
Dear friends,
Planning is a key agentic AI design pattern in which we use a large language model (LLM) to autonomously decide on what sequence of steps to execute to accomplish a larger task. For example, if we ask an agent to do online research on a given topic, we might use an LLM to break down the objective into smaller subtasks, such as researching specific subtopics, synthesizing findings, and compiling a report.
Many people had a “ChatGPT moment” shortly after ChatGPT was released, when they played with it and were surprised that it significantly exceeded their expectation of what AI can do. If you have not yet had a similar “AI Agentic moment,” I hope you will soon. I had one several months ago, when I presented a live demo of a research agent I had implemented that had access to various online search tools.
I had tested this agent multiple times privately, during which it consistently used a web search tool to gather information and wrote up a summary. During the live demo, though, the web search API unexpectedly returned with a rate limiting error. I thought my demo was about to fail publicly, and I dreaded what was to come next. To my surprise, the agent pivoted deftly to a Wikipedia search tool — which I had forgotten I’d given it — and completed the task using Wikipedia instead of web search.
This was an AI Agentic moment of surprise for me. I think many people who haven’t experienced such a moment yet will do so in the coming months. It’s a beautiful thing when you see an agent autonomously decide to do things in ways that you had not anticipated, and succeed as a result!
Many tasks can’t be done in a single step or with a single tool invocation, but an agent can decide what steps to take. For example, to simplify an example from the HuggingGPT paper (cited below), if you want an agent to consider a picture of a boy and draw a picture of a girl in the same pose, the task might be decomposed into two distinct steps: (i) detect the pose in the picture of the boy and (ii) render a picture of a girl in the detected pose. An LLM might be fine-tuned or prompted (with few-shot prompting) to specify a plan by outputting a string like "{tool: pose-detection, input: image.jpg, output: temp1 } {tool: pose-to-image, input: temp1, output: final.jpg}".
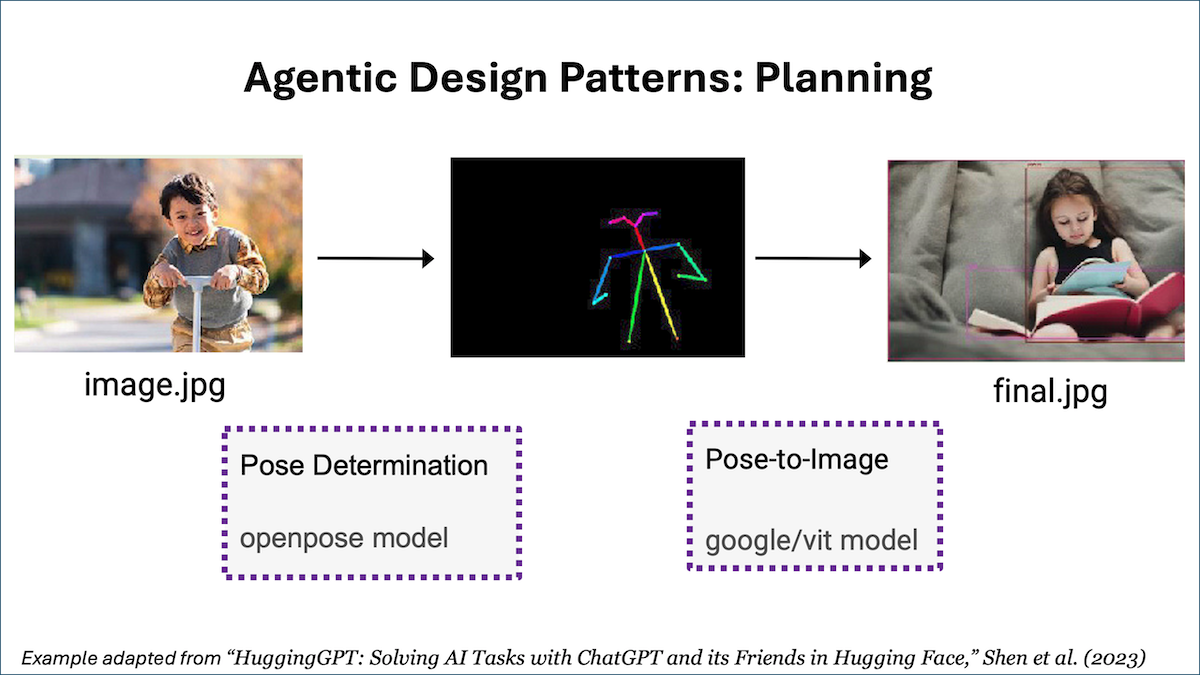
This structured output, which specifies two steps to take, then triggers software to invoke a pose detection tool followed by a pose-to-image tool to complete the task. (This example is for illustrative purposes only; HuggingGPT uses a different format.)
Admittedly, many agentic workflows do not need planning. For example, you might have an agent reflect on, and improve, its output a fixed number of times. In this case, the sequence of steps the agent takes is fixed and deterministic. But for complex tasks in which you aren’t able to specify a decomposition of the task into a set of steps ahead of time, Planning allows the agent to decide dynamically what steps to take.
On one hand, Planning is a very powerful capability; on the other, it leads to less predictable results. In my experience, while I can get the agentic design patterns of Reflection and Tool use to work reliably and improve my applications’ performance, Planning is a less mature technology, and I find it hard to predict in advance what it will do. But the field continues to evolve rapidly, and I'm confident that Planning abilities will improve quickly.
If you’re interested in learning more about Planning with LLMs, I recommend:
- “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,” Wei et al. (2022)
- “HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face,” Shen et al. (2023)
- “Understanding the planning of LLM agents: A survey,” by Huang et al. (2024)
Keep learning!
Andrew
P.S. Making sure your RAG system has access to the data it needs to answer questions is an important, but often laborious, step for good performance. Our new short course “Preprocessing Unstructured Data for LLM Applications,” taught by Matt Robinson of Unstructured, teaches you how to build systems that can easily ingest data from a wide range of formats (like text, images, and tables) and from many different sources (like PDF, PowerPoint, and HTML). You’ll learn practical ways to extract and normalize content from diverse formats, enrich your content with metadata to enable more powerful retrieval and reasoning, and use document layout analysis and vision transformers to process embedded images and tables. Putting these components together, you’ll build a RAG bot that draws from multiple document types, demonstrating how high-quality data ingestion and preprocessing affect the quality of RAG output. Sign up here!
News

Coding Agents Proliferate
New coding tools act like agents to automate software programming tasks.
What’s new: A wave of open source software-development tools based on large language models take advantage of the ability of large language models to plan, critique their own work, and extend themselves by calling functions.
How it works: These projects follow hot on the heels of Cognition’s Devin, a commercial system billed as a semi-autonomous software developer that’s available to selected customers upon request. Some, like Devin, provide sandboxed chat for natural-language commands, command line shell, code editor, and/or a web browser through which the agent can test code or find documentation. Given a prompt, they generate a step-by-step plan and execute it. They may ask for further information or instructions, and users can interrupt to modify their requests.
- Devika uses Anthropic’s Claude 3, OpenAI’s GPT-4 and GPT-3.5, and models supported by Ollama, a tool that runs large language models locally. Like Devin, Devika runs in a web browser and includes an agent that performs planning and reasoning. A persistent knowledge base and database recalls active projects.
- OpenDevin is based on GPT-4 but has access to more than 100 models via litellm, a package that simplifies API calls. OpenDevin’s developers aim to match Devin’s user interface and enable the system to evaluate its own accuracy.
- SWE-agent addresses bugs and issues in Github repositories. It can use any language model. Using GPT-4, it resolved 12.3 percent of tasks in the SWE-bench dataset of real-world GitHub issues. (Devin resolved 13.9 percent of SWE-bench tasks. Claude 3, the highest-scoring model not specifically trained for coding, resolved 4.8 percent of SWE-bench tasks.)
Behind the News: Code-completion tools like Github Copilot and Code Llama quickly have become ubiquitous. AutoGPT, released in 2023, is an open-source generalist AI agent based on GPT-4 that has been used to write and debug code. Recently Replit, known for its Ghostwriter code-completion and chatbot applications, began building its own LLMs for automated code repair.
Why it matters: Agentic coding tools are distinguished by techniques that enable large language models to plan, reflect on their work, call tools, and collaborate with one another. Users report that, unlike previous coding assistants, the new tools are better at sustaining extended tasks and correcting their own work.
We’re thinking: Many software developers worry that large language models will make human coders obsolete. We doubt that AI will replace coders, but we believe that coders who use AI will replace those who don’t. Agent-based tools still have a long way to go, but they seem likely to augment programmers’ abilities in a larger development pipeline.

What Users Do With Generative AI
Generative AI is being used mostly to generate ideas.
What’s new: The tech consultancy Filtered studied the most common uses for generative AI. While most gen AI users produced text, the study surprisingly found that users were slightly more likely to generate videos than images.
How it works: The analysts sifted through tens of thousands of posts on popular online forums for anecdotes that described uses of generative AI. The analysts grouped the posts into a list of 100 most popular uses of generative AI and ranked each one by reach and value added.
- Most often, individuals used generative AI as an aid to brainstorming, both at work and otherwise. They also turned to generative AI for specific suggestions, like recommending movies, suggesting holiday destinations, and generating characters for role-playing games.
- Other uses in the top five: text editing, emotional support, deep dives into niche subjects, and searching for information. (One poster used a chatbot to track down the brand of cookie his grandmother liked.)
- Many users employed generative AI to revise their own work, for example troubleshooting or optimizing code, editing emails before sending them, improving marketing copy, or tweaking images.
- Workplace-related uses included drafting cover letters, creating notes in preparation for meetings, summarizing meetings after they happened, and analyzing sales data. Many students found generative AI useful as a learning aid to review course materials or create personalized ways to learn.
- Many users found that generative AI helped them better understand technical information, such as legal advice or medical expertise. Users relied on chatbots for tasks that might have required them to consult a human expert, like drafting legal complaints, summarizing jargon-filled documents, and seeking information on medical test results.
Behind the news: The range of use cases reflects the huge number of people, from all walks of life and all parts of the world, who are using generative AI tools. In a given week in November 2023, more than 100 million people used ChatGPT, the most popular of these tools. Independently, in February 2024, Pew Research found that 23 percent of U.S. adults had used ChatGPT at least once, including 43 percent of respondents under 30 years old and 37 percent of those with postgraduate degrees. According to the Pew report, 20 percent of all Americans had used ChatGPT for work, and 17 percent had used it for entertainment, with younger and more educated users leading the way.
Why it matters: It’s clear that millions of people use generative AI but less clear how they use it. Understanding how and where they actually apply it is helpful for anyone who aims to develop new generative AI products and services or plans to integrate the tech into their organization.
We’re thinking: While it’s encouraging that more than a fifth of U.S. adults have tried ChatGPT, it also suggests huge room for growth in generative AI at large.
NEW FROM DEEPLEARNING.AI

Integrate diverse data types into your LLM applications in our new short course built in collaboration with Unstructured. Learn techniques to extract and normalize data from PDFs, tables, and images into a structured format. Sign up today

Instability at Stability AI
The CEO of Stability AI resigned as the company faces an increasingly competitive market.
What’s new: Emad Mostaque stepped down from Stability AI, developer of the Stable Diffusion image generator among other models, amid financial woes, uncertain direction, and sinking confidence from investors and employees alike, Forbes reported. Mostaque’s departure followed the exits of numerous executives and key employees.
How it works: Stability confirmed Mostaque’s departure in a blog post. The company’s chief operating officer Shan Shan Wong and chief technology officer Christian Laforte will act as co-CEOs until its directors find a permanent replacement. They inherit a company with troubles beyond leadership.
- Stability faces serious cash-flow issues. In 2023, it projected $11 million in revenue against $153 million in costs. Currently it spends $8 million monthly compared to revenue of $3 million in November and $5.4 million in February.
- The company’s bill for processing power provided by Amazon Web Services, Google, and CoreWeave amounts to $99 million annually. It often failed to pay on time. Stability contemplated reselling access to its leased GPUs to make up for its revenue shortfall.
- Stability struggled to commercialize its models. It tried to strike deals with companies such as Samsung, Snap, and Canva and governments such as Singapore, but the parties couldn’t agree on terms.
- Throughout 2023, it tried to raise funds by courting investors like Nvidia and Google. Negotiations failed partly over questions about the company’s finances. Ultimately it sought a buyer, but no deal emerged.
- Stability faces unpredictable liabilities due to lawsuits over its alleged use of copyrighted images as training data and its models’ ability to produce images in the styles of human artists.
Behind the news: Despite its troubles, Stability continued to release new models. In February, it opened the waitlist for the third-generation version of Stable Diffusion. Last month, it released Stable Video 3D, a project in which the team produced three-dimensional objects from images. This month, it released Stable Audio 2.0, which can produce music files up to three minutes long from a text prompt.
Why it matters: Stability has been a standard bearer for open-source AI in a field where tech giants aim to dominate with closed models. Effective leadership could have a major impact on the models available to developers in the years ahead.
We’re thinking: Stability helped capture the public imagination during the generative AI boom of 2022, and its open models, particularly its diffusion models, have been a huge benefit to the AI community. We hope new leadership puts the company on firm footing.
A Transformer Alternative Emerges
An architectural innovation improves upon transformers — up to 2 billion parameters, at least.
What’s new: Albert Gu at Carnegie Mellon University and Tri Dao at Princeton University developed the Mamba architecture, a refinement of the earlier state space sequence architecture. A relatively small Mamba produced tokens five times faster and achieved better accuracy than a vanilla transformer of similar size while processing input up to a million tokens long.
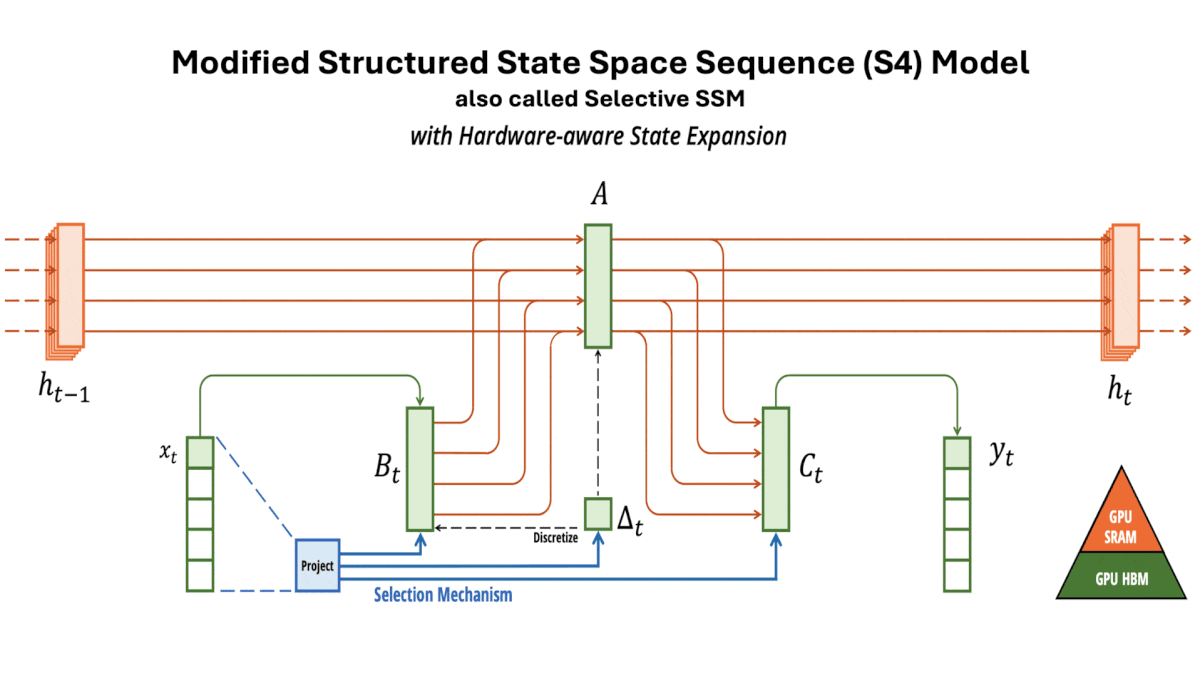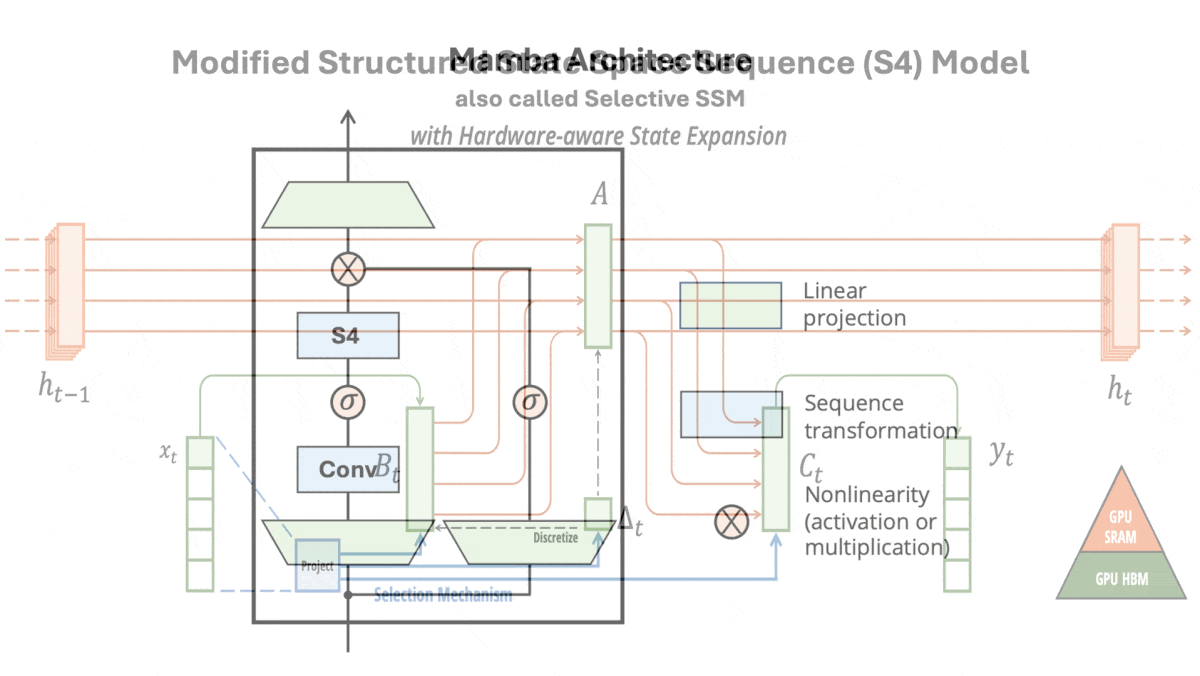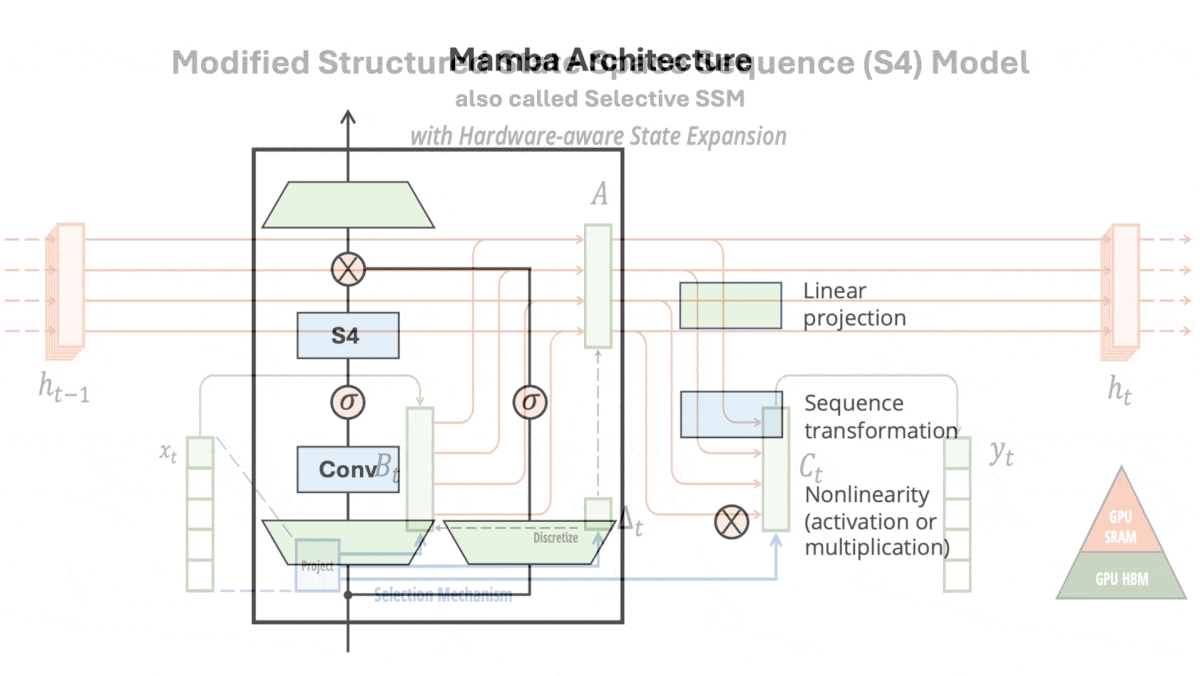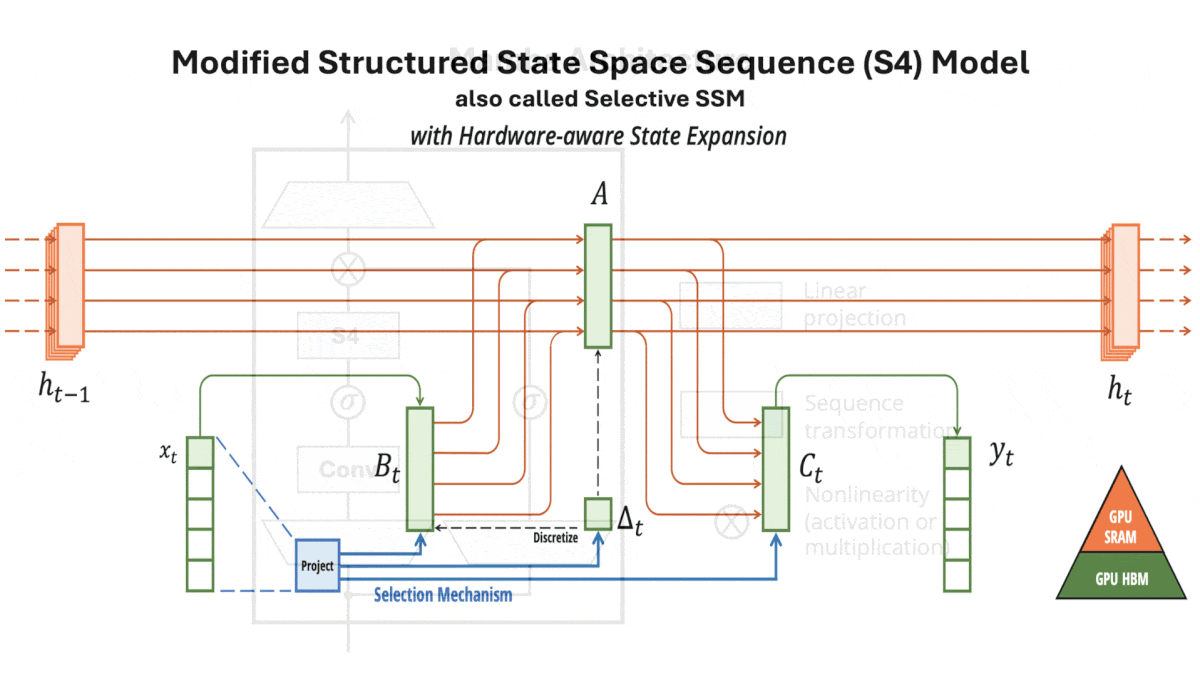
Structured State Space Sequence (S4) basics: S4s, also known as structured SSMs, can be functionally similar to recurrent neural networks (RNNs): They can accept one token at time and produce a linear combination of the current token and an embedding that represents all previous tokens. Unlike RNNs and their extensions including LSTMs — but like transformers — they can also perform an equivalent computation in parallel during training. In addition, they are more computationally efficient than transformers. An S4’s computation and memory requirements rise linearly with input size, while a vanilla transformer’s rise quadratically — a heavy burden with long input sequences.
Key insight: S4s are more efficient than transformers but, while a transformer’s input length is limited only by processing and memory, an S4’s input length is limited by how well its hidden state can represent previously input tokens as new tokens arrive. A gating mechanism that lets the model process the most important parts of an input and ignore the rest can enable it to process longer inputs. One viable gate: Typically S4s apply the same mathematical function to all input tokens, whose parameters consist of four learned matrices. Changing the matrices for each input enables the model to learn which tokens or parts of tokens are least important and can be ignored (set to zero). This condenses the input, enabling the modified S4 to process very long input sequences.
How it works: Mamba is made up of blocks, each of which includes a modified S4 (which the authors call a selective SSM). The authors pretrained different instances on a variety of tasks including generating tokens from The Pile (a collection of text from the web) and predicting DNA base pairs in HG38 (a single human genome) in sequences up to 1 million tokens long.
- In each block, the authors replaced three of the S4’s four fixed matrices with learned linear functions of the input. That is, they replaced each of three learned matrices with a learned matrix multiplied by the input. (The authors hypothesized that modifying the fourth matrix would not help, so they didn’t change it.)
- The following layer multiplied the model’s output with a linear projection of the block’s input. This acted as a gate to filter out irrelevant parts of the embedding.
Results: Mamba achieved better speed and accuracy than transformers of similar size, including tasks that involved inputs of 1 million tokens.
- Running on an Nvidia A100 GPU with 80GB, a Mamba of 1.4 billion parameters produced 1,446 tokens per second, while a transformer of 1.3 billion parameters produced 344 tokens per second.
- In sizes from 130 million parameters to 2.8 billion parameters, Mamba outperformed the transformer Pythia and the S4 H3 on many tasks. It was better at predicting the next word of The Pile, and it was better at question-answering tasks such as WinoGrande and HellaSwag. For instance, on WinoGrande, using models of roughly 2.8 billion parameters, Mamba achieved 63.5 percent accuracy, Pythia 59.7 percent accuracy, and H3 61.4 percent accuracy.
- After fine-tuning on Great Apes DNA Classification (classifying DNA segments up to 1 million tokens long as belonging to one of five species of great ape), using models of 1.4 million parameters, Mamba achieved 70 percent accuracy, while Hyena DNA achieved 55 percent accuracy.
Yes, but: The authors tested model sizes much smaller than current state-of-the-art large language models.
Why it matters: Google’s transformer-based Gemini 1.5 Pro offers context lengths up to 1 million tokens, but methods for building such models aren’t yet widely known. Mamba provides an alternative architecture that can accommodate very long input sequences while processing them more efficiently. Whether it delivers compelling benefits over large transformers and variations that provide higher efficiency and larger context is a question for further research
We're thinking: Research on Mamba is gaining momentum. Other teams are probing the architecture in projects like Motion Mamba, Vision Mamba, MoE-Mamba, MambaByte, and Jamba.
Data Points
Read Data Points to find the latest AI updates of the week, including:
👉 Advanced new editing tools by DALL·E
👉 Command R+, a new LLM by Cohere
👉 An update on big tech's hunt for AI training
And more!