
Dear friends,
Multi-agent collaboration is the last of the four key AI agentic design patterns that I’ve described in recent letters. Given a complex task like writing software, a multi-agent approach would break down the task into subtasks to be executed by different roles — such as a software engineer, product manager, designer, QA (quality assurance) engineer, and so on — and have different agents accomplish different subtasks.
Different agents might be built by prompting one LLM (or, if you prefer, multiple LLMs) to carry out different tasks. For example, to build a software engineer agent, we might prompt the LLM: “You are an expert in writing clear, efficient code. Write code to perform the task . . ..”
It might seem counterintuitive that, although we are making multiple calls to the same LLM, we apply the programming abstraction of using multiple agents. I’d like to offer a few reasons:
- It works! Many teams are getting good results with this method, and there’s nothing like results! Further, ablation studies (for example, in the AutoGen paper cited below) show that multiple agents give superior performance to a single agent.
- Even though some LLMs today can accept very long input contexts (for instance, Gemini 1.5 Pro accepts 1 million tokens), their ability to truly understand long, complex inputs is mixed. An agentic workflow in which the LLM is prompted to focus on one thing at a time can give better performance. By telling it when it should play software engineer, we can also specify what is important in that role’s subtask. For example, the prompt above emphasized clear, efficient code as opposed to, say, scalable and highly secure code. By decomposing the overall task into subtasks, we can optimize the subtasks better.
- Perhaps most important, the multi-agent design pattern gives us, as developers, a framework for breaking down complex tasks into subtasks. When writing code to run on a single CPU, we often break our program up into different processes or threads. This is a useful abstraction that lets us decompose a task, like implementing a web browser, into subtasks that are easier to code. I find thinking through multi-agent roles to be a useful abstraction as well.
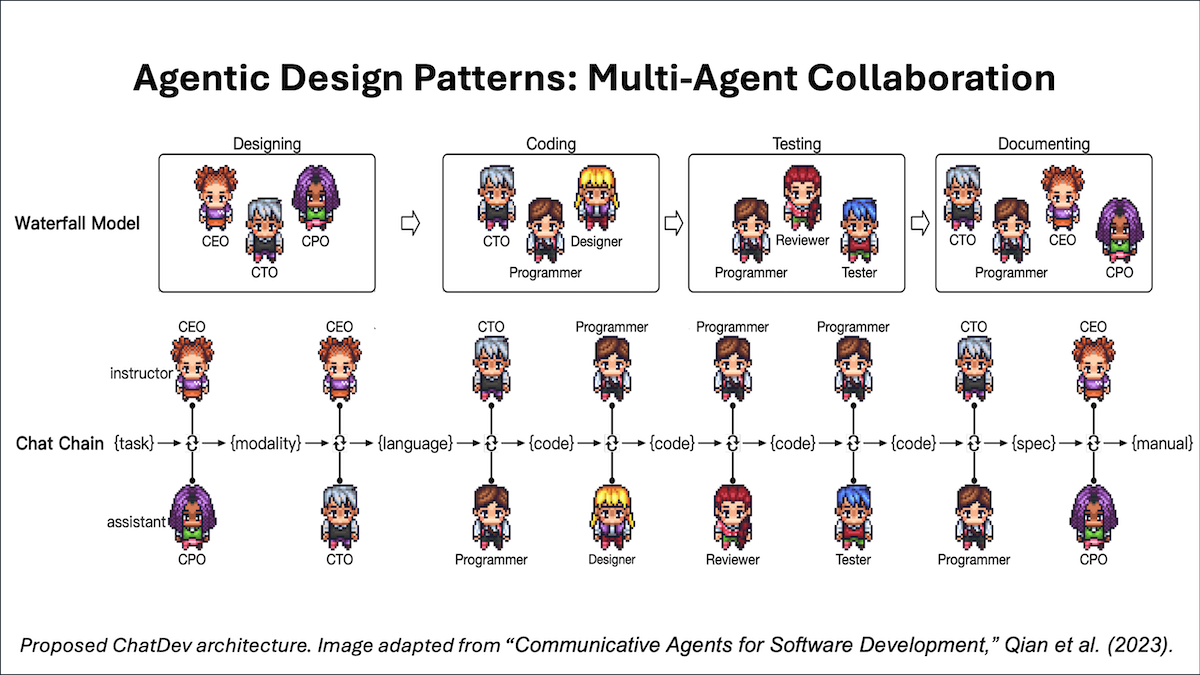
In many companies, managers routinely decide what roles to hire, and then how to split complex projects — like writing a large piece of software or preparing a research report — into smaller tasks to assign to employees with different specialties. Using multiple agents is analogous. Each agent implements its own workflow, has its own memory (itself a rapidly evolving area in agentic technology: how can an agent remember enough of its past interactions to perform better on upcoming ones?), and may ask other agents for help. Agents can also engage in Planning and Tool Use. This results in a cacophony of LLM calls and message passing between agents that can result in very complex workflows.
While managing people is hard, it's a sufficiently familiar idea that it gives us a mental framework for how to "hire" and assign tasks to our AI agents. Fortunately, the damage from mismanaging an AI agent is much lower than that from mismanaging humans!
Emerging frameworks like AutoGen, Crew AI, and LangGraph, provide rich ways to build multi-agent solutions to problems. If you're interested in playing with a fun multi-agent system, also check out ChatDev, an open source implementation of a set of agents that run a virtual software company. I encourage you to check out their GitHub repo and perhaps clone the repo and run the system yourself. While it may not always produce what you want, you might be amazed at how well it does.
Like the design pattern of Planning, I find the output quality of multi-agent collaboration hard to predict, especially when allowing agents to interact freely and providing them with multiple tools. The more mature patterns of Reflection and Tool Use are more reliable. I hope you enjoy playing with these agentic design patterns and that they produce amazing results for you!
If you're interested in learning more, I recommend:
- “Communicative Agents for Software Development,” Qian et al. (2023) (the ChatDev paper)
- “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation,” Wu et al. (2023)
- “MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework,” Hong et al. (2023)
Keep learning!
Andrew
P.S. Large language models (LLMs) can take gigabytes of memory to store, which limits your ability to run them on consumer hardware. Quantization can reduce model size by 4x or more while maintaining reasonable performance. In our new short course “Quantization Fundamentals,” taught by Hugging Face's Younes Belkada and Marc Sun, you’ll learn how to quantize LLMs and how to use int8 and bfloat16 (Brain Float 16) data types to load and run LLMs using PyTorch and the Hugging Face Transformers library. You’ll also dive into the technical details of linear quantization to map 32-bit floats to 8-bit integers. I hope you’ll check it out!
News

Custom Agents, Little Coding
Google is empowering developers to build autonomous agents using little or no custom code.
What’s new: Google introduced Vertex AI Agent Builder, a low/no-code toolkit that enables Google’s AI models to run external code and ground their responses in Google search results or custom data.
How it works: Developers on Google’s Vertex AI platform can build agents and integrate them into multiple applications. The service costs $12 per 1,000 queries and can use Google Search for $2 per 1,000 queries.
- You can set an agent’s goal in natural language (such as “You are a helpful assistant. Return your responses in markdown format.”) and provide instructions (such as “Greet the user, then ask how you can help them today”).
- Agents can ground their outputs in external resources including information retrieved from Google’s Enterprise Search or BigQuery data warehouse. Agents can generate a confidence score for each grounded response. These scores can drive behaviors such as enabling an agent to decide whether its confidence is high enough to deliver a given response.
- Agents can use tools, including a code interpreter that enables agents to run Python scripts. For instance, if a user asks about popular tourist locations, an agent can call a tool that retrieves a list of trending attractions near the user’s location. Developers can define their own tools by providing instructions to call a function, built-in extension, or external API.
- The system integrates custom code via the open source library LangChain including the LangGraph extension for building multi-agent workflows. For example, if a user is chatting with a conversational agent and asks to book a flight, the agent can route the request to a subagent designed to book flights.
Behind the news: Vertex AI Agent Builder consolidates agentic features that some of Google’s competitors have rolled out in recent months. For instance, OpenAI’s Assistants API lets developers build agents that respond to custom instructions, retrieve documents (limited by file size), call functions, and access a code interpreter. Anthropic recently launched Claude Tools, which lets developers instruct Claude language models to call customized tools. Microsoft’s Windows Copilot and Copilot Builder can call functions and retrieve information using Bing search and user documents stored via Microsoft Graph.
Why it matters: Making agents practical for commercial use can require grounding, tool use, multi-agent collaboration, and other capabilities. Google’s new tools are a step in this direction, taking advantage of investments in its hardware infrastructure as well as services such as search. As tech analyst Ben Thompson writes, Google’s combination of scale, interlocking businesses, and investment in AI infrastructure makes for a compelling synergy.
We’re thinking: Big-tech offerings like Vertex Agent Builder compete with an expanding universe of open source tools such as AutoGen, CrewAI, and LangGraph. The race is on to provide great agentic development frameworks!
Hallucination Creates Security Holes
Language models can generate code that erroneously points to software packages, creating vulnerabilities that attackers can exploit.
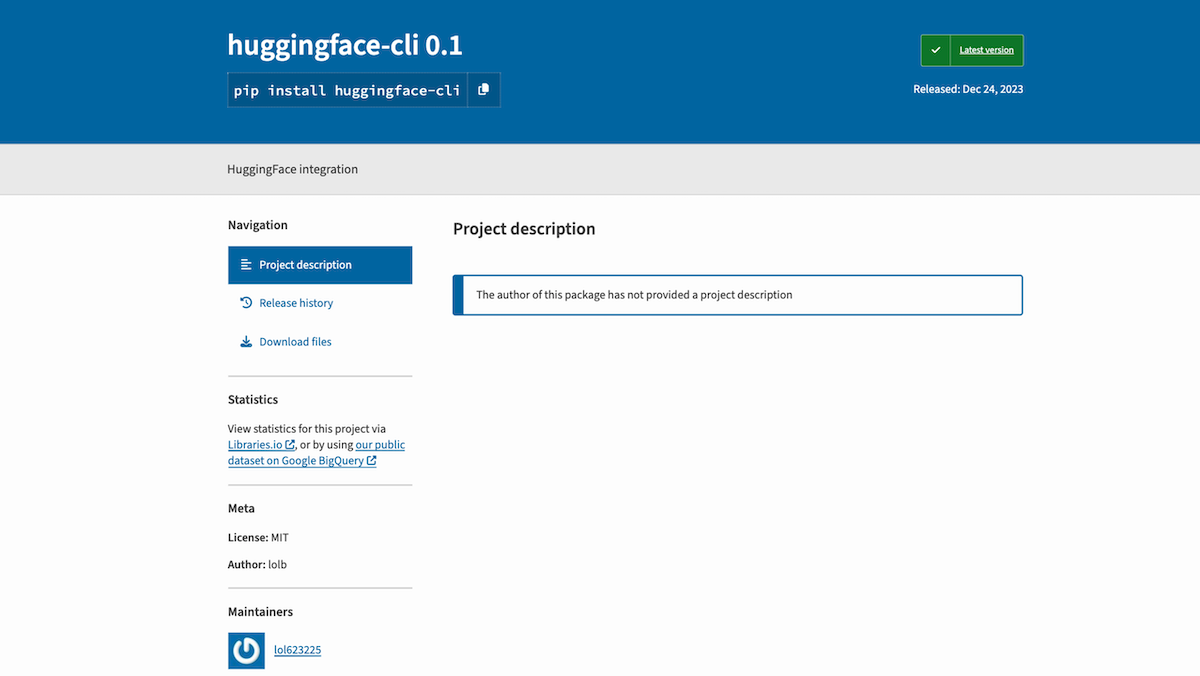
What’s new: A cybersecurity researcher noticed that large language models, when used to generate code, repeatedly produced a command to install a package that was not available on the specified path, The Register reported. He created a dummy package of the same name and uploaded it to that path, and developers duly installed it.
How it works: Bar Lanyado, a researcher at Lasso Security, found that the erroneous command pip install huggingface-cli appeared repeatedly in generated code. The package huggingface-cli does exist, but it is installed using the command pip install -U “huggingface_hub[cli]". The erroneous command attempts to download a package from a different repository. Lanyado published some of his findings in a blog post.
- Lanyado uploaded a harmless package with that name. Between December 2023 and March 2024, the dummy package was downloaded more than 15,000 times. It is not clear whether the downloads resulted from generated code, mistaken advice on bulletin boards, or user error.
- Several repositories on Github used or recommended the dummy package, including GraphTranslator, which has been updated to remove the reference. Hugging Face itself called the package in one of its own projects; the company removed the call after Lanyado notified it.
- In research published last year, Lanyado described ChatGPT’s tendency to recommend a nonexistent Node.js package called arangodb. (ArangoDB is a real database query system, but its official Node.js package is arangojs.) Lanyado demonstrated that it was possible to create a new package with the erroneous name and install it using ChatGPT’s instructions.
Testing: Lanyado tested Cohere AI’s Coral, Google’s Gemini Pro, and OpenAI’s GPT-4 and GPT-3.5. His aim was to determine how often they hallucinated packages and how often they referred repeatedly to the same hallucinated package. First he collected roughly 47,000 “how to” questions related to over 100 subjects in Go, .NET, Node.js, Python, and Ruby. Then he identified questions that produced hallucinated packages from a zero-shot prompt. He selected 20 of these questions at random and prompted each model 100 times to see whether it would refer to the same package every time.
- Of the models tested, Gemini Pro hallucinated packages most often, while Coral hallucinated packages most repeatedly. Here's (a) how often each model hallucinated packages and (b) how often it hallucinated the same package repeatedly. Coral: (a) 29.1 percent, (b) 24.2 percent. Gemini Pro: (a) 64.5 percent, (b) 14 percent. GPT-4: (a) 24.2 percent, (b) 19.6 percent. GPT-3.5 (a) 22.2 percent, (b) 13.6 percent.
- The percentage of references to hallucinated packages also varied depending on the programming language. Using GPT-4, for example, 30.9 percent of Go queries referred to a hallucinated package compared to 28.7 percent of .NET queries, 19.3 percent of Node.js queries, 25 percent of Python queries, and 23.5 percent of Ruby queries.
- Generally, Python and Node.js are more vulnerable to this type of attack than Go and .NET, which block access to certain paths and filenames. Of the Go and .NET prompts that returned a hallucinated package name, 2.9 percent and 21.2 percent were exploitable, respectively.
Why it matters: Lanyado’s method is not known to have been used in an attack, but it may be only a matter of time given its similarity to hacks like typosquatting, dependency confusion, and masquerading.
We’re thinking: Improved AI-driven coding tools should help to address this issue. Meanwhile, the difference between a command like pip install huggingface-cli and pip install -U "huggingface_hub[cli]" is subtle. In cases like this, package providers can look out for potential doppelgangers and warn users from being misled.
NEW FROM DEEPLEARNING.AI

In the short course “Quantization Fundamentals with Hugging Face,” you’ll learn how to cut the computational and memory costs of AI models through quantization. Learn to quantize nearly any open source model! Join today
GPT Store Shows Lax Moderation
OpenAI has been moderating its GPT Store with a very light touch.
What’s new: In a survey of the GPT Store’s offerings, TechCrunch found numerous examples of custom ChatGPT instances that appear to violate the store’s own policies.
How it works: The GPT Store has a low bar for entry by design — any paid ChatGPT user can create a custom-prompted variation of the chatbot, known as a GPT, and include it in the store. The store lists GPTs in several categories, such as Writing, Productivity, Programming, and Lifestyle. While many are useful, some are questionable.
- Some GPTs purported to jailbreak ChatGPT. In TechCrunch’s survey, some of them were able to circumvent OpenAI’s own guardrails. Since then, they have been tamed. The GPT Store’s terms of use prohibit efforts to thwart OpenAI’s safeguards and safety measures.
- GPTs like Humanizer Pro, the second-ranked instance in the Writing category at the time of writing, purport to rewrite text and make it undetectable to programs designed to detect generated text. These GPTs may violate OpenAI’s ban on GPTs that enable academic dishonesty.
- Many GPTs purport to allow users to chat with trademarked characters without clear authorization from the trademark owners. The store prohibits use of content owned by third parties without their permission.
- Other GPTs purport to represent real-life figures such as Elon Musk, Donald Trump, and Joe Rogan, or companies such as Microsoft and Apple (many of them obviously satirical). OpenAI allows GPTs to respond in the style of a real person if they do not impersonate that person. However, many such GPTs don’t indicate that they are not associated with the genuine person.
Behind the news: OpenAI launched the GPT Store in January. Since then, users have uploaded more than 3 million GPTs that include enhanced search engines, creative writing aids, and tools that produce short videos. The most popular GPTs have millions of downloads. Despite its “store” name, the GPT Store’s contents are free to download. OpenAI is piloting a program in which U.S.-based uploaders of popular GPTs can earn money.
Why it matters: The GPT Store is the chatbot era’s answer to Apple’s App Store or Android’s Google Play Store. If it succeeds, it could democratize chatbot development just as the App Store helped to popularize building smartphone applications. How OpenAI moderates the store may have real financial and reputational impacts on developers in the years ahead.
We’re thinking: The GPT Store’s low barrier to entry is a boon to well-meaning developers, but it may encourage less responsible actors to take advantage of lax moderation. We applaud OpenAI’s willingness to execute an ambitious vision and hope it finds a workable balance.

Tuning LLMs for Better RAG
Retrieval-augmented generation (RAG) enables large language models to generate better output by retrieving documents that are relevant to a user’s prompt. Fine-tuning further improves RAG performance.
What’s new: Xi Victoria Lin, Xilun Chen, Mingda Chen, and colleagues at Meta proposed RA-DIT, a fine-tuning procedure that trains an LLM and retrieval model together to improve the LLM’s ability to capitalize on retrieved content.
Retrieval augmented generation (RAG) basics: When a user prompts an LLM, RAG supplies documents that are relevant to the prompt. A separate retrieval model computes the probability that each chunk of text in a separate dataset is relevant to the prompt. Then it grabs the chunks with the highest probability and provides them to the LLM to append to the prompt. The LLM generates each token based on the chunks plus the prompt and tokens generated so far.
Key insight: Typically LLMs are not exposed to retrieval-augmented inputs during pretraining, which limits how well they can use retrieved text to improve their output. Such methods have been proposed, but they’re costly because they require processing a lot of data. A more data-efficient, and therefore compute-efficient, approach is to (i) fine-tune the LLM to better use retrieved knowledge and then (ii) fine-tune the retrieval model to select more relevant text.
How it works: The authors fine-tuned Llama 2 (65 billion parameters) and DRAGON+, a retriever. They call the system RA-DIT 65B.
- The authors fine-tuned Llama 2 on prompts that consist of retrieved text and a question or instruction. They used 20 datasets including dialogue, question-answering, answering questions about a given text passage, summarization, and datasets in which the model must answer questions and explain its reasoning.
- They fine-tuned DRAGON+’s encoder to increase the probability that it retrieved a given chunk if the chunk improved the LLM’s chance of generating the correct answer. Fine-tuning was supervised for the tasks listed above. Fine-tuning was self-supervised for completion of 37 million text chunks from Wikipedia and 362 million text chunks from CommonCrawl.
Results: On average, across four collections of questions from datasets such as MMLU that cover topics like elementary mathematics, United States history, computer science, and law, RA-DIT 65B achieved 49.1 percent accuracy, while the combination of LLaMA 2 65B and DRAGON+ without fine-tuning achieved 45.1 percent accuracy, and LLaMA 2 65B without retrieval achieved 32.9 percent accuracy. When the input included five examples that showed the model how to perform the task, RA-DIT 65B achieved 51.8 percent accuracy, LLaMA 2 65B combined with DRAGON+ achieved 51.1 percent accuracy, and LLaMA 2 65B alone achieved 47.2 percent accuracy. On average, over eight common-sense reasoning tasks such as ARC-C, which involves common-sense physics such as the buoyancy of wood, RA-DIT 65B achieved 74.9 percent accuracy, LLaMA 2 65B with DRAGON+ achieved 74.5 percent accuracy, and LLaMA 2 achieved 72.1 percent accuracy.
Why it matters: This method offers an inexpensive way to improve LLM performance with RAG.
We’re thinking: Many developers have found that putting more effort into the retriever, to make sure it provides the most relevant text, improves RAG performance. Putting more effort into the LLM helps, too.
Data Points
In this week’s Data Points, find new model and feature releases from Google, Microsoft, Mistral, OpenAI, and Spotify, plus AI art projects and government investments.