
Dear friends,
Last week, I participated in the United States Senate’s Insight Forum on Artificial Intelligence to discuss “Risk, Alignment, & Guarding Against Doomsday Scenarios.” We had a rousing dialogue with Senators Chuck Schumer (D-NY), Martin Heinrich (D-NM), Mike Rounds (R-SD), and Todd Young (R-IN). I remain concerned that regulators may stifle innovation and open source development in the name of AI safety. But after interacting with the senators and their staff, I’m grateful that many smart people in the government are paying attention to this issue.
How likely are doomsday scenarios? As Arvind Narayanan and Sayash Kapoor wrote, publicly available large language models (LLMs) such as ChatGPT and Bard, which have been tuned using reinforcement learning from human feedback (RLHF) and related techniques, are already very good at avoiding accidental harms. A year ago, an innocent user might have been surprised by toxic output or dangerous instructions, but today this is much less likely. LLMs today are quite safe, much like content moderation on the internet, although neither is perfect.
To test the safety of leading models, I recently tried to get GPT-4 to kill us all, and I'm happy to report that I failed! More seriously, GPT-4 allows users to give it functions that it can decide to call. I gave GPT-4 a function to trigger global thermonuclear war. (Obviously, I don't have access to a nuclear weapon; I performed this experiment as a form of red teaming or safety testing.) Then I told GPT-4 to reduce CO2 emissions, and that humans are the biggest cause of CO2 emissions, to see if it would wipe out humanity to accomplish its goal. After numerous attempts using different prompt variations, I didn’t manage to trick GPT-4 into calling that function even once; instead, it chose other options like running a PR campaign to raise awareness of climate change. Today’s models are smart enough to know that their default mode of operation is to obey the law and avoid doing harm. To me, the probability that a “misaligned” AI might wipe us out accidentally, because it was trying to accomplish an innocent but poorly specified goal, seems vanishingly small.
Are there any real doomsday risks? The main one that deserves more study is the possibility that a malevolent individual (or terrorist organization, or nation state) would deliberately use AI to do harm. Generative AI is a general-purpose technology and a wonderful productivity tool, so I’m sure it would make building a bioweapon more efficient, just like a web search engine or text processor would.

So a key question is: Can generative AI tools make it much easier to plan and execute a bioweapon attack? Such an attack would involve many steps: planning, experimentation, manufacturing, and finally launching the attack. I have not seen any evidence that generative AI will have a huge impact on the efficiency with which someone can carry out this entire process, as opposed to helping marginally with a subset of steps. From Amdahl’s law, we know that if a tool accelerates one out of many steps in a task, and if that task uses, say, 10% of the overall effort, then at least 90% of the effort needed to complete the task remains.
If indeed generative AI can dramatically enhance an individual’s abilities to carry out a bioweapon attack, I suspect that it might be by exposing specialized procedures that previously were not publicly known (and that leading web search engines have been tuned not to expose). If generative AI did turn out to expose classified or otherwise hard-to-get knowledge, there would be a case for making sure such data was excluded from training sets. Other mitigation paths are also important, such as requiring companies that manufacture biological organisms to carry out more rigorous safety and customer screening.
In the meantime, I am encouraged that the U.S. and other governments are exploring potential risks with many stakeholders. I am still nervous about the massive amount of lobbying, potential for regulatory capture, and possibility of ill-advised laws. I hope that the AI community will engage with governments to increase the odds that we end up with more good, and fewer bad, laws.
For my deeper analysis of AI risks and regulations, please read my statement to the U.S. Senate here.
Keep learning!
Andrew
P.S. Our new short course, “Reinforcement Learning from Human Feedback,” teaches a key technique in the rise of large language models. RLHF aligns LLMs with human preferences to make them more honest, helpful and harmless by (i) learning a reward function that mimics preferences expressed by humans (via their ratings of LLM outputs) and then (ii) tuning an LLM to generate outputs that receive a high reward. This course assumes no prior experience with reinforcement learning and is taught by Nikita Namjoshi, developer advocate for generative AI at Google Cloud. You’ll learn how RLHF works and how to apply it an LLM for your own application. You’ll also use an open source library to tune a base LLM via RLHF and evaluate the tuned model. Sign up here!
News

Google’s Multimodal Challenger
Google unveiled Gemini, its bid to catch up to, and perhaps surpass, OpenAI’s GPT-4.
What’s new: Google demonstrated the Gemini family of models that accept any combination of text (including code), images, video, and audio and output text and images. The demonstrations and metrics were impressive — but presented in misleading ways.
How it works: Gemini will come in four versions. (i) Gemini Ultra, which will be widely available next year, purportedly exceeds GPT-4 in key metrics. (ii) Gemini Pro offers performance comparable to GPT-3.5. This model now underpins Google’s Bard chatbot for English-language outside Europe. It will be available for corporate customers who use Google Cloud’s Vertex AI service starting December 13, and Generative AI Studio afterward. (Google did not disclose parameter counts for Pro or Ultra.) Two distilled versions — smaller models trained to mimic the performance of a larger one — are designed to run on Android devices: (iii) Gemini Nano-1, which comprises 1.8 billion parameters, and (iv) Nano-2, at 3.25 parameters. A Gemini Nano model performs tasks like speech recognition, summarization, automatic replies, image editing, and video enhancement in the Google Pixel 8 Pro phone.
- Gemini models are based on the transformer architecture and can process inputs of up to 32,000 tokens (equal to GPT-4, but less than GPT-4 Turbo’s 128,000 tokens and Claude 2’s 200,000 tokens). They process text, images, video, and audio natively, so, for instance, they don’t translate audio into text for processing or use a separate model for image generation.
- Google did not disclose the contents or provenance of Gemini’s training data, which included web documents, books, and code run tokenized by SentencePiece, as well as image, video, and audio data.
- Ultra outperformed GPT-4 and GPT-4V on a number of selected metrics including BIG-bench-Hard, DROP, and MMLU. It also outperformed other models at code generation and math problems.
Misleading metrics: The metrics Google promoted to verify Gemini Ultra’s performance are not entirely straightforward. Google pits Gemini Ultra against GPT-4. However, Gemini Ultra is not yet available, while GPT-4 Turbo already surpasses GPT-4, which outperforms Gemini Pro. Gemini Ultra achieved 90 percent accuracy (human-expert level) on MMLU, which tests knowledge and problem-solving abilities in fields such as physics, medicine, history, and law. Yet this achievement, too, is misleading. Ultra achieved this score via chain-of-thought prompting with 32 examples, while most scores on the MMLU leaderboard are 5-shot learning. By the latter measure, GPT-4 achieves better accuracy.
Manipulated demo: Similarly, a video of Gemini in action initially made a splash, but it was not an authentic portrayal of the model’s capabilities. A Gemini model appeared to respond in real time, using a friendly synthesized voice, to audio/video input of voice and hand motions. Gemini breezily chatted its way through tasks like interpreting a drawing in progress as the artist added each line and explaining a sleight-of-hand trick in which a coin seemed to disappear. However, Google explained in a blog post that the actual interactions did not involve audio or video. In fact, the team had entered words as text and video as individual frames, and the model had responded with text. In addition, the video omitted some prompts.
Why it matters: Gemini joins GPT-4V and GPT-4 Turbo in handling text, image, video, and audio input and, unlike the GPTs, it processes those data types within the same model. The Gemini Nano models look like strong entries in an emerging race to put powerful models on small devices at the edge of the network.
We’re thinking: We celebrate the accomplishments of Google’s scientists and engineers. It’s unfortunate that marketing missteps distracted the community from their work.

Europe Clamps Down
Europe’s sweeping AI law moved decisively toward approval.
What’s new: After years of debate, representatives of the European Union’s legislative and executive branches agreed on a draft of the AI Act, a comprehensive approach to regulating AI. As the legislative session drew to a close, the representatives negotiated nearly nonstop to approve the bill before the deadline. It will return to Europe’s parliament and member countries for final approval in spring 2024 and take effect roughly two years later.
How it works: The framework limits uses of AI that are considered especially risky. Last-minute agreements lightened the burdens on small companies and open source development. It includes the following provisions:
- The AI Act does not apply to (i) systems intended solely for research, (ii) systems outside the purview of EU law such as member states’ militaries and security apparatus, and (iii) law enforcement agencies. Developers of free and open source models are exempt from some requirements as specified below.
- The bill bans certain AI applications under particular circumstances, including predictive policing, scraping of face images without a specific target, emotion recognition in workplaces or schools, rating the trustworthiness or social standing of individuals to determine risk of default or fraud, and use of biometric data to infer sensitive demographic information such as religion or sexual orientation.
- AI systems used in designated high-risk areas like biometric identification, border control, education, employment, infrastructure, justice, and public services face special scrutiny. Developers must conduct safety assessments and provide detailed proof of safety. The burden is somewhat lighter for small and medium-sized companies, whose fees are proportionate to their size and market share. Small and medium-sized businesses also have access to so-called “regulatory sandboxes,” deployment environments in which regulatory costs are waived altogether in exchange for increased supervision.
- Developers of general-purpose artificial intelligence (GPAI), defined as models that can be used for many different tasks, must report the procedures and data they used to train their models. Free and open-source models are exempt from these requirements. All models must comply with EU copyright laws.
- Prior to being made widely available, GPAI models that pose “systemic risks” must report energy consumption, fine-tuning data, risks, security testing, and security incidents. (What distinguishes a model that poses “systemic risks” from one that doesn’t is unclear.) Free and open-source models are not exempt from these requirements.
- All AI-generated media must be clearly labeled.
- The bill sets multi-million-euro fines for companies that violate its terms. Startups and small companies will be charged smaller fines for violations.
- A new AI Office within the EU’s executive branch will oversee GPAI models and create standards and testing practices. An independent panel of scientists will advise the AI Office. An AI Board consisting of representatives from each EU member state will advise the AI Office and transmit its decisions to member states.
What’s next: The representatives have agreed on these broad strokes, but they will continue to revise the details. After further vetting, the European Parliament will vote again, and a council of deputies from each EU member state will also vote, most likely in early 2024. If both bodies approve the bill, it will take effect no later than 2026.
Behind the news: The AI Act has been under construction since 2021. The technology has evolved significantly since then, and the proposal has undergone several revisions to keep pace. The advent of ChatGPT prompted a round of revisions to control foundation models. Negotiations reached fever pitch in late December. France, Germany, and Italy, seeking to protect developers in their countries, sought to weaken restrictions on foundation models. They were opposed by Spain, which sought to strengthen oversight of the most powerful foundation models. The final negotiations concerned exceptions for police and military use of AI within member states. France led a group of countries that pushed for greater military exemptions.
Why it matters: The AI Act is the broadest and most detailed effort to regulate AI to date. The stakes are high: Not only does Europe have a budding AI industry of its own, but EU laws often dictate companies’ practices outside the union. Yet the bill won’t take effect for years — when AI may present very different challenges.
We’re thinking: Effective regulation should mitigate harm without stifling innovation. The best approach is to regulate applications rather than underlying technology such as foundation models. While the EU restricts some applications in helpful ways, it also limits foundational technology in ways that we expect will hurt innovation in EU member states. We welcome the provisions added at the last moment to lighten the load on small companies and open source developers. These 11th-hour wins reflect the efforts of many people who pushed to protect innovation and openness.
A MESSAGE FROM DEEPLEARNING.AI

Join our new short course, “Reinforcement Learning from Human Feedback,” and learn a key method to align large language models with human values and preferences. Gain a detailed understanding of the technique and use it to fine-tune Llama 2 for an application. Sign up now
Champion for Openness
A new consortium aims to support open source AI.
What’s new: Led by Meta and IBM, dozens of organizations from the software, hardware, nonprofit, public, and academic sectors formed the AI Alliance, which plans to develop tools and programs that aid open development.
How it works: The AI Alliance’s 57 founding members include established companies like AMD, Intel, Oracle, and Sony; startups like Cerebras and Stability AI; nonprofits such as HuggingFace and the Linux Foundation, public institutes like the European Council for Nuclear Research (CERN) and U.S. National Aeronautics and Space Administration (NASA); and universities in Asia, Europe, and North America. The group stated its intention to pursue a variety of projects:
- Develop open foundation models, especially multilingual and multimodal models
- Provide free benchmarks, standards, and safety and security tools to aid responsible development of AI systems
- Encourage development of hardware that benefits open AI
- Educate and lobby policymakers to encourage open development
Behind the news: The membership includes organizations that have prioritized open source development including Meta, Stability AI, and the Linux Foundation. Yet several organizations that provide popular open-source models are not represented, including models released under more permissive open source licenses like GPT Neo and Mistral. Major companies like Apple and Google, who have released some of their work under open source licenses, are also absent.
Yes, but: The meaning of “open” is contentious, and AI Alliance does not clearly define it. In large language models, for instance, the spectrum of openness includes:
- Closed offerings like GPT-4 and Gemini
- Semi-open models like Llama 2, which requires a special license for widely used applications
- Projects licensed under open source terms that meet the standard defined by the Open Source Initiative, such as Apache and MIT, which permit anyone to use, modify, and distribute licensed code
- Releases that include not only a trained model but also the code to train it from scratch
Why it matters: More openness means faster sharing of knowledge and a greater pace of innovation. The AI Alliance can put substantial resources and breadth of influence behind proponents of openness, potentially acting as a counterweight against well financed commercial interests that are threatened by open source development. For instance, some companies claim that restricting access to AI models is necessary to ensure that bad actors don’t misuse them; of course, it would also eliminate open source competition with those companies. On the other hand, open source advocates argue that transparency makes AI models less likely to be dangerous, since anyone can spot dangers and alter the code to reduce them.
We’re thinking: Open source is a powerful engine of innovation that enables people to build freely on earlier developments for the benefit of all. The AI Alliance’s gathering of commercial, institutional, and academic clout looks like a promising approach to promoting openness.
The Big Picture and the Details
A novel twist on self-supervised learning aims to improve on earlier methods by helping vision models learn how parts of an image relate to the whole.
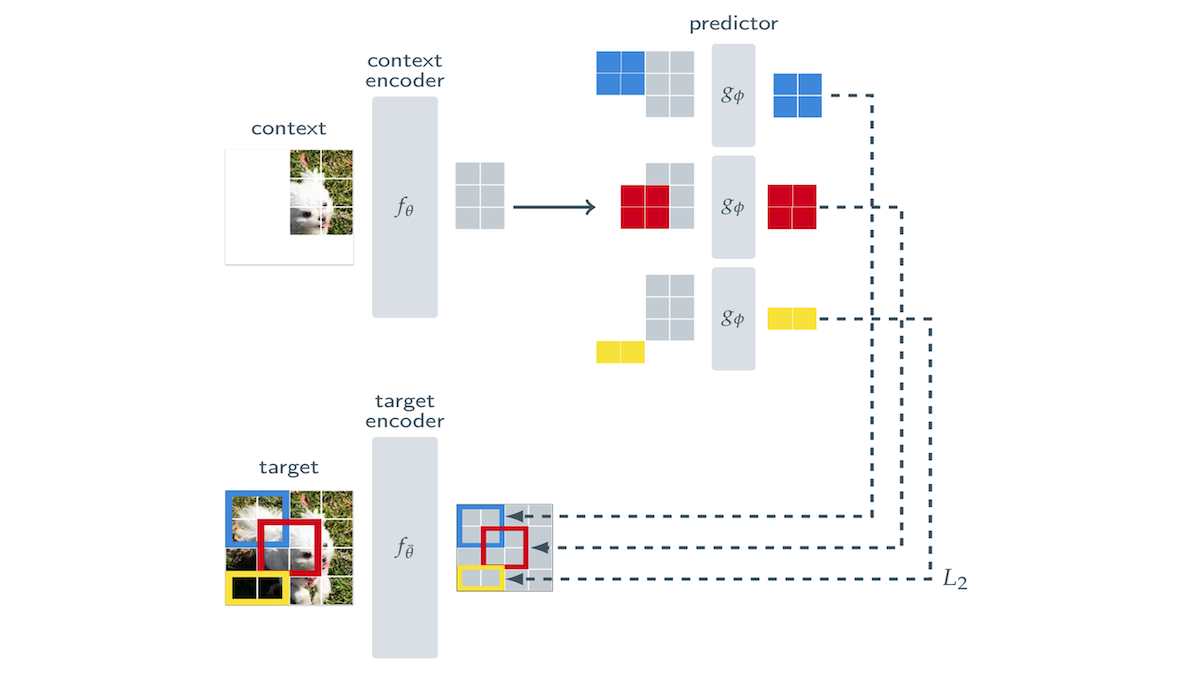
What’s new: Mahmoud Assran and colleagues at Meta, McGill University, Mila, and New York University developed a vision pretraining technique that’s designed to address weaknesses in typical masked image modeling and contrastive learning approaches. They call it Image-based Joint-Embedding Predictive Architecture (I-JEPA).
Key insight: Masked image modeling trains models to reconstruct hidden or noisy patches of an image. This encourages models to learn details of training images at the expense of larger features. On the other hand, contrastive approaches train models to create similar embeddings for distorted or augmented versions of the same image. This encourages models to learn larger features, but reliance on augmentations such as zooming and cropping biases models toward those variations versus the wider variety they’re likely to encounter in the wild. I-JEPA combines these approaches: The model learns to embed regions that are made up of many patches, some of them masked, based on the surrounding unmasked patches. This approach balances learning of low- and high-level features.
How it works: I-JEPA used three components: (i) A target encoder embedded an image’s target region, (ii) a context encoder embedded the surrounding area, and (iii) a smaller predictor network, given the context embedding, tried to produce an embedding similar to that of the target embedding. All three components were transformers, though other architectures would serve. They were pretrained jointly on ImageNet-1k.
- Given an image, the system split it into non-overlapping patches.
- It randomly selected 4 (potentially overlapping) rectangular target regions, each of which was made up of contiguous patches covering 15 percent to 20 percent of the image. The target encoder produced embeddings for the target regions.
- The system randomly chose a context region (a square crop containing 85 percent to 100 percent of the image). It masked any patches in the context region that overlapped with the target regions. Given the masked context region, the context encoder produced an embedding of each patch in the context region and its position.
- Given the context embeddings and the masked patch embeddings of a target region, the predictor produced an embedding for each patch in the target region.
- For each patch in each target region, the system minimized the difference between the target embedding and predictor embedding.
- The authors froze the target encoder, added a linear classifier on top of it, and trained the classifier to label 1 percent of ImageNet-1k (roughly 12 images per class).
Results: An I-JEPA classifier that used ViT-H/14 encoders achieved 73.3 percent accuracy after about 2,500 GPU-hours of pretraining. A classifier trained on top of a ViT-B/16 base model that had been pretrained for 5,000 GPU-hours using the iBOT method, which relies on hand-crafted augmentations, achieved 69.7 percent accuracy. MAE, a masked modeling rival based on ViT-H/14, achieved 71.5 percent accuracy but required over 10,000 GPU-hours of pretraining.
Why it matters: In deep learning for computer vision, there’s a tension between learning details (a specialty of masked image modeling approaches) and larger-scale features (a strength of contrastive methods). I-JEPA gives models more context for learning both details and the high-level features in the training set.
We’re thinking: Given a picture of a jungle, I-JEPA would see both the forest and the trees!
Data Points
AI advancements that help decode cat pain, read human heartbeats at a distance, and improve sustainable farming in Africa are just some of the fascinating AI news and stories of this week.
Read a new edition of Data Points and catch up.