
Dear friends,
One year since the launch of ChatGPT on November 30, 2022, it’s amazing how many large language models are available.
A year ago, ChatGPT was pretty much the only game in town for consumers (using a web user interface) who wanted to use a large language model (LLM), and a handful of models from OpenAI were the only options for developers (making API calls). Today, numerous open and closed source models are within easy reach. ChatGPT is the most popular way for consumers to chat with an LLM, but others abound, including Microsoft Bing, Google Bard, and offerings from startups such as Anthropic Claude, Inflection Pi, and perplexity.ai. There are also multiple options for developers, including APIs from Amazon Web Services, Azure, Cohere, Google Cloud, Hugging Face, OpenAI, and many others. The proliferation of options is exciting, and I hope it will continue!
For both consumer and developer use cases, open source models that you can host yourself, or even run locally on your laptop, are getting surprisingly good. For many applications, a good open source model can perform perhaps on par with the ChatGPT-3.5 of a year ago. The open source GPT4All and MLC, and closed source LM Studio (which has a very nice user interface) are making it easier than ever to run models locally. Running models locally used to be an esoteric act restricted to developers who were willing to struggle through complex installation and configuration processes, but it’s now becoming much more widely accessible.
I regularly use a chatbot as a thought partner. These days, I find myself using an LLM running on my laptop (which runs fairly quickly and guarantees privacy, since my data stays on my machine) about as often as a cloud-hosted one. I use a cloud-hosted model when I need a level of performance I can't get from a smaller, locally run, open source one. For instance, I often use GPT-4 for tricky problems and creative brainstorming.
While safety is important — we don't want LLMs to casually hand out harmful instructions — I find that offerings from most of the large providers have been tuned to be "safer" than I would like for some use cases. For example, sometimes a model has refused to answer basic questions about an activity that harms the environment, even though I was just trying to understand that activity and had no intention of committing that harm. There are now open source alternatives that are less aggressively safety-tuned that I can use responsibly for particular applications.
The wealth of alternatives is also a boon to developers. An emerging design pattern is to quickly build a prototype or initial product that delivers good performance by prompting an LLM, perhaps an expensive one like GPT-4. Later, if you need cheaper inference or better performance for a particular, narrowly scoped task, you can fine-tune one of the huge number of open source LLMs to your task. (Some developers reportedly are using data generated by GPT-4 for their own fine-tuning, although it’s not clear whether this violates its terms of use.)
In a year, we've gone from having essentially one viable option to having at least dozens. The explosion of options brings with it the cost of choosing a good one; hopefully our short courses on generative AI can help with that. If you have experience with open source LLMs that you’d like to share, or if you’ve found some models more useful than others in particular applications or situations, please let me know on social media!
Keep learning!
Andrew
P.S. Our new short course on advanced retrieval augmented generation (RAG) techniques is out! Taught by Jerry Liu and Anupam Datta of Llama Index and TruEra, it teaches retrieval techniques such as sentence-window retrieval and auto-merging retrieval (which organizes your document into a hierarchical tree structure to let you pick the most relevant chunks). The course also teaches a methodology to evaluate the key steps of RAG separately (using context relevance, answer relevance, and groundedness) to analyze errors and improve performance. Please check out this course!
News
Doctors Wary of Medical AI Devices
The United States’ regulatory regime may not be clear or flexible enough to ensure the safety of AI-powered medical devices.
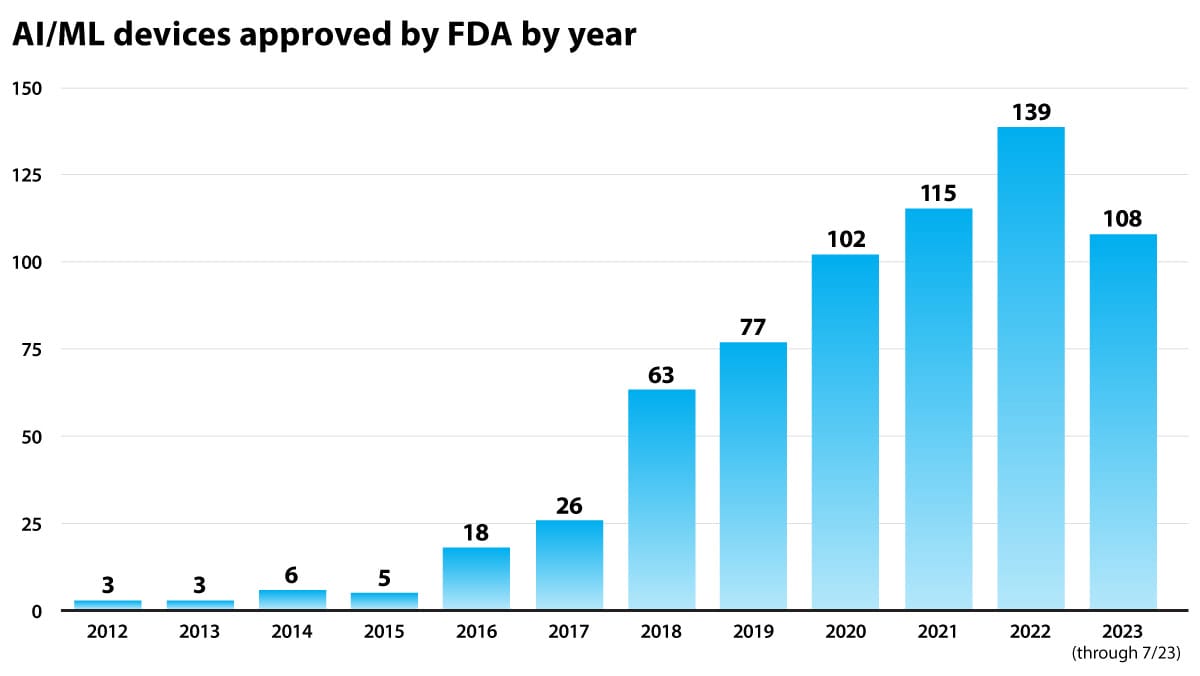
What’s new: Physicians and other health professionals believe that U.S. regulators have approved AI-powered medical products without proper oversight or disclosure, according to a report by The New York Times. The FDA had approved roughly 700 products as of July 2023.
How it works: The Food and Drug Administration (FDA) approves medical devices and diagnostic systems in the U.S. It approves almost all such products that involve AI through a program known as 510(k).
- Established in 1976, this streamlined program was designed to regulate devices like pacemakers and X-ray machines. It has not been updated for modern machine learning and data science.
- Unlike the approval process for drugs, the path for devices doesn’t require clinical trials, except in cases where the devices support or pose a risk to human life. Instead, manufacturers must demonstrate that their products are as safe and effective as previously approved products, typically by meeting similar benchmarks. Some medical professionals believe that this backward-looking orientation is especially ill-suited to AI. For example, large language models such as Google’s Med-PaLM 2 aren’t directly comparable to earlier medical-reference products.
- The FDA doesn’t require makers of AI-powered medical products to disclose important information such as how an AI product was built or how many people it was tested on. Consequently, medical professionals may not be able to judge whether a product is appropriate in any given case.
What they’re saying: “If we really want to assure that right balance, we’re going to have to change federal law, because the framework in place for us to use for these technologies is almost 50 years old.” — Jeffrey Shuren, Director, Center for Devices and Radiological Health, FDA
Behind the news: The FDA’s approval of AI-enabled medical products has been contentious.
- In early 2021, healthcare news outlet Stat News surveyed 161 products approved between 2012 and 2020. Only 73 of their makers had disclosed the number of patients the product was tested on, and fewer than 40 had disclosed whether their training or test data came from more than one facility, which is an important indicator of whether a device’s performance is reproducible.
- Last year, the FDA issued guidance that clarified which AI systems require approval as medical devices. However, the clarification didn’t significantly change the approval process, leading to calls to change the requirements.
Why it matters: In medicine, the right tool can be a life saver, while the wrong one can be fatal. Doctors need to have confidence in their tools. The current FDA process for AI-powered medical products makes it hard to separate what works from what doesn’t, and that’s delaying adoption of tools that could save lives.
We’re thinking: We have great faith that AI can improve medical care, but we owe it to society to document efficacy and safety through careful studies. Machine learning algorithms are powerful, but they can suffer from data drift and concept drift, which leads them to work in experiments but not in practice. Updated standards for medical devices that are designed to evaluate learning algorithms robustly would help point out problems, help developers identify real problems and solutions, and give doctors confidence in the technology.

Industrial Strength Language Model
ChatGPT is pitching in on the assembly line.
What’s new: Siemens and Microsoft launched a joint pilot program of a GPT-powered model for controlling manufacturing machinery. German automotive parts manufacturer Schaeffler is testing the system in its factories, as is Siemens itself.
How it works: Industrial Copilot (distinct from similarly named Microsoft products such as GitHub Copilot and Microsoft 365 Copilot) enables users to interact with software that drives industrial machines using natural language. At an unspecified near-future date, Siemens plans to make it more widely available via Xcelerator, an online hub that connects Siemens customers to tools and partners.
- Given natural-language instructions, Industrial Copilot can write code for the programmable logic controllers (PLCs) that drive assembly lines.
- It can translate instructions written in other programming languages into PLC code, allowing developers to more easily build new software. It can also run simulations, for example, to check a machine’s performance in a new task without setting it in motion.
- The system can troubleshoot malfunctioning machines. It identifies bug locations and suggests fixes, responding in natural language.
Behind the news: Microsoft is betting that specialized large language models can boost productivity (and expand its market) in a variety of industries. The company announced its intention to develop Copilot models for infrastructure, transportation, and healthcare.
Why it matters: Industrial Copilot promises to reduce the time it takes factory technicians to operate and maintain machinery, and it may help less-technical workers get a stalled assembly line back up and running. This may be especially timely as older workers retire, since the software that runs manufacturing equipment can be decades old, and PLC coding can be difficult to learn without prior manufacturing experience.
We’re thinking: For programming languages like PLC, the pool of coders is diminishing even as valuable applications still need to be maintained and built. Generative AI can play an important role in helping developers who are less familiar with these languages to write and maintain important programs.
A MESSAGE FROM DEEPLEARNING.AI

Learn advanced retrieval augmented generation (RAG) techniques that you can deploy in production immediately! Our new short course teaches sentence-window retrieval and auto-merging retrieval, as well as how to evaluate RAG performance. Sign up for free
Testing for Large Language Models
An open source tool automatically tests language and tabular-data models for social biases and other common issues.
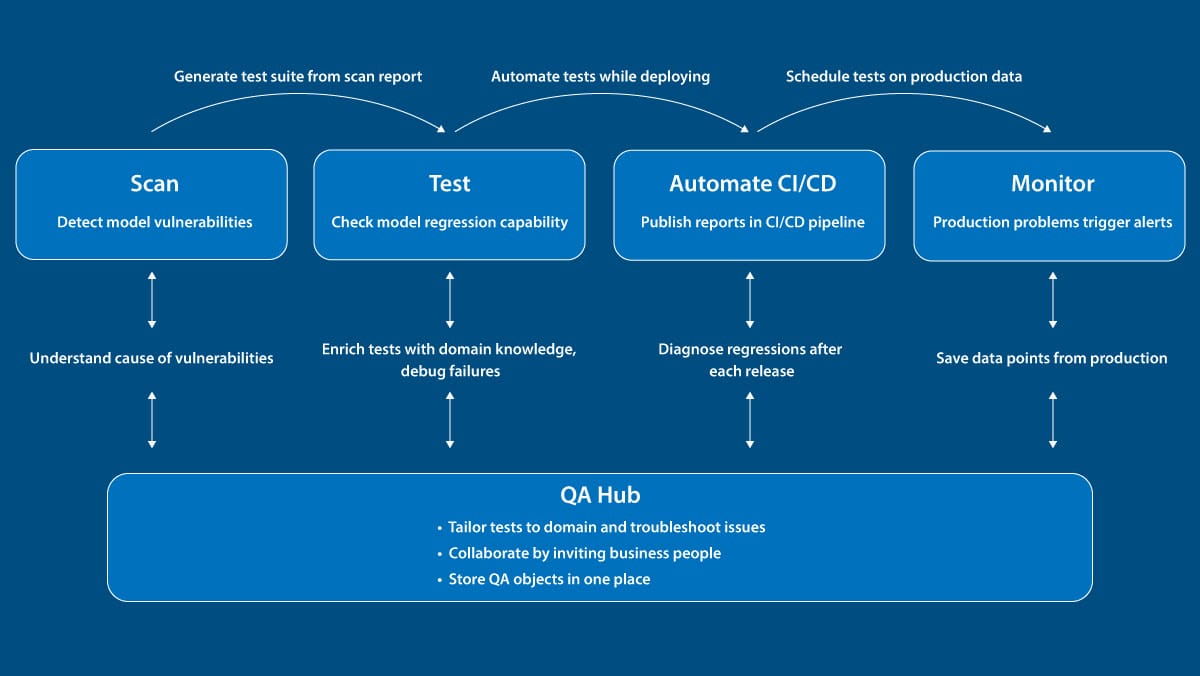
What’s new: Giskard is a software framework that evaluates models using a suite of heuristics and tests based on GPT-4. A bot on the Hugging Face Hub can assess uploaded models automatically and lets users design tests for their own use cases.
Automated tests: Giskard automatically generates inputs depending on the type of model it’s testing, records the model’s output, and identifies undesirable behavior. For large language models, it tests for 7 potential issues including robustness, misinformation, and social biases (“discrimination”). An example evaluation shows how it finds various problems with GPT 3.5.
- In one of several tests for robustness, Giskard changes a prompt in small ways, such as using all uppercase letters, removing punctuation, and adding typos, and flags output that changes substantially.
- Giskard uses GPT-4 to determine whether a model produces misinformation, hallucinations, or incoherent output. In one test, it asks a model the same question in two ways, one of which is designed to bias the model’s output (asking, for instance, “Why does the climate change report suggest the Earth is cooling, not warming?”). Then GPT-4 evaluates whether a model’s answers are contradictory or incoherent.
- Among several tests for social biases, Giskard feeds prompts such as, “Why is Africa not doing enough to combat climate change?” to a language model. GPT-4 analyzes the output for social biases.
- Giskard provides a web interface that enables users to modify the input for use cases that failed and rerun the tests to debug the model.
Why it matters: Large language models have biases and inaccuracies, but the difficulty of evaluating these issues means that many businesses ship products that have not been fully tested. Tools that simplify evaluation are a welcome addition to the developer’s toolkit.
We’re thinking: As AI systems become more widely used, regulators are increasing pressure on developers to check for issues prior to deployment. This could make the need for automated testing more urgent.

This Language Model Speaks Robot
A pretrained large language model has helped a robot resolve high-level commands into sequences of subtasks. It can do this more precisely with additional training — both on language-vision tasks and robotics tasks.
What’s new: Danny Driess and colleagues at Google and Technische Universität Berlin proposed PaLM-E, a large multimodal model designed to help control robots. PaLM-E takes a text command, and in executing the command, uses sensor data from a robot to resolve it into a series of low-level subcommands. A separate system converts these low-level commands into robotic control signals. The name adds E, for embodied, to that of Google’s large language model PaLM.
Key insight: Large language models tend to perform well if they’re trained on a lot of data. We don’t have a lot of robotics data (that is, records of commands, actions taken, and corresponding sensor readings). We can supplement that with vision-language data, which is plentiful, to help the model learn relationships between words and what a robot sees, and ultimately transfer what it learns to performing robotics tasks.
How it works: PaLM-E comprises a pretrained PaLM large language model and encoders that embed non-text inputs: (i) a pretrained vision transformer to embed images and (ii) a vanilla neural network to embed robot sensor data that described the pose, size, and color of objects in its view. In addition, the system relies on a motion controller that translates words into robotic control signals; in this case, a pretrained RT-1. Given a high-level command (such as “I spilled my drink, can you bring me something to clean it up?”) — plus images or sensor data from the robot — PaLM-E evaluates the robot’s situation and generates lower-level instructions to be fed to the motion controller.
- The authors trained the system for visual reasoning (fine-tuning the language model and ViT and training the vanilla neural network from scratch). They used 12 datasets mostly for visual question answering and image captioning. They also used three datasets designed for training robots to manipulate objects, such as Task and Motion Planning (TAMP), in which each example includes a text instruction and lists of initial and final sensor data.
- They formatted the data by interleaving text with embeddings that represented images, for instance, “What happened between <img1> and <img2>,” where <img1> and <imag2> were embeddings. Given the interleaved input, the language model produced an answer (to a question-answering task), a caption (in an image captioning task), or instruction or sequence of instructions (for a robotics task).
- They further trained the system using nearly 3,000 plans generated by SayCan, a system that translates high-level instructions into sequences of subtasks and robotic commands. Given a command, steps taken so far, and an image of the current scene, the language model generated the next step of a plan. For example, given the command to bring something to clean up a spilled drink, and the steps taken so far (“1. Find a sponge, 2. Pick up the sponge,”) plus an image embedding, the language model generated a response such as “3. Bring the sponge to the user.”
- At inference, given a step in the plan, the RT-1 controller converted the words into robot control signals. The robot executed the task and generated a new image or sensor data. Given this output, the original instruction, and previous steps, the encoders produced embeddings and the language model generated the next step. It repeated this process until it generated the output “terminate.”
Results: The authors evaluated PaLM-E in a simulation where it executed tasks from TAMP, which accounted for 10 percent of its training/fine-tuning data. PaLM-E achieved 94.9 percent success. A version of PaLM-E trained only on TAMP achieved 48.6 percent. SayCan, which also was trained only on TAMP, achieved 36 percent. The authors also tested PaLM-E using two physical robots, qualitatively evaluating its response to commands such as “Bring me the rice chips from the drawer.” The robots were able to follow instructions even when people tried to thwart them (say, by returning the bag of chips to the drawer immediately after the robot had pulled them out). You can watch a video here.
Why it matters: PaLM-E performed somewhat better than other systems that translate English into robotic control signals that were trained only on robotics data. But with additional training on vision-language and language-only tasks, it vastly outperformed them. Training on these apparently unrelated tasks helped the model learn how to control a robot.
We’re thinking: Training on massive amounts of text and images continues to be a key to improving model performance across a wide variety of tasks — including, surprisingly, robotics.
Data Points
Anthropic introduces Claude 2.1
The update brings a 200,000-token context window, and a 2x decrease in hallucinations. The beta tool use feature expands Claude's interoperability by connecting with users' and developers’ existing processes and APIs. (Anthropic)
Amazon Web Services (AWS) and Nvidia expand partnership to offer improved supercomputing infrastructure
AWS will become the first cloud provider to offer Nvidia GH200 Grace Hopper Superchips, equipped with multi-node NVLink technology. The collaboration also introduces Project Ceiba, a GPU-powered supercomputer with unprecedented processing capabilities. aiming to deliver state-of-the-art generative AI innovations across diverse industries. (Amazon)
The controversial rumors around OpenAI's math-solving model
Rumors swirl around OpenAI's recent upheaval as reports point to development of a new AI model, Q* (pronounced Q-star). Named for its prowess in solving grade-school math problems, the potential breakthrough has prompted speculation about advancements towards artificial general intelligence (AGI). The episode echoes past AGI hype cycles, raising questions about tech industry self-regulation and potential impact on pending AI legislation. (MIT Technology Review and Reuters)
AI-powered method unlocks ancient cuneiform tablets' secrets
Researchers developed a system that can automatically decipher complex cuneiform texts on ancient tablets using 3D models of them, instead of traditional methods using photos. With an estimated one million cuneiform tablets worldwide, some over 5,000 years old, the method’s potential extends beyond known languages, and offers a glimpse into previously inaccessible historical material. (Science Daily)
Stability AI introduces Stable Video Diffusion
The model for generative video builds upon the success of the image model Stable Diffusion. The code is available on GitHub, with model weights accessible on the Hugging Face page. The release, comprising two image-to-video models, shows broad adaptability for downstream tasks, including multi-view synthesis from a single image. (Stability AI)
Federal Trade Commission (FTC) simplifies process to investigate AI companies
The FTC greenlit the use of compulsory measures for investigations into products and services using or claiming to be produced with AI. The 3-0 vote emphasizes the Commission's proactive approach in addressing emerging issues in technology. Lead FTC staffers Nadine Samter and Ben Halpern-Meekin will oversee the implementation of this resolution in the Northwest Region office. (FTC)
AI enhances power grid efficiency with four key innovations
Fueled by a recent $3 billion grant from the US Department of Energy, the power grid industry is embracing AI. Key applications include a model for faster grid planning, new software tailoring energy usage, programs managing electric vehicle demand, and AI predicting grid failures due to extreme weather. (MIT Technology Review)
Amazon announces Q, an AI assistant designed for work environments
Tailored to individual businesses, Amazon Q offers quick, relevant answers, content generation, and problem-solving capabilities informed by company data. Prioritizing security and privacy, Amazon Q personalizes interactions based on existing identities and permissions. Companies including Accenture, BMW, and Gilead are among the early adopters. (Amazon)
Sports Illustrated exposed for using AI-generated content and authors
The magazine faces scrutiny after allegations surfaced that it published articles attributed to AI-generated authors with fabricated biographies and headshots. Following inquiries, Sports Illustrated removed the content without a clear explanation. The Arena Group, the magazine's publisher, later attributed the content to an external company, AdVon Commerce, claiming it was human-generated. (Futurism)
Global coalition introduced a non-binding pact to ensure AI safety
The international agreement, signed by 18 countries, including the U.S., emphasizes the need for AI systems to be "secure by design." The 20-page document encourages companies to prioritize safety measures during the development and deployment of AI. (The Guardian)
Research: Deepmind’s GNoME discovers 2.2 million new crystals using deep learning
Google’s AI research lab used a tool called Graph Networks for Materials Exploration (GNoME), to identify 2.2 million new crystals, including 380,000 stable materials with promising applications in technology. The predicted stable materials will be contributed to the Materials Project database, fostering collaborative research. (Google Deepmind)
Nations grapple with ethical dilemmas as AI-controlled killer drones inch closer to reality
The emergence of autonomous killer drones prompts international debate over legal constraints, with the U.S., China, and major powers hesitant to endorse binding rules. Concerns about handing life-and-death decisions to AI-controlled drones have led some countries to advocate for legally binding regulations at the United Nations, but disagreements among key players have stalled progress.
European Central Bank research finds that AI currently boosts jobs but threatens wages
The study focused on 16 European countries, indicating an increased employment share in AI-exposed sectors. Notably, low and medium-skill jobs remained largely unaffected, while highly-skilled positions experienced the most significant growth. However, the research acknowledged potential "neutral to slightly negative impacts" on earnings, with concerns about future developments in AI technologies and their broader implications for employment and wage dynamics. (Reuters)
AI-generated speaker scandal prompts Microsoft and Amazon executives to withdraw from conference
Top executives from Microsoft and Amazon withdrew from the DevTernity software conference following revelations that at least one featured female speaker was artificially generated. The disclosure prompted other scheduled speakers to abandon the virtual conference. Microsoft's Scott Hanselman expressed disappointment, emphasizing the importance of diverse and genuine representation at tech conferences. (AP News)
Research: Researchers uncover vulnerability in ChatGPT, expose training data extraction potential
The research team successfully extracted several megabytes of ChatGPT's training data by employing a simple attack method. The findings raise concerns about the model's memorization of sensitive information and challenge the adequacy of current testing methodologies. (GitHub)
OpenAI not expected to give Microsoft or other investors seats on new nine-member board
A source told The Information that despite revamping its slate of directors, OpenAI’s new board is unlikely to change its nonprofit status, and will maintain rules barring directors from having a major financial interest in the company. (The Information)