
Dear friends,
I continue to be alarmed at the progress of proposed California regulation SB 1047 and the attack it represents on open source and more broadly on AI innovation. As I wrote previously, this proposed law makes a fundamental mistake of regulating AI technology instead of AI applications, and thus would fail to make AI meaningfully safer. I’d like to explain why the specific mechanisms of SB 1047 are so pernicious to open source.
To be clear, there are routes that regulators should pursue to improve safety. For example, I would welcome outlawing nonconsensual deepfake pornography, standardizing watermarking and fingerprinting to identify generated content, and investing more in red teaming and other safety research. Unfortunately, the proposed bill pursues a less beneficial and more harmful path.
SB 1047’s purported goal is to ensure safety of AI models. It puts in place complex reporting requirements for developers who fine-tune models or develop models that cost more than $100 million to train. It is a vague, ambiguous law that imposes significant penalties for violations, creating a huge gray zone in which developers can’t be sure how to avoid breaking the law. This will paralyze many teams.
You can read the latest draft of the law here. I’ve read through it carefully, and I find it ambiguous and very hard to follow.
Developers who try to navigate the law’s complex requirements face what feels like a huge personal risk. It requires that developers submit a certification of compliance with the requirements of the law. But when the requirements are complex, hard to understand, and can even shift according to the whims of an unelected body (more on this below), how do we ensure we are in compliance?
For example, the certification must include many different sections. One is an analysis of “the nature and magnitude of critical harms … the model might reasonably cause or enable.” But given that even leading AI researchers aren’t sure what harms models might cause or enable, how is a team of developers supposed to figure this out and declare — under penalty of perjury — that they meet this requirement?
Further, some developers will be required to implement “protections to prevent … misuse of, or unsafe post-training modifications of, the covered model and all covered model derivatives … that are appropriate in light of the risks associated with the covered model, including from advanced persistent threats or other sophisticated actors.” Even leading AI researchers don’t agree on how best to “protect” AI models against these supposed risks, or what would be “appropriate.” So how are developers supposed to figure out how to comply with this requirement?

This creates a scary situation for developers. Committing perjury could lead to fines and even jail time. Some developers will have to hire expensive lawyers or consultants to advise them on how to comply with these requirements. (I am not a lawyer and am not giving legal advice, but one way to try to avoid perjury is to show that you are relying on expert advice, to demonstrate that you had no intent to lie.) Others will simply refrain from releasing cutting-edge AI products.
If this law passes, the fear of a trial by a jury — leading to a verdict that can be very unpredictable with significant penalties in the event of a conviction — will be very real. What if someone releases a model today after taking what they genuinely felt were reasonable safeguards, but a few years later, when views on AI technology might have shifted, some aggressive prosecutor manages to convince a jury that whatever they did was not, in hindsight, “reasonable”? Reasonableness is ambiguous and its legal interpretation can depend on case law, jury instructions, and common facts, among other things. This makes it very hard to ensure that what a developer does today will be deemed reasonable by a future jury. (For more on this, see Context Fund’s analysis of SB 1047.)
One highly placed lawyer in the California government who studied this law carefully told me they found it hard to understand. I invite you to read it and judge for yourself — if you find the requirements clear, you might have a brilliant future as a lawyer!
Adding to the ambiguity, the bill would create a Frontier Model Division (FMD) with a five-person board that has the power to dictate standards to developers. This small board would be a great target for lobbying and regulatory capture. (Bill Gurley has a great video on regulatory capture.) The unelected FMD can levy fees on developers to cover its costs. It can arbitrarily change the computation threshold at which fine-tuning a model becomes subject to its oversight. This can lead to even small teams being required to hire an auditor to check for compliance with an ambiguous safety standard.
These provisions don’t ensure that AI is safe. They create regulatory uncertainty, and more opportunities for vested interests wishing to stifle open-source to lobby for shifts in the requirements that raise the cost of compliance. This would lock out many teams that don’t have a revenue stream — specifically, many open-source contributors — that would let them pay for lobbyists, auditors, and lawyers to help ensure they comply with these ambiguous and unreasonable requirements.
Open source is a wonderful force that is bringing knowledge and tools to many people, and is a key pillar of AI innovation. I am dismayed at the concerted attacks on it. Make no mistake, there is a fight in California right now for the future health of open source. I am committed to doing what I can to preserve open source, but I don’t assume that the pro-open source side will prevail. I hope you will join me in speaking out against SB 1047 and other laws that threaten to stifle open source.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In our new course “Prompt Compression and Query Optimization,” you’ll learn how to use MongoDB’s features to build efficient retrieval augmented generation (RAG) systems and address challenges to scaling, performance, and security. Enroll for free
News
Claude Advances the LLM Interface
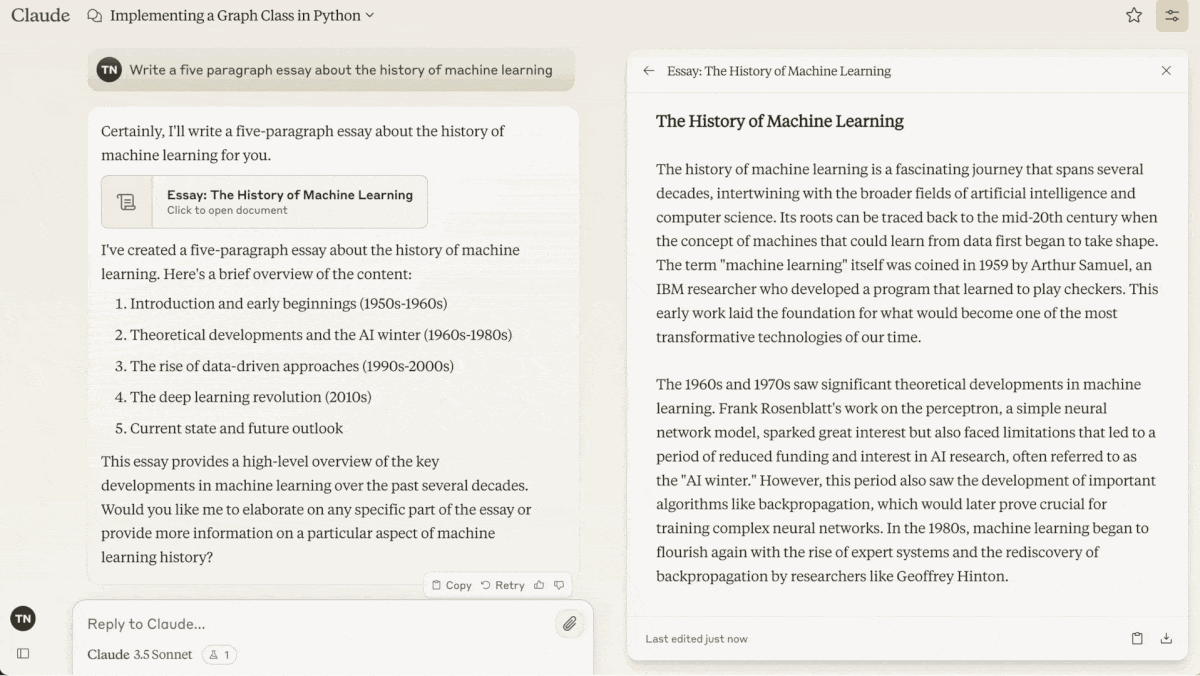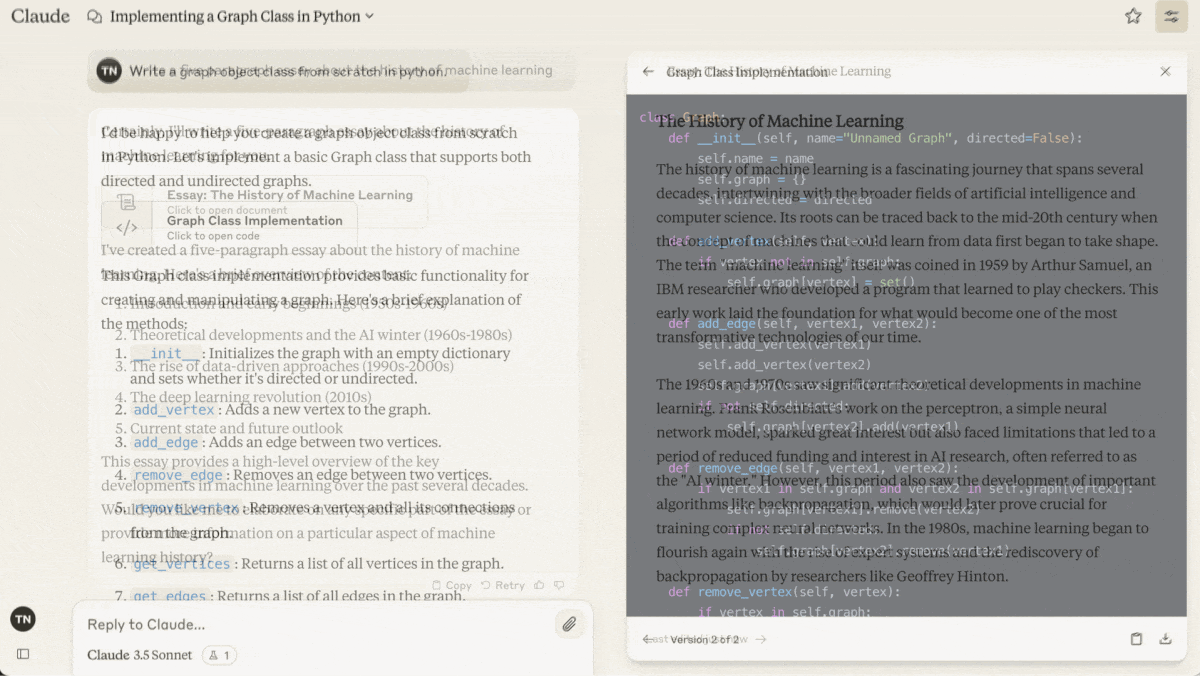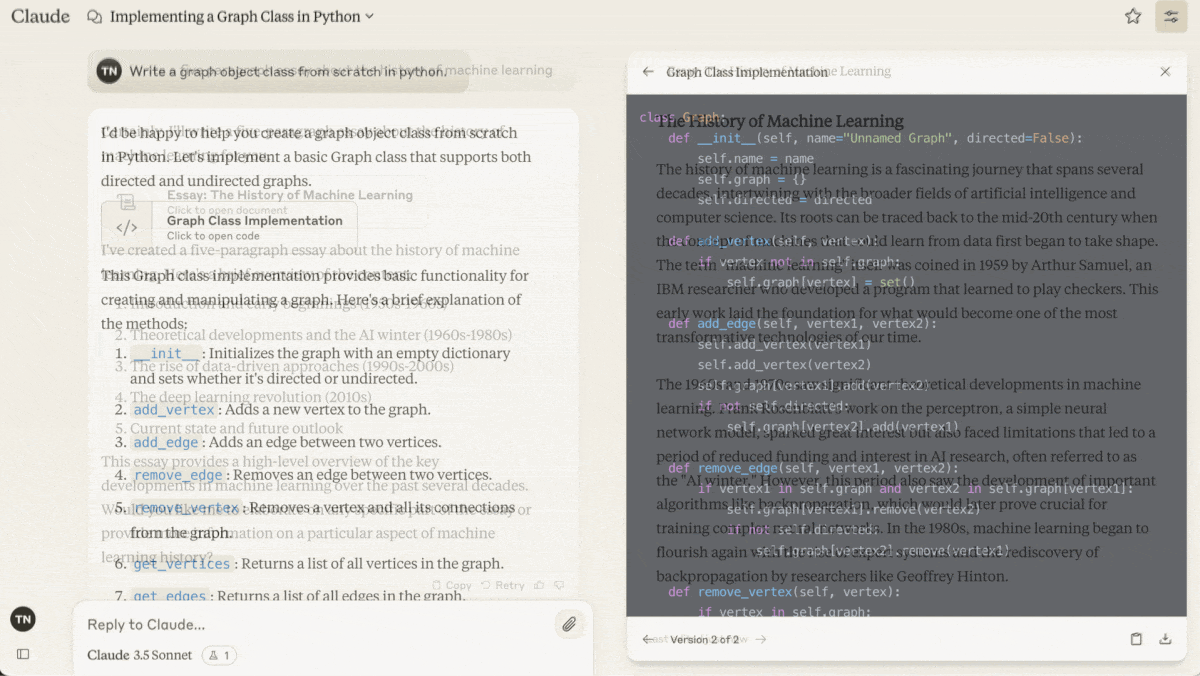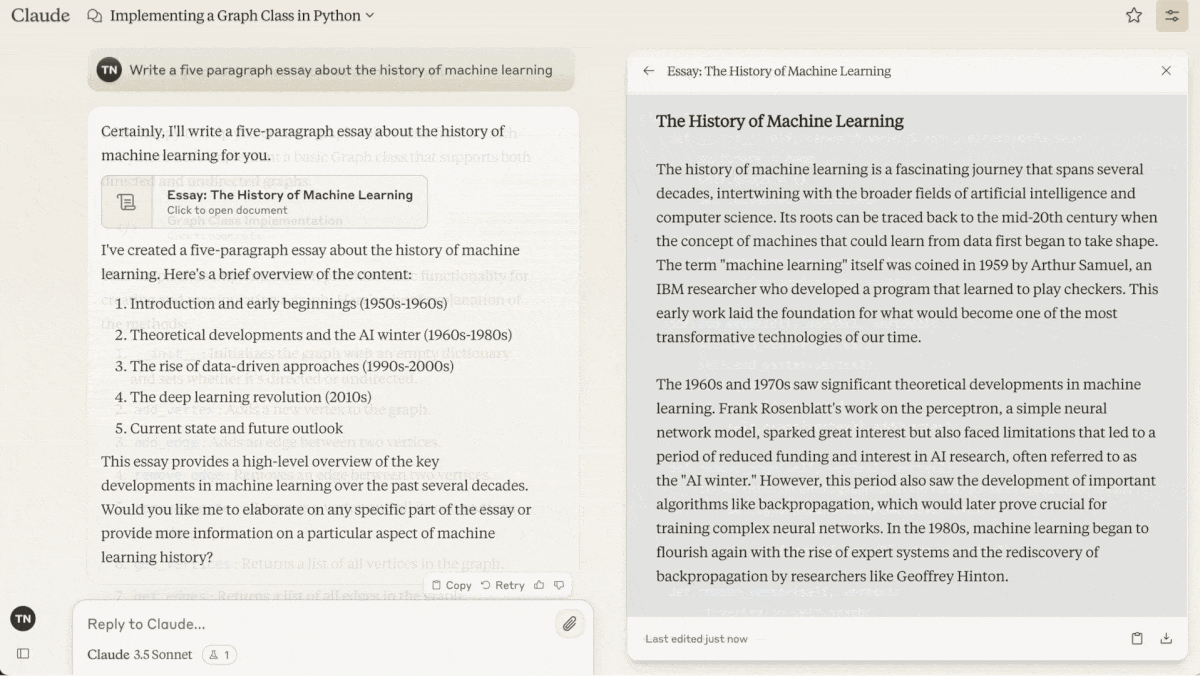
Claude 3.5 Sonnet lets users work on generated outputs as though they were independent files — a step forward in large language model user interfaces.
What’s new: Anthropic introduced Artifacts, a feature that displays outputs in a separate window of Claude 1.5 Sonnet’s web interface, outside the stream of conversation that creates and modifies them. Artifacts can include documents, code snippets, HTML pages, vector graphics, or visualizations built using JavaScript.
How it works: Users can enable artifacts from the “feature preview” dropdown in their profile menu at Claude.ai. Then, asked to generate an output that’s likely to act as standalone content and undergo further work, Claude opens an artifact window next to the chat frame, populates it with an initial output, and further updates it according to subsequent prompts.
- Text or code artifacts are typically at least 15 lines long. Visual artifacts created using a programming language or markup can be viewed selectively as code or a rendered display. Users can interact with multiple artifacts (or multiple versions of the same artifact) and switch between them.
- For instance, asking Claude to “create an 8-bit crab” creates an artifact that shows a downloadable vector image of a crab. Ryan Morrison of Tom’s Guide used artifacts to create pixel art, a simple 2D game, and a tool that builds a family tree one relative at a time.
- Developer and designer Meng To showed a tool built with help from Artifacts that enables users to customize a diagram of a vector field in real time by adjusting sliders and menu options.
- Pliny the Prompter, who regularly shares jailbreaks on X, found what appears to be a part of Claude’s internal instructions concerning artifacts. The instructions suggest that Claude avoids rendering an artifact if a chat response will do, avoids creating new artifacts in favor of updating existing ones, renders one artifact per text unless requested otherwise, and deliberates silently about whether to create an artifact by generating text between specific XML tags that hide it from the user. (Artifacts themselves are enclosed in a different set of tags.)
Why it matters: Artifacts make working with a large language model more fluidly interactive. Large language models (LLMs) have long been able to generate code but, outside of AI-assisted development environments like GitHub with Copilot, executing generated code typically requires further steps such as copy-pasting the code into a development environment. The additional steps add friction for developers and confusion for non-developers. Keeping and running the code in a separate window makes for a convenient, low-friction experience. Likewise when generating images and other kinds of visual output.
We’re thinking: It’s rare when a user interface update makes a tool more useful for casual and hardcore users alike. It’s even more exciting to see it happen to an LLM!
AI’s Path to Zero Emissions Is Cloudy
The boom in AI is jeopardizing big tech’s efforts to reach its targets for emissions of greenhouse gasses.
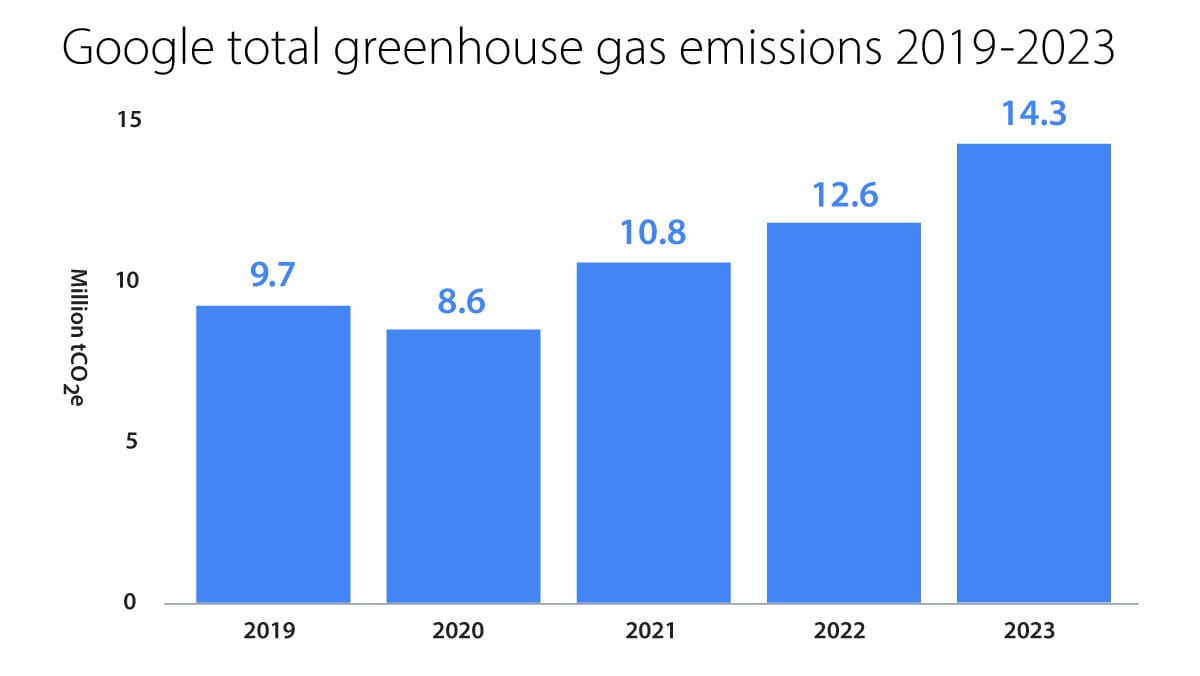
What’s new: Google’s annual environmental report shows that the company’s total carbon dioxide emissions rose nearly 50 percent between 2019 and 2023 to 14.3 million tons. Google attributes the rise to its efforts to satisfy rising demand for AI.
How it works: Google’s carbon emissions increased 16.7 percent from 2021 to 2022 and another 13.5 percent from 2022 to 2023 for a total 48 percent rise over those periods. “As we further integrate AI into our products, reducing emissions may be challenging due to increasing energy demands from the greater intensity of AI compute, and the emissions associated with the expected increases in our technical infrastructure investment,” the report states.
- Three-quarters of total emissions, or 10.8 million tons, are associated with purchases that include the data-center hardware and construction. These emissions increased 23 percent from 2019 to 2023 and 8 percent year-over-year.
- Powering, heating, and cooling data centers and other facilities accounted for around a quarter of Google’s 2023 emissions. Emissions from these activities have increased more than four-fold since 2019.
- Low-emissions energy has reduced Google’s total data-center emissions substantially, but some regions don’t have enough of it to meet demand. Solar, wind, hydro, geothermal, and nuclear energy account for most of the energy consumed by Google’s data centers in Europe, Canada, and South America. However, these sources account for less than 5 percent in Singapore, Qatar, and Saudi Arabia.
Countering the trend: Google is working to reduce its greenhouse gas emissions on several fronts. Its effort to purchase electricity from low-emissions sources cut its net carbon footprint by around 30 percent in 2023. It claims that its owned-and-operated data centers are 1.8 times more energy-efficient than a typical enterprise data center, and its sixth-generation tensor processing units (TPUs) are 67 percent more efficient than the prior generation. Google has asked its largest hardware partners to match 100 percent of their energy consumption with renewable energy 2029. The company is pursuing several AI-based initiatives to mitigate climate change from weather prediction to fuel-efficient vehicle routing. It says that AI has the potential to mitigate 5 to 10 percent of global greenhouse gas emissions by 2030.
Behind the news: In 2020, after five years of successfully reducing its carbon footprint, Google set an ambitious target to reach net-zero greenhouse gas emissions by 2030. But its total emissions since then have risen each year. Google’s experience mirrors that of Amazon and Microsoft, which aim to reach net-zero carbon emissions by 2030 and 2040 respectively. Amazon’s emissions increased 39 percent from 2019 to 2022, while Microsoft’s emissions rose 29 percent between 2020 and 2023. (Amazon’s and Microsoft’s cloud computing revenues were roughly triple Google’s in 2023 and thus their AI-related greenhouse case emissions presumably were larger.)
Why it matters: Growing use of AI means greater consumption of energy. The tech giants’ ambitious emissions goals predate the rapid growth of generative AI, and their latest reports show that it’s time to rethink them. This adds urgency to already critical efforts to develop renewable and other low-emissions energy sources.
We’re thinking: We applaud Google’s efforts to cut its carbon emissions and its transparency in issuing annual environmental reports. We’re somewhat relieved to note that, for now, data centers and cloud computing are responsible for 1 percent of the world’s energy-related greenhouse gas emissions; a drop in the bucket compared to transportation, construction, or agriculture. Moreover, we believe that AI stands to create huge benefits relative to the climate impact of its emissions, and AI is one of the most powerful tools we have to develop low-carbon energy sources and boost energy efficiency throughout society. Continuing to improve the technology will help us develop lower-carbon energy sources and efficient ways to harness them.

Amazon Onboards Adept
Amazon hired most of the staff of agentic-AI specialist Adept AI in a move that echoes Microsoft’s absorption of Inflection in March.
What’s new: Amazon onboarded most of the leadership and staff of Adept AI, which has been training models to operate software applications running on local hardware, GeekWire reported. Amazon licensed Adept’s models, datasets, and other technology non-exclusively. The companies did not disclose the financial terms of the deal. (Disclosure: Andrew Ng serves on Amazon’s board of directors.)
How it works: Amazon hired two thirds of Adept’s former employees. Those who remain will “focus entirely on solutions that enable agentic AI” based on proprietary models, custom infrastructure, and other technology.
- Amazon hired Adept CEO David Luan and four of his fellow co-founders, all Google or Open AI alumni. They joined Amazon’s artificial general intelligence (AGI) autonomy team, which reports to Amazon head scientist for AGI Rohit Pradad. The autonomy team will build agents that can automate software workflows.
- Adept built agents that control applications on a user’s desktop in response to natural-language commands based on proprietary language and vision-language models. For example, a recruiter could use Adept’s technology to find promising job candidates on LinkedIn and import their profiles into a Salesforce database.
- The startup found that the high cost of building foundation models was unsustainable without further fundraising. Although Adept had planned to release a full-fledged agentic tool this year, it also explored an outright sale to several companies including Meta.
- As of March 2023, Adept had raised a total of $415 million at a valuation of more than $1 billion.
Behind the news: Amazon’s agreement with Adept is one of several moves to compete in AI for both businesses and consumers. In March, the company completed a $4 billion investment in Anthropic in exchange for a minority share in the startup. It’s reportedly developing new models and overhauling its longstanding Alexa voice assistant.
Why it matters: Luan and his team say they’re aiming to automate corporate software workflows, a potentially valuable and lucrative market. Although Amazon Web Services’ Bedrock platform already enables users to build AI agents, Adept’s talent may bring expanded agentic and interactive capabilities.
We’re thinking: AI agentic capabilities are blossoming, and Adept’s work is a notable example.
Like LoRA, But for Pretraining
Low-rank adaptation (LoRA) reduces memory requirements when fine-tuning large language models, but it isn’t as conducive to pretraining. Researchers devised a method that achieves similar memory savings but works well for both fine-tuning and pretraining.
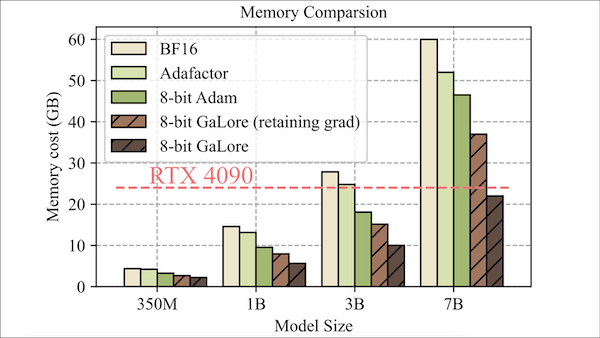
What’s new: Jiawei Zhao and colleagues at California Institute of Technology, Meta, University of Texas at Austin, and Carnegie Mellon proposed Gradient Low-Rank Projection (GaLore), an optimizer modification that saves memory during training by reducing the sizes of optimizer states. They used this approach to pretrain a 7B parameter transformer using a consumer-grade Nvidia RTX 4090 GPU.
Key insight: LoRA saves memory during training by learning to approximate a change in the weight matrix of each layer in a neural network using the product of two smaller matrices. This approximation results in good performance when fine-tuning (though not quite as good as fine-tuning all weights) but worse performance when pretraining from a random initialization. The authors proved theoretically that updating weights according to an approximate gradient matrix — which reduces the memory required to store optimizer states — can yield the same performance as using the exact gradient matrix (at least for deep neural networks with ReLU activation functions and classification loss functions). Updating weights only once using an approximate gradient matrix is insufficient. However, updating weights repeatedly using gradient approximations that change with each training step (because the inputs change between training steps) achieves an effect similar to training weights in the usual way.
How it works: GaLore approximates a network’s gradient matrix divided into layer-wise matrices. Given a layer’s gradient matrix G (size m x n), GaLore computes a smaller matrix P (size r x m). It uses PG, a smaller approximation of the gradient matrix (size r x n), to update optimizer states. To further save memory, it updates layers one at a time instead of all at once, following LOMO.
- At each training step, for each layer, GaLore computed the layer-wise gradient matrix normally.
- GaLore computed a smaller matrix P that, when multiplied by the gradient matrix, yielded a smaller matrix that approximated the weight update. GaLore computed P every 200 training steps (that is, it used the same P for 200 training steps at a time before computing a new P).
- GaLore multiplied P by the gradient matrix to compute a smaller, approximate version of the gradient matrix. It used this smaller version to update the Adam optimizer’s internal states, requiring less memory to store the optimizer’s internal states. Then the optimizer used its internal states to update the smaller matrix.
- GaLore multiplied P by the smaller matrix to produce a full-sized approximation of the gradient matrix. It used the full-sized approximation to update the current layer’s weights.
Results: The authors tested GaLore in both pretraining and fine-tuning scenarios.
- The authors compared GaLore to Adam while pretraining five transformer architectures from 60 million to 7 billion parameters to generate the next token in web text. GaLore (set up to represent its internal states using 8-bit numbers) pretrained LLaMA 7B from scratch using 22GB of memory, while Adam (modified to represent its internal states using 8-bit numbers) needed 46GB of memory. After training on 19.7 billion tokens, LLaMA 7B achieved 14.65 perplexity, while Adam achieved 14.61 perplexity (a measure of how well a model reproduces validation examples, lower is better).
- They also used GaLore to fine-tune RoBERTaBase on the multi-task benchmark GLUE. GaLore needed 253MB of memory and achieved a score of 85.89 (averaging eight of 11 GLUE tasks), while LoRA needed 257MB of memory and reached 85.61.
Why it matters: LoRA’s ability to fine-tune large models using far less memory makes it a very popular fine-tuning method. GaLore is a theoretically motivated approach to memory-efficient training that’s good for both pretraining and fine-tuning.
We're thinking: LoRA-style approximation has been unlocking data- and memory-efficient approaches in a variety of machine learning situations — an exciting trend as models grow and demand for compute resources intensifies.