
Dear friends,
I’m thrilled to announce our new Natural Language Processing Specialization! Courses 1 and 2 are available on Coursera. We expect to release Courses 3 and 4 soon.
NLP is reshaping daily life. No doubt you’ve found valuable information using web search and the search functions found on countless websites and apps. Anti-spam systems are a critical part of the global email system. How does a smart speaker understand your commands? How does a chatbot generate relevant responses? This specialization will give you the foundation you need to understand such systems and the knowledge to build them yourself.

You will implement a sentiment analysis system, build models that translate human languages, and even construct a chatbot. You will master the most important NLP architectures including transformer networks, and you will receive practical, hands-on training to implement techniques like tokenizing text (turning words into features suitable for training neural networks or other machine learning algorithms).
The courses are taught by two wonderful instructors: Younes Bensouda Mourri, with whom I’ve had the pleasure of working for many years at Stanford, and Łukasz Kaiser, a member of the Google Brain team whom you might recognize as a co-author of TensorFlow.
I invite you to dive into the NLP Specialization and use the skills you gain to do amazing things.
Keep learning!
Andrew
Special Issue: NLP Ascendent

An Explosion of Words
Not long ago, language models were confined to narrow topics and foiled by shifts in context. Today, they’re advancing rapidly thanks to innovations in model architecture, training methods, and distributed computing. Neural networks are translating languages, answering questions, summarizing texts, generating articles that can be indistinguishable from those written by reporters at the New York Times, and even popping off an occasional pun. This explosion makes it more important than ever that our models track subtle shades of meaning, grasp narrative logic, and choose words that are free of bias with respect to gender and ethnicity. In this special issue of The Batch, we probe the frontiers of NLP.
AI Transformed
Noam Shazeer helped spark the latest NLP revolution. He developed the multi-headed self-attention mechanism described in “Attention Is All You Need,” the 2017 paper that introduced the transformer network. That architecture became the foundation of a new generation of models that have a much firmer grip on the vagaries of human language. Shazeer’s grandparents fled the Nazi Holocaust to the former Soviet Union, and he was born in Philadelphia in 1976 to a multi-lingual math teacher turned engineer and a full-time mom. He studied math and computer science at Duke University before joining Google in 2000. Below, he discusses the transformer and what it means for the future of deep learning.
The Batch: How did you become interested in machine learning?
Shazeer: I always liked messing around with the computer and probability was one of my favorite topics. My favorite course in grad school was a seminar where the class collaborated to write a crossword puzzle solver. We got to put together all kinds of different techniques in language processing and probabilities.
The Batch: Was that your gateway to NLP?
Shazeer: It was a great introduction to the field. They say a picture is worth 1,000 words, but it’s also 1 million times as much data. So language is 1,000 times more information dense. That means it’s a lot easier to do interesting stuff with a given amount of computation. Language modeling feels like the perfect research problem because it’s very simple to define (what’s the next word in the sequence?), there’s a huge amount of training data available, and it’s AI-complete. It’s great working at Google because it’s a language company.
The Batch: How did the idea of self-attention evolve?
Shazeer: I’d been working with LSTMs, the state-of-the-art language architecture before transformer. There were several frustrating things about them, especially computational problems. Arithmetic is cheap and moving data is expensive on today’s hardware. If you multiply an activation vector by a weight matrix, you spend 99 percent of the time reading the weight matrix from memory. You need to process a whole lot of examples simultaneously to make that worthwhile. Filling up memory with all those activations limits the size of your model and the length of the sequences you can process. Transformers can solve those problems because you process the entire sequence simultaneously. I heard a few of my colleagues in the hallway saying, “Let’s replace LSTMs with attention.” I said, “Heck yeah!”
The Batch: The transformer’s arrival was hailed as “NLP’s ImageNet moment.” Were you surprised by its impact?
Shazeer: Transformer is a better tool for understanding language. That’s very exciting, and it’s going to affect a lot of applications at Google like translation, search, and accessibility. I’ve been very pleasantly surprised by transfer learning for transformers, which really kicked off with BERT. The fact that you could spend a lot of computation and train a model once, and very cheaply use that to solve all sorts of problems.
The Batch: One outcome is an ongoing series of bigger and bigger language models. Where does this lead?
Shazeer: According to the papers OpenAI has been publishing, they haven’t seen any signs that the quality improvements plateau as they make the models bigger. So I don’t see any end in sight.
The Batch: What about the cost of training these enormous models?
Shazeer: At this point, computation costs 10-17 to 10-18 dollars per operation. GPT-3 was trained using 3×1023 operations, which would mean it cost on the order of $1 million to train. The number of operations per word is roughly double the parameter count, so that would be about 300 billion operations per word or roughly 1 millionth of a dollar per word that you analyze or produce. That doesn’t sound very expensive to me. If you buy a paperback book and read it, that costs around one ten-thousandth of a dollar per word. You can still see significant scaling up possible while finding cost-effective applications.
The Batch: Where do you find inspiration for new ideas?
Shazeer: Mostly building on old ideas. And I often find myself looking at the computational aspects of deep learning and trying to figure out if you could do something more efficiently, or something better equally efficiently. I wasted a lot of time in my first few years in deep learning on things that would never work because fundamentally they weren’t computationally efficient. A lot of the success of deep learning is because it runs many orders of magnitude faster than other techniques. That’s important to understand.
The Batch: What’s on the horizon for NLP?
Shazeer: It’s hard to predict the future. Translation of low-resource languages is one fun problem, and a very useful one to give way more people the opportunity to understand each other.
The Batch: Who is your number-one NLP hero?
Shazeer: There have been a massive number of people standing on each other’s shoulders.
The Batch: But who stands at the bottom?
Shazeer: I don’t know! From here, it looks like turtles all the way down.

Outing Hidden Hatred
Facebook uses automated systems to block hate speech, but hateful posts can slip through when seemingly benign words and pictures combine to create a nasty message. The social network is tackling this problem by enhancing AI’s ability to recognize context.
What’s new: Facebook built a hate speech detector designed to recognize that a statement like, “You are welcome here,” is benign by itself but threatening when accompanied by a picture of a graveyard. The model automatically blocks some hateful speech, but in most cases it flags content for humans to review.
Key insight: Facebook extracts separate features from various aspects of a post. Then it melds the features to represent the post as a whole.
How it works: The system examines 10 different aspects of each post including text, images, video, comments, and external context from the web. Separate models extract feature vectors from these elements, fuse them, and classify the post as benign or hate speech. The training and test data came from the company’s own Hateful Memes dataset. The researchers trained the system using a self-supervised method, hiding portions of input data and training the model to predict the missing pieces. They fine-tuned the resulting features on a labeled dataset of hateful speech.
- To extract vectors from text, the researchers used XLM-R, a pre-trained multilingual model trained on 100 languages.
- They used an object detection network to extract features from images and video. Facebook doesn’t specify the architecture in its production system, but the best baseline model on this dataset used Faster R-CNN.
- They fused vectors from various inputs using the approach known as early fusion, in which a model learns to combine features into a unified representation.
Results: A BERT model achieved 59.2 percent accuracy on a text-only subset of Hateful Memes. The best multimodal classifier released by Facebook, ViLBERT, achieved 63.2 percent accuracy.
Free money: If you think you can do better, there’s cash up for grabs in a competition for models that recognize hateful combinations of words and imagery. The contest is set to end in October.
Why it matters: The need to stop the viral spread of hatred, fear, and distrust through social media seems to grow only more urgent with the passage of time. Numerous experts have drawn a connection between online hate speech and real-world violence.
We’re thinking: What constitutes hate speech is hard for humans to agree on, never mind neural networks. There is a danger in policing speech either way. But there is greater danger in fanning flames of hostility on a global scale. Companies need strong, ethical leadership that can work with stakeholders to define limits on expressions of hatred. Then AI will be key in implementing such standards at scale. Meanwhile, we hope that blocking examples that are easiest to recognize opens room for reasoned debate about the edge cases.
Learn how to extract the sentiment from text in Course 1 of the NLP Specialization from deeplearning.ai, available now on Coursera. To master more sophisticated techniques using neural networks and transformers, stay tuned for Courses 3 and 4, coming soon to Coursera.

What Were We Talking About?
Conversational agents have a tough job following the zigs and zags of human conversation. They’re getting better at it — thanks to yesterday’s technology.
What’s new: Amazon recently improved the Alexa chatbot’s ability to identify the current topic of conversation. The system keeps its responses relevant by tracking the back and forth between itself and the user.
Key insight: In conversation, the topic can shift fluidly. The meaning of a word that’s ambiguous in a single conversational exchange, such as “it,” is often clear in light of previous conversational turns. Evaluating several exchanges makes it possible to identify the current topic more accurately.
How it works: The system recognizes 12 common topics (like politics, sports, fashion, books, and movies) and 14 intentions (like information request, opinion request, and general chat). The training data came from 100,000 conversations gathered in the 2017 Alexa Prize competition. Human annotators labeled a topic and intention for each statement.
- Each time a user or Alexa speaks, a 2017-vintage architecture known as a conditional adversarial domain network predicts the current dialog action.
- A pre-trained network extracts word vectors and passes them as a sequence to a biLSTM, a small, efficient recurrent layer that debuted in 2015.
- The biLSTM reads through what has already been said, word by word, forward and backward, to extract conversational features.
- Based on the features and dialog action, the biLSTM predicts the current topic.
Results: Amazon evaluated its topic identifier using a test dataset collected alongside the training data. The system exceeded baseline accuracy of 55 percent to achieve 74 percent accuracy when it used context from five conversational exchanges.
Why it matters: There’s plenty of life left in older techniques. Given the right data, algorithms from years ago can still do well on modern tasks.
We’re thinking: Is it too much to ask that deep learning take its place alongside sports and fashion as one of the 12 topics?
To learn about word vectors and how to use them in NLP, check out Courses 1 and 2 of the NLP Specialization from deeplearning.ai, now available on Coursera. Build powerful models using RNNs and LSTMs in the upcoming Course 3.

Choosing Words Carefully
The words “big” and “large” have similar meanings, but they aren’t always interchangeable: You wouldn’t refer to an older, male sibling as your “large brother” (unless you meant to be cheeky). Choosing among words with similar meanings is critical in language tasks like translation.
What’s new: Google used a top language model to develop BLEURT, a way to compare translation models.
Background: Machine learning engineers typically evaluate a translation model’s ability to choose the right words by translating a sentence from one language to another and back again. The metric called BLEU quantifies how far the re-translation’s meaning has drifted from that of the original sentence. But BLEU, which scores similarity on a 0-to-1 scale using an n-gram method, often misses nuances. BLEURT does a better job by training a language model to predict the semantic similarity between different sequences of words.
Key insight: BERT is a general-purpose, unsupervised language model at the heart of many state-of-the-art systems. Fine-tuned on sentences that humans judge to be similar, it should learn to agree with human notions of similarity.
How it works: BLEURT uses BERT to extract feature vectors from an original sentence and its re-translation. A linear layer predicts their similarity.
- The researchers created a dataset of millions of sentence pairs. Each pair includes a sentence from Wikipedia and a version modified by randomly deleting some words and replacing others with similar ones.
- The researchers used BLEU and other techniques to estimate the similarity between these pairs.
- They pre-trained BLEURT to predict those measures of similarity.
- Then they fine-tuned it on a smaller set of human-annotated data to predict human similarity scores.
Results: The authors drew sentences from each of several datasets and created variations on them. BLEURT and BLEU ranked the similarity between each variation and the original, and the authors compared the Kendall Tau correlation, the percentage of pairs assigned the same order minus the percentage of pairs ordered differently, with the human ranking (which is given a score of 1.0). BLEURT achieved a Kendall Tau correlation of 0.338 while BLEU achieved 0.227 — a nice bump, although it leaves plenty of room for improvement.
Why it matters: Language models have improved by leaps and bounds in recent years, but they still stumble over context. Better word choices could improve not only automatic translation but the gamut of language tasks including chat, text summarization, sentiment analysis, question answering, and text classification.
We’re thinking: BLEU stands for Bilingual Evaluation Understudy. BERT stands for Bidirectional Encoder Representations from Transformers. Does anyone know what BLEURT stands for?
Course 1 of the NLP Specialization from deeplearning.ai covers translation basics. Learn how to build a cutting-edge encoder/decoder attention model for translation in the upcoming Course 4, coming soon.
A MESSAGE FROM DEEPLEARNING.AI

We’re excited to launch our brand-new Natural Language Processing Specialization! Courses 1 and 2 are live on Coursera, with more to come. Enroll now

Gender Bender
AI learns human biases: In word vector space, “man is to computer programmer as woman is to homemaker,” as one paper put it. New research helps language models unlearn such prejudices.
What’s new: Double-Hard Debias improves on a previous algorithm to mitigate gender bias in trained language generators. Tianlu Wang developed the method with researchers at the University of Virginia and Salesforce.
Key insight: The earlier Hard Debias works by identifying a masculine-to-feminine dimension in word vectors. Words that don’t have gender-specific meanings and, in popular word embeddings, fall at either end of this axis (such as doctor and nurse) are considered biased. Hard Debias compensates by shrinking the vector’s magnitude in this dimension. However, other work shows the relative frequency of words in various contexts distorts the feature space. For instance, grandfather appears as a genderless verb in legal discussions, where it means “to exempt,” while grandmother doesn’t, and that difference deforms grandfather’s gender dimension. Removing the dimension that encodes such alternative uses should make Hard Debias more effective.
How it works: Double-Hard Debias removes this frequency-related dimension before adjusting for gender bias. (It doesn’t affect the processing of inherently gendered words identified by the researchers, such as he and she.) The researchers applied their method to several models that extract word embeddings including the popular GloVe.
- Double Hard Debias first identifies the most gender-biased words: those whose gender dimension falls farthest from the mean.
- It finds the dimensions that capture the most variability. These dimensions are most likely to distort the gender axis and therefore candidates for removal.
- It selects the candidate dimension with the most impact on gender by determining the effect of removing it on the gender-bias dimension of the words identified in the first step.
- Then it removes the selected frequency dimension from all word vectors.
- Finally, the original Hard Debias algorithm recalculates the gender dimension of the revised word vectors.
Results: The researchers applied Double-Hard Debias and Hard Debias to separate models. They trained the models on two data subsets drawn from the OntoNotes corpus of informal speech. One was made up of biased statements (say, pairing doctor with he). The other comprised anti-biased statements (for instance, pairing doctor with she). Then they asked the models who he and she referred to. The difference in the Hard Debias model’s F1 scores when tested on the biased and unbiased data was 19.7. The difference in the Double Hard Debias model’s F1 scores was 7.7, showing that gender had a far smaller impact on its performance in the task.
Why it matters: Bias in machine learning is a serious problem. A medical language model that assumes all doctors are male and all nurses female could make serious mistakes when reading medical reports. Similarly, a legal platform that equates sexual assault victim with female could lead to unjust outcomes. Solutions like this are crucial stopgaps on the way to developing less biased datasets. The model’s authors told The Batch that Double Hard Debias could be applied towards other types of bias, too.
We’re thinking: If you’re building an NLP system, often bias won’t affect metrics like relevance or BLEURT results. But it’s important to attend to it anyway, because bias can have a significant unforeseen impact on users. We need the whole AI community to work hard to reduce undesirable biases wherever possible.
Learn how to create NLP models using word vectors in Courses 1 and 2 of the NLP Specialization from deeplearning.ai. To use word vectors with deep neural networks, stay tuned for Course 3, available soon on Coursera.

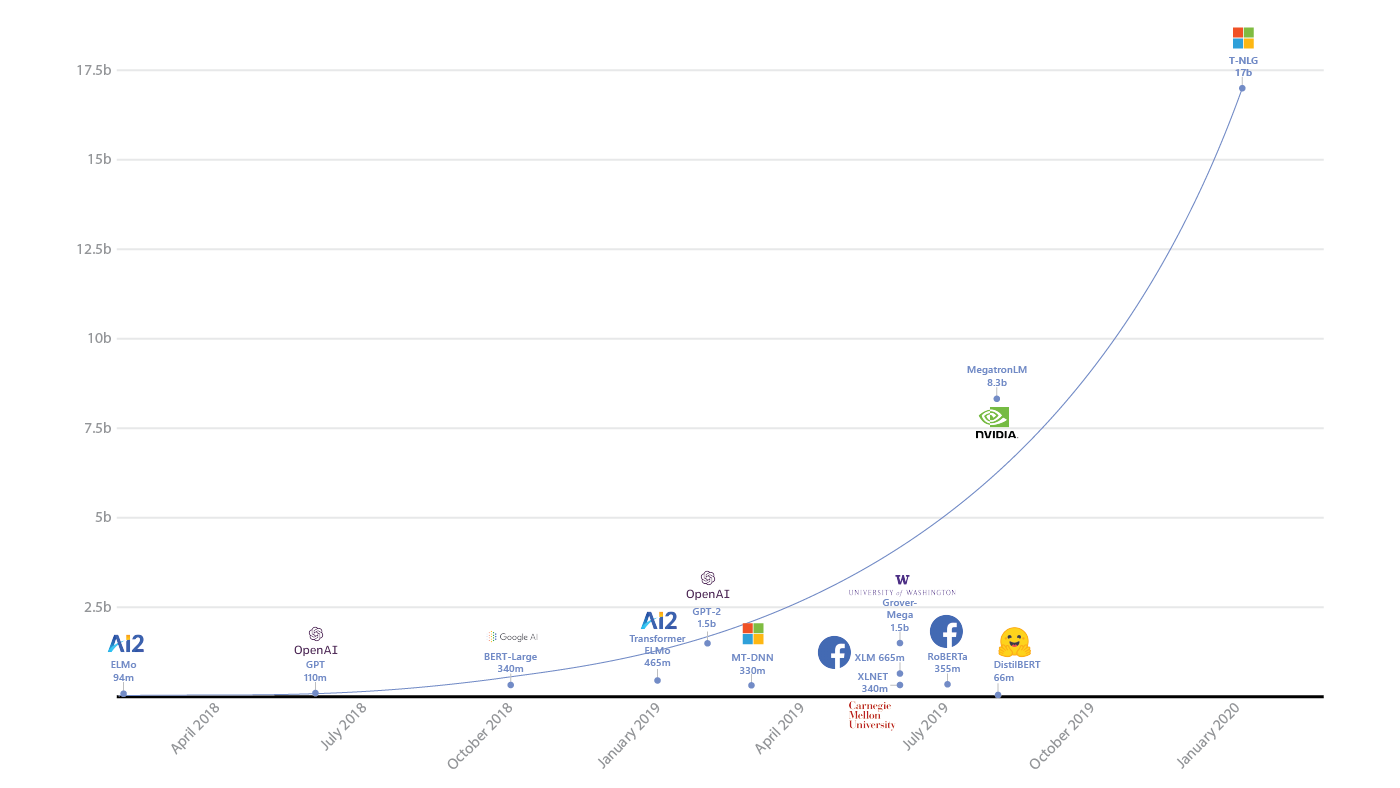
Bigger is Better
Natural language processing lately has come to resemble an arms race, as the big AI companies build models that encompass ever larger numbers of parameters. Microsoft recently held the record — but not for long.
What’s new: In February, Microsoft introduced Turing Natural Language Generation (Turing-NLG), a language model that comprises 17 billion parameters.
Key insight: More parameters is better. More training data is better. And more compute is better. For the time being, these factors determine the state of the art in language processing.
How it works: Like other recent large language models, Turing-NLG is based on the transformer architecture, which extracts features across long sequences of data without having to examine every element in between. Also like its immediate predecessors, it’s trained on unlabeled data via an unsupervised method, which enables it to absorb information from far more text than supervised models have available.
{kind=link}
- Turing-NLG draws on knowledge stored in its parameter values to answer questions such as: “How many people live in the U.S.?”. It generates responses one word at a time depending on context provided by the preceding words. For example, it would have to generate “There are 328.2 million” before deciding to generate “people.”
- The researchers fine-tuned the model on multiple text summarization datasets to generate abstractive summaries, or summaries that use novel words rather than phrases drawn from source texts. This enables it to answer questions by summarizing relevant portions of reference data.
- Like many deep learning models, Turing-NLG is far too big to train on a single GPU. Instead, such models are divided into pieces and distributed to many processors that run in parallel. That approach incurs a cost in processing efficiency, as each chip must move redundant data to and from memory, and for an architecture as big as Turing-NLG, that inefficiency can be crippling. To train their gargantuan model, the researchers used techniques developed by Nvidia for Megatron to distribute the model efficiently, and Microsoft’s own ZeRO to schedule memory resources dynamically.
Results: The researchers pitted Turing-NLG against Megatron. Turing-NLG improved state-of-the-art accuracy on the Lambada language understanding benchmark from 66.51 percent to 67.98 percent. It also improved perplexity (lower is better) on the WikiText of verified Wikipedia articles from 10.81 to 10.21.
Yes, but: The race to build bigger and better language models doesn’t leave any breathing room even for engineers at the biggest tech powerhouses. Less than four months after Microsoft announced Turing-NLG, OpenAI detailed GPT-3. At 175 billion parameters, it’s roughly 10 times bigger and achieved 76.2 percent accuracy on Lambada.
Why it matters: As language models balloon, so do scores on NLP benchmarks. Keep your seatbelts on: Microsoft says its approach to allocating hardware resources can scale past 1 trillion parameters.
We’re thinking: The recipe of adding parameters, data, and compute for better performance has a long history. That today’s language models ingest far more text than a human could read in a lifetime reveals both the power of brute-force training and the algorithms’ inefficiency at learning.
To learn how to build cutting-edge transformer models, stay tuned for Course 4 of the NLP Specialization from deeplearning.ai, coming soon.

Found in Translation
Language models can’t correct your misspellings or suggest the next word in a text without knowing what language you’re using. For instance, if you type “tac-,” are you aiming for “taco,” a hand-held meal in Spanish, or “taca,” a crown in Turkish? Apple developed a way to head off such cross-lingual confusion.
What’s new: It’s fairly easy to identify a language given a few hundred words, but only we-need-to-discuss-our-relationship texts are that long. Apple developed a way to tell, for example, Italian from Turkish based on SMS-length sequences of words.
Key insight: Methods for identifying languages in longer text passages take advantage of well studied statistical patterns among words. Detecting languages in a handful of words requires finding analogous patterns among letters.
How it works: The system comprises only a lightweight biLSTM and a softmax layer. This architecture requires half the memory of previous methods.
- A separate model narrows the possibilities by classifying the character set: Do the letters belong to Latin? Cyrillic? Hanzi? For instance, European languages and Turkish use the Latin alphabet, while Japanese and some Chinese languages use Hanzi.
- The biLSTM considers the order of input characters in both directions to squeeze out as much information as possible.
- Then it predicts the language based on the features it extracts.
Results: The system can spot languages in 50 characters as accurately as methods that require lots of text. Compared with Apple’s previous method based on an n-gram approach, the system improves average class accuracy on Latin scripts from 78.6 percent to 85.7 percent.
Why it matters: Mobile devices don’t yet have the horsepower to run a state-of-the-art multilingual language model. Until they do, they’ll need to determine which single-language model to call.
We’re thinking: Humans are sending more and more texts that look like this: ????????????. We hope NLP systems don’t go ????.
Learn how to build your own LSTM models for natural language processing in Course 3 of the NLP Specialization from deeplearning.ai, coming soon to Coursera.