
Dear friends,
Today we take it for granted that many people know how to read and write. Someday, I hope, it will be just as common that people know how to write code.
Several hundred years ago, society didn’t view language literacy as a necessary skill. A small number of people learned to read and write, and everyone else let them do the reading and writing. It took centuries for literacy to spread, and now society is far richer for it.
Words enable deep human-to-human communication. Code is the deepest form of human-to-machine communication. As machines become more central to daily life, that communication becomes ever more important.
Traditional software engineering — writing programs that explicitly tell a computer sequences of steps to execute — has been the main path to code literacy. But AI, machine learning, and data science offer a new paradigm in which computers extract knowledge from data. This technology offers another pathway to coding — one that strikes me as even more promising.

Many Sundays, I buy a slice of pizza from my neighborhood pizza parlor. The gentleman behind the counter may have little reason to learn how to build software applications (beyond personal growth and the pleasure of gaining a new skill).
But AI and data science have great value even for a pizza maker. A linear regression model might enable him to better estimate demand so he could optimize the restaurant’s staffing and supply chain. He could better predict sales of Hawaiian pizza — my favorite! — so he could make more Hawaiian pies in advance and reduce the amount of time customers had to wait for them.
Uses of AI and data science can be found in almost any situation that produces data, and I believe that a wide variety of professions will find more uses for custom AI applications and data-derived insights than for traditional software engineering. This makes literacy in AI-oriented coding even more valuable than traditional skills. It could enable countless individuals to harness data to make their lives richer.
I hope the promise of building basic AI applications, even more than that of building basic traditional applications, encourages more people to learn how to code. If society embraces this new form of literacy as it has the ability to read and write, we will all benefit.
Keep learning!
Andrew
DeepLearning.ai Exclusive

Working AI: Language Models for All
As a senior machine learning engineer at Retro Rabbit, a software consultancy, Jade Abbott focuses on solving customer problems. On the side, she develops natural language processing models for African languages. Read more
News

Credit Where It’s Due
A neural network is helping credit card users continue to shop even when the lender’s credit-approval network goes down.
What’s new: Visa developed a deep learning system that analyzes individual cardholders’ behavior in real time to predict whether credit card transactions should be approved or denied. The system can step in when a card issuer — generally a bank that normally would vet such transactions — suffers a network outage that makes it impossible to assess creditworthiness.
How it works: If a cardholder’s purchases are blocked, they might switch to another card, costing the bank revenue and possibly a customer. And if a miscreant tries to commit fraud, the bank stands to lose money. So Visa provides a backup system that predicts the decision in case the lender can’t due to software glitches, severe weather, or routine maintenance.
- The new model is trained on the company’s database of historical transactions. It learns an individual’s normal behavior based on factors like spending history, location, and timing of transactions.
- In tests, it matched banks’ decisions with 95 percent accuracy. An earlier, rule-based algorithm was half as accurate, according to a report by the Wall Street Journal.
- Visa plans to make the service available for a fee starting in October.
Why it matters: Unlike, say, fraud detection, this model touches cardholders directly to improve the customer experience. It points the way toward public-facing models that personalize banking, credit, and other financial arrangements.
Yes, but: Visa declined to share details of its new algorithm with The Batch. Decisions to extend credit can be based on patterns in data that encode social biases, and an algorithm trained on a biased dataset will reflect its biases. For instance, an algorithm may decline transactions requested by a cardholder whose home address is in a neighborhood associated with defaults on loans, and accept those requested by someone with a comparable history of repayment who lives in a wealthier neighborhood. Large financial institutions are aware of this problem, but standards that specify what is and isn’t fair are still in development.
We’re thinking:The financial industry’s health depends on trust. That should provide ample incentive to define the fairness of automated systems in lending and other financial services. Efforts such as Singapore’s Principles to Promote Fairness, Ethics, and Transparency are an important step.
Fewer Labels, More Learning
Large models pretrained in an unsupervised fashion and then fine-tuned on a smaller corpus of labeled data have achieved spectacular results in natural language processing. New research pushes forward with a similar approach to computer vision.
What’s new: Ting Chen and colleagues at Google Brain developed SimCLRv2, a training method for image recognition that outperformed the state of the art in self-supervised learning and beat fully supervised models while using a small fraction of the labels. The new work extends their earlier SimCLR, which The Batch reported on here.
Key insight: Larger models have proven more effective in self-supervised pretraining. But enormous models can be hard to deploy and run efficiently. SimCLRv2 starts with a giant feature extractor, fine-tunes the resulting features, and shrinks the final model using knowledge distillation. The result is a model of more reasonable size that achieves high accuracy despite training on relatively few labeled examples.
How it works: The most novel aspect of the original SimCLR was its use of image augmentation to train a feature extractor via contrastive learning. SimCLRv2 follows that pattern, but it uses deeper models and distills the trained architecture.
- The authors started by pretraining a feature extractor to generate similar features from augmented versions of the same image, and dissimilar features from unrelated images.
- Next, they fine-tuned the feature extractor using subsets of ImageNet. They ran experiments using either 1 percent or 10 percent of the labels.
- The final step was knowledge distillation: A teacher model trained a student model to match its predictions on unlabeled data. The authors achieved equally good results from both self-distillation (in which the teacher and student share the same architecture) and conventional distillation (in which the student is a more compact model).
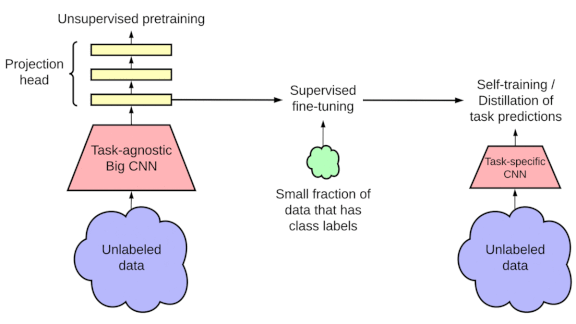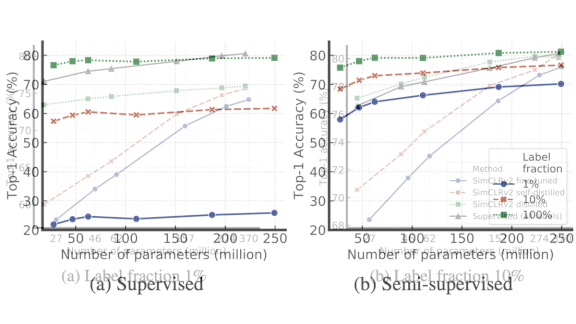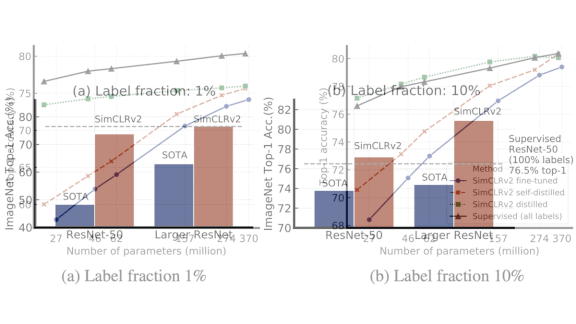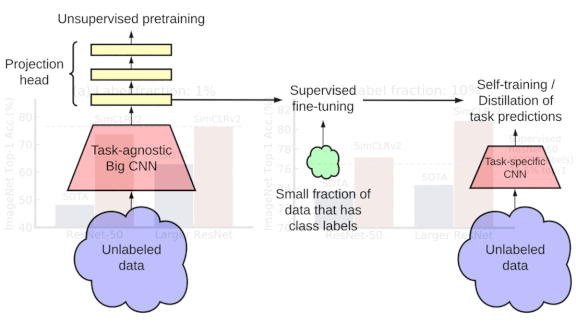
Results: A resnet-50 trained via SimCLRv2 using 10 percent of ImageNet labels outperformed a supervised resnet-50 trained on all the labels. It achieved a top-1 accuracy of 77.5 percent, an 8.7 percent improvement over the previous state of the art on the task with similar architecture and label constraints, versus the supervised model’s 76.6 percent. A resnet-152 (three times wider with selective kernels) trained via SimCLRv2 that used 1 percent of ImageNet labels matched a supervised resnet-50, achieving 76.6 percent top-1 accuracy. That’s 13.6 percent better than the previous best model trained on the same number of labels.
Why it matters: Techniques that make it possible to train neural networks effectively on relatively few labeled images could have an impact on small data problems such as diagnosing medical images and detecting defects on a manufacturing line, where labeled examples are hard to come by. The progress from SimCLR to SimCLRv2 bodes well for further advances.
We’re thinking: Self-supervised models tend to be huge partly because it isn’t clear initially what they’ll be used for, so they must learn lots of general-purpose features. Knowledge distillation looks like a promising way to trim the extra features for specific purposes in which a smaller network may suffice.

Planet Hunter
A machine learning model is scouring the cosmos for undiscovered planets.
What’s new: Astronomers from the University of Warwick developed a system that learned to identify faraway worlds in a dataset of thousands of candidates.
How it works: Astronomers often find planets outside Earth’s solar system, or exoplanets, by scanning the sky for stars that flicker, which indicates that a planet might pass in front of them. Given a set of possible planets, the researchers used machine learning to sift out false positives caused by camera errors, cosmic rays, or stars eclipsing one another to identify the real deal.
- The researchers trained several models using data that represents thousands of verified exoplanets among thousands of false positives, gathered by the retired Kepler space telescope. They tested the models on a large dataset of confirmed candidates.
- Out of nine different models, four — a Gaussian process classifier, random forest, extra trees classifier, and neural network — achieved top scores for area under the curve (AUC), precision, and recall.
- The authors double-checked their models’ conclusions against an established exoplanet validation technique, which didn’t always agree. They advocate using both approaches rather than relying on one or the other.
Results: In some test cases when the authors’ models and the earlier technique disagreed strongly, their approach identified confirmed exoplanets that the old approach missed. Similarly, the authors identified a preponderance of confirmed false positives that the earlier approach classified as planets with greater than 99 percent confidence.
What’s next: The authors’ models analyzed 2,680 unconfirmed candidates and classified 83 likely exoplanets. The earlier technique agreed that 50 of them were bona fide exoplanets — prime targets for further study. The authors hope to apply their method to the dataset collected from NASA’s recent Transiting Exoplanet Survey Satellite mission, which contains thousands more unconfirmed candidates.
Why it matters: Any indirect method of determining an exoplanet’s existence is bound to be imperfect. By combining approaches, researchers aim to improve the likelihood that what they take to be planets really are, so scientists can proceed with deeper investigations.
We’re thinking: Outer space offers an endless supply of data, and machine learning is the ultimate tool for crunching it. A match made in the heavens!
A MESSAGE FROM DEEPLEARNING.AI

Course 4 of our Natural Language Processing Specialization launches on September 23 on Coursera! Pre-enroll now

The Geopolitics of Data
Some politicians and pundits believe that, in the AI era, the military with the most data wins. A new analysis disputes this notion.
What’s new: A report by Georgetown University’s Center for Security and Emerging Technology examines the relative strengths of the Chinese and U.S. militaries in AI.
What it says: Data points come in many forms and degrees of usefulness, the authors note. Thus, the size of a country’s data trove doesn’t translate directly into power. A more important factor is the degree to which a country can use data to gain an edge in developing military systems.
- Unlike the U.S. government, China has the power to requisition vast troves of commercial data for military use. But commercial data is often useless for military AI applications. A self-driving tank trying to navigate a shell-pocked landscape would get no help from traffic data gathered by self-driving cars used by civilians, for instance.
- Instead, data management is key: gathering, cleaning, labeling, storing, and optimizing data so it suits the job at hand. Good data management accelerates the process of bringing prototypes to deployment.
- Moreover, emerging techniques like few-shot learning and synthetic data could make stockpiling huge datasets less important.
- The report concludes that no country currently has a clear advantage in military AI. Rather, different countries have distinct strengths and weaknesses.
Behind the news: The Chinese government began to emphasize big data in 2014 and since has launched efforts to industrialize data collection across all sectors of its economy and military. Its U.S. counterpart began working on its AI strategy last year and still hasn’t fully organized its cloud computing infrastructure.
Why it matters: More nuanced thinking about the relative value of various datasets can help military planners focus on what really matters without worrying over who has the biggest pile of petabytes.
We’re thinking: Datasets are often verticalized, and data from one domain often aren’t directly useful in another. Oversimplifications of the value of data don’t help us find the right data to make our systems work. In any case, every nation has a stake in avoiding the weaponization of AI.
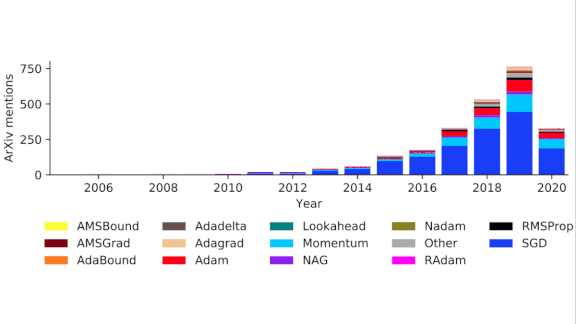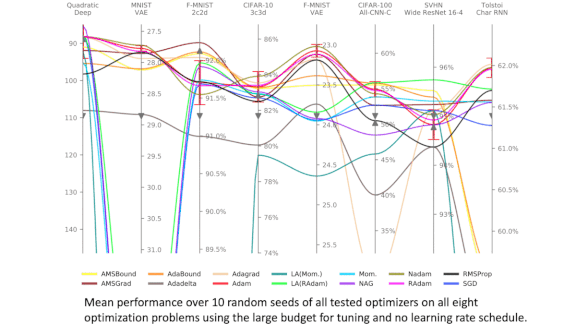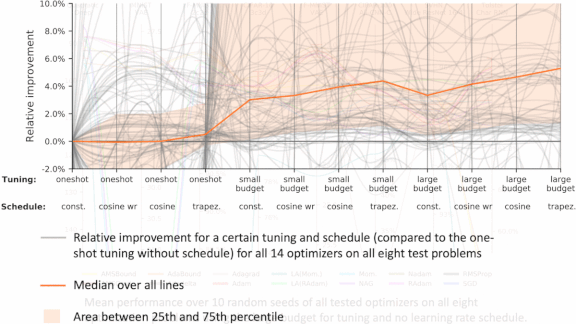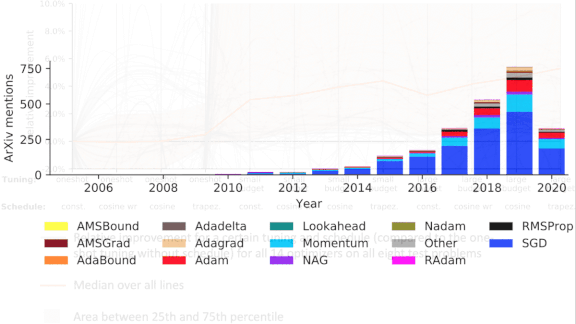
Optimizer Shootout
Everyone has a favorite optimization method, but it’s not always clear which one works best in a given situation. New research aims to establish a set of benchmarks.
What’s new: Robin Schmidt and colleagues at University of Tübingen evaluated 14 popular optimizers using the Deep Optimization Benchmark Suite some of them introduced last year.
Key insight: Choosing an optimizer is something of a dark art. Testing the most popular ones in several common tasks is a first step toward setting baselines for comparison.
How it works: The authors evaluated methods including AMSGrad, AdaGrad, Adam (see Andrew’s video on the topic), RMSProp (video), and stochastic gradient descent. Their selection was based on the number of mentions a given optimizer received in the abstracts of arXiv.org preprints.
- The authors tested each optimization method on eight deep learning problems consisting of a dataset (image or text), standard architecture, and loss function. The problems include both generative and classification tasks.
- They used the initial hyperparameter values proposed by each optimizer’s original authors. They also searched 25 and 50 random values to probe each one’s robustness.
- They applied four different learning rate schedules including constant value, smooth decay, cyclical values, and a trapezoidal method (in which the learning rate increased linearly at the beginning, maintained its value, and decreased linearly at the very end).
- Each experiment was performed using 10 different initializations in case a given initialization degraded performance.
Results: No particular method yielded the best performance in all problems, but several popular ones worked well on the majority of problems. (These included Adam, giving weight to the common advice to use it as a default choice.) No particular hyperparameter search or learning rate schedule proved universally superior, but hyperparameter search raised median performance among all optimizers on every task.
Why it matters: Optimizers are so numerous that it’s impossible to compare them all, and differences among models and datasets are bound to introduce confounding variables. Rather than relying on a few personal favorites, machine learning engineers can use this work to get an objective read on the options.
We’re thinking: That’s 14 optimizers down and hundreds to go! The code is open source, so in time we may get to the rest.