
Dear friends,
The past week has been an unusual split-screen time in AI. On one side, I see rapidly developing innovations from OpenAI, as well as Elon Musk's Grok and Kai-Fu Lee's open source Yi-34B large language model. On the other side, the White House and participants in last week’s AI Safety Summit are making regulations that may slow down AI by stifling innovation and limiting open source.
As you can read below, OpenAI held a developer day in which it announced numerous tools for developers. I found the sheer volume of new features impressive. OpenAI is continuing to demonstrate that it is a fast moving company capable of shipping quickly!
The speed with which OpenAI moves is a lesson for other businesses. We live in an era when tools available to developers are improving quickly, and thus the set of things we can build with generative AI growing fast. As I describe in my presentation on Opportunities in AI, AI tools often get more attention, but ultimately AI applications have to generate more revenue than tools for the market to succeed.
In my experience, speed in decision-making and execution is a huge predictor of startup success. Bearing in mind the importance of responsible AI, I respect leaders and teams that make decisions and execute quickly. In contrast, I’ve also seen companies where shipping a feature can require 3 months for legal, marketing, and privacy review. Systemically forcing yourself to make a decision quickly rather than calling another meeting to talk about a topic some more (unless it’s really necessary) can push an organization to move faster.
When you move fast, not everything will work out. For example, when OpenAI launches so many new features (including highly innovative ones like the GPT store, where developers can distribute special-purpose chatbots as though they were mobile apps), it’s possible that not every one of them will take off. But the sheer speed and volume of execution makes it likely that some of these bets will pay off handsomely. And not only for OpenAI, but also for developers who use the new features to build new products.
If you’re a developer, the rapidly growing set of tools at your disposal gives you an opportunity to execute quickly and build things that have never existed before, largely because the tools to build them didn’t exist. I believe this is the time to keep building quickly — and responsibly — and accelerate the pace at which we bring new applications to everyone.
Keep learning!
Andrew
P.S. Vector databases are a backbone of large language model (LLM) search and data-retrieval systems, for example in retrieval augmented generation (RAG). In our new short course, created with Weaviate and taught by Sebastian Witalec, you’ll learn the technical foundations of how vector databases work and how to incorporate them in your LLM applications. You’ll also learn to build RAG and search applications. I invite you to sign up for “Vector Databases: from Embeddings to Applications”!
News

Generative AI as Development Platform
OpenAI added new features designed to help developers build applications using its generative models.
What’s new: OpenAI introduced a plethora of capabilities at its first developer conference in San Francisco.
Upgrades and more: The company rolled out the upgraded GPT-4 Turbo (which now underpins ChatGPT). It extended API access to its DALL·E 3 image generator, text-to-speech engine, speech recognition, and agent-style capabilities. And it showed off a new concept in chatbots called GPTs.
- GPT-4 Turbo expands the number of tokens (typically words or parts of words) the model can process at once to 128,000 — up from a previous maximum of 32,000. That enables the model to process context over the length of a book. API access costs between one-third and half the previous cost of GPT-4 Turbo’s predecessors (some of which got price cuts).
- GPT-4 Turbo includes a JSON mode that returns valid JSON, enabling developers to get usable structured data from a single API call. Reproducible outputs (in beta) make the model’s behavior more consistent from one use to another by letting users specify a random number seed. Log probabilities (available soon) will allow developers to build features like autocomplete by predicting which tokens are likely to appear next in a sequence.
- New API calls enable developers to take advantage of image input/output, text-to-speech, and speech recognition (coming soon). New calls are available for building agent-style applications that can reason about and execute sequences of actions to complete a task. They can also retrieve information external to the model and execute functions.
- The company introduced GPTs: custom chatbots that can be configured using a conversational interface and distributed in store, like mobile apps. For instance, Canva built a GPT that generates graphics to order through conversation.
Why it matters: OpenAI is enabling developers to build intelligence into an ever wider range of applications. GPT-4 Turbo's 128,000-token context window makes possible applications that require tracking information across huge volumes of input. The expanded APIs open up language, vision, and multimodal capabilities as well as agent-style applications that respond to changing conditions and behave in complex ways. The opportunities for developers are immense.
We’re thinking: It’s amazing to see cutting-edge AI developments become widely available so quickly. Early on, OpenAI withheld its work out of fear that it could be misused. But that policy clearly no longer holds. “We believe that gradual iterative deployment is the best way to address safety challenges of AI,” OpenAI CEO Sam Altman said in his keynote. Based on the evidence to date, we agree.

AI Safety Summit Mulls Risks
An international conference of political leaders and tech executives agreed to regulate AI.
What’s new: 28 countries including China and the United States as well as the European Union signed a declaration aimed at mitigating AI risks.
How it works: The declaration kicked off the United Kingdom’s first AI Safety Summit at Bletchley Park, a country house outside London, where Alan Turing and others cracked Germany’s Enigma code during World War II.
- The signatories agreed to jointly study safety concerns including disinformation, cybersecurity, and biohazards. They committed to addressing risks within their borders but didn’t announce specific programs.
- 10 countries including France, Germany, Japan, the U.S., and the UK will nominate experts to lead an international AI panel akin to the Intergovernmental Panel on Climate Change. This panel will prepare a report on the “state of AI science.”
- Amazon, Google, Meta, Microsoft, OpenAI, and other companies agreed to allow governments to test AI products before releasing them to the public.
- AI safety institutes established by individual countries will administer the tests. The UK and U.S. announced such institutes, which pledged to collaborate with each other and their counterparts in other countries.
More to come: The AI Safety Summit is set to be the first in a series. South Korea will host a follow-up in six months. France will host a third summit six months later.
Yes, but: Critics found the conference wanting. Some researchers criticized it for failing to endorse concrete limits on AI. Others blamed the speakers for promoting fear, particularly UK prime minister Rishi Sunak, who compared the AI risks to a global pandemic or nuclear war.
Why it matters: AI is developing rapidly, and regulatory frameworks are already emerging in China, Europe, and the U.S. The summit is an effort to lay groundwork for a coherent international framework.
We’re thinking: We applaud approaches that engage leaders in government, industry, and research. But we remain concerned that exaggerated fear of risks may lead to regulations that stifle innovation, especially by limiting open source development. UK Deputy Prime Minister Oliver Dowden spoke about the value of open source and said there should be a very high bar to restrict open source in any way. We heartily agree!
A MESSAGE FROM DEEPLEARNING.AI

Learn how to use vector databases with large language models to build applications that include hybrid and multilingual searches! Take our new course, “Vector Databases: from Embeddings to Applications.” Enroll for free
The Language of Schizophrenia
Large language models may help psychiatrists resolve unanswered questions about mental illness.
What’s new: Researchers from University College London, Beijing Normal University, and Lisbon’s Champalimaud Centre for the Unknown used a large language model to measure differences in the ways people with schizophrenia use words.
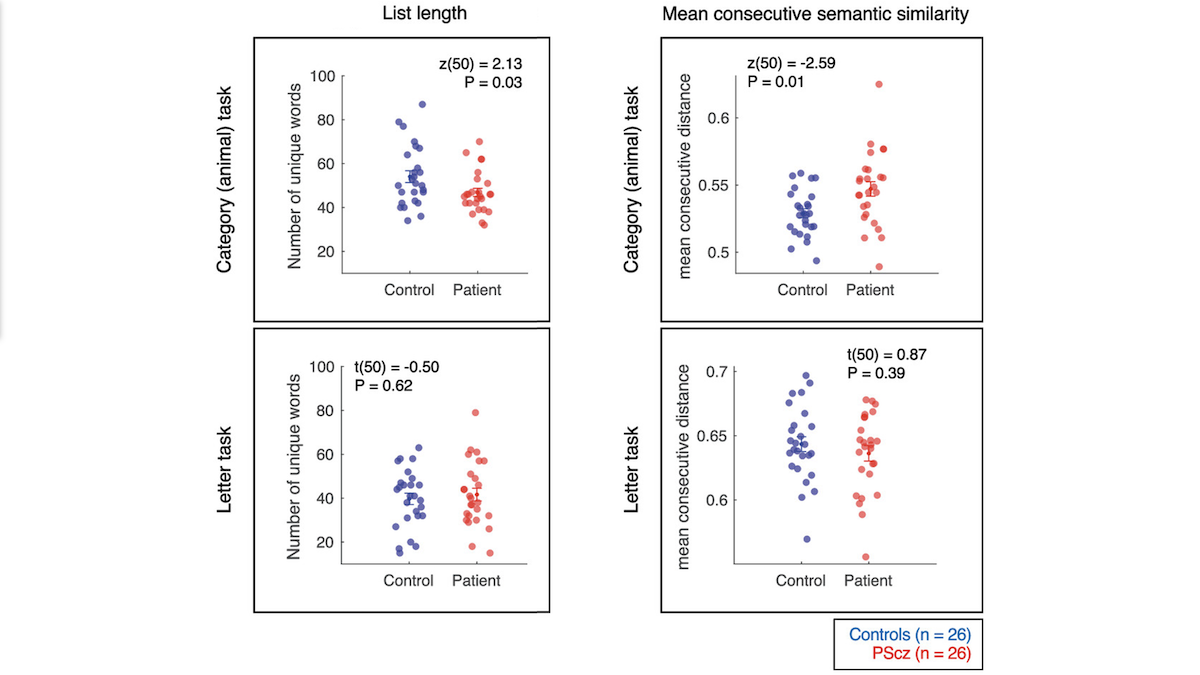
Key insight: Neuroscientists theorize that schizophrenia disturbs the brain’s ability to represent concepts. When given a task like “name as many animals as you can in five minutes,” patients with schizophrenia would propose names in a less-predictable order than people who haven’t. In general, the consecutive names produced by people with schizophrenia would be less semantically related than those produced by others.
How it works: The authors asked 26 people who had been diagnosed with schizophrenia and 26 people who hadn’t to name as many animals as they could in five minutes. They also asked the subjects to name as many words that start with the letter “P” as they could in five minutes.
- The authors analyzed the randomness of the lists by comparing them to an “optimal” order based on embeddings generated by a fastText model that was pretrained on text from the web. Given a word, fastText embedded it. They computed the cosine similarity — a measure of semantic relationship — between every pair of words in each list.
- They used the traveling salesman algorithm to compute an optimal order of words in each list, starting with the first word. The optimal order contained all words, and it maximized the similarity between consecutive words.
- To measure the randomness of the orders produced by people in the experiment, first they totaled the cosine similarities between consecutive words in each list for original and optimal orders. Then they found the difference in total cosine similarity between the original and optimal orders.
Results: Responses by subjects with schizophrenia had greater randomness. To control for variations in the contents of various patients’ lists, the researchers expressed the degree of randomness as a standard score, where 0 indicates complete randomness, and the lower the negative number, the more optimal the order. On average, people with schizophrenia achieved -5.81, while people without schizophrenia achieved -7.02.
Why it matters: The fastText model’s embeddings helped the authors demonstrate a relationship between cognitive activity and psychiatric symptoms that previously was purely theoretical. Such a relationship has been difficult to establish through brain imaging or traditional testing.
We’re thinking: It’s important to note that the authors don’t propose using their method as a diagnostic tool to determine whether or not a patient has schizophrenia. Unlike diagnosing, say, a cancerous tumor, establishing ground truth in mental illness is extremely complicated. The fact that AI-based measurements agree with doctors’ assessments is a very positive sign.

Synthetic Data Helps Image Classification
Generated images can be more effective than real ones in training a vision model to classify images.
What's new: Yonglong Tian, Lijie Fan, and colleagues at Google and MIT introduced StableRep, a self-supervised method that trains vision transformers on images generated by Stability.AI’s Stable Diffusion image generator.
Key insight: Models that employ a contrastive loss learn to represent examples as more or less similar. For example, images that depict a particular object are more similar to each other, and images that depict other objects are less similar to the first group. The training method known as SimCLR uses a contrastive loss with two augmented (cropped, rotated, flipped, and so on) versions of each image, so a model learns that augmented versions of one image, which is closely related but different, are similar to one another — but not to augmented versions of other images. Given a prompt, an image generator produces images that are closely related but significantly more different than augmented versions of the same image. This makes for greater variety among similar examples, which can lead to more effective learning using a contrastive loss.
How it works: The authors generated images and trained a vision transformer on them using a contrastive loss.
- The authors used Stable Diffusion to generate 2.7 million images. They drew the prompts from the captions in Conceptual Captions (a dataset of images and captions) and asked Stable Diffusion to generate 10 images of each prompt.
- They augmented each generated image according to SimCLR, but only once.
- They trained a ViT-B/16 to generate a similar embedding for the augmented version of each image generated from the same prompt, and a dissimilar embedding for the augmented version of each image generated from other prompts.
Results: The authors compared the ViT-B/16 trained using StableRep to two models of the same architecture trained using SimCLR (one using generated images, the other using images from Conceptual Captions). They also compared it to two CLIP models that produced matching embeddings for images and their paired captions, one trained on generated images and their prompts, the other on real images and their captions. For each of 11 computer vision datasets, the authors trained a linear classifier on top of each model without changing the model’s weights. Comparing the classifiers’ performance, StableRep achieved the best results on 9 of them. For example, on FGVC-Aircraft (10,000 images of 100 different aircraft), StableRep achieved 57.6 percent accuracy, while the best competing model, CLIP pretrained on generated images, scored 53.5 percent.
Why it matters: The fact that text-to-image generators can produce images of similar things that are quite different in appearance makes them a powerful resource for training vision models. And they provide a practically unlimited source of such images!
We're thinking: Different foundation models understand different aspects of the world. It’s exciting that a large diffusion model, which is good at generating images, can be used to train a large vision transformer, which is good at analyzing images!
A MESSAGE FROM FOURTHBRAIN

Join us for two live workshops! Learn to leverage large language models in these interactive, hands-on sessions. Team registrations are available. Register here
Data Points
TikTok explores AI-powered product recognition for e-commerce integration
The social video platform is testing an AI tool that recognizes products in videos and suggests similar items available on TikTok Shop. The product recommendation system, which currently works without notifying the video’s creator, is currently in the experimental stage with limited availability in the U.S. and UK. (Business Insider)
Elon Musk’s startup xAI introduced its first model, Grok
The chatbot, now available to X Premium+ subscribers, boasts real-time knowledge from the X platform. Grok also claims to answer unconventional questions that many other AI systems might reject. Further details about Grok's capabilities and features are yet to be specified. (DW)
Librarians embrace AI as the next chapter in academic support
There may be no universal AI guidelines for libraries, but librarians are finding ways to educate students about responsible AI use and citation practices. Despite the challenges, librarians across institutions see opportunities for AI to enhance information literacy and educate students on verifying and evaluating information sources.Many librarians, educators, and students view AI as an opportunity to shape the future of academic research. (Inside Higher Ed)
Recruitment agencies leverage AI to enhance talent acquisition
Recruiters are using AI to sift through a vast number of applications and engage with a wider range of candidates, with the goal of exploring diverse talent pools. Chatbots also enhance the initial interaction with job seekers, allowing recruiters to concentrate on building meaningful relationships with advanced candidates. However, increased use of AI also poses ethical and practical problems, such as poor data quality and the risk of perpetuating human biases. (Financial Times)
Research: The increasing energy footprint of AI may not be sustainable
The surge in generative AI raises concerns about AI’s significant energy consumption. New research argues that AI’s current trajectory could lead to annual electricity consumption equivalent to the entire country of Ireland. Human self-regulation and institutions carefully evaluating AI integration into various solutions will be pivotal in curbing energy consumption and limiting environmental impact. (IEEE Spectrum)
The United Nations uses AI to analyze Israeli-Palestinian conflict
The UN partnered with AI company CulturePulse to build a virtual simulation of Israel and the Palestinian territories to analyze the long-standing conflict. The model employs a multi-agent system to simulate the region, factoring in numerous variables, helping experts pinpoint the root causes of the conflict. The UN hopes this approach will enable a deeper understanding of the complex issue and uncover potential solutions. (Wired)
AI-aided song marks the last Beatles song featuring John Lennon's voice
The song, “Now and Then,” billed as the last Beatles track, will be part of a double A-side single alongside the band's debut UK single from 1962, "Love Me Do." AI was used to isolate instruments and vocals from the original tape of "Now and Then," recorded by Lennon as a home demo in the late 1970s. (Reuters)
Jury finds Tesla's autopilot not responsible for fatal 2019 crash
The case centered on the death of Micah Lee, who was using Autopilot features in his Tesla when it veered off the road, collided with a palm tree, and caught fire. The jury absolved the carmaker of responsibility for the accident. This verdict is significant for Tesla, which is facing multiple lawsuits related to incidents involving its driver-assistance software. (The Washington Post)
Baidu introduces paid version of Ernie Bot
The Chinese giant’s chatbot is charging 59.9 yuan (approximately $8.18) per month for access to its premium version, expanding Baidu’s AI offerings in the Chinese market. (Reuters)
Judge reduces artists’ copyright lawsuitagainst Midjourney and Stability AI
U.S. District Judge William Orrick dismissed some claims in the proposed class action copyright infringement suit, including all allegations against Midjourney and DeviantArt, but allowed visual artists to file an amended complaint. (Reuters)
A comprehensive resource for teaching and learning with text generation technologies
The "TextGenEd" collection offers a range of assignments and other resources to help writing teachers integrate text generation technologies into their courses. The collection is open access, allowing teachers to adapt and use the assignments, and provides insights from instructors who have implemented them in their classes. The collection also offers a historical perspective on automated and computational writing, from Leibniz's cryptographic machine to modern AI-generated texts. (WAC Clearinghouse)
Microsoft launches investigation after controversial AI poll on an article about a woman's death
The controversy arose when an autogenerated poll accompanied an article by The Guardian about a woman's death, asking readers to speculate about the cause of her death. The Guardian's CEO, Anna Bateson, demanded that Microsoft publicly acknowledge its responsibility for the poll and called for safeguards against the inappropriate application of AI technologies in journalism. (Axios)
DeepMind's latest AlphaFold model improves drug discovery with precise molecule predictions
The Google-affiliated research lab unveiled the latest iteration of its AlphaFold model, which improved its capability to predict molecular structures. This updated version of AlphaFold can generate predictions for a wide range of molecules, including proteins, ligands, nucleic acids, and post-translational modifications. (TechCrunch and Google DeepMind)
Scarlett Johansson takes legal action against unauthorized use of her image in AI-generated ad
The 22-second ad used real footage of Johansson to create a fabricated image and dialogue. Johansson's representatives confirmed that she is not affiliated with the company. The actress had previously voiced concerns about her image being used in deepfakes without consent. (The Guardian)
AI adds layer of uncertainty to Israel-Hamas conflict
The Israel-Hamas conflict has been marked not only by the actual events but also by the presence of potentially manipulated AI-generated media. This erosion of trust in digital content, coupled with the ease of creating persuasive deepfakes, is raising concerns about the impact of synthetic media on public perception. (The New York Times)
Collins Dictionary names “A”' as the most notable word of 2023
Collins selected the word from a list of new terms that reflect the evolving language and concerns of its users, including "greedflation," "debanking," "nepo baby," and "deinfluencing." The annual word of the year is determined by lexicographers who monitor various sources to capture the zeitgeist. (The Guardian)
Dawn, the supercomputer powered by Intel and Dell
Dell Technologies, in collaboration with Intel and the University of Cambridge, deployed the Dawn Phase 1 supercomputer, which is part of the UK's AI Research Resource (AIRR) initiative. The system is built on Dell PowerEdge XE9640 servers, optimized for AI and HPC workloads, and features direct liquid cooling technology for enhanced efficiency. (Intel)
Research: AI outperforms biopsy in assessing aggressiveness of certain cancers
A study conducted by the Royal Marsden NHS foundation trust and the Institute of Cancer Research (ICR) found that an AI algorithm outperformed biopsies in grading the aggressiveness of sarcomas, a form of cancer that develops in the body's connective tissues. AI's enhanced accuracy can lead to quicker diagnosis and more personalized treatment for high-risk patients, while low-risk patients can avoid unnecessary treatments and follow-up scans. (The Guardian)