
Dear friends,
Progress on LLM-based agents that can autonomously plan out and execute sequences of actions has been rapid, and I continue to see month-over-month improvements. Many projects attempt to take a task like “write a report on topic X” and autonomously take actions such as browsing the web to gather information to synthesize a report.
AI agents can be designed to take many different types of actions. Research agents (like many projects built on AutoGPT, GPTresearcher, or STORM) search the web and fetch web pages. A sales representative agent might dispatch a product to a user. An industrial automation agent might control a robot.
So far, I see agents that browse the web progressing much faster because the cost of experimentation is low, and this is key to rapid technical progress. It’s cheap to fetch a webpage, and if your agent chooses poorly and reads the wrong page, there’s little harm done. In comparison, sending a product or moving a physical robot are costly actions, which makes it hard to experiment rapidly. Similarly, agents that generate code (that you can run in a sandbox environment) are relatively cheap to run, leading to rapid experimentation and progress.
Although today’s research agents, whose tasks are mainly to gather and synthesize information, are still in an early phase of development, I expect to see rapid improvements. ChatGPT, Bing Chat, and Gemini can already browse the web, but their online research tends to be limited; this helps them get back to users quickly. But I look forward to the next generation of agents that can spend minutes or perhaps hours doing deep research before getting back to you with an output. Such algorithms will be able to generate much better answers than models that fetch only one or two pages before returning an answer.
Even when experimentation is quick, evaluation remains a bottleneck in development. If you can try out 10 algorithm variations quickly, how do you actually pick among them? Using an LLM to evaluate another LLM's output is common practice, but prompting an LLM to give very accurate and consistent evaluations of text output is a challenge. Any breakthroughs here will accelerate progress!

An exciting trend has been a move toward multi-agent systems. What if, instead of having only a single agent, we have one agent to do research and gather information, a second agent to analyze the research, and a third to write the final report? Each of these agents can be built on the same LLM using a different prompt that causes it to play a particular, assigned role. Another common design pattern is to have one agent write and a second agent work as a critic to give constructive feedback to the first agent to help it improve. This can result in much higher-quality output. Open-source frameworks like Microsoft’s AutoGen, Crew AI, and LangGraph are making it easier for developers to program multiple agents that collaborate to get a task done.
I’ve been playing with many agent systems myself, and I think they are a promising approach to architecting intelligent systems. A lot of progress has been made by scaling up LLMs, and this progress no doubt will continue. But big ideas are sometimes made up of many, many little ideas. (For example, you might arrive at an important mathematical theorem via lots of little derivation steps.) Today’s LLMs can reason and have lots of “little ideas” in the sense that they take in information and make basic inferences. Chain-of-thought prompting shows that guiding an LLM to think step-by-step — that is, to string together many basic inferences — helps it to answer questions more accurately than asking it to leap to a conclusion without intermediate steps.
Agent programming models are a promising way to extend this principle significantly and guide LLMs to have lots of little ideas that collectively constitute bigger and more useful ideas.
Keep learning!
Andrew
P.S. New short course: “Open Source Models with Hugging Face,” taught by Maria Khalusova, Marc Sun, and Younes Belkada! Hugging Face has been a game changer by letting you quickly grab any of hundreds of thousands of already-trained open source models to assemble into new applications. This course teaches you best practices for building this way, including how to search and choose among models. You’ll learn to use the Transformers library and walk through multiple models for text, audio, and image processing, including zero-shot image segmentation, zero-shot audio classification, and speech recognition. You’ll also learn to use multimodal models for visual question answering, image search, and image captioning. Finally, you’ll learn how to demo what you build locally, on the cloud, or via an API using Gradio and Hugging Face Spaces. Please sign up here
News
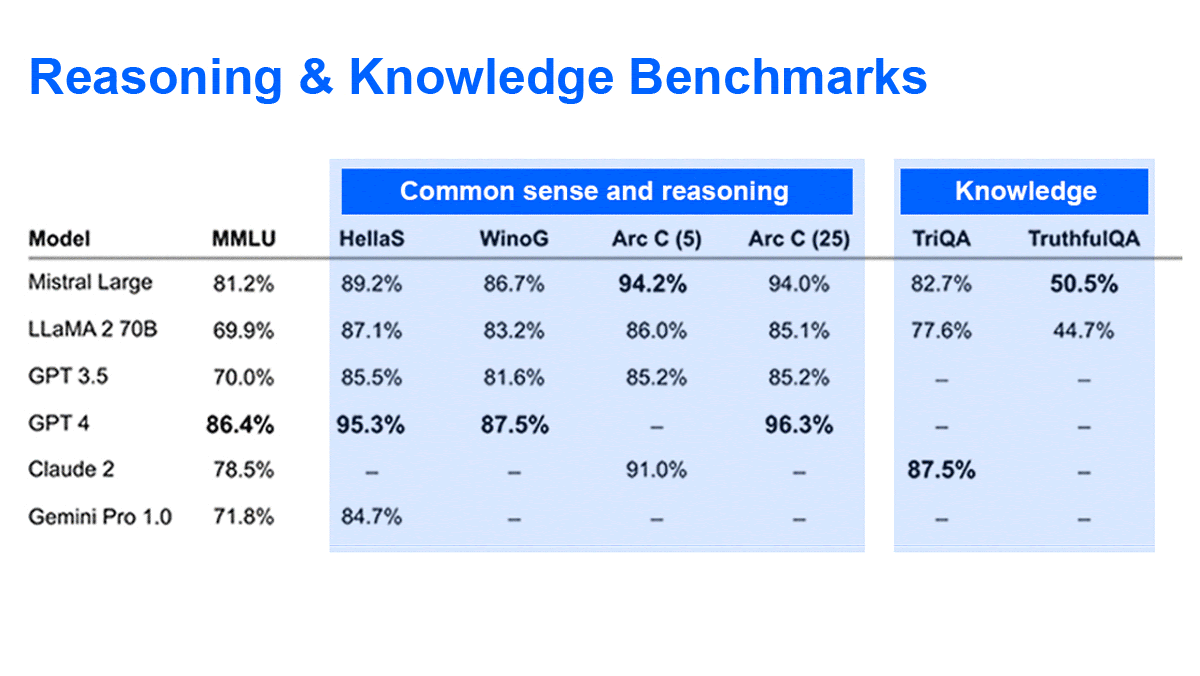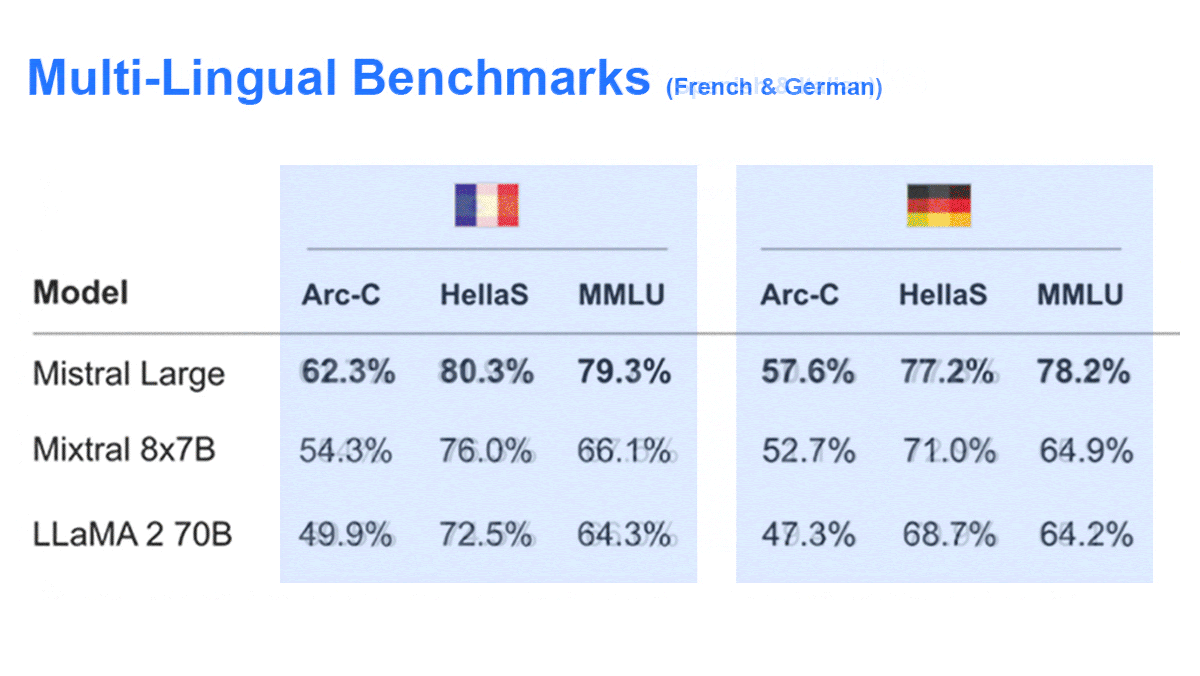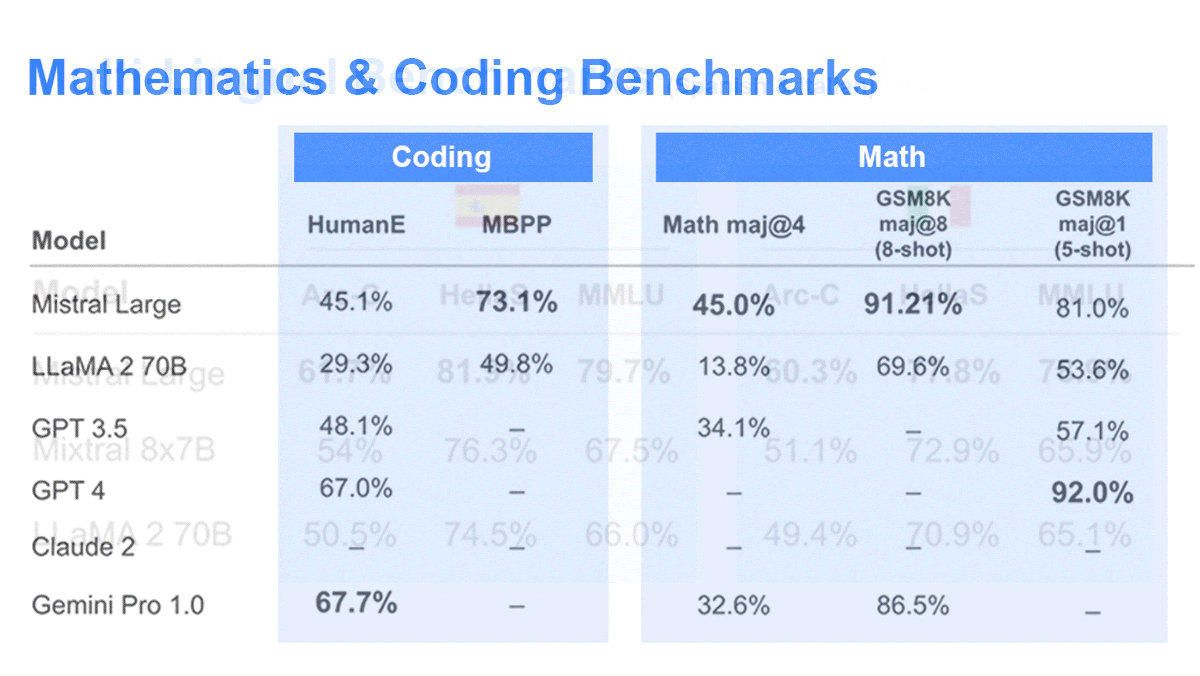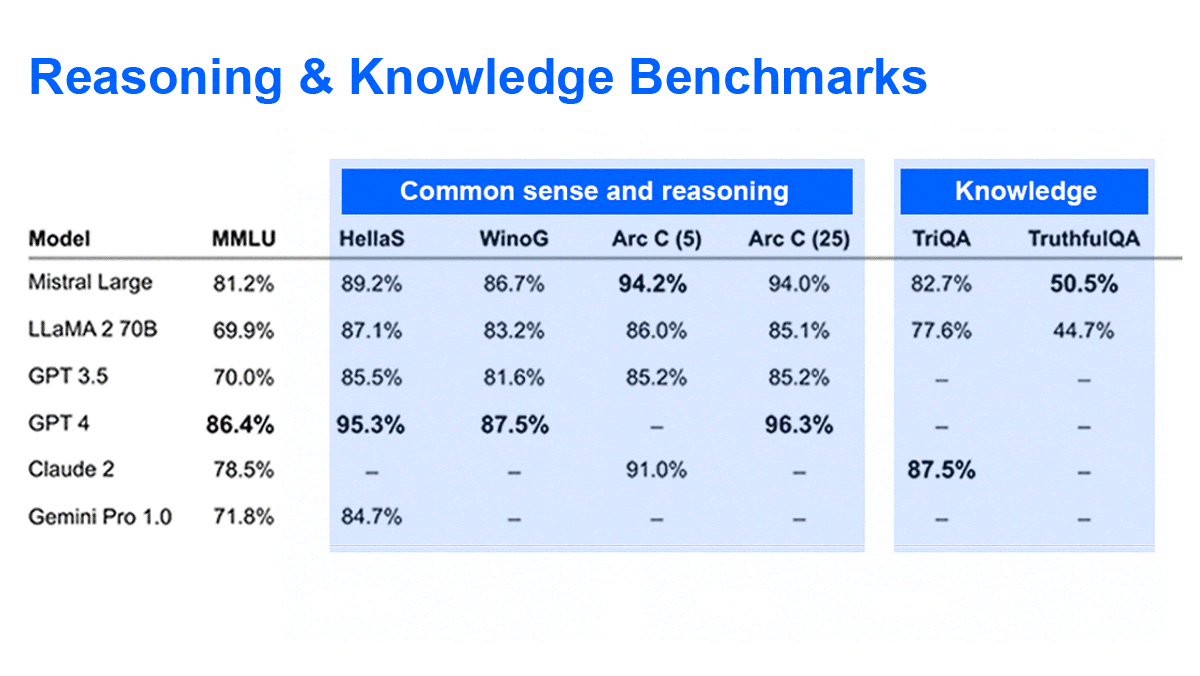
Mistral AI Extends Its Portfolio
European AI champion Mistral AI unveiled new large language models and formed an alliance with Microsoft.
What’s new: Mistral AI introduced two closed models, Mistral Large and Mistral Small (joining Mistral Medium, which debuted quietly late last year). Microsoft invested $16.3 million in the French startup, and it agreed to distribute Mistral Large on its Azure platform and let Mistral AI use Azure computing infrastructure. Mistral AI makes the new models available to try for free here and to use on its La Plateforme and via custom deployments.
Model specs: The new models’ parameter counts, architectures, and training methods are undisclosed. Like the earlier, open source Mistral 7B and Mixtral 8x7B, they can process 32,000 tokens of input context.
- Mistral Large achieved 81.2 percent on the MMLU benchmark, outperforming Anthropic’s Claude 2, Google’s Gemini Pro, and Meta’s Llama 2 70B, though falling short of GPT-4. Mistral Small, which is optimized for latency and cost, achieved 72.2 percent on MMLU.
- Both models are fluent in French, German, Spanish, and Italian. They’re trained for function calling and JSON-format output.
- Microsoft’s investment in Mistral AI is significant but tiny compared to its $13 billion stake in OpenAI and Google and Amazon’s investments in Anthropic, which amount to $2 billion and $4 billion respectively.
- Mistral AI and Microsoft will collaborate to train bespoke models for customers including European governments.
Behind the news: Mistral AI was founded in early 2023 by engineers from Google and Meta. The French government has touted the company as a home-grown competitor to U.S.-based leaders like OpenAI. France’s representatives in the European Commission argued on Mistral’s behalf to loosen the European Union’s AI Act oversight on powerful AI models.
Yes, but: Mistral AI’s partnership with Microsoft has divided European lawmakers and regulators. The European Commission, which already was investigating Microsoft’s agreement with OpenAI for potential breaches of antitrust law, plans to investigate the new partnership as well. Members of President Emmanuel Macron’s Renaissance party criticized the deal’s potential to give a U.S. company access to European users’ data. However, other French lawmakers support the relationship.
Why it matters: The partnership between Mistral AI and Microsoft gives the startup crucial processing power for training large models and greater access to potential customers around the world. It gives the tech giant greater access to the European market. And it gives Azure customers access to a high-performance model that’s tailored to Europe’s unique regulatory environment.
We’re thinking: Mistral AI has made impressive progress in a short time, especially relative to the resources at its disposal as a startup. Its partnership with a leading hyperscaler is a sign of the tremendous processing and distribution power that remains concentrated in the large, U.S.-headquartered cloud companies.
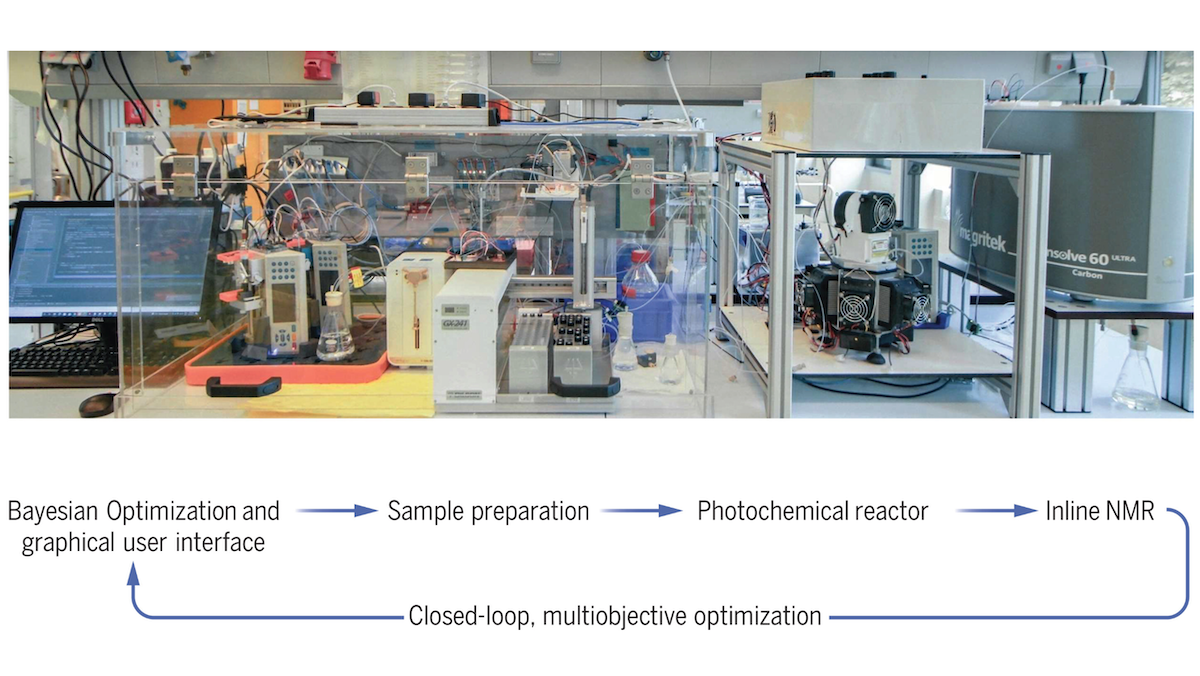
Robot Chemist
A robot outperformed human chemists at synthesizing chemicals.
What’s new: Researchers at University of Amsterdam built RoboChem, an integrated robotic system that learned to design light-activated chemical reactions while achieving optimal yields and throughput.
How it works: RoboChem includes a computer that runs a machine learning model and a set of automated lab instruments including a liquid handler, syringe pumps, and a photochemical reactor, all enclosed in an airtight vacuum chamber. Given a set of reagents and resulting product, RoboChem aimed to find conditions that maximize the yield (the ratio of the amount of a product synthesized to the potential amount, expressed as a percentage) and throughput (rate of synthesis) in the fewest experimental runs. It followed a 3-part cycle: (i) determine experimental conditions (amounts and concentrations of the given reagents, intensity of light, and time spent in the reactor), (ii) combine the reagents under those conditions, and (iii) evaluate the yield and throughput via a spectrometer.
- RoboChem learned how to find the best conditions for each reaction using a Gaussian process, which provides a function and uncertainty estimate for variables to be maximized (in this case, yield and throughput) given the values of other variables (the experimental conditions). Given a set of reagents and 6 to 20 sets of random conditions, RoboChem ran the reactions, measured the results, and updated the Gaussian process.
- RoboChem chose new conditions based on which parts of the Gaussian process’s function had the highest uncertainty and which parts were most likely to produce the highest yield and throughput. RoboChem ran the reaction, measured the results, and updated the Gaussian process.
- It repeated this cycle until it achieved an author-defined throughput, yield, or number of experiments. It returned the conditions with the highest throughput and yield.
Results: Robochem executed reactions to produce 18 substances. In all cases, it found experimental conditions that had either higher throughput and yield, or higher throughput and nearly equivalent yield, than the best conditions previously known. In one reaction, RoboChem achieved yield of 58 percent and throughput of 95.6 g/Lh (gram yield per liter in the reactor per hour), while previous work had achieved 45 percent and 2.8 g/Lh. In another reaction, RoboChem achieved 81 percent and 1720 g/Lh, where previous best results achieved 82 percent and 3 g/Lh — 1 percent lower yield but 573 times greater throughput.
Behind the news: In 2020, researchers at the University of Liverpool trained a mobile robot arm to navigate a chemistry lab, mix chemicals, and operate equipment. That robot used a similar optimization method. However, the Amsterdam robot is much less expensive and proved itself in a wider range of experiments.
Why it matters: The authors believe that RoboChem could dramatically increase lab productivity at lower cost in time and money. The light-activated reactions they focused on have applications in fields including pharmaceuticals, household chemicals, and renewable energy.
We’re thinking: These researchers clearly are in their element.
A MESSAGE FROM DEEPLEARNING.AI

In “Open Source Models with Hugging Face,” our latest short course, you’ll use open source models to build chatbots, language translators, and audio narrators using Hugging Face tools like the model hub, transformers library, Spaces, and Gradio. Join now

Google Releases Open Source LLMs
Google asserted its open source bona fides with new models.
What’s new: Google released weights for Gemma-7B, an 8.5 billion-parameter large language model intended to run GPUs, and Gemma-2B, a 2.5 billion-parameter version intended for deployment on CPUs and edge devices. Each size is available in two versions: pretrained base model and one fine-tuned to follow instructions.
How it works: Gemma models are based on the architecture used in Google’s larger Gemini. Unlike Gemini, they’re not multimodal.
- Gemma-2B and Gemma-7B were trained on 2 trillion and 6 trillion tokens, respectively, of English-language web documents, mathematics, and code snippets. They can process 8,192 tokens of context.
- The fine-tuned versions underwent further training: (i) They received supervised fine-tuning on human-written prompt-and-response pairs as well as synthetic responses that had been filtered for personal information, toxic responses, and other objectionable material. (ii) They were aligned using reinforcement learning with human feedback, in which their output was judged by a model trained on preferences expressed by users.
- Gemma’s license permits commercial use but prohibits a wide range of uses that Google deems harmful including copyright infringement, illegal activity, generating misinformation, or producing sexually explicit content.
- Gemma-7B ranks higher than comparably sized open models including Meta’s Llama 2 7B and Mistral-7B, according to HuggingFace’s Open LLM Leaderboard. By Google’s assessment, it outperforms the nearly double-sized Llama 2 13B in major question answering, reasoning, math, and coding benchmarks. Gemma-2B falls short of the most capable models of its size such as the 2.7-billion-parameter Phi-2.
Behind the news: Google has a rich history of open source AI projects including AlphaFold, TensorFlow, several versions of BERT and T5, and the massive Switch. Lately, though, its open source efforts have been overshadowed by open large language models (LLMs) from Meta, Microsoft, and Mistral.ai. LLMs small enough to run on a laptop have opened open source AI to an expanding audience of developers.
Why it matters: Gemma raises the bar for models of roughly 7 billion parameters. It delivers exceptional performance in a relatively small parameter counts, expanding the options for developers who are building on top of LLMs.
We’re thinking: Gemma confirms Google’s commitment to open source and outperforms top open models of equal size. It’s likely to spur further innovation, especially in AI for edge devices, and keep the Google name in front of enterprising open source developers.

Schooling Language Models in Math
Large language models are not good at math. Researchers devised a way to make them better.
What's new: Tiedong Liu and Bryan Kian Hsiang Low at the National University of Singapore proposed a method to fine-tune large language models for arithmetic tasks.
Key insight: Large language models (LLMs) do fairly well at addition and subtraction as well as multiplication and division by single digits or by powers of 10. They’re less adept at the more challenging tasks of multiplication and division of larger numbers. One way to perform these tasks well is to divide them into simpler subtasks. For example, a relatively easy way to multiply two large numbers like 123 and 321 is to
- Split one number into decimal places (123 becomes 100 + 20 + 3)
- Multiply the other number by each of these (100 * 321 + 20 * 321 + 3 * 321)
- Add the resulting products to arrive at the solution (32100 + 6420 + 963 = 39483)
A similar technique exists for division. Together, these approaches can enable LLMs to perform more complicated mathematical tasks.
How it works: The authors built GOAT (a model GOod at Arithmetic Tasks) by fine-tuning LLaMA on a synthetic dataset that comprised 1 million examples of arithmetic operations on integers that were divided into steps for easier calculation.
- The prompts were simple instructions like “Calculate 397 x 4429” or “I would appreciate it if you could assist me in calculating 1463456 + 2107”.
- The answers were either numbers (for the simpler operations) or chains of reasoning (for multiplications and divisions of larger numbers). For example, if the prompt was “Calculate 24x79”, the target was “24 * 79 = 24 * (70 + 9) = 24 * 70 + 24 * 9 = 1680 + 216 = 1896”.
- To create these chains, the authors wrote a Python script. For multiplication, the script randomly generated two numbers, split one number into decimal places, multiplied the second number by each of those terms, then added the products. It followed a similar procedure for division.
Results: The authors compared GOAT and GPT-4 on BIGBench, which contains arithmetic operations on integers up to five digits. GOAT performed either on par with or better than GPT-4 for all operations. Specifically, GPT-4 struggled to multiply and divide large numbers. Multiplying 5-digit numbers, GPT-4 achieved 0 percent accuracy, while GOAT achieved 96.7 percent. Dividing five-digit numbers, GPT-4 achieved 53.4 percent, while GOAT achieved 96.5 percent. GOAT also performed better than other LLMs (Bloom, GPT-NeoX, OPT, and Pythia) that had been fine-tuned in the same way. The authors attribute this to the fact that LLaMA generates a separate token for each digit (and does not learn tokens that represent multiple digits), while the other models learn tokens for multiple digits (for example, separate tokens for 748, 74, and 7).
Why it matters: LLMs have latent mathematical knowledge that can be unlocked by thoughtful fine-tuning.
We’re thinking: Humans, too, aren’t great at multiplying or dividing numbers directly — but give us a pencil and paper so we can work things out step by step, and we’re much better.
Data Points
More AI news of the week includes:
🔊 Adobe previews an AI audio tool
💰 Microsoft launches Copilot for Finance
🐋 AI uncovers reasons behind humpback whale deaths