
Dear friends,
In addition to creating tremendous value, AI is creating tremendous concentrations of power. Our community is wrestling with what constitutes fair use of that power.
The Markup published an article criticizing car insurance giant Allstate for price discrimination — charging different fees to different customers — based not only on their risk but also on their predicted willingness to pay. Is this behavior okay?
Digital technology enables online comparison shopping, which shifts pricing power toward consumers. But it also enables companies to create unique products for individual customers — say, a ride from point A to point B at a particular time, or a health insurance plan tailored to the customer’s personal history — and AI can help optimize prices to maximize profit for vendors. That can lead to both better products and worse price transparency.
If an online store sells the same hammer to different people for different prices, customers eventually will notice. That helps keep this form of price discrimination in check. But the temptation for sellers is still there. In 2016, Uber revealed that customers pay higher prices when their phone battery is low. (The company said it didn’t take advantage of this phenomenon.)
I wonder sometimes if I should comparison-shop more frequently than I do. Less because I’m anxious to save a few dollars on one purchase, but because I want to train vendors’ AI systems to think I’m sensitive to price and thus to offer me lower prices.
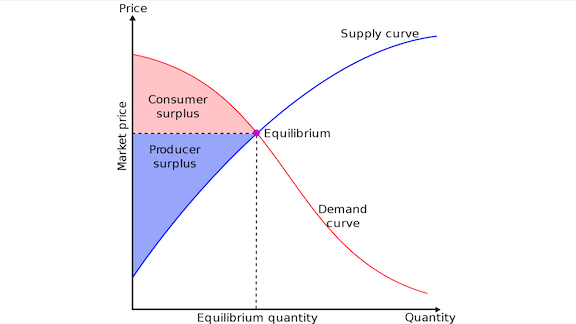
In college, my Economics 101 professor taught about supply and demand, and how our economy creates surpluses for both producers and consumers. But AI is prompting us to revisit old economic theories — along with our sense of what’s fair.
These are hard questions. I hope we can work on them together to give the world great products and services at even better prices.
Keep learning!
Andrew
DeepLearning.ai Exclusive

Breaking Into AI: A Learning Journey
After a decade in wireless communications, Cherif was ready for a change. Online courses, textbooks, and meetups helped him build his skills and land a Machine Learning Engineer role at Postmates. Learn how he overcame obstacles, aced job interviews, and started applying ML in the real world in the latest installment of our “Breaking Into AI” series. Read more
News

History in Hi Res
While deep learning is taking us into the future, it’s also opening windows into the past.
What’s new: Machine learning-savvy Redditor Denis Shiryaev brought 100-year-old silent film footage of New York City into the 21st century by automatically sharpening the picture, boosting the frame rate, and adding color.
How he did it: Shiryaev obtained eight minutes of footage shot by a Swedish film maker in 1911. He spent five days running the movie through a gauntlet of neural nets.
- Shiryaev used Enhanced Super-Resolution Generative Adversarial Networks to compute additional pixels, boosting resolution to 4K (approximately 4,000 pixels horizontally).
- He used Depth-Aware Video Frame Interpolation to generate in-between frames, raising the frame rate to 60 per second. Film shot in the early 1900s typically had much lower frame rates, making them look sped-up and jerky.
- He applied DeOldify to colorize the imagery. He noted on Reddit that he isn’t completely sold on that process, because the colors aren’t historically accurate.
- The sound effects were digital audio clips. Several commenters said they recognized horse whinnies from the video game Age of Empires II.
Behind the news: Shiryaev has used these procedures to update footage of Moscow in 1896, an iconic film from the same year that shows a French train pulling into station and Apollo 16 astronauts driving their moon buggy across the lunar surface in 1972.
Why it matters: Shiryaev’s work brings these pieces of the past to life, overcoming the poor image quality, jerky movements, and lack of colors that diminish so much historic film. Similar treatment no doubt would perk up careworn Hollywood classics as well.
We’re thinking: We can’t wait to up-res old home videos. It’s about time our parents’ 1980s hairstyles were revealed in high def.
Transformers Transformed
Transformer networks have revolutionized natural language processing, but they hog processor cycles and memory. New research demonstrates a more frugal variation.
What’s new: Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya at UC Berkeley and Google modified the transformer architecture to run faster while requiring orders of magnitude less memory during training. They call the new version Reformer.
Key insight: The transformer architecture is inherently inefficient: It tracks relationships among all input tokens, whether or not they matter to the output, and training requires a lot of memory. A few simple tweaks can rein in these excesses.
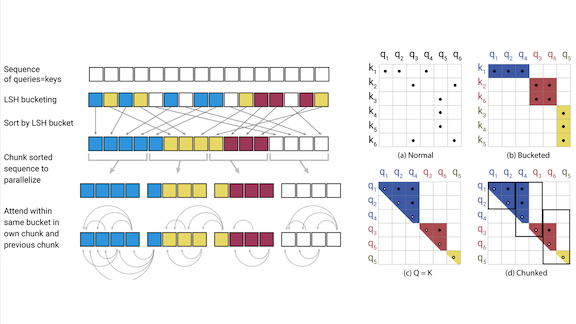
How it works: The researchers replaced the transformer’s feed-forward network with a reversible residual network. They modified the attention mechanism with locality-sensitive hashing.
- Typically, a transformer must keep all feed-forward layers in memory during training. In Reformer, each layer of the reversible residual network stores information that enables backpropagation to occur one layer at a time, rather than storing information about the entire network. That way, the network requires only enough memory to store one layer.
- A transformer’s attention mechanism encodes relationships between the current token and previous tokens, but usually only a few are important. Locality-sensitive hashing sorts the previous tokens into buckets according to similarity. Then Reformer computes attention relationships only within buckets.
Results: The authors ran experiments on Wikipedia text parceled into sequences of 64,000 tokens (more than double the number in the original transformer paper) in 16GB of memory. Reformer achieved almost the same performance as a transformer with an identical number of parameters while consuming less memory. Furthermore, the time required to compute LSH attention scaled more efficiently with increased sequence length.
Why it matters: Researchers seeking better performance are pumping up transformer-based models to immense sizes — Microsoft’s latest language model has 17 billion parameters. Running such behemoths can be out of reach for all but the largest corporate research labs. Reformer offers a more efficient alternative.
We’re thinking: Reformer’s improvements equip the transformer architecture for reading and generating long sequences — not only text, but also long-form video and audio. This capability could lead to larger-scale benchmarks to propel transformers into new tasks.

Eyes on the Assembly Line
AI may not steal your job, but it can tell the boss when you’re slacking.
What’s new: Drishti, a startup based in Palo Alto and Bengaluru, tracks the productivity of industrial workers by recognizing their actions on the assembly line. Automotive parts giant Denso is using the technology to eliminate bottlenecks in its factory in Battle Creek, Michigan, according to Wired.
How it works: Drishti trains the system to recognize standardized actions in the client’s industrial processes.
- The training data includes video of many different people from a variety of angles, so the software can classify actions regardless of who is performing them.
- Cameras watch employees as they assemble auto components. The system tracks how long it takes them to complete their tasks and alerts managers of significant deviations from the norm. Workers see a live display of their performance metrics. It shows them a smiley face if they’re ahead of schedule, a frown if they fall behind.
- The system has helped factories achieve double-digit improvements in several productivity indicators, a Denso executive told Forbes.
Behind the news: Drishti’s founders include Prasad Akella, who led General Motors’ efforts to develop collaborative robots, and computer vision expert Krishnendu Chadbury, who led teams at Google, Adobe, and Flipkart.
Why it matters: Manufacturing is a $14 trillion industry. According to research sponsored by Drishti, humans perform 72 percent of the work, and human error causes 68 percent of defects. Using AI to help people work more efficiently could yield substantial gains.
Yes, but: Workers in some industries are pushing back against automated management. Last year, dozens of employees walked out of Amazon warehouses to protest the pace of work demanded by AI-powered supervisors, which they said led to dangerous conditions.
We’re thinking: Complaining about the quality of others’ work while not doing any yourself? Computers are becoming more like humans all the time!
A MESSAGE FROM DEEPLEARNING.AI

Want to deploy a TensorFlow model in your web browser or on your smartphone? The deeplearning.ai TensorFlow: Data and Deployment Specialization will teach you how. Enroll now

Code No Evil
A prominent AI researcher has turned his back on computer vision over ethical issues.
What happened: The co-creator of the popular object-recognition network You Only Look Once (YOLO) said he no longer works on computer vision because the technology has “almost no upside and enormous downside risk.”
Why he quit: Joseph Redmon, a graduate student at the University of Washington with a charmingly unorthodox résumé, said on Twitter, “I stopped doing CV research because I saw the impact my work was having.” He didn’t respond to a request for an interview.
- “I loved the work but the military applications and privacy concerns eventually became impossible to ignore,” he said.
- Redmon disclosed his decision in a discussion sparked by a call for papers from NeurIPS requiring authors to include a statement discussing “ethical aspects and future societal consequences” of their work.
- He previously aired his concerns in a 2018 TEDx talk. He had been “horrified” to learn that the U.S. Army used his algorithms to help battlefield drones track targets, he said, urging the audience to make sure technology is used for good.
Behind the news: Redmon and his faculty advisor Ali Farhudi devised YOLO in 2016 to classify objects in real time, funded partly by Google and the U.S. Office of Naval Research. The work won a People’s Choice Award at that year’s Computer Vision and Pattern Recognition conference. The last update came in April 2018.
Why it matters: Concerns are mounting over a number of ethical concerns in machine learning including biased output, potential misuse, and adverse social impacts. The field stands to lose more talented researchers if it doesn’t come to grips with issues like this.
We’re thinking: Researchers need to recognize the ethical implications of their work and guide it toward beneficial uses. Many technologies have both civilian and military uses, and opting out may not be as powerful as helping to shape the field from within.

Locating Landmarks on the Fly
Directions such as “turn left at the big tree, go three blocks, and stop at the big red house on your left” can get you to your destination because they refer to stationary landmarks. New research enables self-driving cars to identify such stable indicators on their own.
What’s new: Dan Barnes and Ingmar Posner of Oxford University built a model that extracts landmarks on the fly from radar scans to build maps for autonomous vehicles. Radar is challenging in this application because it generates noise and ghost images, but it has the benefits of long range, high refresh rate, and robustness to environmental conditions. This video explains.
Key insight: Self-driving cars often navigate by recognizing landmarks. The researchers realized that neural networks can discover them by reversing the task: The radar signals most valuable to navigation are likely stable features of the landscape.
How it works: The system learns to identify keypoints that best predict a car’s motion. The training data specifies a vehicle’s motion from radar frame to radar frame.
- A U-Net architecture transforms each radar frame into potentially useful keypoints. It predicts vectors for each one representing its position, description, and usefulness for navigation.
- A separate algorithm compares the position of keypoints with similar descriptions in successive frames. It uses the differences in their positions to predict the car’s motion. The keypoints that are most useful in performing this task are likely to be stable.
- Using the description vector, the system can match keypoints from different perspectives. This enables it to map loops in a route, a challenging problem for earlier methods that process entire radar frames rather than keypoints.
Results: The system’s error in predicting the car’s position after driving a fixed distance was 2.06 percent, compared to the previous state of the art, 3.72 percent. Similarly, the error in the car’s predicted orientation fell from 0.0141 to 0.0067 degrees per meter driven. The new system ran an order of magnitude faster. For routes that didn’t include a loop, an earlier whole-frame approach cut the predicted position error to 1.59 percent and rotation error to 0.0044 degrees per meter.
Why it matters: The ability to generate keypoints automatically is making waves in other computer vision tasks. Combining keypoints with vector descriptions makes it possible to learn valuable things about them, from whether they indicate a loop in the route to recognizing a habitual parking space.
We’re thinking: Our surroundings are always changing: Outdoors, trees fall down and buildings go up, while indoors objects are moved all the time. Algorithms that detect landmarks on the fly will be useful for mapping and navigating such dynamic environments.
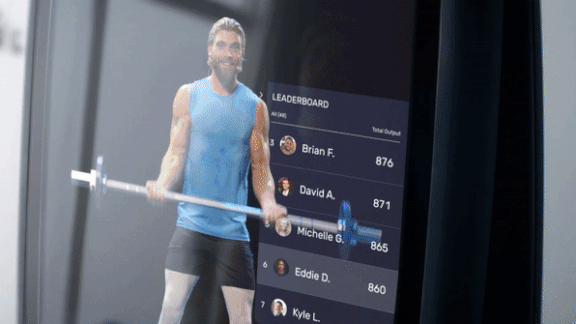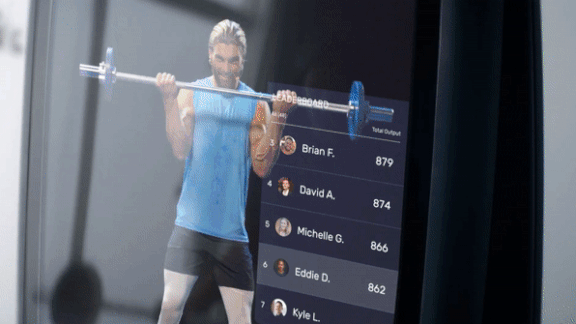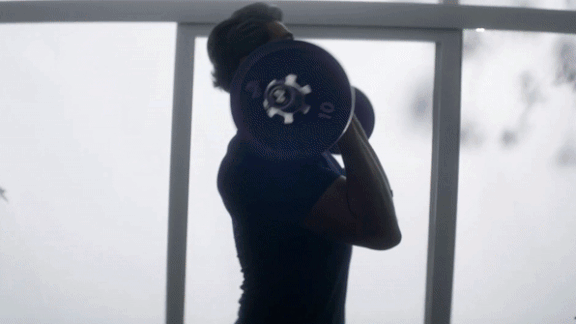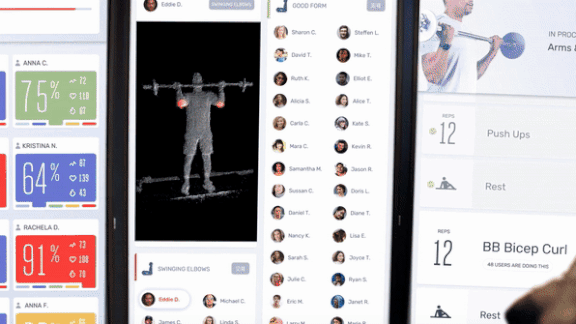
Personal TrAIner
No more sloppy workouts: AI can correct your form.
What’s new: A home exercise system uses neural nets to analyze your motions and tell you when you perform a move properly, reports The Verge.
How it works: Tempo is a six-foot-tall easel with a giant screen on the front and storage for weights on the back. The system’s motion tracking capability is built around Microsoft’s Azure Kinect. A depth-sensing camera emits infrared light and indirectly measures the time it takes for photons to zip from the camera to your body and back again, creating a continuous 3D image.
- Azure Kinect’s development kit comes with AI software that tracks body motion. Tempo didn’t respond to a question about whether it uses this model in its product.
- The model is trained to judge good and bad form across a variety of exercises. If your knees are off center during a squat, for example, the machine will tell you.
- The system also delivers live training sessions. Instructors can see your machine’s data and call you out if your form isn’t up to snuff.
Behind the news: Tempo is the first at-home exercise machine that monitors form, but it has plenty of competition in the world of Internet-connected exercise equipment. Peloton makes treadmills and exercise bikes with screens that stream live classes, while FightCamp Gym offers a connected punching bag.
Why it matters: Exercising well is exercising efficiently. Proper form can help you avoid injuries and get better results from your routine.
We’re thinking: We’re weighing the benefits of a system like this against the fact that we’d have no excuse not to go to the gym if it were in the next room.