active methods like the flipped classroom, where students watch videos at home and work on exercises in class. The paper is nicely summarized by this figure:
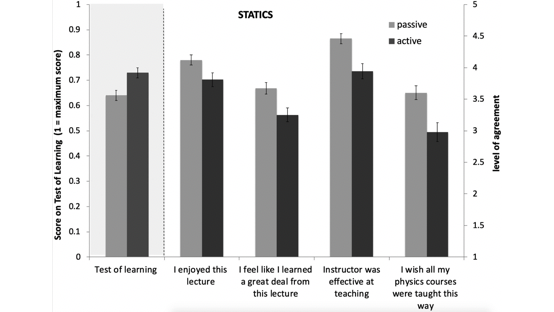
The leftmost pair of bars shows that students learn more from active learning. Ironically, they feel they are learning more from passive methods, shown by the remaining bars.
I’ve been using a flipped classroom for much of my teaching, with great results. Students watch lectures on Coursera, then come to the classroom to ask questions and work in small groups. This paper explains why many instructors are reluctant to switch to active learning, even though it’s more effective.
The world needs much better education everywhere. I hope more educators who teach in person will embrace active learning methods.
Keep learning!
Andrew
News

Ready or Not
Independent research lab OpenAI designed virtual agents to play hide-and-seek. They evolved increasingly clever strategies, eventually hacking the game world’s physics to gain advantage.
What happened: The researchers trained the agents to navigate and manipulate their environment and juiced them with reinforcement learning. Then they divided their creations into teams of hiders and seekers and set them loose in a virtual world that included movable blocks, walls, and ramps.
How it works: Seekers scored points if they caught sight of a hider. Hiders scored if they finished a game without being seen. An agent could move or lock objects in place; but only the agent that locked a given object could unlock it again.
- The agents figured out the basics over the first several million rounds. Around game 22 million, hiders — which were given a grace period at the start of each round to scramble for cover — began building shelters out of the movable objects.
- Roughly 100 million rounds in, seekers learned to infiltrate these hideaways using ramps. A few million later, the hiders stymied this strategy by locking the ramps.
- The researchers say they didn’t expect the agents to learn much more. But around game 450 million, seekers discovered they could push blocks around even if they were standing on top. This allowed them to surf to hiders’ walls and walk right into their hideaways (as seen in the animation above).
- Hiders eventually discovered the final, unbeatable strategy: Lock up every moveable object they wouldn’t be using as a barricade, then lock themselves inside a shelter of movable walls.
Why it matters: Hide-and-seek strategies could map to many real-world applications. For instance, rescue robots could be programmed as seekers — with rules restricting which types of objects are okay to pick up or move — to sift through rubble for survivors after a disaster.
We’re thinking: Reinforcement learning continues to find clever solutions. But the need to play 480 million rounds limits such techniques to simulated environments. We look forward to breakthroughs in small-data RL that make it possible to apply such techniques to physical robots that can play, say, thousands of games before they wear out. Meta learning, which organizations including OpenAI have worked on, could be an important step in this direction.
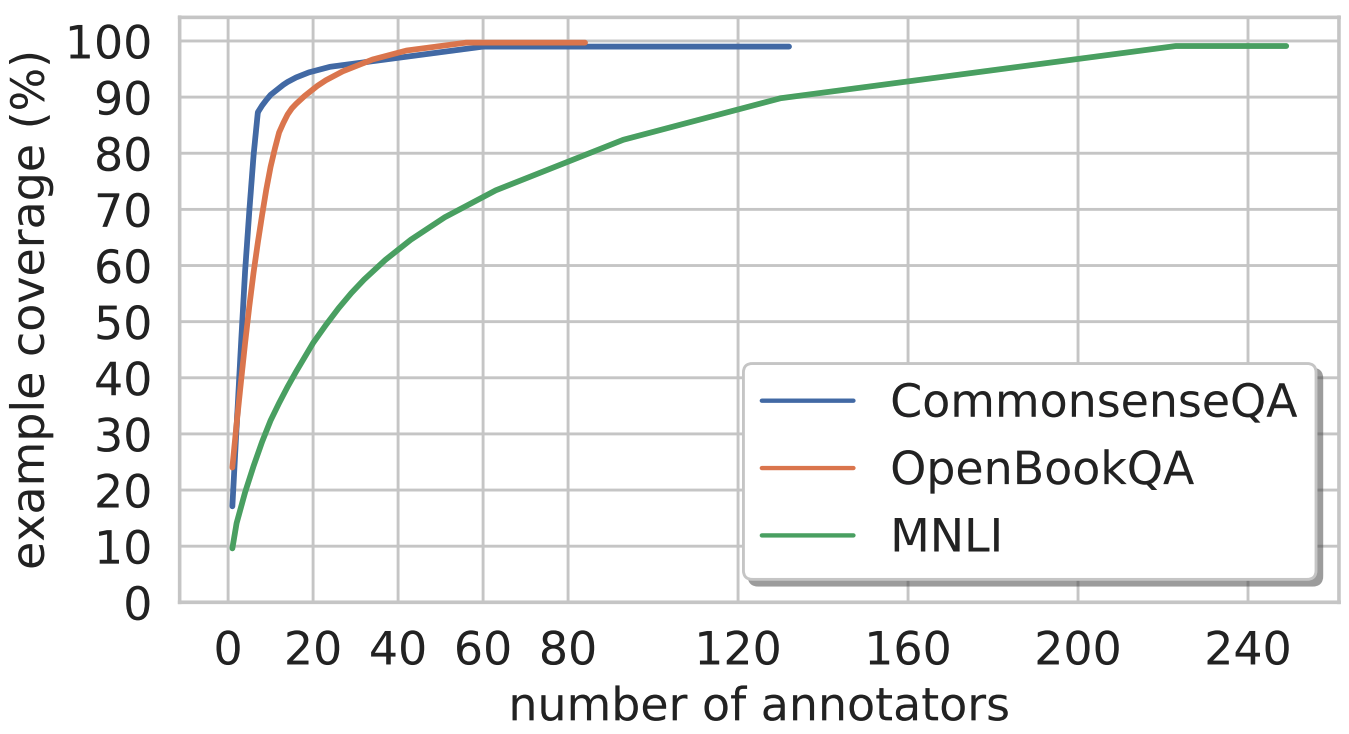
AI Knows Who Labeled the Data
The latest language models are great at answering questions about a given text passage. However, these models are also powerful enough to recognize an individual writer’s style, which can clue them in to the right answers. New research measures such annotator bias in several data sets.
What’s new: Researchers from Tel Aviv and Bar-Ilan Universities uncovered annotator bias in several crowdsourced data sets.
Key insight: Only a few dozen people may generate the lion’s share of examples in a crowdsourced natural-language data set (see graph above). Having an overly small team of annotators introduces bias that can influence a model’s behavior.
How it works: Mor Geva, Yoav Goldberg, and Jonathan Berant studied three data sets: MNLI, OpenBookQA, and CommonsenseQA. They fine-tuned the BERT architecture for each of three experiments:
- The authors measured the change in BERT’s performance after giving input sentences an annotator label. This experiment probed the degree to which the annotator’s identity encoded the correct answer.
- Then they used BERT to predict the annotator of individual text samples. This tested whether the annotator’s style encoded the person’s identity.
- Finally, they observed the difference in performance when the test and training sets had no annotators in common versus when the training set included samples from test-set annotators. An increase in performance further confirmed the presence of annotator bias.
Results: Performance improved an average of 4 percent across the three data sets when input text included an annotator label. The model inferred annotators most accurately in data sets created by fewer contributors. In two of three data sets, mixing in samples from test-set annotators during training improved test accuracy, implying that the model doesn’t generalize to novel annotators.
Why it matters: Annotator bias is pernicious and difficult to detect. This work raises a red flag around the number of contributors to data sets used in natural-language research.
We’re thinking: Benchmark data sets are used to identify the best-performing models, which drives further research. If the data is biased, it may lead that research astray. Here’s hoping this work inspires further enquiry into sources of bias and ways to assess and mitigate it.

Robots Put Down Stakes
Construction projects require teams of surveyors who continually map blueprints to precise, real-world locations. Drones might do it faster, saving time and money.
What’s new: Civdrone, a startup with offices in New York and Tel Aviv, is developing a platform that uses drones to place surveying stakes around construction sites.
How it works:
- The company uses off-the-shelf drones, each piloted by a human operator and equipped with a quiver of stakes.
- Where a survey marker is needed, a drone flies to the location, lands, and stabs a stake into the ground using a small pile driver.
- Each stake is topped with a QR code, which the drone encodes with the location’s GPS coordinates and elevation. The QR code can also contain information such as the presence of a gas pipe buried below.
- Construction workers can use a phone or dedicated QR-code reader to read the information.
Behind the news: Construction is a hot area for drones, where mostly they provide a bird’s-eye view of job sites to help builders plan, track progress, and spot hazards. One maker of software for commercial and industrial drones says the construction industry is its fastest-growing customer.
Why it matters: Surveying ensures that buildings stay true to their designs and plumb even as the ground shifts from day to day. Highly trained surveyors can insert around a hundred markers per day. Civdrone says it can do the work four times faster.
We’re thinking: Construction companies live and die by their ability to stay on schedule and budget. Eliminating even the smallest delays — such as workers waiting for surveyors to finish their work — can keep projects on track and maintain wiggle room for when bigger snafus inevitably occur.
A MESSAGE FROM DEEPLEARNING.AI

Is your neural network too deep? Learn to optimize your neural networks and make them effective in Course 2 of the Deep Learning Specialization. Start today

The Long and Short of It
Not long ago, text-to-speech systems could read only a sentence at a time, and they were ranked according to their ability to accomplish that limited task. Now that they can orate entire books, we need new benchmarks.
What’s new: A Google research team discovered that the usual measure of text-to-speech quality — having human judges rate single-sentence examples for human-like realism — varies widely depending on how samples are presented. That makes the standard procedure insufficient to evaluate performance on longer texts.
Key insight: Rob Clark and colleagues tested samples of various lengths and formats to see how they affected quality ratings.
How it works: Judges rated human and synthesized voices reading identical news articles and conversational transcripts.
- The judges evaluated samples in three forms: paragraphs, isolated sentences making up those paragraphs, and sentences preceded by the prior sentence or two (which were not rated).
- For sentences accompanied by preceding material, the preceding material was presented in human, synthesized, or text versions.
Results: Samples that included prior sentences earned higher scores than sentences in isolation, regardless of whether they were spoken by humans or machines. That is, the additional context made the synthesized voices seem more realistic. Moreover, readings of paragraphs scored higher than readings of their component sentences, showing that isolated sentences aren’t a good gauge of long-form text-to-speech.
Why it matters: Metrics that reflect AI’s performance relative to human capabilities are essential to progress. The authors show that the usual measure of text-to-speech performance doesn’t reflect performance with respect to longer texts. They conclude that several measures are necessary.
We’re thinking: As natural language processing evolves to encompass longer forms, researchers are setting their sights on problems that are meaningful in that context. This work demonstrates that they also need to reconsider the metrics they use to evaluate success.

Are Those Results Reproducible?
As deep learning becomes more resource-intensive, labs with better funding tend to achieve better results. One consequence is that less wealthy organizations often can’t replicate state-of-the-art successes. Some observers are calling it a crisis.
What’s new: Members of the deep learning community are asking researchers to be more forthright about the hardware, software, and computing power they used to achieve their results, according to Wired. That could help other researchers economize in seeking to replicate them.
How it works: NeurIPS asks that authors submitting papers to its December conference include a reproducibility checklist.
- Submissions must provide clearly written descriptions of algorithms, mathematical underpinnings, and models. Also, how much memory they needed, how much data they crunched, and — crucially — the number of times they ran the model. A link to the source code, too.
- Theoretical claims must include a list of assumptions, and the authors must publish the complete proof.
- Authors must back up figures and tables with either an open data set or a simulation.
Behind the news: In 2005, Stanford professor John Ioannidis published the landmark paper, “Why Most Published Research Findings Are False.” The work pointed out that science in many disciplines — particularly social psychology and medicine — relies on foundational research that hasn’t been replicated. Many observers fear that AI could fall into the same trap.
Why it matters: Science rests on hypotheses confirmed by experiments that yield consistent results every time they’re performed. AI is making rapid progress, but building on results that haven’t been verified puts that momentum at risk.
We’re thinking: In the natural sciences, unverified results fuel skeptics of anthropogenic climate change, who appeal to uncertainty to avoid decisive action on the greatest challenge of our time. Maintaining the highest scientific standards in AI is the best protection against critics who might take advantage of this issue to impede progress in the field.

Watching the Watchers
A growing number of nations use AI to track their citizens. A new report sheds light on who’s watching and how.
What’s new: Published by Carnegie Endowment for International Peace, “The Global Expansion of AI Surveillance” details which countries are buying surveillance gear, which companies are supplying it, and what technologies are most in-demand.
What the report says: Of 176 countries surveyed, at least 75 use some combination of face recognition, location tracking, and predictive policing.
- This list of users spans advanced democracies, including the U.S., Germany, and the UK, to absolute dictatorships. Countries with the largest defense budgets are most likely to invest in AI-driven surveillance.
- The U.S. and China are the top producers of equipment. Huawei is the most prolific, selling to governments in 50 countries. IBM is the biggest U.S. dealer, providing surveillance systems to 11 countries.
- The report simply lists nations, suppliers, and applications. It doesn’t evaluate whether particular users or uses violate international human-rights agreements.
Methodology: The authors drew their information from news reports. They accepted information as reported by established sources like The New York Times and Economist. They gathered corroborating accounts before relying on less rigorous sources like blogs.
Why it matters: Surveillance networks are deeply rooted even in bastions of liberal democracy like London. They can support public safety, as in New South Wales, Australia, where smartcams spot drivers using a phone behind the wheel. But they also promote social biases and erode trust in authority and, at their worst, they’re powerful tools for repression. Baltimore’s secret drone-policing fiasco shows how an all-seeing eye can lead well-intentioned authorities in the direction of invasive dystopia.
We’re thinking: Tracking which governments use which technology is important because it empowers citizens to react. The AI community, in particular, should take a proactive stance in promoting wise use of these technologies.