
Dear friends,
I spoke on Tuesday at Coursera’s annual conference. It was the company’s most well-attended conference yet, and the first to be held online.
Higher education is in for turbulent times. With campuses shut down indefinitely and many professors teaching digitally for the first time, schools are challenged to deliver high-quality education while both students and teachers remain at home. At the same time, more people than ever — of all ages, all over the world — are more interested than ever in taking courses online.

In his keynote, Coursera CEO Jeff Maggioncalda spoke of the importance of social justice. Even as Covid-19 heightens social inequities, within this crisis lies an opportunity for educators to serve learners around the world. It’s also an opportunity to rebuild society’s trust in science, reason, and each other.
When the pandemic is over, hundreds of millions of learners around the world will have picked up the habit of learning online. The momentum could drive a new golden age of learning, and it’s not too early to start preparing. Let’s make sure we keep working to democratize access to education and make our society more fair and equitable.
Stay safe and keep learning!
Andrew
News
New Machine Learning Resources
Machine learning engineers need tools and data to help fight the Covid-19 pandemic. Here are some that crossed our radar screen last week.
- CoViz: With new research being published daily, it can be difficult to keep track of everything known about Covid-19. The Allen Institute for AI offers CoViz, an interactive network that visualizes relationships among concepts present in the COVID-19 Open Research Dataset. You can use it to explore relationships between relevant proteins, genes, cells, diseases, and chemicals to make sure you’re up to date.
- Keystone Policy Intervention Dataset: In addition to medical interventions, policy interventions like social distancing have played a key role in battling Covid-19. To help researchers evaluate them, Keystone Strategy, in association with Stanford’s Susan Athey and Harvard’s Marco Iansiti, compiled a dataset that documents non-pharmaceutical interventions implemented by various local and national governments.
- ICU Beds: One challenge of the novel coronavirus is the strain it puts on health care systems. The shortage of personal protective equipment has been well documented, and recently Kaiser Health News documented the availability of ICU beds in the U.S. The data, which records the number of ICU beds per county along with population and demographics, is available for download. The corpus could be used to explore, for instance, the sensitivity of Covid-19 fatality rate to ICU resources, or the value of policy measures such as social distancing in resource-constrained counties.
News
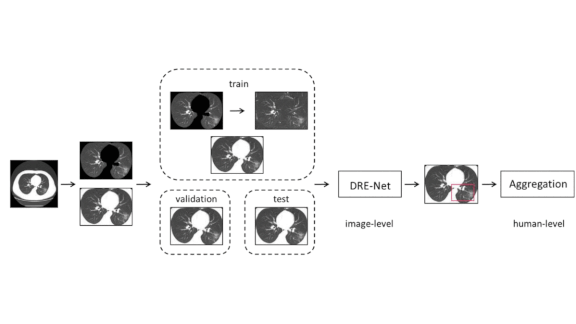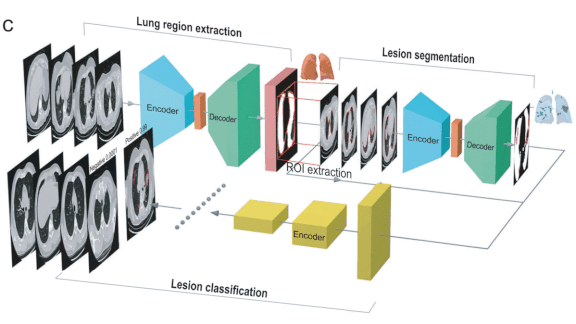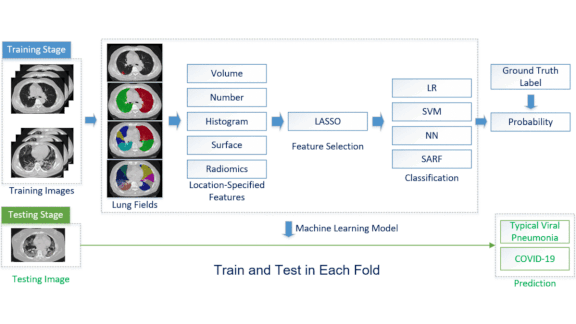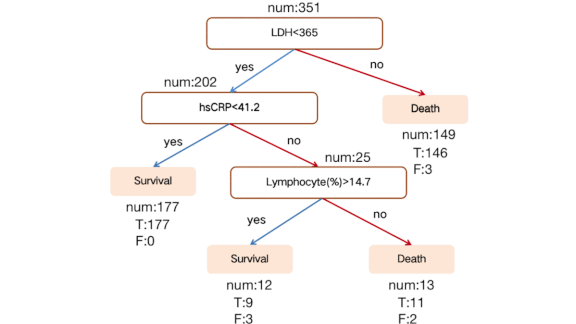
First, Make No Harmful Models
Researchers have rushed out a battery of AI-powered tools to combat the coronavirus, but an assessment of dozens of models is a wake-up call for machine learning engineers.
What’s new: Many models built to spot Covid-19 infection, predict the likelihood of hospitalization, or forecast outcomes are built on flawed science, according to a survey published in the British Medical Journal.
What they found: A group of clinicians, scientists, and engineers led by Laure Winants, an epidemiologist at Maastricht University in the Netherlands, found that biased data compromised all of the 31 models analyzed.
- Nearly a dozen models used patient data that did not represent populations of people infected by the virus.
- Most models trained to detect Covid-19 infection in CT scans were trained on poorly annotated data. Many of the researchers who built them neglected to benchmark their work against established machine learning methods.
- Many models designed to predict patient outcomes were trained only on data from patients who had died or recovered. These models didn’t learn from patients who remained symptomatic by the end of the study period, yielding prognoses that were either overly optimistic or overly dire.
Results: In a commentary that accompanied the survey, BMJ’s editors declared the models so “uniformly poor” that “none can be recommended for clinical use.”
The path forward: The authors recommend that machine learning researchers adopt the 22-point TRIPOD checklist as a standard for developing predictive medical AI. Developed by an international consortium of physicians and data scientists, the checklist is designed to help engineers report their work clearly and reduces risk of developing models with biased data.
Why it matters: Patients and health care systems alike need more accurate and faster diagnoses and prognoses. The AI community is used to publishing preliminary results to accelerate progress, but the health care community tends to wait for rigorous peer review to avoid causing harm.
We’re thinking: Given how fast the Covid-19 situation is evolving, sharing results early and often is a good thing. But the AI community also needs new mechanisms to make sure preliminary models don’t cause harm.
Preserving Detail in Image Inputs
Given real-world constraints on memory and processing time, images are often downsampled before they’re fed into a neural network. But the process removes fine details, and that degrades accuracy. A new technique squeezes images with less compromise.
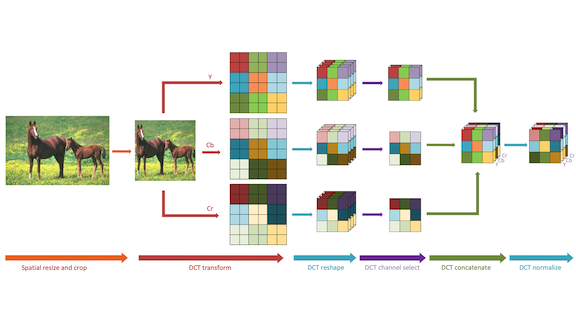
What’s new: Researchers at the Alibaba DAMO Academy and Arizona State University led by Kai Xu reduce the memory needed for image processing by using a technique inspired by JPEG image compression.
Key insight: JPEG removes information the human eye won’t miss by describing patterns of pixels as frequencies. Successive color changes from pixel to pixel are higher frequencies, while monochromatic stretches are lower frequencies. By cutting frequencies that have little visual effect, the algorithm compresses images with minimal impact on image quality. The researchers employed a similar strategy to reduce input data without losing information critical to learning.
How it works: The researchers transformed images into the frequency domain, selected frequencies to remove, and fed the reduced frequency representation into ResNet-50 and MobileNet V2 models.
- The algorithm starts by converting RGB images to YCbCr format, which specifies brightness, red, and blue in each pixel. Humans are especially sensitive to brightness, making this format good for data reduction.
- It transforms the YCbCr image into a frequency representation of the same size. Then it groups similar frequencies into channels (which longer capture brightness and color). The grouping increases the number of channels by a fixed amount but reduces height and width of the images to a neural network-friendly size.
- The researchers propose two methods to decide which frequencies to discard. In one, a separate model learns to turn each channel on or off based on how it affects classification performance. In the other, they use rules based on observation; for example, lower frequency channels tend to capture more useful information.
Results: ResNet-50 trained on ImageNet in the usual way achieves 76 percent top-1 accuracy, but slimming the input in the frequency domain increased accuracy by 1.38 percent. A MobileNet V2 trained on ImageNet and ResNet-50 feature pyramid network trained on COCO saw similar improvements.
Why it matters: Many images are much larger than the input size of most convolutional neural networks, which makes downsampling a necessary evil. Rescaling the frequency representation of images preserves relevant information, so downsampling doesn’t need to hurt performance.
We’re thinking: Smartphones capture images in 4K, but CNNs require 224×224 pixels. It’s nice to know the missing resolution isn’t going entirely to waste.
AI on the Cob
Deep learning research is harvesting better ways to manage farms.
What’s new: A convolutional neural network predicted corn yields in fields across the U.S. Midwest.
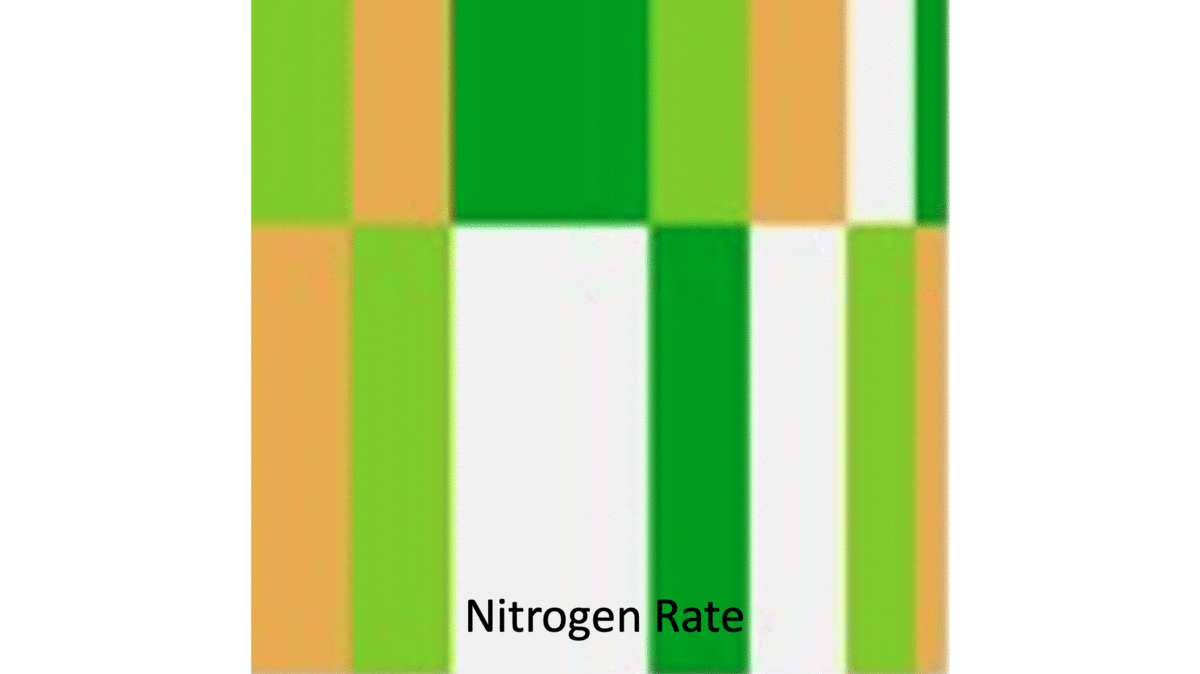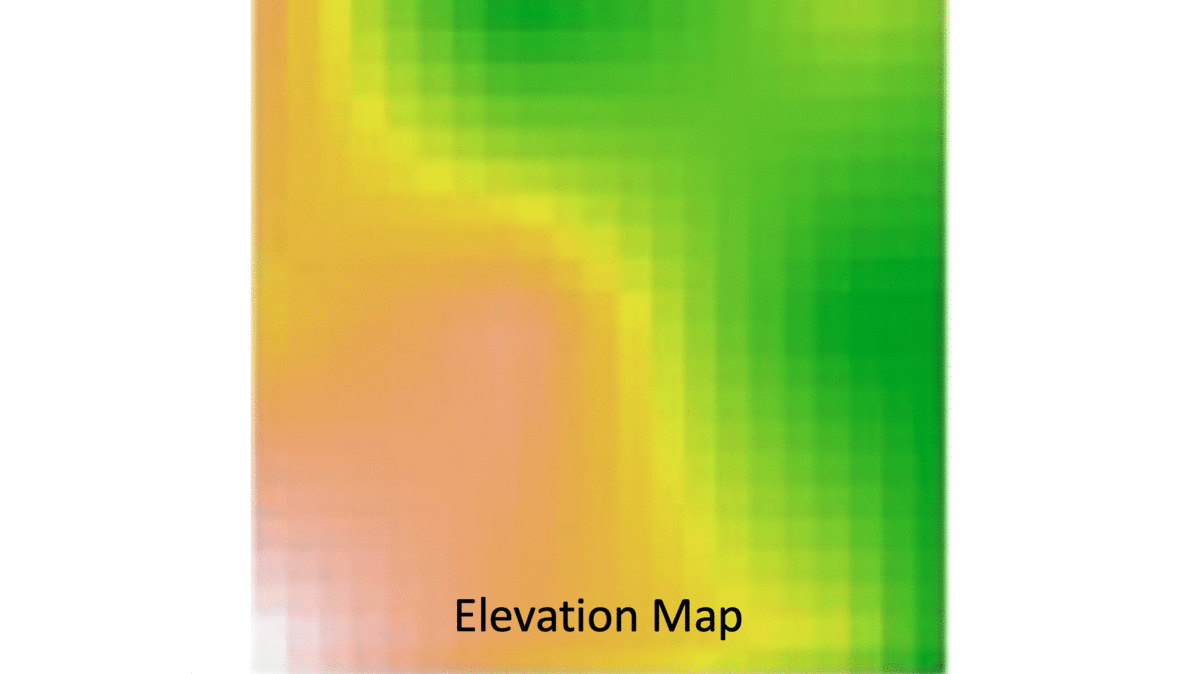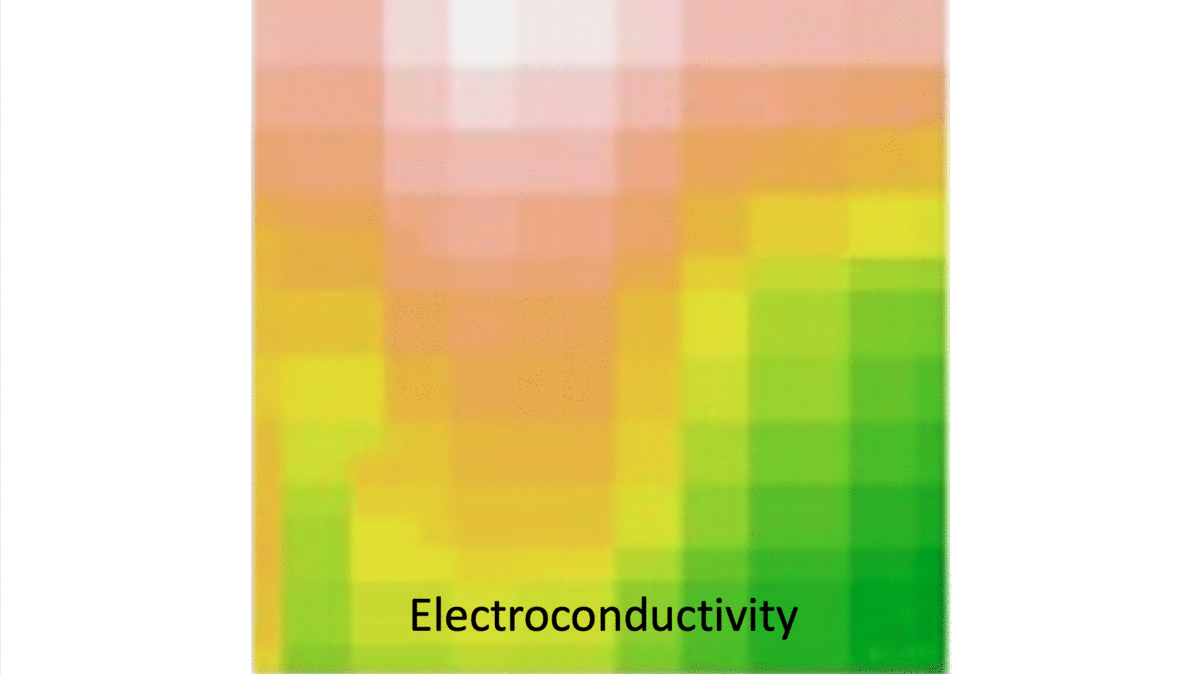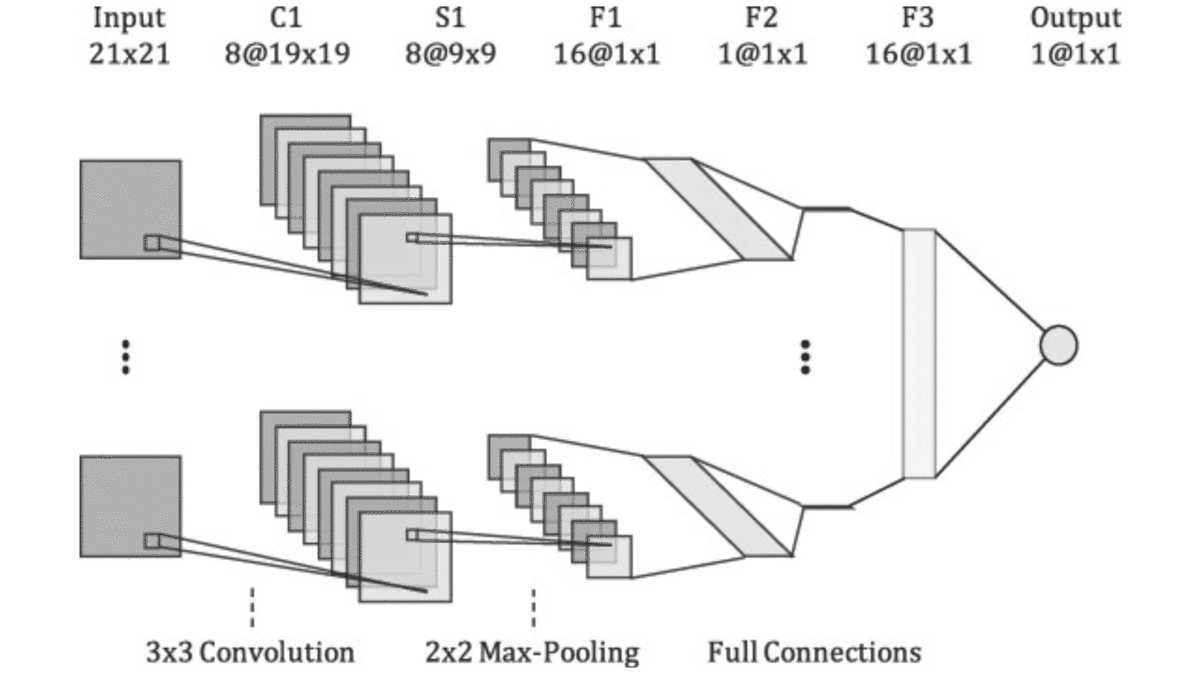
How it works: Researchers from the University of Illinois at Urbana-Champaign built a network that forecasts the quantity of corn that will grow seasonally in a given field under variable rates of seeding and nitrogen fertilization.
- The researchers chose nine experimental fields in Illinois, Ohio, Nebraska, and Kansas, with an average size of nearly 100 acres.
- Their best-performing model subdivided each field into plots 5 meters square. For each square, the researchers entered various levels of seed and fertilizer along with elevation, soil quality, and satellite imagery.
- The five inputs were fed into separate convolutional layers as raster images representing parameters of each square. These layers had access to only one parameter each and were not combined until the final fully connected layers.
- Keeping the inputs in separate layers until late in the network helped the architecture process spatial data that varied significantly over space; for instance, soil quality or elevation that differed from one square to the next.
Results: The team’s model averaged .70 root mean squared error of the mean yield standard deviation in all fields. It predicted yields more accurately than other neural networks the team built in all but one. It was also better than a set of non-neural benchmarks, outperforming a random forest model by 29 percent and a multiple linear regression model by 68 percent.
Behind the news: Agriculture requires farmers to manage numerous environmental factors and decision points, from weather patterns to hiring manual labor. Machine learning can help at every stage. Big-ag heavyweights like John Deere as well as startups like Dot and SwarmFarm offer highly automated tractors including machines that use advanced image recognition to kill individual weeds. Landing AI helped design a rig that automatically optimizes harvesting. (Disclosure: Andrew Ng is CEO of Landing AI.) Other companies specialize in evaluating produce quality, crop health, and multi-farm operations.
Why it matters: Systems like this could help farmers increase yields, save on seed costs, and reduce excess nitrogen that ends up running off into water sources. The authors are performing more trials to improve the model and working on an optimization algorithm so farmers can generate fertilizer and seed maps for their own fields.
We’re thinking: In many developing economies, younger people don’t want to make their living from farming, and small family-run farms are being consolidated into larger plots. This creates opportunities for AI and automation to make agriculture more efficient, and potentially to make food more affordable and protect the environment.
A MESSAGE FROM DEEPLEARNING.AI

How can you estimate a patient’s future health? Build your own survival model in Course 2 of the AI for Medicine Specialization. Enroll now
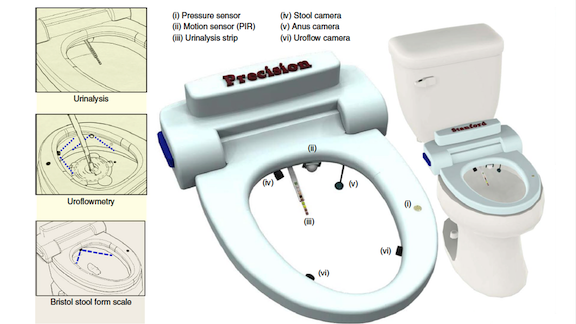
A Neural Net in Every Bathroom
It’s time to stop flushing valuable data down the toilet.
What’s new: The Precision Health Toilet, a suite of sensors that attach to an ordinary commode, monitors human waste for input for signs of disease. It identifies individual users by scanning where the sun doesn’t shine.
How it works: The system, developed by a team led by Stanford radiologist and bioengineer Seung-min Park, analyzes excreta in three ways:
- Urinalysis: When an infrared sensor detects a stream, a urinalysis testing strip extends into the line of fire. Once soaked, the strip retracts and a camera records its findings. A transmitter sends the data to the cloud for analysis. Urine flow: A computer vision model measures the rate and volume of micturition by analyzing imagery from two high-speed cameras mounted below the bowl.
- Stool quality: When a user sits down, a sensor activates an LED light to illuminate the inside of the bowl and tells a drain-facing camera to begin recording. When the user has finished, the camera sends the video to a cloud server, where a convolutional neural network sorts frames depicting stool. A second CNN categorizes the feces into one of the seven categories of the Bristol Stool Form Scale. Physicians use these categories to evaluate bowel health.
- The system identifies individual users by fingerprint via a sensor on the flush handle. It also uses a camera inside the bowl to capture their unique “analprint,” a biometric composed of a pattern of 35 or so creases.
Results: The toilet performs well in the lab, but it’s still a prototype, not yet ready to aid in clinical diagnosis or disease screening. Its inventors hope to make it into a commercial product, which would require software upgrades as well as self-cleaning mechanisms for the sensors. In an interview with The Verge, Park estimated a commercial system would probably cost between $300 and $600.
Behind the news: Japanese toilet maker Toto was first to market with an AI-powered biomedical toilet. Its Flow Sky measures urine flow by analyzing the water level in the bowl. And the European Space Agency reportedly is developing toilets capable of detecting infectious diseases.
Why it matters: Human waste contains biomarkers for diabetes, metabolic disorders, and some cancers. Urine flow is an indicator of bladder, urinary tract, and prostate health. Like a heart monitor for excretory organs, a toilet mechanism of this type could monitor risk factors for dozens of diseases.

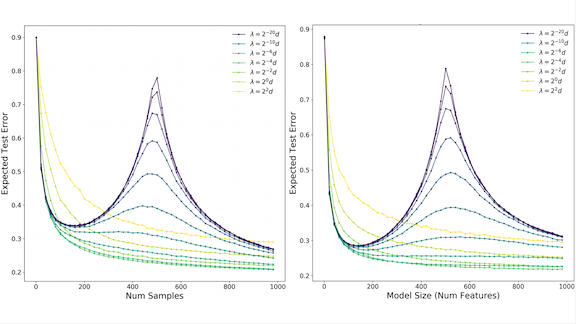
Moderating the ML Roller Coaster
Wait a minute — we added training data, and our model’s performance got worse?! New research offers a way to avoid so-called double descent.
What’s new: Double descent occurs when a model’s performance changes in unpredictable ways as the amount of training data or number of parameters crosses a certain threshold. The error falls as expected with additional data or parameters, but then rises, drops again, and may take further turns. Preetum Nakkiran and collaborators at Harvard, Stanford, and Microsoft found a way to eliminate double descent in some circumstances.
Key insight: The researchers evaluated double descent in terms of a model’s test error. Framing the problem this way led them to the conclusion that regularization — discouraging a model from having large weights — can prevent it. Where previous research described the occurrence of double descent as models or datasets grow infinitely large, the authors’ analysis applies to all sizes. This enables them to offer a practical approach to managing the problem.
How it works: The researchers proved that double descent is manageable in linear regression models if the dataset meets certain criteria. They also demonstrated experimental results for a broader class of problems.
- A model’s test error is its average mean squared error over all possible test sets. If the error increases with the size of the model or training set, the model can suffer from double descent.
- The researchers analyzed linear regression models with L1 regularization, also called ridge regression. Selecting the right penalty for a particular model or dataset size mitigates double descent if the input is Gaussian with zero mean and covariance matrix given by the identity matrix.
- In models that don’t use linear regression, such as simple convolutional neural networks, some regularization penalty values mitigated double descent. However, the researchers couldn’t find a way, other than trial and error while peeking at the test set, to choose the penalty.
Results: The researchers proved that their regularization technique prevents double descent in linear regression models if the dataset meets certain criteria. They also used linear regression models with datasets that didn’t match all of their criteria, and in every case they considered, they found a regularization penalty that did the trick.
Yes, but: Although the technique avoided double descent in a variety of circumstances, particularly in linear regression models, the authors were not able to prove that their technique works in every case.
Why it matters: This approach to mitigating double descent may look limited, since it applies only to some linear regression models. But improvements could have broad impact, given that linear regression is ubiquitous in neural network output layers.
We’re thinking: Double descent is sneaky. Researchers can miss it when they run benchmark datasets if they cherry-pick the best-performing models. And engineers can fail to detect it in applications because it isn’t predictable from results on the training set. It may be rare in practice, but we’d rather not have to worry about it.

Workers of the World, Don’t Unite
Computer vision is helping construction workers keep their social distance.
What’s new: Smartvid.io, a service that focuses on construction sites, offers a tool that recognizes when workers get too close to each other. The tool sends social distancing warnings and reports to construction superintendents.
How it works: Supervisors receive an alert when its neural nets spot workers breaking social distancing guidelines set by the U.S. Occupational Health & Safety Administration. They can also watch an annotated video feed on desktop or mobile devices and receive a daily summary of on-site social distancing metrics.
- The company added social-distance recognition to its existing computer vision platform. The new features extend the platform’s earlier ability to detect hazards such as a worker nearing the edge of an elevated platform. It also identifies risks like puddles, piles of clutter, and ladders.
- The platform recognizes contextual clues to identify the task an individual is performing and whether the worker is wearing appropriate safety gear. It can recognize hard hats, work gloves, and protective glasses. The company aims to add face masks soon.
Behind the news: AI increasingly is taking on workplace safety functions. Amazon plans to monitor social distancing in its warehouses using computer vision, according to Reuters. Landing AI, which helps traditional companies implement AI, released a similar tool last week. (Disclosure: Andrew Ng is CEO of Landing AI.)
Why it matters: In response to Covid-19, 13 U.S. states have suspended certain kinds of building projects, and three have shut down construction entirely. Technology that helps workers maintain a safe distance could help keep them working through the pandemic.
We’re thinking: These systems will need to be rolled out with deep respect for privacy rights, and the specific features that our community chooses to build or not to build will have an important impact.