
Dear friends,
Much has been said about many companies’ desire for more compute (as well as data) to train larger foundation models. I think it’s under-appreciated that we have nowhere near enough compute available for inference on foundation models as well.
Years ago, when I was leading teams at Google, Baidu, and Stanford that focused on scaling up deep learning algorithms, many semiconductor manufacturers, data center operators, and academic researchers asked me whether I felt that AI technology would continue to make good use of more compute if they kept on delivering it. For many normal desktop processing workloads, like running a web browser or a text editor, having a faster CPU doesn’t help that much beyond a certain point. So do we really need faster and faster AI processors to train larger and larger models? Each time, I confidently replied “yes!” and encouraged them to keep scaling up compute. (Sometimes, I added half-jokingly that I had never met a machine learning engineer who felt like they had enough compute. 😀)
Fortunately, this prediction has been right so far. However, beyond training, I believe we are also far from exhausting the benefits of faster and higher volumes of inference.
Today, a lot of LLM output is primarily for human consumption. A human might read around 250 words per minute, which is around 6 tokens per second (250 words/min / (0.75 words/token) / (60 secs/min)). So it might initially seem like there’s little value to generating tokens much faster than this.
But in an agentic workflow, an LLM might be prompted repeatedly to reflect on and improve its output, use tools, plan and execute sequences of steps, or implement multiple agents that collaborate with each other. In such settings, we might easily generate hundreds of thousands of tokens or more before showing any output to a user. This makes fast token generation very desirable and makes slower generation a bottleneck to taking better advantage of existing foundation models.
That’s why I’m excited about the work of companies like Groq, which can generate hundreds of tokens per second. Recently, SambaNova published an impressive demo that hit hundreds of tokens per second.
Incidentally, faster, cheaper token generation will also help make running evaluations (evals), a step that can be slow and expensive today since it typically involves iterating over many examples, more palatable. Having better evals will help many developers with the process of tuning models to improve their performance.
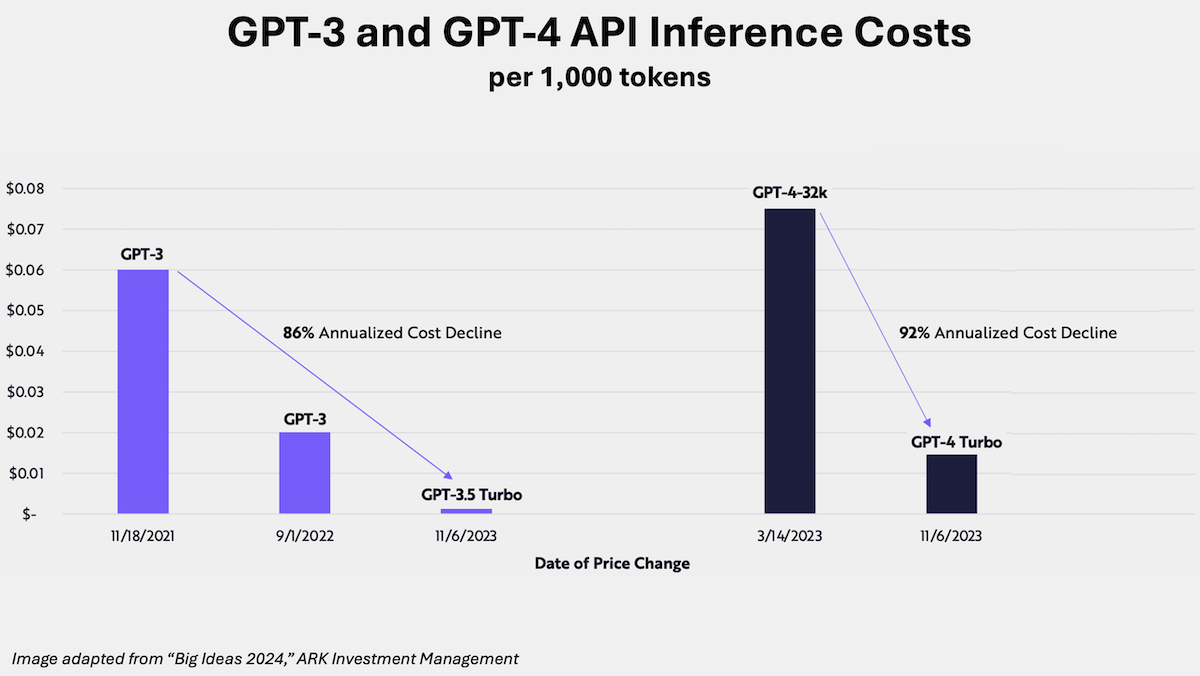
Fortunately, it appears that both training and inference are rapidly becoming cheaper. I recently spoke with Cathie Wood and Charles Roberts of the investment firm ARK, which is famous for its bullish predictions on tech. They estimate that AI training costs are falling at 75% a year. If they are right, a foundation model that costs $100M to train this year might cost only $25M to train next year. Further, they report that for “enterprise scale use cases, inference costs seem to be falling at an annual rate of ~86%, even faster than training costs.”
I don’t know how accurate these specific predictions will turn out to be, but with improvements in both semiconductors and algorithms, I do see training and inference costs falling rapidly. This will be good for application builders and help AI agentic workflows lift off.
Keep learning!
Andrew
P.S. New short course with Mistral AI! Mistral’s open-source Mixtral 8x7B model uses a mixture of experts (MoE) architecture. Unlike a standard transformer, MoE uses multiple expert feed-forward networks with a gating network that selects a number of experts at inference time. This enables MoE to match the performance of larger models but with faster inference. Mixtral 8x7B has 46.7B parameters but activates only 12.9B at inference time to predict the next token. In “Getting Started with Mistral,” taught by Sophia Yang, you’ll explore Mistral’s open-source (Mistral 7B, Mixtral 8x7B) and commercial models, learn about function calling for tool use with Mistral, and build a Mistral-powered chat interface that can reference external documents. Please sign up here!
News
Songs Made to Order
A new breed of audio generator produces synthetic performances of songs in a variety of popular styles.
What’s new: Udio launched a web-based, text-to-song generator that creates songs in styles from barbershop to heavy metal. Suno, which debuted its service late last year with similar capabilities, upgraded to its offering.
How it works: Both services take text prompts and generate full-band productions complete with lyrics, vocals, and instrumental solos, two separate generations per prompt. Users can generate lyrics to order or upload their own words, and they can download, share, and/or post the results for others to hear. Leaderboards rank outputs according to plays and likes.
- Founded by alumni of Google’s DeepMind division, Udio lets registered users generate up to 1,200 songs monthly for free and expects to offer paid services at an unspecified future date. Users enter a text prompt and/or choose style tags. The system automatically replaces artist names with stylistic descriptions but sometimes produces results that sound uncannily like the artists requested. Users can choose to generate an instrumental track or add lyrics, allocating them to verse, chorus, or background vocals. Udio generates audio segments 33 seconds long, which users can extend, remix, and modify. The company has not released information about the underlying technology.
- Suno lets users generate 10 songs daily for free or pay to generate more. Enter a prompt, and the system generates complete songs up to 2 minutes long; alternatively, users can specify lyrics, style, and title in separate prompts. The system refuses to generate music from prompts that include the name of a real-world artist. Suno hasn’t disclosed technical information, but last year it released an open-source model called Bark that turns a text prompt into synthetic music, speech, and/or sound effects.
Behind the news: Most earlier text-to-music generators were designed to produce relatively free-form instrumental compositions rather than songs with structured verses, choruses, and vocals. Released earlier this month, Stable Audio 2 generates instrumental tracks up to three minutes long that have distinct beginnings, middles, and endings. Users can also upload audio tracks and use Stable Audio 2.0 to modify them.
Yes, but: Like text-to-image generators circa last year, current text-to-music models offer little ability to steer their output. They don’t respond consistently to basic musical terminology such as “tempo” and “harmony,” and requesting a generic style like “pop” can summon a variety of subgenres from the last 50 years of popular music.
Why it matters: With the advent of text-to-music models that produce credible songs, audio generation seems primed for a Midjourney moment, when the public realizes that it can produce customized music at the drop of a prompt. Already Udio’s and Suno’s websites are full of whimsical paeans to users’ pets and hobbies. The technology has clear implications for professional performers and producers, who, regrettably, have little choice but to adapt to increasing automation. But for now fans have fun, new toys to play with.
We’re thinking: You can dance to these algo-rhythms!

Benchmarks for Industry
How well do large language models respond to professional-level queries in various industry domains? A new company aims to find out.
What’s new: Vals.AI, an independent model testing service, developed benchmarks that rank large language models’ performance of tasks associated with income taxes, corporate finance, and contract law; it also maintains a pre-existing legal benchmark. Open AI’s GPT-4 and Anthropic’s Claude 3 Opus did especially well in recent tests.
How it works: Vals AI hosts leaderboards that compare the performance of several popular large language models (LLMs) with respect to accuracy, cost, and speed, along with with analysis of the results. The company worked with independent experts to develop multiple-choice and open-ended questions in industrial domains. The datasets are not publicly available.
- ContractLaw includes questions related to contracts. They ask models to retrieve parts of contracts that are relevant to particular terms, edit excerpts, and determine whether excerpts meet legal standards.
- CorpFin tests accuracy in answering corporate finance questions. It feeds to models a public commercial credit agreement — terms of a business loan or a line of credit — and poses questions that require extracting information and reasoning over it.
- TaxEval tests accuracy on tax-related prompts. Half of the questions test skills like calculating taxable income, marginal rate, and the like. The other half cover knowledge such as how different accounting methods impact taxes or how taxes apply to various types of assets.
- Vals AI also tracks performance on LegalBench, an open benchmark that evaluates legal reasoning.
Results: Among 15 models, GPT-4 and Claude 3 Opus dominated Vals.AI’s leaderboards as of April 11, 2024. GPT-4 topped CorpFin and TaxEval, correctly answering 64.8 and 54.5 percent of questions, respectively. Claud 3 Opus narrowly beat GPT-4 on ContractLaw and LegalBench, achieving 74.0 and 77.7 percent, respectively. The smaller Claude 3 Sonnet took third place in ContractLaw, CorpFin, and TaxEval with 67.6, 61.4, and 37.1 percent. Google’s Gemini Pro 1.0 took third place in LegalBench with 73.6 percent.
Behind the news: Many practitioners in finance and law use LLMs in applications that range from processing documents to predicting interest rates. However, LLM output in such applications requires oversight. In 2023, a New York state judge reprimanded a lawyer for submitting an AI-generated brief that referred to fictitious cases.
Why it matters: Typical AI benchmarks are designed to evaluate general knowledge and cognitive abilities. Many developers would like to measure more directly performance in real-world business contexts, where specialized knowledge may come into play.
We’re thinking: Open benchmarks can benefit from public scrutiny, and they’re available to all developers. However, they can be abused when developers cherry-pick benchmarks on which their models perform especially well. Moreover, they may find their way into training sets, making for unfair comparisons. Independent testing on proprietary benchmarks is one way to address these issues.
NEW FROM DEEPLEARNING.AI

Join “Getting Started with Mistral” and access Mistral AI’s open source and commercial models via API calls. Learn to select the right model for your use case and get hands-on with features like JSON mode, function calling, and effective prompting techniques. Enroll for free!

AI Progress Report: Manufacturing
Manufacturers are embracing AI even as they struggle to find the talent and data required.
What’s new: The market-research arm of MIT Technology Review surveyed manufacturers’ use of AI in engineering, design, procurement, and production. All respondents were at least experimenting with AI, and many expect to launch their first deployments in the next year or two. Microsoft sponsored the research.
How it works: The authors interviewed executives at 300 manufacturers in aerospace, automotive, chemicals, electronics, and heavy equipment. All were either applying or considering AI in product design or factory operations.
- The most common uses of AI in production involved designing products, creating content such as technical documentation, and building chatbots. The most common uses in earlier stages were knowledge management and quality control.
- 35 percent of respondents had deployed AI in production. Another 37 percent were experimenting with AI, while 27 percent were conducting preliminary research.
- 45 percent of respondents in electronics and 39 percent in automotive had deployed AI in production. Larger companies were more likely to have deployed AI (77 percent of companies with revenues over $10 billion compared to 4 percent of those with revenues under $500 million). Larger companies were also more likely to forecast increases in AI spending in the next two years.
- Asked to name the biggest challenges to scaling up uses of AI, respondents most often pointed to shortages of skills and talent. Asked to name challenges their company faced with respect to data, they pointed to maintaining data quality, integrating data from different parts of an organization, and governing data.
Behind the news: Manufacturers are using AI to help design products, visually inspect goods, and maintain equipment. The field has attracted major players: Last year, Microsoft and Siemens launched a pilot of Industrial Copilot, which enables users to interact in natural language with software that drives assembly lines.
Why it matters: Manufacturers want to use AI, but many face obstacles of talent and data. That spells opportunities for budding practitioners as well as for manufacturers that lack infrastructure for collecting and managing data.
We’re thinking: One key to successful implementation of AI in manufacturing is tailoring systems to the unique circumstances of each individual facility. The highly heterogeneous tasks, equipment, and surroundings in different factories mean that one model doesn’t fit all. Developers who can solve this long-tail problem stand to reap rewards.
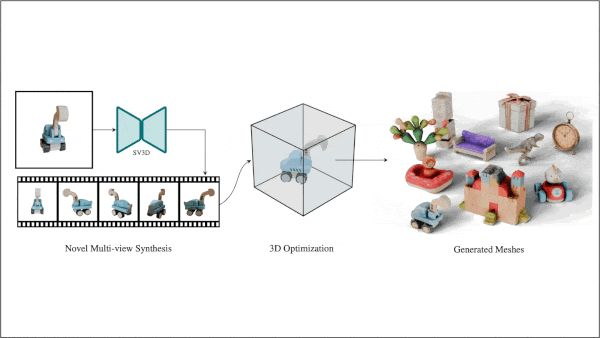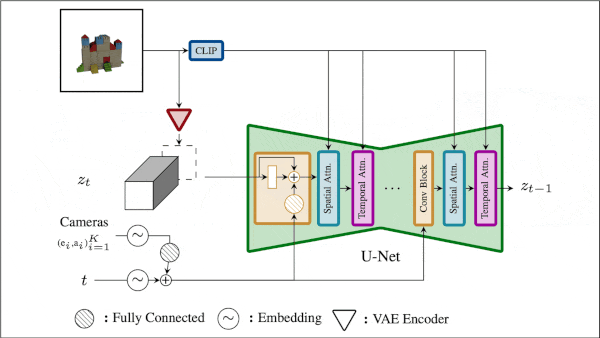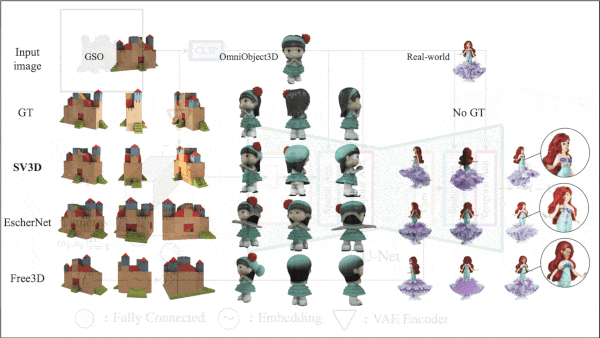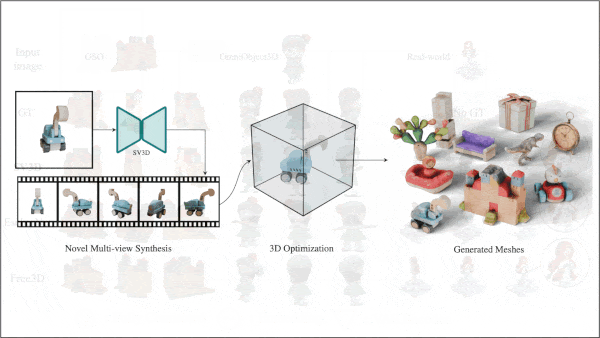
A 3D Model From One 2D Image
Video diffusion provides a new basis for generating 3D models.
What's new: Vikram Voleti, Chun-Han Yao, Mark Boss, Varun Jampani, and colleagues at Stability AI produced a method that generates a 3D model from a single image based on Stability’s video diffusion model. You can see its output here.
Key insight: The approach known as a Neural Radiance Field (NeRF) learns to create a 3D model from images of the same object shot at various angles. Given a single image of an object, a video diffusion model can learn to generate videos that orbit around it. The frames from such orbital videos give NeRF the information it needs to produce a 3D model.
How it works: To generate an image, the authors took one step before and two steps during inference. Before inference: Learn to generate an orbital video. During inference: (i) Train a NeRF model on an orbital video. (ii) Improve the 3D model using diffusion following DreamFusion.
- The authors fine-tuned a pretrained Stable Video Diffusion, given an image of an object, to generate an orbital video. They fine-tuned the model on orbital views of synthetic objects in the Objaverse dataset, first without and then with information about the camera’s orbit. They called the fine-tuned model Stable Video 3D (SV3D).
- At inference, SV3D generated an orbital video from an image, where the orbit periodically went up and down to ensure the top and bottom of the object were visible. From these images, the authors trained an Instant-NGP NeRF model, which learned to represent the object as a 3D model and generate pictures from new camera angles based on different views of the same object.
- To improve the 3D model, the authors first represented it using DMTet instead of Instant-NGP. DMTet is a system of networks built to refine 3D shapes from rough point clouds or low-resolution 3D models. The authors rendered images of DMTet’s 3D model along random camera orbits. For each image, the authors added noise to the image’s representation and removed it using SV3D. DMTet learned to update its 3D model to minimize the difference between the rendered image and the updated version from SV3D.
Results: The authors produced 3D models from images of 50 objects in GSO, a 3D object dataset of scanned household items. They compared their 3D models to those produced by other methods including EscherNet, a method that uses an image diffusion model to generate images of an object from different angles that are used to train a pair of vanilla neural networks to produce a 3D model. Evaluated according to Chamfer distance, a measure of the distance between the points on the ground truth and generated 3D models (lower is better), their method achieved .024, while EscherNet achieved .042.
Why it matters: Video diffusion models must generate different views of the same object, so they require a greater understanding of 3D objects than image diffusion models, which need to generate only one view at a time. Upgrading from an image diffusion model to a video diffusion model makes for better 3D object generation.
We’re thinking: Building 3D models used to be difficult, but with models like this, it's becoming less of a mesh.