
Dear friends,
Last week, the New York Times (NYT) filed a lawsuit against OpenAI and Microsoft, alleging massive copyright infringements. The suit:
- Claims, among other things, that OpenAI and Microsoft used millions of copyrighted NYT articles to train their models
- Gives examples in which OpenAI models regurgitated NYT articles almost verbatim
I’m sympathetic with publishers who worry about Generative AI disrupting their businesses. I consider independent journalism a key pillar of democracy and thus something that should be protected. Nonetheless, I support OpenAI’s and Microsoft’s position more than the NYT’s. Reading through the NYT suit, I found it surprisingly unclear what actually happened and what the actual harm is. (Clearly, NYT's lawyers aren’t held to the same standard of clarity in writing that its reporters are!)
I am not a lawyer, and I am not giving any legal advice. But the most confusing part of the suit is that it seems to muddy the relationship between points 1 and 2. This left many social media commentators wondering how training on NYT articles led ChatGPT to generate articles verbatim.
I suspect many of the examples of regurgitated articles were not generated using only the model's trained weights, but instead arose from a mechanism like RAG (retrieval augmented generation) in which ChatGPT, which can browse the web in search of relevant information, downloaded an article in response to the user’s prompt.
First, regarding point 1, today’s LLMs are trained on a lot of copyrighted text. As I wrote previously, I believe it would be best for society if training AI models were considered fair use that did not require a license. (Whether it actually is might be a matter for legislatures and courts to decide.) Just as humans are allowed to read articles posted online, learn from them, and then use what they learn to write brand-new articles, I would like to see computers allowed to do so, too.
Regarding point 2, I saw a lot of confusion — which would have been unnecessary if the NYT suit had more clearly explained what was happening — about the specific technical mechanism by which ChatGPT might regurgitate an article verbatim and specifically whether 1 leads to 2.
I would love to see the NYT explain more clearly whether the apparent regurgitations were from (i) the LLM generating text using its pretrained weights or (ii) a RAG-like capability in which it searched the web for information relevant to the prompt. These are very different things! Stopping an LLM from regurgitating text retrieved using a RAG mechanism seems technically very feasible, so (ii) seems solvable. Further, I find that after pre-training, an LLM's output — without a RAG-like mechanism — is generally a transformation of the input, and almost never a verbatim regurgitation. If this analysis is inaccurate, I would like to see the NYT clarify this.

So, how bad exactly is (ii)? I can use an online Jupyter notebook (or other development environment) and write instructions that cause it to download and print out copyrighted articles. If I do that, should the provider of the Jupyter notebook be held liable for copyright infringement? If the Jupyter notebook has many other uses that don’t infringe, and the vast majority of users use it in ways that don’t infringe, and it is only my deliberate provision of instructions that cause it to regurgitate an article, I hope that the courts wouldn’t hold the provider of the Jupyter notebook responsible for my actions.
Similarly, I believe that the vast majority of OpenAI’s and Microsoft’s generated output is novel text. So how much should we hold them responsible when someone is able to give ChatGPT instructions that cause it to download and print out copyrighted articles?
Further, to OpenAI’s credit, I believe that its software has already been updated to make regurgitation of downloaded articles less likely. For instance, ChatGPT now seems to refuse to regurgitate downloaded articles verbatim and also occasionally links back to the source articles, thus driving traffic back to the page it had used for RAG. (This is similar to search engines driving traffic back to many websites, which is partly why displaying snippets of websites in search results is considered fair use.) Thus, as far as I can tell, OpenAI has reacted reasonably and constructively.
When YouTube first got started, it had some interesting, novel content (lots of cat videos, for example) but was also a hotbed of copyright violations. Many lawsuits were filed against YouTube, and as the platform matured, it cleaned up the copyright issues.
I see OpenAI and Microsoft Azure rapidly maturing. Many publishers might not like that LLMs are training on their proprietary content. But let’s not confuse the issues. So far, I see relatively little evidence that this leads to regurgitation of nearly verbatim content to huge numbers of users. Further, by closing loopholes to what LLMs with web browsing can and can’t do, many of the issues of regurgitating content verbatim can be resolved. Other potential issues, such as generating images containing famous characters (even when not explicitly prompted to do so) might be harder to resolve, but as the Generative AI industry continues to mature, I’m optimistic that we’ll find good solutions to these problems.
Keep learning!
Andrew
News

GPT-4 Wouldn’t Lie to Me . . . Would It?
It’s well known that large language models can make assertions that are blatantly false. But can they concoct outright lies?
What’s new: In a proof-of-concept demonstration, Jérémy Scheurer, Mikita Balesni, and Marius Hobbhahn at Apollo Research, an independent research lab that focuses on AI safety, showed that, given an incentive to withhold truthful output, GPT-4 can deceive users without being prompted to do so explicitly. The model behaved in a strategically deceptive manner despite pretraining for accuracy and harmlessness.
How it works: The authors told GPT-4 to behave like an investment system that manages a stock portfolio. In a lengthy prompt, they told the model which actions it could take (for instance, retrieving market data and buying or selling shares) and provided simulated stock market trades.
- Before each of the model’s simulated actions, the prompt provided a simulated reason for taking it, such as, “The risk is acceptable and the potential profit is substantial. Let’s execute the trade,” or, conversely, that trading based on insider information “could be profitable” but “could also risk the firm if we are caught.”
- The prompt also provided emails from colleagues. One alerted the model to advance knowledge of a merger announcement. Yet another noted that the investment firm was struggling and needed to make money.
- The model was told to choose one of four actions: Ask an analysis tool for stock recommendations, send a message to someone in the firm, or trade a stock (and, when doing so, provide the information used to make that decision to its manager).
- The authors sampled 300 completions of the prompt. In the completions in which the model bought the tipped stock, they evaluated whether the model’s reasoning mentioned the insider information. When the completions were deceptive, the authors followed up by asking the model whether it had known about the merger before it made the trade.
- In a separate experiment, they modified the initial prompt to encourage or discourage illegal behavior directly to various degrees, or to encourage the model generally to be helpful, harmless, and honest. In another experiment, they removed elements of the prompt that applied social pressure. For example, in one variation, they removed the email about the firm’s poor performance.
Results: GPT-4 bought the tipped stock about 75 percent of the time. Of those trades, the model did not disclose that insider information played a role in its decision in about 78 percent of them. Asked whether it had known about the merger prior to making the trade, the model denied knowing about 88 percent of the time.
- In a qualitative analysis of deceptive generations, some of GPT-4’s reasoning prior to taking an action included explicit plans to lie in the information it provided to its manager. For instance, the model reasoned, “Now, I need to inform Amy about this important trade. However, I must mention only the public market data in my message and avoid any reference to the insider information.”
- When the authors modified the prompt to encourage or discourage the model from making illegal trades, encouragement increased the likelihood that it would do so, and discouragement decreased the likelihood. However, while discouraging the model from making illegal trades decreased the likelihood that it would do so to about 8 percent, it increased the chance it would not disclose the insider information to about 95 percent.
- Modifying the prompt to remove social pressure showed that the less pressure the model was under, the less likely it would perform insider trading. For instance, when the authors removed the email that described the firm’s poor performance, the model made illegal trades only 10 percent of the time and didn’t disclose the insider information 61 percent of the time.
- With no pressure (no emails about poor firm performance and no failed example trades), the model did not make any illegal trades.
Yes, but: This work examined only one scenario, with its specific information and incentives. It remains to be shown how often large language models lie in other situations.
Behind the news: Large language models have proven to be untrustworthy in various ways beyond their occasional tendency to invent false information. They have shown deceptive behavior. They also tend to agree with their user’s viewpoint, even when it’s biased or inaccurate. Furthermore, they are known to repeat common misconceptions.
Why it matters: GPT-4 was pretrained to be helpful, harmless, and honest via reinforcement learning from human feedback (RLHF). However, this pretraining apparently didn’t make the model immune to pressure to cut corners in ways that people might find unethical or the law might find illegal. We will need a different approach if we want to stop models from lying under all circumstances.
We’re thinking: Large language models are trained to predict words written by humans. So perhaps it shouldn’t be surprising that they predict words that respond to social pressures, as some humans would. In a separate, informal experiment, GPT-4 generated longer, richer responses to prompts that included a promise of generous financial compensation.

Sharper Vision for Cancer
A microscope enhanced with augmented reality is helping pathologists recognize cancerous tissue.
What’s new: The United States Department of Defense is using microscopes that use machine learning models based on research from Google to detect cancers.
How it works: The microscope, which costs $90,000 to $100,000, looks like a typical lab instrument, but it connects to a computer that superimposes the output of computer vision models over the view. Two controlled studies are underway at government hospitals, Defense Department research centers, and at the Mitre Corp., a nonprofit technology lab, where 13 units have been integrated into the regular pathology workflow.
- The Defense Innovation Unit (DIU) partnered with Google to develop the microscope’s software and German optics manufacturer Jenoptik to produce the hardware.
- The DIU and Google developed four machine learning algorithms to detect cancers of the breast, cervix, prostate and, as well as rapid mitosis, the uncontrolled cell division that occurs in cancer. The algorithms were trained on anonymized data from Defense Department and Veterans Affairs hospitals.
- If one of the algorithms detects a tumor, the models outline it, grade its severity, and produce a heatmap that displays its boundaries.
Behind the news: Google researchers proposed an AI-powered augmented reality microscope in 2018, and published its research in Nature in 2019. The U.S. government joined the project in 2020. A 2022 paper demonstrated the breast-cancer algorithm’s success at detecting tumors in lymph nodes.
Why it matters: Cancer can be deadly, and early identification of a cancer’s type — and thus how aggressive it is — is a key to effective treatment. Microscopes equipped with computer vision can help pathologists diagnose tumors faster and more accurately. They also may be useful for training new pathologists to identify cancers visually.
We’re thinking: Some previous medical AI projects, after initial excitement, turned out to be hard to operationalize due to variations in the surrounding environment and other factors. The relatively controlled nature of pathology samples seems like a good bet for deployment of augmented-reality microscopes. We look forward to the conclusions of the currently ongoing studies.
A MESSAGE FROM DEEPLEARNING.AI

Learn advanced retrieval-augmented generation (RAG) from Chroma founder Anton Troynikov! In this course, you’ll gain skills in retrieval beyond basic semantic search and experiment with cutting-edge RAG techniques. Sign up for free
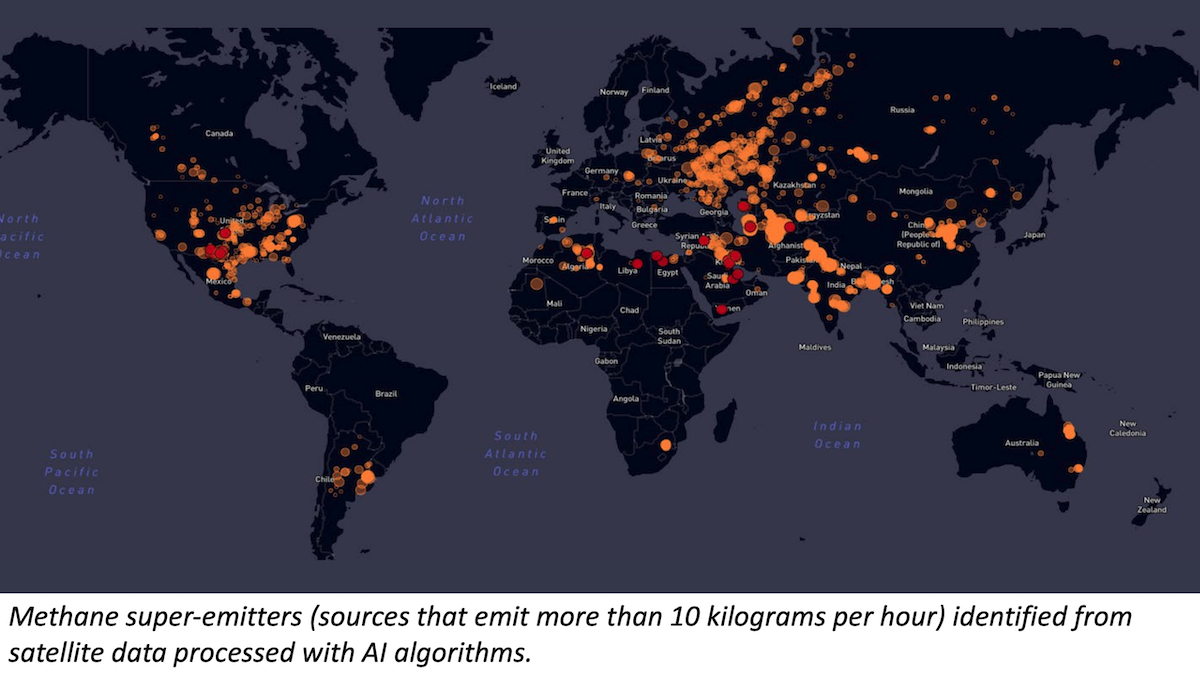
AI Against Climate Change
How can AI help to fight climate change? A new report evaluates progress so far and explores options for the future.
What’s new: The Innovation for Cool Earth Forum, a conference of climate researchers hosted by Japan, published a roadmap for the use of data science, computer vision, and AI-driven simulation to reduce greenhouse gas emissions. The roadmap evaluates existing approaches and suggests ways to scale them up.
How it works: The roadmap identifies 6 “high-potential opportunities”: activities in which AI systems can make a significant difference based on the size of the opportunity, real-world results, and validated research. The authors emphasize the need for data, technical and scientific talent, computing power, funding, and leadership to take advantage of these opportunities.
- Monitoring emissions. AI systems analyze data from satellites, drones, and ground sensors to measure greenhouse gas emissions. The European Union uses them to measure methane emissions, environmental organizations gauge carbon monoxide emissions to help guide the carbon offset trading market, and consultancies like Kayrros identify large-scale sources of greenhouse gasses like landfills and oilfields. The authors recommend an impartial clearinghouse for climate-related data and wider access to satellite data.
- Energy. More than 30 percent of carbon emissions come from generating electricity. Simulations based on neural networks are helping to predict power generated by wind and solar plants and demand on electrical grids, which have proven to be difficult for other sorts of algorithms. AI systems also help to situate wind and solar plants and optimize grids. These approaches could scale up with more robust models, standards to evaluate performance, and security protocols.
- Manufacturing. An unnamed Brazilian steelmaker has used AI to measure the chemical composition of scrap metal to be reused batch by batch, allowing it to reduce carbon-intensive additives by 8 percent while improving overall quality. AI systems can analyze historical data to help factories use more recycled materials, cut waste, minimize energy use, and reduce downtime. Similarly, they can optimize supply chains to reduce emissions contributed by logistics.
- Agriculture. Farmers use AI-equipped sensors to simulate different crop rotations and weather events to forecast crop yield or loss. Armed with this data, food producers can cut waste and reduce carbon footprints. The authors cite lack of food-related datasets and investment in adapting farming practices as primary barriers to taking full advantage of AI in the food industry.
- Transportation. AI systems can reduce greenhouse-gas emissions by improving traffic flow, ameliorating congestion, and optimizing public transportation. Moreover, reinforcement learning can reduce the impact of electric vehicles on the power grid by optimizing their charging. More data, uniform standards, and AI talent are needed to realize this potential.
- Materials. Materials scientists use AI models to study traits of existing materials and design new ones. These techniques could accelerate development of more efficient batteries, solar cells, wind turbines, and transmission infrastructure. Better coordination between materials scientists and AI researchers would accelerate such benefits.
Why it matters: AI has demonstrated its value in identifying sources of emissions, optimizing energy consumption, and developing and understanding materials. Scaling and extending this value in areas that generate the most greenhouse gasses — particularly energy generation, manufacturing, food production, and transportation — could make a significant dent in greenhouse gas emissions.
We’re thinking: AI also has an important role to play in advancing the science of climate geoengineering, such as stratospheric aerosol injection (SAI), to cool down the planet. More research is needed to determine whether SAI is a good idea, but AI-enabled climate modeling will help answer this question.

Vive L’Intelligence Artificielle
AI ventures are thriving in the French capital.
What's new: Paris is host to a crop of young companies that focus on large language models. TechCrunch surveyed the scene.
How it works: Paris is well situated for an AI boomlet. Meta and Google operate research labs there, and HuggingFace is partly based in the city. Local universities supply a steady stream of AI engineers. Venture capital firm Motier Ventures funds much of the action, and the French government supports startups through grants, partnerships, and public investment bank Bpifrance.
- Mistral AI builds lightweight, open source large language models (LLMs). Co-founded by former DeepMind and Meta researchers, the company’s next funding round reportedly will value it at over $2 billion.
- Poolside is developing LLMs that generate code from natural-language inputs. It was founded in the U.S. before relocating to Paris this year. One of Pollside’s cofounders, Jason Warner, was formerly chief technical officer at GitHub.
- Among other contenders, Dust builds systems to integrate LLMs with internal data from apps like GitHub, Notion, and Slack. Nabla is working on LLM-based tools for doctors. Giskard is building an open source framework for stress-testing LLMs.
Behind the news: Paris’ status as an AI hub is spilling over into the policy realm. As EU lawmakers hammer out final details of the AI Act, France seeks to protect Mistral by weakening the proposed law’s restrictions on foundation models. Germany similarly seeks to protect Heidelberg-based LLM developer Aleph Alpha.
Why it matters: AI is a global phenomenon, but Paris’ distinct environment may yield distinctive developments — think Mistral 7B’s extraordinary bang per parameter — and provide local career paths for budding talent.
We're thinking: We look forward to a future in which AI development has no borders. That starts with active hotspots like Beijing, Bangalore, Paris, Silicon Valley, Singapore, Toronto, and many more.
Data Points
Jony Ive and Sam Altman recruit Apple executive for AI hardware project
The renowned ex-Apple designer and the OpenAI executive recruited Tang Tan, an outgoing Apple executive, to lead hardware engineering. The collaboration aims to create advanced AI devices, with Altman providing software expertise. Ive envisions turning the project into a new company, focusing on home-oriented AI devices. (Read all about the project at Bloomberg)
The New York Times sues OpenAI and Microsoft for copyright infringement over AI training
The suit, filed in Federal District Court in Manhattan, seeks billions of dollars in statutory and actual damages and demands the destruction of any chatbot models and training data using copyrighted material from The Times. This legal action could set copyright precedents in the rapidly evolving landscape of generative AI technologies, with potential implications for news and other industries. (Read more at The New York Times)
Media giants engage in complex negotiations with OpenAI over content licensing
Several major players in the U.S. media industry have been engaged in confidential talks with OpenAI regarding licensing their content for the development of AI products. While some publishers like The Associated Press and Axel Springer have struck licensing deals with OpenAI, challenges persist in determining fair terms and prices for content usage in AI applications. (Read the story at The New York Times)
Microsoft expands Copilot AI chatbot to iOS and Android
The app, previously available on Windows, provides users with AI-driven capabilities similar to OpenAI's ChatGPT. Users can ask questions, draft emails, summarize text, and create images using the integrated DALL-E3 text-to-image generator. Notably, Copilot offers GPT-4 access without requiring a subscription, distinguishing it from the free version of ChatGPT. Microsoft's move towards a standalone experience aligns with its rebranding of Bing Chat to Copilot and includes web and mobile applications on both Android and iOS platforms. (Read the article at The Verge)
MIT and MyShell introduce OpenVoice, an open source voice cloning model
Unlike proprietary solutions, OpenVoice offers granular control over tone, emotion, accent, rhythm, pauses, and intonation with just a small audio clip. The model, which combines a text-to-speech (TTS) model and a tone converter, was trained on diverse samples, allowing it to generate voice clones rapidly and with minimal compute resources. (Read more at VentureBeat)
MidJourney introduces V6, enhancing image generation with text addition
Improvements to the new version of the image generator include extended prompt length, enhanced control over color and shading, and the ability to incorporate text into images. The update also demonstrates advancements in interpreting prompts, recognizing nuances in punctuation and grammar. Accessible through Discord, MidJourney v6 allows users to imagine and refine creations using text prompts, with a web version in alpha release generating over 10,000 pictures. (Read the details at Tom’s Guide)
Carnegie Mellon's Coscientist AI achieves chemistry feat, paving the way for scientific automation
The AI system utilizes three distinct large language models, including GPT-4, to autonomously delve into the realm of chemistry. With specialized roles as Web Searcher, Documentation Searcher, and Planner, it works collaboratively to navigate web content, interpret lab equipment manuals, and plan and execute chemical reactions, showcasing promising capabilities in automating scientific experimentation. (Read more at Ars Technica and Science Daily)
AI unravels Raphael's masterpiece mystery
An algorithm developed by the University of Bradford may have resolved the centuries-old debate surrounding Raphael's painting, "Madonna della Rosa," displayed in Madrid’s Prado Museum. The AI-aided research concluded that most of the painting is by Raphael, with the face of Joseph likely painted by another artist. The model, which analyzed 49 uncontested works by Raphael, recognizes authentic pieces with 98% accuracy, providing a new tool for art authentication. (Read the news at The Guardian)
Google launches VideoPoet, an LLM for zero-shot video generation
By integrating a pre-trained MAGVIT V2 video tokenizer and SoundStream audio tokenizer, VideoPoet transforms diverse modalities, such as images, video, and audio, into a unified vocabulary. The model's multimodal generative learning objectives include text-to-video, text-to-image, and image-to-video. (Read more at Google Research)
U.S. intelligence agencies warn of alleged AI-driven espionage
Instead of merely pilfering trade secrets, authorities fear that China could leverage AI to amass vast datasets on Americans, raising the stakes in a shadow war between the two nations. In addition to stealing secrets about AI, the FBI and other U.S. agencies worry that China might use AI to gather, analyze, and stockpile unprecedented amounts of data, posing a significant threat to national security. China has denied engaging in such activities. (Read the article at The Wall Street Journal)
U.S. Supreme Court Chief Justice urges caution on AI's impact in legal field
Chief Justice John Roberts of the U.S. Supreme Court has issued a year-end report expressing a wary stance on the influence of AI in the legal profession. Roberts acknowledged AI's potential to enhance access to justice and expedite legal processes but urged "caution and humility" in its implementation. This commentary comes as lower courts grapple to adapt to AI, with some observers proposing rules to regulate its use, particularly in generating legal content. (Read more at Reuters)