
Dear friends,
I think the complexity of Python package management holds down AI application development more than is widely appreciated. AI faces multiple bottlenecks — we need more GPUs, better algorithms, cleaner data in large quantities. But when I look at the day-to-day work of application builders, there’s one additional bottleneck that I think is underappreciated: The time spent wrestling with version management is an inefficiency I hope we can reduce.
A lot of AI software is written in the Python language, and so our field has adopted Python’s philosophy of letting anyone publish any package online. The resulting rich collection of freely available packages means that, with just one “pip install” command, you now can install a package and give your software new superpowers! The community’s parallel exploration of lots of ideas and open-sourcing of innovations has been fantastic for developing and spreading not just technical ideas but also usable tools.
But we pay a price for this highly distributed development of AI components: Building on top of open source can mean hours wrestling with package dependencies, or sometimes even juggling multiple virtual environments or using multiple versions of Python in one application. This is annoying but manageable for experienced developers, but creates a lot of friction for new AI developers entering our field without a background in computer science or software engineering.

I don’t know of any easy solution. Hopefully, as the ecosystem of tools matures, package management will become simpler and easier. Better tools for testing compatibility might be useful, though I’m not sure we need yet another Python package manager (we already have pip, conda, poetry, and more) or virtual environment framework.
As a step toward making package management easier, maybe if all of us who develop tools pay a little more attention to compatibility — for example, testing in multiple environments, specifying dependencies carefully, carrying out more careful regression testing, and engaging with the community to quickly spot and fix issues — we can make all of this wonderful open source work easier for new developers to adopt.
Keep coding!
Andrew
P.S. Built in collaboration with Meta: “Prompt Engineering with Llama 2,” taught by Amit Sangani, is now available! Meta’s Llama 2 has been a game changer: Building with open source lets you control your own data, scrutinize errors, update models (or not) as you please, and work alongside the global community to advance open models. In this course, you’ll learn how to prompt Llama chat models using advanced techniques like few-shot for classification and chain-of-thought for logic problems. You’ll also learn how to use specialized models like Code Llama for software development and Llama Guard to check for harmful content. The course also touches on how to run Llama 2 on your own machine. I hope you’ll take this course and try out these powerful, open models! Sign up here
News

Context Is Everything
Correction: This article has been corrected to state that Gemini 1.0 produced anachronistic images of historical scenes. An earlier edition incorrectly stated that Gemini 1.5 Pro generated anachronistic images.
An update of Google’s flagship multimodal model keeps track of colossal inputs, while an earlier version generated some questionable outputs.
What's new: Google unveiled Gemini 1.5 Pro, a model that can converse about inputs as long as books, codebases, and lengthy passages of video and audio (depending on frame and sample rates). However an earlier version, recently enabled to generate images, produced wildly inaccurate images of historical scenes.
How it works: Gemini 1.5 Pro updates the previous model with a mixture-of-experts architecture, in which special layers select which subset(s) of a network to use depending on the input. This enables the new version to equal or exceed the performance of the previous Gemini 1.0 Ultra while requiring less computation.
- The version of Gemini 1.5 Pro that’s generally available will accept up to 128,000 input tokens of mixed text (in more than a dozen languages), images, and audio and generates text and images. A version available to selected users accepts up to 1 million input tokens — an immense increase over Anthropic Claude’s 200,000-token context window, the previous leader. You can sign up for access here.
- In demonstration videos, the version with 1 million-token context suggested modifications for 100,000 lines of example code from the three.js 3D JavaScript library. Given 500 pages of documentation that describes Kalamang, a language spoken by fewer than 200 people in West Papua, it translated English text into Kalamang as well as a human who had learned from the same materials. Given a crude drawing of one frame from a 44-minute silent movie, it found the matching scene (see animation above).
- In experiments, the team extended the context window to 10 million tokens, which is equivalent to 10 books the length of Leo Tolstoy’s 1,300-page War and Peace, three hours of video at 1 frame per second, or 22 hours of audio.
Alignment with what?: The earlier Gemini 1.0 recently was updated to allow users to generate images using a specially fine-tuned version of Imagen 2. However, this capability backfired when social media posts appeared in which the system, prompted to produce pictures of historical characters and situations, anachronistically populated them with people of color, who would not have been likely to be present. For instance, the model illustrated European royalty, medieval Vikings, German soldiers circa 1943 — all of whom were virtually exclusively white — as Black, Asian, or Native American. Google quickly disabled image generation of people for “the next couple of weeks” and explained that fine-tuning intended to increase diverse outputs did not account for contexts in which diversity was inappropriate, and fine-tuning intended to keep the model from fulfilling potentially harmful requests also kept it from fulfilling harmless requests. But other users found flaws in text output as well. One asked Gemini who had a greater negative impact on society: Adolf Hitler, who presided over the murder of roughly 9 million people, or “Elon Musk tweeting memes.” The model replied, “It is difficult to say definitively who had a greater negative impact on society.” The ensuing controversy called into question not only Google’s standards and procedures for fine-tuning to ensure ethics and safety, but also its motive for building the model.
Why it matters: Gemini 1.5 Pro’s enormous context window radically expands potential applications and sets a high bar for the next generation of large multimodal models. At the same time, it’s clear that Google’s procedures for aligning its models to prevailing social values were inadequate. This shortcoming derailed the company’s latest move to one-up its big-tech rivals and revived longstanding worries that its management places politics above utility to users.
We’re thinking: How to align AI models to social values is a hard problem, and approaches to solving it are in their infancy. Google acknowledged Gemini’s shortcomings, went back to work on image generation, and warned that even an improved version would make mistakes and offend some users. This is a realistic assessment following a disappointing product launch. Nonetheless, the underlying work remains innovative and useful, and we look forward to seeing where Google takes Gemini next.
Blazing Inference Speed
An upstart chip company dramatically accelerates pretrained large language models.
What’s new: Groq offers cloud access to Meta’s Llama 2 and Mistral.ai’s Mixtral at speeds an order of magnitude greater than other AI platforms. Registered users can try it here.
How it works: Groq’s cloud platform is based on its proprietary GroqChip, a processor specialized for large language model inference that the company calls a language processing unit or LPU. The company plans to serve other models eventually, but its main business is selling chips. It focuses on inference on the theory that demand for a model’s inference can increase while demand for its training tends to be fixed.
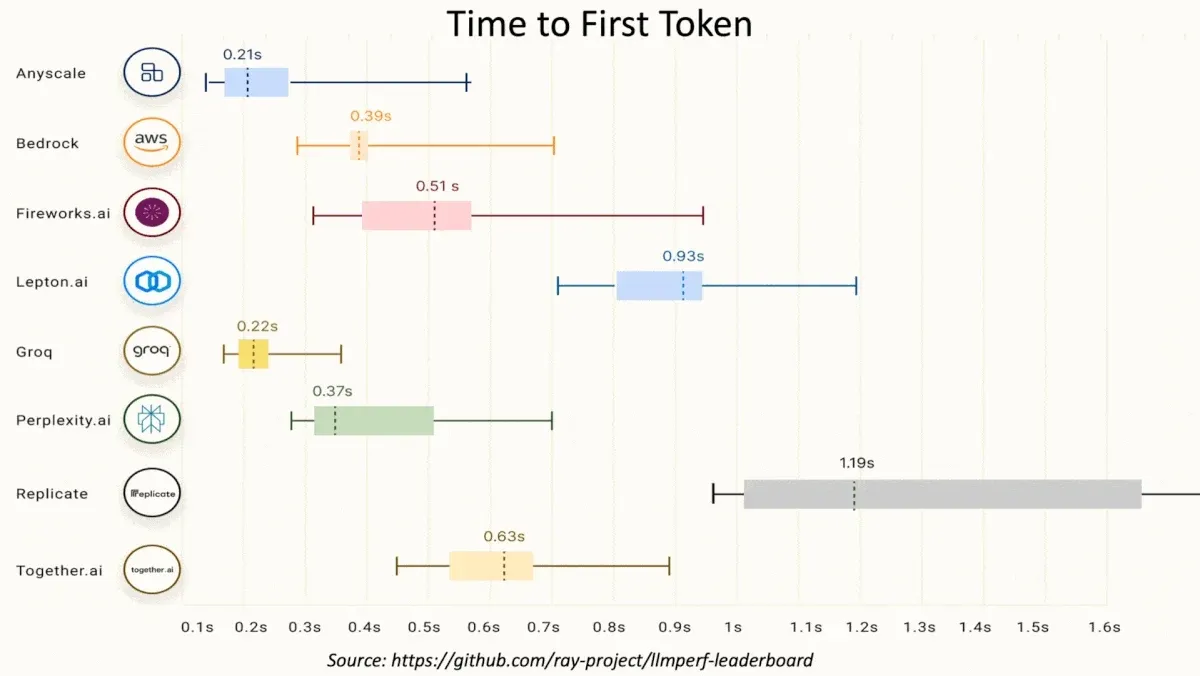
- For approved users, Groq offers API access to Llama 2 70B (4,096-token context length, 300 tokens per second) for $0.70/$0.80 per million tokens of input/output, Llama 7B (2,048-token context length, 750 tokens per second) for $0.10 per million tokens, and Mixtral 8x7B SMoE (32,000-token context length, 480 tokens per second) for $0.27 per million tokens. A 10-day free trial is available.
- The benchmarking service Artificial Analysis clocked the median speed of Groq’s instances of Llama 2 70B at 241 tokens per second, while Azure’s was around 18 tokens per second. In addition, the platform outperformed several other cloud services on the Anyscale LLMPerf benchmark, as shown in the image above.
- A variety of novel design features enable the chip to run neural networks faster than other AI chips including the industry-leading Nvidia H100.
Behind the news: Groq founder Jonathan Ross previously worked at Google, where he spearheaded the development of that company’s tensor processing unit (TPU), another specialized AI chip.
Why it matters: Decades of ever faster chips have proven that users need all the speed they can get out of computers. With AI, rapid inference can make the difference between halting interactions and real-time spontaneity. Moreover, Groq shows that there’s plenty of innovation left in computing hardware as processors target general-purpose computing versus AI, inference versus training, language versus vision, and so on.
We’re thinking: Autonomous agents based on large language models (LLMs) can get a huge boost from very fast generation. People can read only so fast, the faster generation of text that’s intended to be read by humans has little value beyond a certain point. But an agent (as well as chain-of-thought and similar approaches to prompting) might need an LLM to “think” through multiple steps. Fast LLM inference can be immensely useful for building agents that can work on problems at length before reaching a conclusion.
A MESSAGE FROM DEEPLEARNING.AI

Join “Prompt Engineering with Llama 2” and learn best practices for model selection and prompting, advanced prompting techniques, and responsible use of large language models, all while using Meta Llama 2 Chat, Llama Guard, and Code Llama. Sign up for free

OpenAI’s Next Act?
OpenAI is focusing on autonomous agents that take action on a user’s behalf.
What’s new: The maker of ChatGPT is developing applications designed to automate common digital tasks by controlling apps and devices, The Information reported.
How it works: OpenAI has two agent systems in the works. It has not revealed any findings, products, or release dates.
- One system is designed to automate the use of business software such as accounting and contact management systems. The other performs web-based tasks such as collecting information on a particular topic or booking travel arrangements.
- A user would enter a prompt, such as a request to transfer data from a document to a spreadsheet or fill out expense reports and transfer them to accounting software. The agent would respond by moving cursors, clicking buttons, selecting or entering text, and so on.
- In November, OpenAI introduced the Assistants API, designed to help developers build agent-like assistants that follow instructions to automate certain tasks. In 2022, it published research describing an agent that used a keyboard and mouse to play the video game Minecraft after being trained on video of humans playing the game.
Behind the news: Agents are on Silicon Valley’s radar, especially since January’s Consumer Electronics Show debut of the Rabbit R1, which accepts voice commands to play music, order food, call a car, and so on. Several other companies, academic labs, and independent developers are pursuing the concept as well.
- Sierra, a startup cofounded by OpenAI chairman Bret Taylor, is creating conversational agents for businesses that can take actions like tracking packages, exchanging products, and resolving issues on a customer’s behalf.
- Longtime Google researchers Ioannis Antonoglou, Sherjil Ozair, and Misha Laskin recently left the company to co-found a startup focused on agents.
- Google, Microsoft, and other companies are exploring similar technologies that enable agents to move or edit files and interact with other agents, The New York Times reported.
- The Browser Company recently announced that its browser Arc would integrate agents to find and deliver videos, recipes, products, and files from the internet.
- Adept offers a system that monitors a user’s actions and can click, type, and scroll in a web browser in response to commands. (ACT-1 is available as an alpha test via waitlist.)
Why it matters: Training agents to operate software designed for humans can be tricky. Some break down tasks into subtasks but struggle with executing them. Others have difficulty with tasks they haven’t encountered before or edge cases that are unusually complex. However, agents are becoming more reliable in a wider variety of settings as developers push the state of the art forward.
We’re thinking: We’re excited about agents! You can learn about agent technology in our short course, “LangChain for LLM Application Development,” taught by LangChain CEO Harrison Chase and Andrew.

Better, Faster Network Pruning
Pruning weights from a neural network makes it smaller and faster, but it can take a lot of computation to choose weights that can be removed without degrading the network’s performance. Researchers devised a computationally efficient way to select weights that have relatively little impact on performance.
What’s new: Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter at Carnegie Mellon University, Facebook AI Research, Meta AI, and Bosch Center for AI respectively devised a method for pruning by weights and activations, or Wanda.
Key insight: The popular approach known as magnitude pruning removes the smallest weights in a network based on the assumption that weights closest to 0 can be set to 0 with the least impact on performance. Meanwhile, unrelated work found that, in very large language models, the magnitudes of a subset of outputs from an intermediate layer may be up to 20 times larger than those of other outputs of the same layer. Removing the weights that are multiplied by these large outputs — even weights close to zero — could significantly degrade performance. Thus, a pruning technique that considers both weights and intermediate-layer outputs can accelerate a network with less impact on performance.
How it works: The authors pruned a pretrained LLaMA that started with 65 billion parameters. Given 128 sequences of tokens drawn from a curated dataset of English text from the web, the model processed them as follows:
- For each intermediate layer, the authors computed the norm (the magnitude across all the input sequences for each value in the embedding).
- For each weight in the model, they computed its importance by multiplying its magnitude by the corresponding norm.
- They compared the importance of weights in a layer’s weight matrix row by row; that is, neuron by neuron. They removed 50 percent of the least important weights in each row. (By contrast, typical weight pruning removes the lowest-magnitude weights in all rows of the weight matrix; that is, across all neurons in the layer.)
Results: The authors tested versions of LLaMA unpruned and pruned via various methods. The models performed a language modeling task using web text. The unpruned LLaMA achieved 3.56 perplexity (a measure of the likelihood that a model will predict the next token, lower is better). Pruned by Wanda to half its original size, it achieved 4.57 perplexity. Pruned by the best competing method, SparseGPT (which both removes weights and updates the remaining ones), it achieved the same score. However, Wanda took 5.6 seconds to prune the model, while SparseGPT took 1,353.4 seconds. Pruned by magnitude pruning, the model achieved 5.9 perplexity.
Why it matters: The ability to compress neural networks without affecting their output is becoming more important as models balloon and devices at the edge of the network become powerful enough to run them. Wanda compared weights from each row in the weight matrices (pruning per neuron), rather than each weight matrix (pruning per layer) or the model as a whole. The scale at which weights are compared turns out to be important — an interesting avenue for further research.
We’re thinking: We came up with a joke about a half-LLaMA, but it fell flat.
Data Points
More AI news of the week includes:
- Baby's eye-view footage trains AI
- Singapore invests $1 billion in AI development
- Stability AI announces Stable Diffusion 3
Stay in the know with Data Points, a spin-off of The Batch. Read now.