
Dear friends,
I’d like to share a programming tip that I’ve used for years. A large part of programming involves googling for code snippets you need on Stack Overflow and other websites. (Shh. Don’t tell the nondevelopers. ????) But that’s not enough if your goal is to maximize your own learning. When the relevant code snippet is just several lines, rather than copy-pasting them from a web page into my code, I usually retype them myself. The physical practice helps train my brain to internalize the concept and syntax.
To gain skill as a programmer, you need to internalize both the concepts and the syntax. When I’m trying to help friends get started on coding, I ask them to type print(“Hello World”). By typing it out, you can be sure you know the command’s syntax, such as whether it requires parentheses ( ), square brackets [ ], and so on.
You can’t learn to ride a bicycle by reading a book on the theory of bicycling. You have to do it yourself! Coding is more similar to this type of physical skill than most people realize, and practice makes perfect.

When you’re trying to master a programming technique, consider these practices:
- Read a line of code, then type it out yourself. (Bonus points for doing it without looking at the reference code while typing.)
- Learn about an algorithm, then try to implement it yourself.
- Read a research paper and try to replicate the published result.
- Learn a piece of math or a theorem and try to derive it yourself starting with a blank piece of paper.
Many creative artists start by replicating the works of artists who came before; so, too, in coding. By replicating examples of good programming (being mindful of copyright and attribution, of course), your brain masters the ability to create them. This frees you to focus on higher-level tasks so you can rearrange what you’ve learned into new, original works.
So next time you’re tempted to copy and paste a few lines of code, I hope you’ll start typing instead.
Keep learning!
Andrew
DeepLearning.AI Exclusive

Breaking Into AI: The Juggler
Kennedy Kamande Wangari works as a junior data scientist, organizes Nairobi’s AI community, studies machine learning, and is considering a startup, all while maintaining his personal life. In this edition of Breaking Into AI, he explains how he keeps so many balls in the air. Read more
News

Toward 1 Trillion Parameters
An open source library could spawn trillion-parameter neural networks and help small-time developers build big-league models.
What’s new: Microsoft upgraded DeepSpeed, a library that accelerates the PyTorch deep learning framework. The revision makes it possible to train models five times larger than the framework previously allowed, using relatively few processors, the company said.
How it works: Microsoft debuted DeepSpeed in February, when it used the library to help train the 17 billion-parameter language model Turing-NLG. The new version includes four updates:
- Three techniques enhance parallelism to use processor resources more efficiently: Data parallelism splits data into smaller batches, model parallelism partitions individual layers, and pipeline parallelism groups layers into stages. Batches, layers, and stages are assigned to so-called worker subroutines for training, making it easier to train extremely large models.
- ZeRO-Offload efficiently juggles resources available from both conventional processors and graphics chips. The key to this subsystem is the ability to store optimizer states and gradients in CPU, rather than GPU, memory. In tests, a single Nvidia V100 was able to train models with 13 billion parameters without running out of memory — an order of magnitude bigger than PyTorch alone.
- Sparse Attention uses sparse kernels to process input sequences up to an order of magnitude longer than standard attention allows. In tests, the library enabled Bert and Bert Large models to process such sequences between 1.5 and 3 times faster.
- 1-bit Adam improves upon the existing Adam optimization method by reducing the volume of communications required. Models that used 1-bit Adam trained 3.5 times faster than those trained using Adam.
Results: Combining these improvements, DeepSpeed can train a trillion-parameter language model using 800 Nvidia V100 graphics cards, Microsoft said. Without DeepSpeed, the same task would require 4,000 Nvidia A100s, which are up to 2.5 times faster than the V100, crunching for 100 days.
Behind the news: Deep learning is spurring a demand for computing power that threatens to put the technology out of many organizations’ reach.
- A 2018 OpenAI analysis found the amount of computation needed to train large neural networks doubled every three and a half months.
- A 2019 study from the University of Massachusetts found that high training costs may keep universities and startups from innovating.
- Semiconductor manufacturing giant Applied Materials estimated that AI’s thirst for processing power could consume 15 percent of electricity worldwide by 2025.
Why it matters: AI giants like Microsoft, OpenAI, and Google use enormous amounts of processing firepower to push the state of the art. Smaller organizations could benefit from technology that helps them contribute as well. Moreover, the planet could use a break from AI’s voracious appetite for electricity.
We’re thinking: GPT-3 showed that we haven’t hit the limit of model and dataset size as drivers of performance. Innovations like this are important to continue making those drivers more broadly accessible.

Do Muppets Have Common Sense?
Two years after it pointed a new direction for language models, Bert still hovers near the top of several natural language processing leaderboards. A new study considers whether Bert simply excels at tracking word order or learns something closer to common sense.
What’s new: Leyang Cui and colleagues at Westlake University, Fudan University, and Microsoft Research Asia probed whether Bert captures common-sense knowledge in addition to linguistic structures like syntax, grammar, and semantics.
Key insight: The multiheaded self-attention mechanism in transformer-based models like Bert assigns weights that represent the relative importance between one word and another in the input text. This process effectively creates a link between every pair of words. Given common-sense questions and answers, the researchers probed the relative strength of such links between the questions, correct answers, and wrong answers.
How it works: The authors devised two tasks, one designed to show whether Bert encodes common sense, the other to show whether Bert uses it to make predictions. The tasks are based on two metrics the model computes for each of the dozen attention heads per layer: (a) attention weights between words and (b) gradient-based attribution weights that show the importance of each attention weight in a given prediction.
- The authors used the CommonsenseQA dataset of multiple-choice questions about everyday phenomena. They concatenated each question to each potential answer to produce five question-and-answer pairs, only one of which is correct.
- Considering only correct pairs, the authors measured the percentage of times the attention weights between the answer and key concept were greater than that of the attention weights between the answer and every other word in the question. If this percentage was greater than random, they took it as a sign that Bert had encoded common sense.
- Considering all question-and-answer pairs, the authors measured how often the strength of the links (that is, attention and attribution weights) between the key concept and correct answer was greater than those between the key concept and incorrect answers. If this percentage was greater than random, then Bert used the encoded common sense to predict answers.
Results: Bert scored significantly higher than random in both tests. In the test for encoding common-sense knowledge, the highest-scoring attention head achieved 46.82 percent versus a random 10.53 percent. That score rose to 49.22 percent when the model was fine-tuned on a different portion of CommonsenseQA. In the test for using common-sense knowledge, the best attention head with a fine-tuned output layer scored 36.88 percent versus a random 20 percent.
Why it matters: Language models can string words together in ways that conform to conventional grammar and usage, but what do they really know beyond correlations among words? This work suggests that Bert, at least, also gains knowledge that might be considered common sense.
We’re thinking: Researchers have debated the notion that AI might exhibit common sense at least since the Cyc project in 1984. To study common sense a scientific, rather than philosophical, issue requires a clear definition of the phenomenon. Despite efforts from Aristotle (~300 B.C.) to CommonsenseQA, we still don’t have one. Apparently, the definition of common sense defies common sense.
Insurance Coverage for AI
The U.S. government’s largest national health insurance plan will pay for hospital use of a deep learning model, building momentum for AI to become an integral part of the doctor’s toolkit.
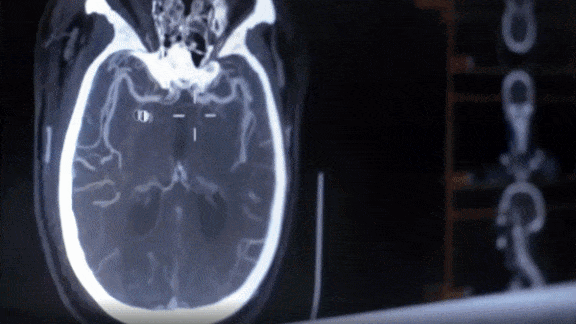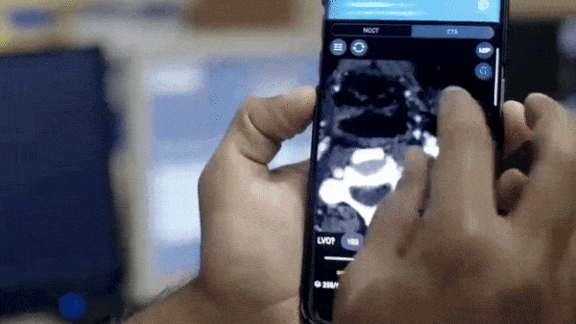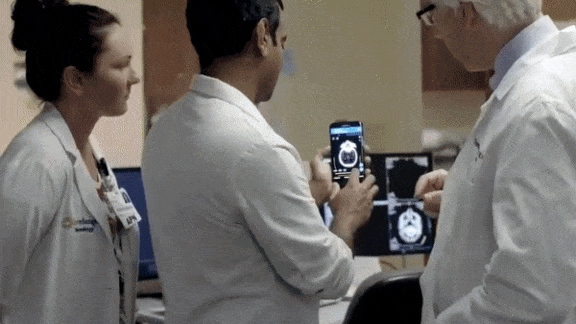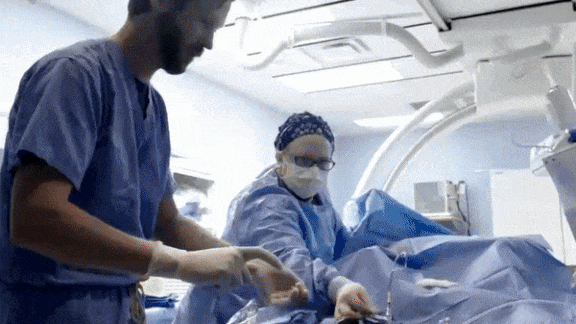
What’s new: The Centers for Medicare and Medicaid Services agreed to reimburse hospitals for use of Viz LVO, a smartphone app that spots signs of stroke so patients can receive time-critical treatment. It is the first AI software to be covered under Medicare’s New Technology Add-on Payment program, which covers the cost of certain breakthrough technologies. The government will pay hospitals up to $1,040 per patient for each use.
How it works: Elderly and otherwise disadvantaged U.S. citizens are eligible for government health insurance called Medicare. The agency that oversees the program added the app, from startup Viz.ai, to a list of new technologies that are approved for reimbursement.
- Viz LVO classifies blocked blood vessels in CT scans of the brain with 90 percent accuracy. When it identifies a potential stroke victim, it automatically notifies a specialist to review the case, bypassing the usual radiologist review.
- The model screens out roughly 90 percent of scans, dramatically reducing the number that require a specialist’s attention.
- The app has been shown to accelerate diagnosis and improve patient outcomes.
Behind the news: U.S. Food and Drug Administration approved Viz LVO in 2018. The agency has approved the efficacy and safety of 64 AI-powered medical devices and algorithms, according to a recent study.
Why it matters: In America, healthcare is a business, and hospitals hesitate to use even the most promising new technologies unless they know they will be paid. Medicare’s decision covers the app in a hospital setting without requiring patients to contribute. According to one analysis, the reimbursement is high enough for hospitals to pay for the technology assuming around 25 patients annually use it. This assures that Viz LVO will be used when doctors deem it helpful and could pave the way for more medical tools based on machine learning.
We’re thinking: The primary duty of the healthcare system is to ensure patient wellbeing. AI is gaining acceptance in medicine, but widespread adoption depends on compensating hospitals for their work.
A MESSAGE FROM DEEPLEARNING.AI
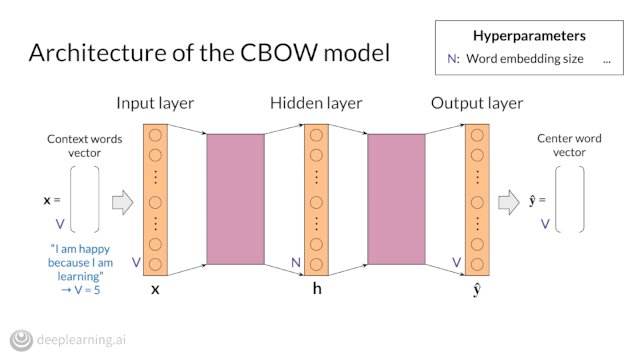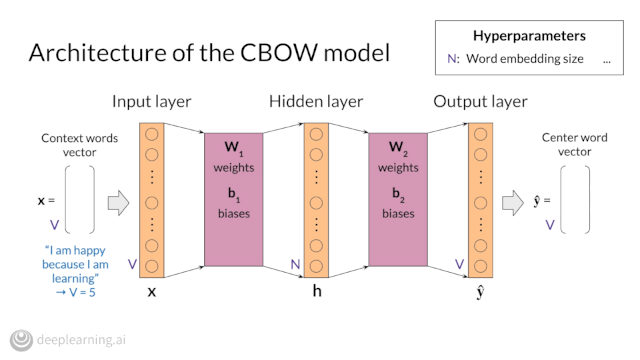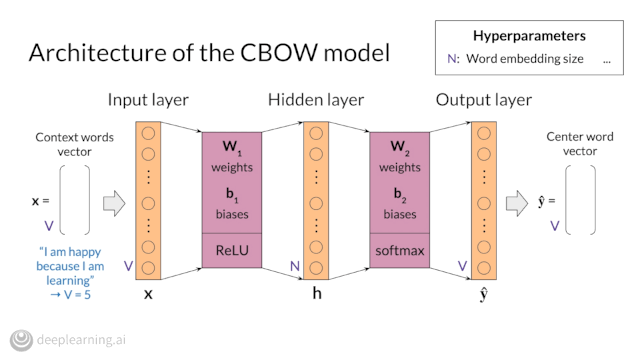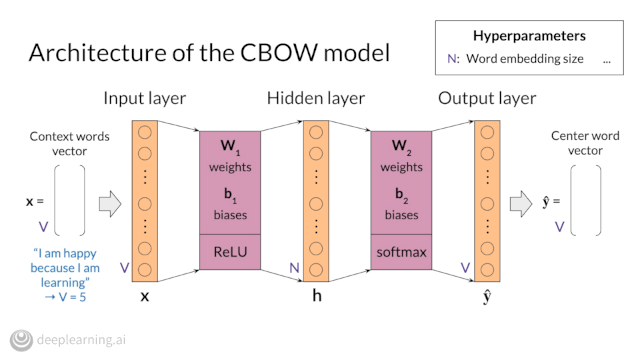
Course 4 of our NLP Specialization, which covers Attention Models, will be available next week! Pre-enroll now
Chess: The Next Move
AI has humbled human chess masters. Now it’s helping them take the game to the next level.
What’s new: DeepMind and retired chess champion Vladimir Kramnik trained AlphaZero, a reinforcement learning model that bested human experts in chess, Go, and Shogi, to play-test changes in the rules. Kramnik and others have observed that strategies learned from computers dominate human players’ current approaches. The collaboration aims to infuse the game with new energy.
How it works: AlphaZero is the successor to AlphaGo, the model that famously beat the Go world champion in 2016. The team taught the model nine novel variations of the rules to see how the changes affected gameplay.
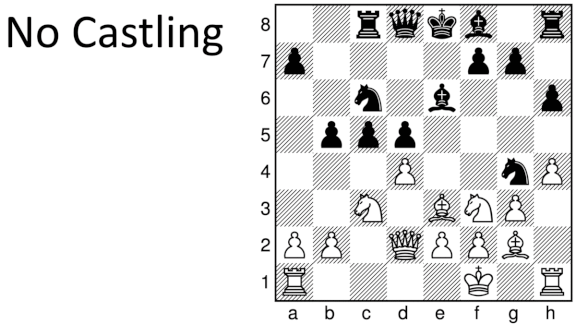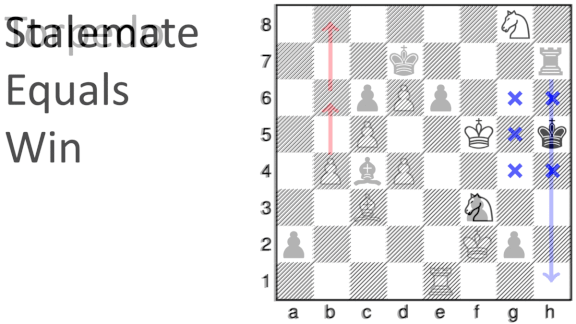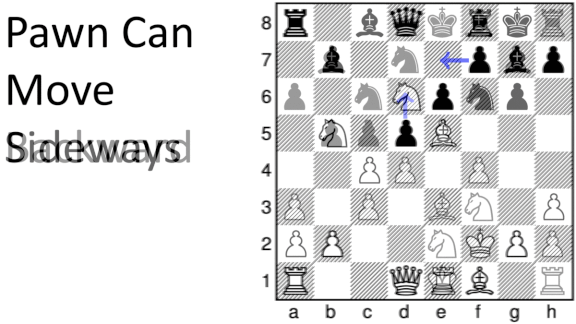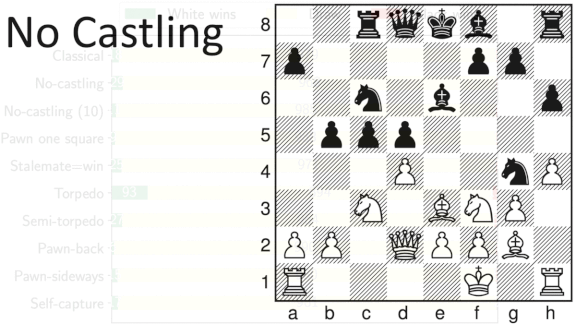
- Five of the variants altered the ways pawns can move. Two restricted defensive strategies. One allowed players to capture their own pieces, and one awarded victory if a player forced the game into a stalemate, or draw.
- AlphaZero played each variant against itself 10,000 times taking one second per move, then another 1,000 taking one minute per move. The team used the outcomes of these games to assess how the differing rules affected the value of each chess piece.
- Games with longer turn times resulted in more draws, an indication that these variants require deeper strategic thinking.
- The new rules spawned many intriguing patterns of play. The variant called self-capture, which allows players to take their own pieces, created more opportunities to sacrifice for strategic gains. The change “makes the game more beautiful,” Kramnik told Wired.
Behind the news: The rules of chess have evolved several times in its 1,500-year history, most famously in the 1400s when the queen was given the ability to move multiple squares in any direction.
Why it matters: In addition to shedding light on new possibilities for an ancient game, AlphaZero sped up the process of play-testing new rules. Game designers could adapt this approach to explore how various tweaks affect their own creations.
We’re thinking: AI and humans have a checkered past, but together they’re finding the right moves.
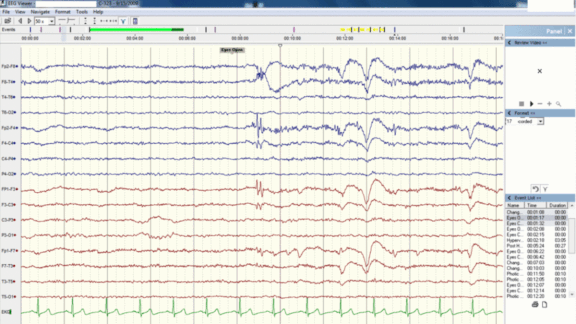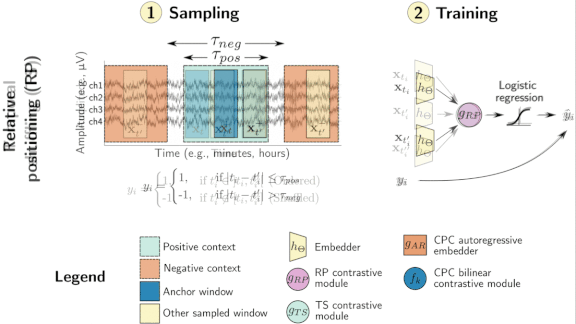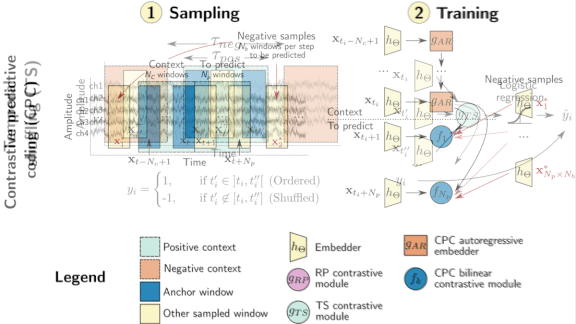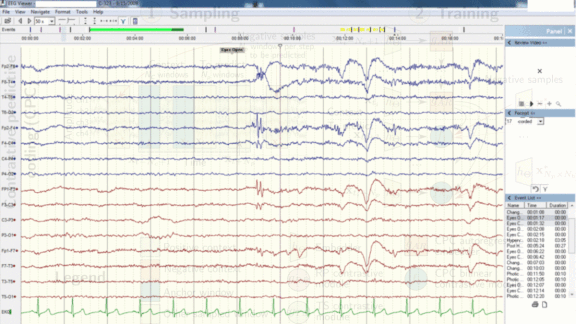
Unlabeled Brainwaves Spill Secrets
For people with neurological disorders like epilepsy, attaching sensors to the scalp to measure electrical currents within the brain is benign. But interpreting the resulting electroencephalogram (EEG) graphs can give doctors a headache. Deep learning could help diagnose such conditions.
What’s new: Led by Hubert Banville, researchers at Université Paris-Saclay, InteraXon Inc., University of Helsinki, and Max Planck Institute applied self-supervised learning to extract features from unlabeled EEGs.
Key insight: EEGs labeled to identify stages of sleep, abnormal brain activity, and the like are hard to come by, but unlabeled data is plentiful. The self-supervised technique known as contrastive learning has potential in this domain.
How it works: The authors extracted features from unlabeled EEGs using three contrastive learning techniques: contrastive predictive coding (CPC) and two methods of their own invention. They used data from the Physionet Challenge 2018 (PC18), which labels sleep stages, and TUHab, which labels various types of abnormal brain activity.
- An EEG is a time series of sensor measurements. CPC extracts features from an unlabeled sequence by training a model to distinguish consecutive measurements from non-consecutive ones.
- In the technique known as relative positioning, a model samples a single sensor measurement, called the anchor, and a random measurement from elsewhere in a sequence. It extracts features by learning to determine whether or not the random sample falls within a preset time window around the anchor (between 1 and 40 minutes for sleep stage classification).
- The technique called temporal shuffling teaches a model to learn the order in which samples are collected. The model samples two endpoints within a time window and a third from anywhere in the sequence. It extracts features by learning to classify whether or not the third sample came between the first two.
Results: The authors built simple models based on the extracted features and trained them to classify sleep stages and abnormal brain activity using limited amounts of labeled examples. The three techniques performed equally well. Using 10 percent of the labeled examples, they achieved a top accuracy of 72.3 percent on PC18 and 79.4 percent on TUHab.
Why it matters: The potential upside of using AI to interpret images in medical applications, where the expertise required to interpret them is relatively rare and expensive, is driving progress in learning approaches that don’t require so many labels. This work demonstrates progress in reading EEGs, but it comes with a caveat: Features clustered not only around stages of sleep but also the dates when the images were produced, which suggests that the algorithms recognized the products of particular technicians. Work remains to either make the AI more robust or eliminate the noise — likely both.
We’re thinking: If you think understanding artificial neural networks is difficult, you should talk with people who study biological neural networks!