
Dear friends,
I wrote earlier about how my team at AI Fund saw that GPT-3 set a new direction for building language applications, two years before ChatGPT was released. I’ll go out on a limb to make another prediction: I think we’ll see significant growth in AI, including Generative AI, applications running at the edge of the network (PC, laptop, mobile, and so on).
I realize this flies in the face of conventional wisdom. Most AI runs in data centers, not on edge devices. There are good reasons for this:
- The most powerful large language models require 100B+ parameters and massive amounts of memory even for inference (100B parameters, stored using 8- bit quantization, requires 100GB of memory).
- Many businesses prefer to operate cloud-based, software-as-a-service (SaaS) products (which allows them to charge a recurring subscription fee) rather than software running at the edge (where customers tend to prefer paying a one-time fee). SaaS also gives the company access to data to improve the product and makes the product easier to upgrade.
- Many developers today have been trained to build SaaS applications, and want to build cloud-hosted applications rather than desktop or other edge applications.
Here’s why I think those factors won’t stop AI’s growth at the edge.
- AI applications are starting to run quite well on modern edge devices. For example, I regularly run models with around 1B to 10B parameters on my laptop. If I’m working on an airplane without WiFi access, I will occasionally run a small model to help me with my work.
- For many applications, a model of modest size works fine, especially if it’s fine-tuned to the task at hand. To help me find grammatical errors in my writing, do I really need a 175B parameter model that has broad knowledge of philosophy, history, astronomy, and every other topic under the sun?
- Many users, especially those from Gen Z (born around 1996 to 2010), whose behavior tends to be a leading indicator of future consumer trends, are increasingly sensitive to privacy. This has been a boon to Apple’s product sales, given the company’s reputation for privacy. Surely, to check my grammar, I don’t need to share my data with a big tech company?
- Similarly, for corporations worried about their own data privacy, edge computing (as well as on-premises and virtual private cloud options) could be appealing.

Further, strong commercial interests are propelling AI to the edge. Chip makers like Nvidia, AMD, and Intel sell chips to data centers (where sales have grown rapidly) and for use in PCs and laptops (where sales have plummeted since the pandemic). Thus, semiconductor manufacturers as well as PC/laptop makers (and Microsoft, whose sales of the Windows operating system depend on sales of new PC/laptops) are highly motivated to encourage adoption of edge AI, since this would likely require consumers to upgrade their devices to have the more modern AI accelerators. So many companies stand to benefit from the rise of edge AI and will have an incentive to promote it.
AI Fund has been exploring a variety of edge AI applications, and I think the opportunities will be rich and varied. Interesting semiconductor technology will support them. For example, AMD’s xDNA architecture, drawing on configurable cores designed by Xilinx (now an AMD company), is making it easier to run multiple AI models simultaneously. This enables a future in which one AI model adjusts image quality on our video call, another checks our grammar in real time, and a third pulls up relevant articles.
While it’s still early days for edge AI — in both consumer and industrial markets (for example, running in factories or on heavy machinery) — I think it’s worth investigating, in addition to the numerous opportunities in cloud-hosted AI applications.
Keep learning!
Andrew
P.S. My team at Landing AI will present a livestream, “Building Computer Vision Applications,” on Monday, November 6, 2023, at 10 a.m. Pacific Time. We’ll discuss the practical aspects of building vision applications including how to identify and scope vision projects, choose a project type and model, apply data-centric AI, and develop an MLOps pipeline. Register here!
News
Generative AI Calling
Google’s new mobile phones put advanced computer vision and audio research into consumers’ hands.
What’s new: The Alphabet division introduced its flagship Pixel 8 and Pixel 8 Pro smartphones at its annual hardware-launch event. Both units feature AI-powered tools for editing photos and videos.
How it works: Google’s new phones process images in distinctive ways driven by algorithms on the device itself. They raise the bar for Apple, the smartphone leader, to turn its internal projects into market opportunities.
- The feature called Best Take enables users to select elements from multiple photos and stitches them into a single image. In a group photo, users might replace faces with closed eyes or grimaces with alternatives from other shots that show open eyes and wide smiles.
- Magic Editor uses image-generation technology to edit or alter images. Users can move and resize individual elements and swap in preset backgrounds. They can also generate out-of-frame parts of an element — or an entire photo — on the fly.
- Audio Magic Eraser splits a video’s audio into distinct sounds, enabling users to adjust their relative volume. This capability can be useful to reduce distracting noises or boost dialogue.
- Video Boost, which will arrive later this year on the Pixel 8 Pro only, will improve the image quality of videos by automatically stabilizing motion and adjusting color, lighting, and grain.
Behind the news: Google researchers actively pursued AI systems that alter or enhance images, video, and audio.
- Best Take and Magic Editor resemble a system Google and Georgia Tech researchers described in an August 2023 paper, which uses diffusion models to segment and merge multiple images.
- Magic Editor echoes Imagen, Google’s diffusion text-to-image generator.
- Audio Magic Eraser resembles capabilities described in a recent paper that proposes AudioScopeV2 to separate and recombine various audio and video tracks.
Why it matters: Smartphones produce most of the world’s photos and videos. Yet generative tools for editing them have been confined to the desktop, social-network photo filters notwithstanding. Google’s new phones bring the world closer to parity between the capabilities of desktop image editors and hand-held devices. And the audio-editing capabilities raise the bar all around.
We’re thinking: Earlier this year, Google agreed to uphold voluntary commitments on AI, including developing robust mechanisms, such as watermarks, that would identify generated media. Will Google apply such a mark to images edited by Pixel users?
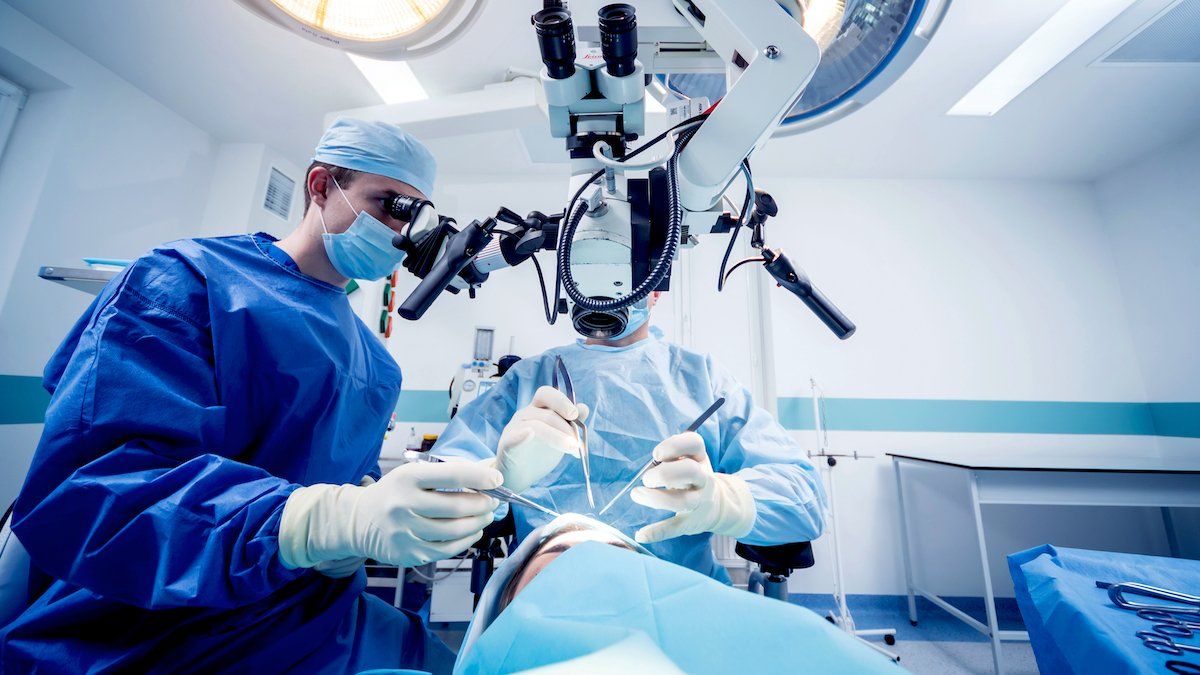
Guiding the Scalpel
A neural network helped brain surgeons decide how much healthy tissue to cut out when removing tumors — while the patients were on the operating table.
What’s new: Researchers from Amsterdam University Medical Centers and Princess Máxima Center for Pediatric Oncology in the Netherlands built a system to assess how aggressively surgeons should treat tumors. It worked accurately and quickly enough to enable doctors to adjust their approach in the operating room.
Key insight: Brain surgeons don’t know the type of tumor they will remove until an operation is underway. When they have a sample — about the size of a kernel of corn — they can classify it by looking at it under a microscope. Alternatively, they can send it out for DNA sequencing, which can take weeks, requiring a second surgery. However, faster, less precise DNA sequencing can be performed on-site, and a neural network can classify such preliminary DNA sequences quickly and accurately. This way, a doctor can proceed with the operation with confidence in the tumor’s classification.
How it works: The authors trained a system of four vanilla neural networks to classify brain tumors.
- The authors made a labeled dataset of nearly 17 million artificial DNA sequences of around 90 tumor types, each constructed by assembling random parts from one of 2,800 sequences of tumor and non-tumor DNA. This approach simulated the messy nature of the fast DNA sequencing process.
- For each neural network, they randomly selected half the sequences for training and used the other half for testing and validation. They trained the networks to classify the tumor types.
- At inference, all four models classified each DNA sample. The system selected the classification from the model that had the highest confidence above a certain threshold. Samples that didn’t clear the confidence threshold received no classification.
Results: The authors’ system performed well on tumor DNA samples in an existing collection as well as those gathered in an operating room. Tested on samples from 415 tumors, it classified 60.7 percent of them accurately, misclassified 1.9 percent, and was unable to classify 37.3 percent. Tested on samples collected during 25 real surgeries, it correctly classified 18 tumors and was unable to classify 7. In all cases, it returned results within 90 minutes (45 minutes to collect the DNA and 45 minutes to analyze it).
Why it matters: 90 minutes is fast enough to inform brain surgeons what kind of tumor they’re dealing with in the early phase of an operation. If this technique can be rolled out widely, it may help save many lives.
We’re thinking: Inferencing presumably takes seconds. The authors say the quick sequencing method processes DNA in 20 to 40 minutes. Speeding up that step offers great potential to accelerate the process.
A MESSAGE FROM DEEPLEARNING.AI

“Generative AI for Everyone,” taught by Andrew Ng, is coming soon! This course demystifies generative AI and assumes no prior experience in coding or machine learning. Learn how generative AI works, how to use it, and how it will affect jobs, businesses, and society. Join the waitlist
Cost Containment for Generative AI
Microsoft is looking to control the expense of its reliance on OpenAI’s models.
What’s new: Microsoft seeks to build leaner language models that perform nearly as well as ChatGPT but cost less to run, The Information reported.
How it works: Microsoft offers a line of AI-powered tools that complement the company’s flagship products including Windows, Microsoft 365, and GitHub. Known as Copilot, the line is based on OpenAI models. Serving those models to 1 billion-plus users could amount to an enormous expense, and it occupies processing power that would be useful elsewhere. To manage the cost, Microsoft’s developers are using knowledge distillation, in which a smaller model is trained to mimic the output of a larger one, as well as other techniques.
- Microsoft’s agreement with OpenAI gives it unique access to outputs from OpenAI models. Distilling Open AI models has become the AI team’s top priority. Such models are already running in Bing Chat.
- Microsoft AI research chief Peter Lee dedicated around 2,000 GPUs to training and validating distilled models, a fraction of the number used to train and validate GPT-4.
- Orca, a 13-billion-parameter LLaMA 2 model that was fine-tuned on GPT-4 outputs, matched ChatGPT on the challenging BIG-Bench Hard benchmark. Nonetheless, it trailed GPT-4 on other benchmarks. (Microsoft reportedly considered releasing Orca on Azure as a competitor to GPT-4 and LLaMA 2, but LLaMA 2’s license restricts its ability to do so.)
- The company is also developing smaller models from scratch. For instance, Phi-1 surpassed most open source models on benchmarks for generating Python code, such as HumanEval, despite being smaller by a factor of 10 and trained on less data by a factor of 100.
Behind the news: Microsoft has invested $10 billion in OpenAI. The deal promises the tech giant 75 percent of OpenAI’s operating profit until its investment is repaid, then 49 percent of further profits until reaching an unspecified cap. Meanwhile, Microsoft does have access to high-performing models from other sources. Its Azure cloud platform serves Meta’s LLaMA 2.
Why it matters: Serving large neural networks at scale is a challenge even for Microsoft, which has immense hardware resources and a favorable agreement with OpenAI. Running distilled and fine-tuned models can cut the cost for both tech giants and tiny startups.
We’re thinking: If users like Copilot so much they're running up a large bill in model inferences, that sounds like a positive sign!
Better Reasoning from ChatGPT
You can get a large language model to solve math problems more accurately if your prompts include a chain of thought: an example that solves a similar problem through a series of intermediate reasoning steps. A new approach to this sort of prompting improved ChatGPT’s accuracy on a variety of reasoning problems.
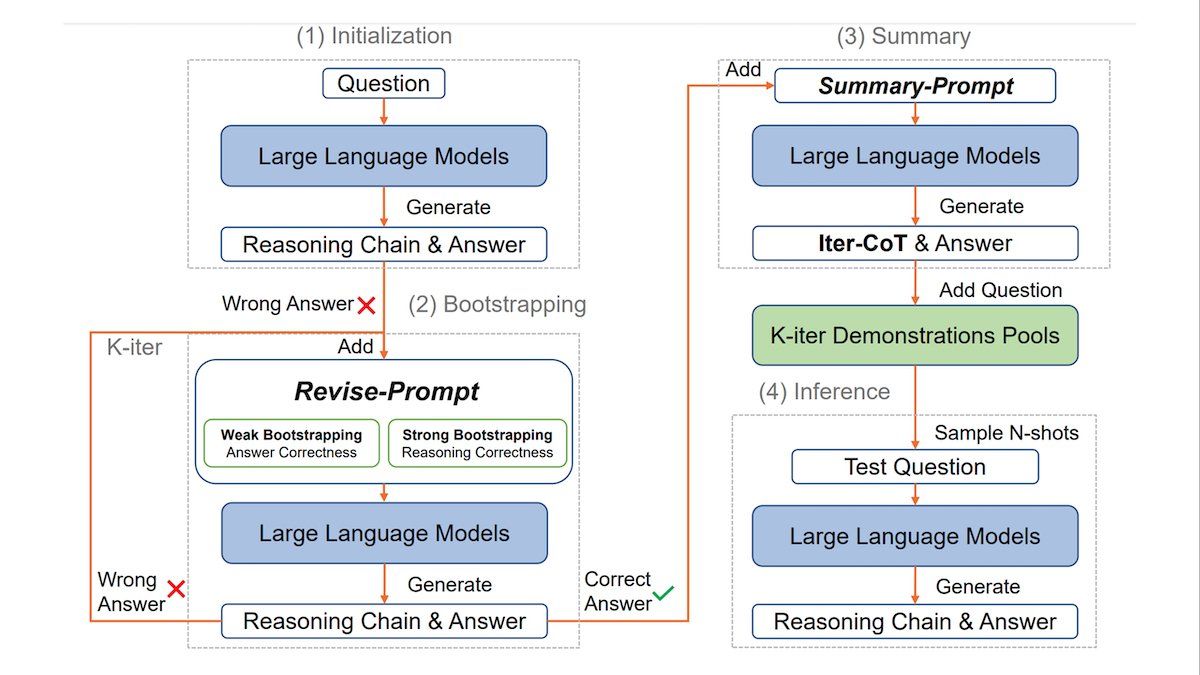
What's new: Jiashuo Sun and colleagues at Xiamen University, Microsoft, and IDEA Research, introduced iterative bootstrapping in chain-of-thought-prompting, a method that prompts a large language model to generate correct chains of thought for difficult problems, so it can use them as guides to solving other problems.
Key insight: Researchers have developed a few ways to prompt a large language model to apply a chain of thought (CoT). The typical method is for a human to write an example CoT for inclusion in a prompt. A faster way is to skip the hand-crafted example and simply instruct the model to “think step by step,” prompting it to generate not only a solution but its own CoT (this is called zero-shot CoT). To improve zero-shot CoT, other work both (i) asked a model to “think step by step” and (ii) provided generated CoTs (auto-CoT). The weakness of this approach is that the model can generate fallacious CoTs and rely on them when responding to the prompt at hand, which can lead to incorrect responses. To solve this problem, we can draw example prompts from a dataset that includes correct responses, and the model can check its responses against the dataset labels. If it’s wrong, it can try repeatedly until it answers correctly. In this way, it generates correct CoT examples to use in solving other problems.
How it works: To prompt ChatGPT to reason effectively, the authors built a database of example problems, chains of thought, and solutions. They drew problems from 11 datasets: six arithmetic reasoning datasets (such as grade-school math word problems), four common-sense reasoning datasets (for example, questions like “Did Aristotle use a laptop?”), and a symbolic reasoning dataset consisting of tasks that involved manipulating letters in words (for instance, “Take the last letters of the words in ‘Steve Sweeney’ and concatenate them”).
- The authors prompted the model with a problem and instructed it to “think step by step” as it generated a solution, and they recorded the input and output.
- When the model’s solution did not match the solution in the dataset, the authors instructed the model to try again using prompts such as, “The answer is not right, can you think more carefully and give me the final answer?” They repeated this step until the model delivered the correct solution.
- Once the model had solved a problem correctly, they prompted it to present the answer again along with the steps that led to it. This output generally rendered the chain of thought more concisely than the model’s initial correct responses. They stored the problem, chain of thought, and solution in a database.
- At inference, when prompting the model to solve a problem, the authors included in the prompt four to eight database entries selected at random.
Results: The authors evaluated their method versus hand-crafting and auto-CoT. Of the 11 datasets, their method achieved the best results on 8. For example, on grade-school math word problems, ChatGPT prompted using their method achieved 73.6 percent accuracy; using hand-crafted prompts, it achieved 69.3 percent accuracy, and using auto-CoT, it achieved 71.4 percent accuracy. Their method underperformed hand-crafted prompts on two common-sense reasoning datasets (76.8 percent versus 77.1 percent and 69.3 percent versus 71.1 percent). It underperformed auto-CoT on one arithmetic dataset (91.9 percent versus 92.5 percent.)
Why it matters: Large language models have powerful latent capabilities that can be activated by clever prompting. ChatGPT was able to solve the problems in the authors’ database, but only after multiple tries. Prompting it with examples of its own correct solutions to these problems apparently enabled it to solve other, similarly difficult problems without needing multiple tries.
We're thinking: It may be possible to modify this method to make human input unnecessary by asking the model to fix the problems in its previous generations or use external tools to validate its outputs.
Data Points
Baidu announces Ernie 4.0
The Chinese tech giant demonstrated a new version of its generative AI model at an event on Tuesday. Baidu claims that the new version of Ernie is on par with Open AI’s GPT-4 model. Ernie will also be incorporated into many of Baidu’s products, including Drive and Maps. It is not yet available to the general public. (Reuters)
Adobe releases Firefly 2.0
The creative software giant’s new image generation model features new text to image and text to vector graphic tools. It automatically generates content credentials for AI-generated material and Adobe promises to defend users against copyright infringement claims. But controversies remain about how Adobe secured its users’ permission to train its models on their images. (Adobe)
Southeast Asia takes business-friendly stance on AI regulation
A confidential draft of the Association of Southeast Asian Nations' (ASEAN) "guide to AI ethics and governance" reveals its emphasis on guiding domestic regulations rather than imposing stringent requirements. This aligns closely with the U.S. NIST AI Risk Management Framework and sets it apart from the European Union's AI Act. (Reuters)
Google commits to protect Generative AI users from copyright claims
The new policy extends to software that generates text and images in Google Workspace and Cloud applications, including Google Cloud’s Vertex AI development platform and Duet AI system. It does not cover instances where users intentionally infringe on the rights of others. This move aligns Google with companies like Microsoft and Adobe that have made similar pledges. (Reuters)
Research: Machine translation dataset bridges gap for ancient Etruscan language
Etruscan, an ancient European language with no native speakers today, only has around 12,000 known inscriptions, most of them still untranslated. A dataset for machine translation from Etruscan to English has been introduced, featuring 2,891 translated examples from academic sources. This release opens doors for future research on Etruscan and other languages with limited data. (Hugging Face)
Indigenous communities are using AI to revitalize their languages
Researchers are developing AI models to aid native language learning and cultural preservation. While AI offers promise, there are concerns about corporate interests profiting from indigenous languages. Many indigenous-run organizations are pursuing new kinds of partnerships with developers, focusing on ethical and community-focused development. (New Scientist)
Software development startup Replit launches its own AI pair programmer
Replit AI contains a comprehensive suite of tools, including Complete Code, Generate Code, Edit Code, and Explain Code. The flagship feature, Complete Code, delivers autocomplete-style suggestions to enhance the coding experience. (Replit)