
Dear friends,
Over the weekend, Hamas launched a surprise terrorist attack on Israel, slaughtering and kidnapping civilians. The images in the media are horrifying, and over 1,000 people have been murdered in Israel, including numerous children. Israel has retaliated by laying siege to and attacking the Gaza Strip.
The mounting civilian casualties on both sides are heartbreaking. My heart goes out to all individuals, families, and communities affected by the violence.

While there is much to be said about rights and wrongs committed by all sides over the past 75 years, there is absolutely no excuse for deliberately targeting civilians or threatening to execute hostages. This is a time for all people of conscience to condemn these heinous acts. It is also time to call on everyone to respect human rights and the international rule of law.
I hope the AI community can play a constructive role in preserving lives as well as promoting civil liberties and democracy. In this moment and in coming years, I hope we remain united as a community, keep pushing for human rights, and decry any violations thereof.
Andrew
News
GPT-4 Opens Its Eyes
Few people have had a chance to try out OpenAI’s GPT-4 with Vision (GPT-4V), but many of those who have played with it expressed excitement.
What’s new: Users who had early access to the image-savvy update of GPT-4, which began a gradual rollout on September 24, flooded social media with initial experiments. Meanwhile, Microsoft researchers tested the model on a detailed taxonomy of language-vision tasks.
Fresh capabilities: Users on X (formerly Twitter) tried out the model in situations that required understanding an image's contents and contexts, reasoning over them, and generating appropriate responses.
- One user gave GPT-4V a photograph of a traffic pole festooned with several parking signs, entered the time and day, and asked, “Can I park here?” The model read the signs and correctly replied, “You can park here for one hour starting at 4PM.”
- Another built a “frontend engineer agent” that enabled the model to turn a screenshot of a webpage into code, then iteratively improve the program to eliminate coding and design errors.
- Shown a single frame from the 2000 Hollywood movie Gladiator, the model correctly identified Russell Crowe as the character Maximus Decimus Meridius and supplied Crowe’s dialogue (“are you not entertained?”).
- GPT-4V behaved like a personalized tutor when it was shown a diagram of a human cell and asked to describe its parts at a ninth-grade level.
Microsoft takes stock: Zhengyuan Yang and colleagues probed GPT-4V’s capabilities and evaluated prompting techniques in a wide variety of tasks that involve subtle interactions between images, words, and computer code. They reported only qualitative results — both positive and negative — leaving it to other researchers to compare the model’s performance with that of competitors like LLaVA.
- Researchers prompted the model visually. Highlighting areas of interest in an image with boxes or text labels further improved its performance.
- Presented with an out-of-order image sequence, GPT-4V identified which event came first and predicted what would happen next. Conversely, given an ordered sequence, it described the action.
- Given a photo of a coastal landscape and asked to reduce a viewer’s desire to visit, the model explained that the rocks were sharp and slippery and provided no place to swim.
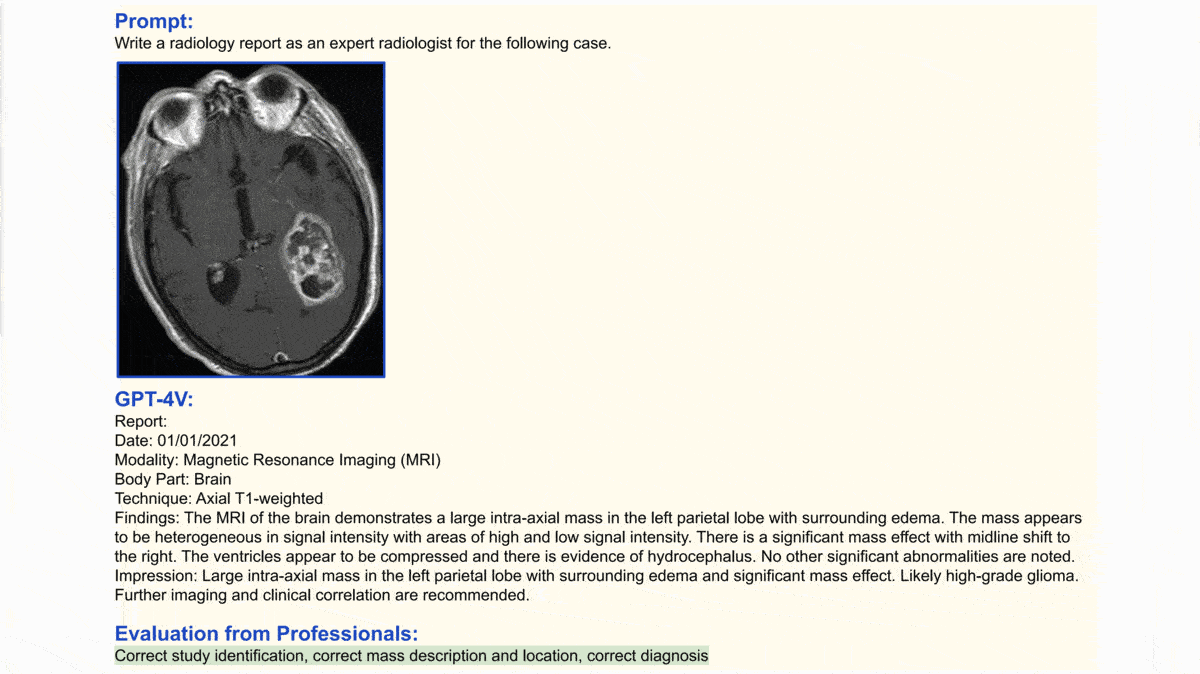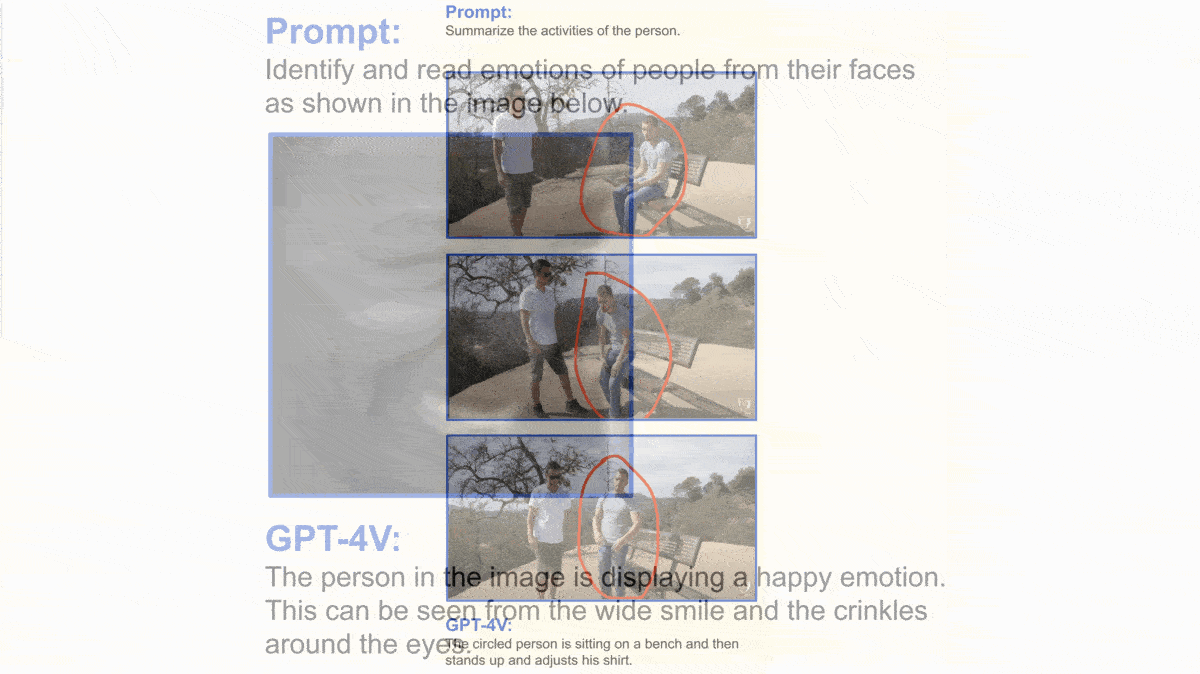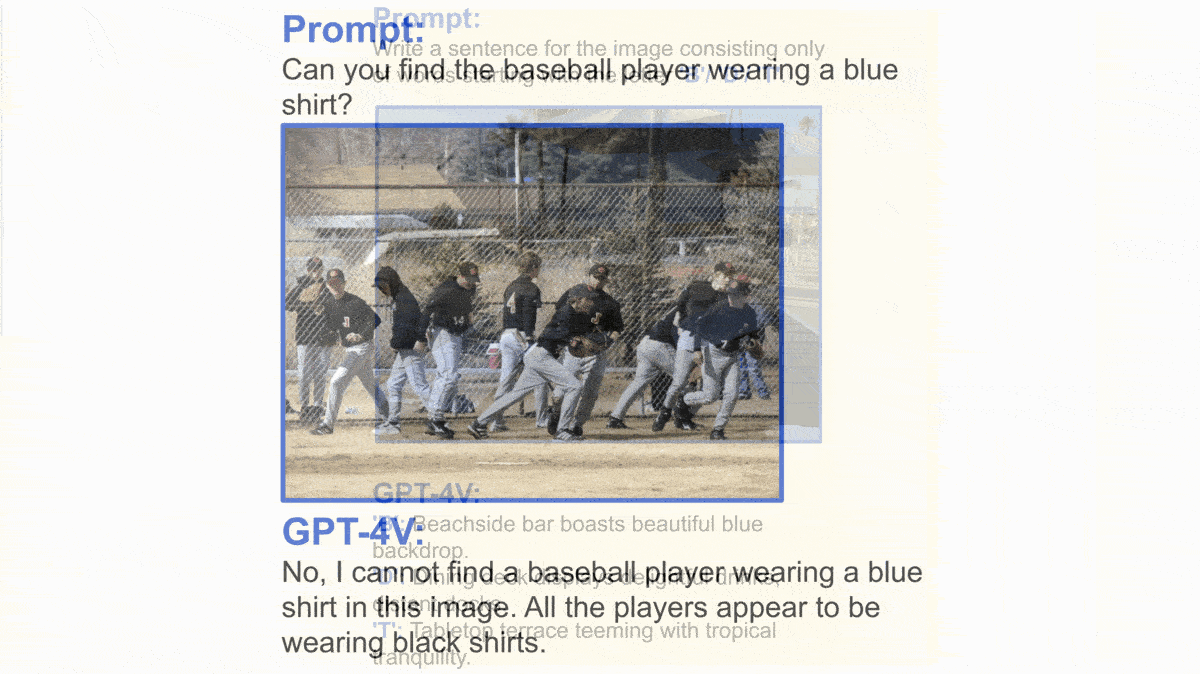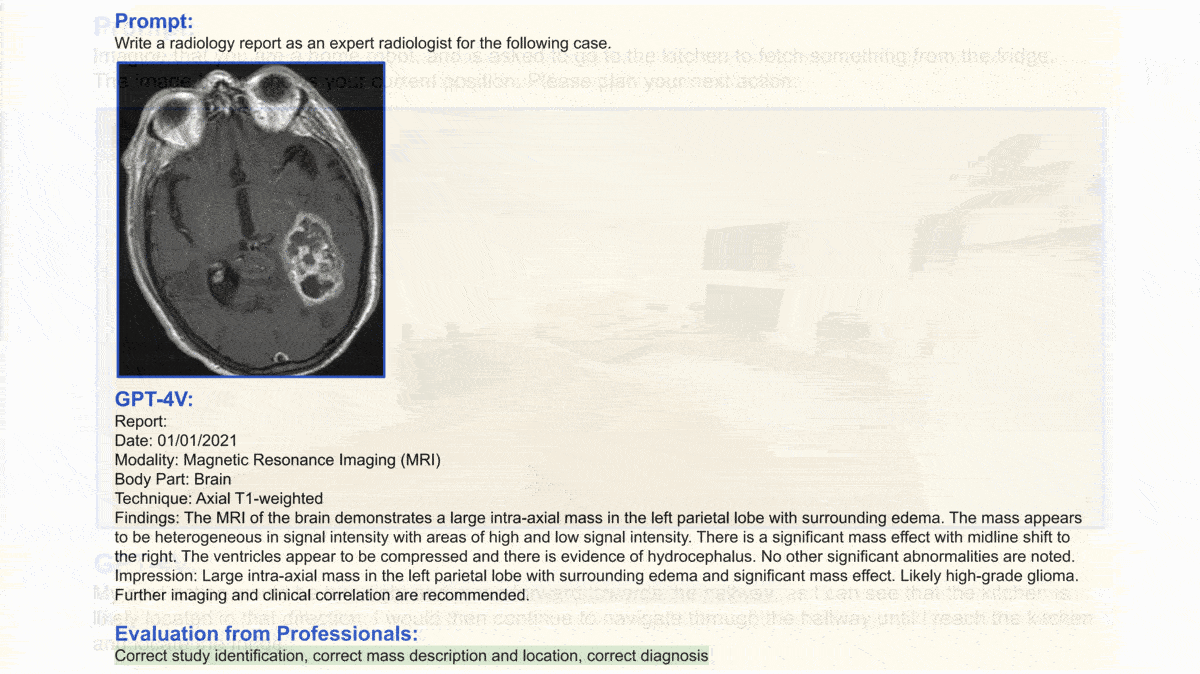
- Given an MRI of a cranium and asked to write a report as an expert radiologist, it proposed the correct diagnosis, according to an “evaluation from professionals.”
- Image captions generated by GPT-4V contained more detail than ground-truth examples, leading the authors to conclude that existing benchmarks wouldn’t do justice to its ability to understand the contents of an image.
Yes, but: These qualitative examples are impressive, but they were cherry-picked to give only a glimpse of GPT-4V’s capabilities. Microsoft noted that the model’s behavior is inconsistent. It remains to be seen how reliably it can perform a given task.
Why it matters: GPT-4V is an early entry in a rising generation of large multimodal models that offer new ways to interact with text, images, and combinations of the two. It performs tasks that previously were the province of specialized systems, like object detection, face recognition, and optical character recognition. It can also adapt, alter, or translate images according to text or image prompts. The prospects for integration with image editors, design tools, coding tools, personal assistants, and a wide range of other applications are tantalizing.
We’re thinking: When the text-only version of GPT-4 became available, OpenAI didn’t report quantitative results for a couple of weeks (and it still hasn’t presented a detailed view of its architecture and training). We look forward to a clearer picture of what GPT-4V can do.
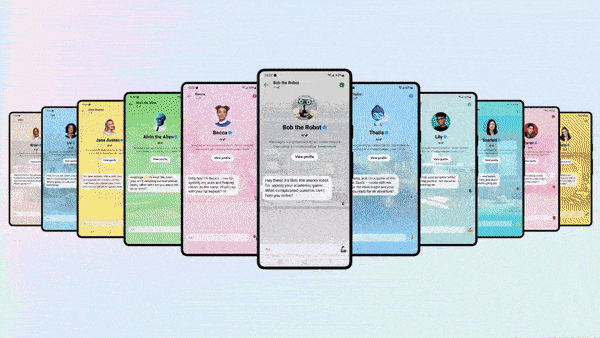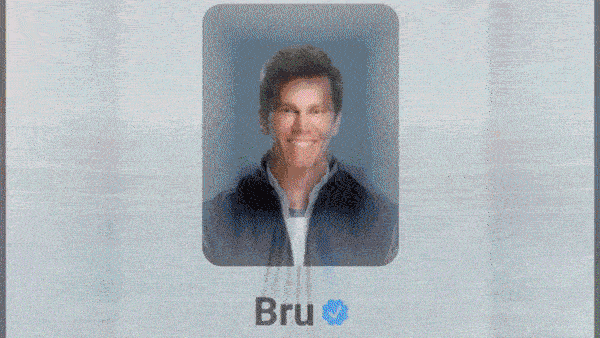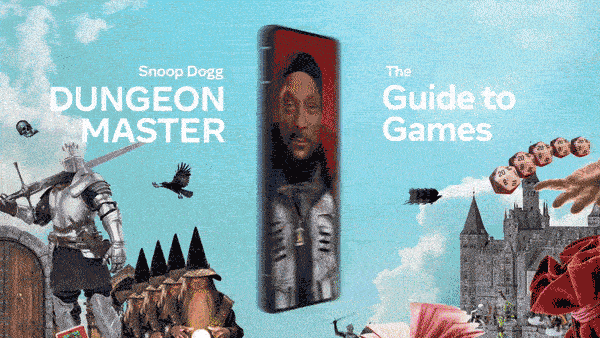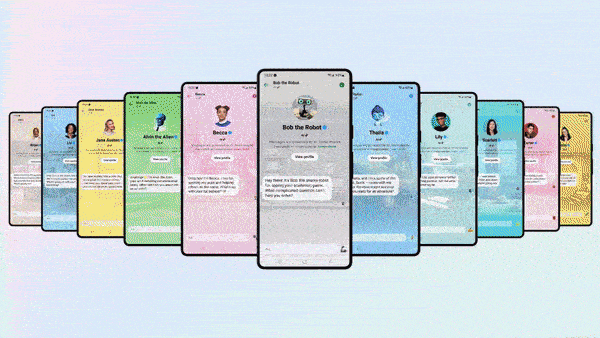
Facebook’s Generative Facelift
Meta is rolling out AI-powered upgrades to its social platforms.
What’s new: Meta announced a chat interface, image generator, and celebrity tie-ins for Facebook, Instagram, Messenger, and WhatsApp.
How it works: The new capabilities take advantage of LLaMa 2 and an unnamed image generator, presumably CM3leon (pronounced “Chameleon”), which Meta described in July.
- Facebook, Instagram, and WhatsApp users can converse with chatbots adorned with the faces of real-life celebrities. The one named Dungeon Master bears the likeness of rapper Snoop Dogg, sports enthusiast Bru looks like retired quarterback Tom Brady, and whodunit detective Amber looks like socialite Paris Hilton. A cadre of non-celebrity bots is available, too, including mom, career-coach, singer-songwriter, robot, and space-alien personas.
- The same apps will add Meta AI, a chatbot that answers questions and produces images. Meta AI, which can search the web via Microsoft’s Bing, is available as a beta test in the U.S. only. It will be available later this month on Meta’s Quest 3 virtual reality headset and an upcoming line of Ray-Ban augmented-reality glasses.
- Emu, an image generator, can produce or alter images according to prompts like “watercolor” or “surrounded by puppies.” It also turns brief prompts into stickers that users can send to each other via Facebook Stories, Instagram, Messenger, and WhatsApp. Stickers will roll out to a small group of English-speaking users within a month. No release date yet for the other capabilities.
Behind the news: Meta has lagged behind its big-tech peers in commercializing its AI research. Current and former Meta employees blamed the delay on factors including staff turnover, a shortage of high-end chips, a focus on research over products, and management’s lack of enthusiasm for large language models. Lately, the release of restricted open source models such as Llama 2 has raised the company's profile as an AI powerhouse.
Why it matters: Social networking is a natural venue for generated text and images, from suggested language for social posts to pictures that reflect a user’s flight of fancy. Meta’s products include some of the most popular mobile apps, which gives nearly 4 billion users access to AI with a mass-media twist.
We’re thinking: Chatbots that look and talk like celebrities are an interesting concept, but users need to know they’re not chatting with a real person. Meta’s celebrity bots bear a familiar likeness while making clear that it represents an artificial character — an intriguing solution. On the other hand, at least one of the company’s non-celebrity bots, whose faces are unfamiliar, has been caught insisting it’s a human being.
A MESSAGE FROM DEEPLEARNING.AI

In this short course, you’ll learn how to use the open source LangChain framework to build a chatbot that interacts with your business documents or other personal data. Enroll today for free
Newsroom AI Poses Opportunities, Challenges
Journalists are approaching text generators with cautious optimism, a new study shows.
What’s new: Researchers at the London School of Economics and Political Science surveyed workers at over 100 news organizations worldwide. 85 percent of respondents said they had experimented with generative AI.
How it works: The authors asked journalists, technologists, and managers how their newsrooms were using generative AI and how they felt about the technology.
- 75 percent of newsrooms surveyed used AI to gather news. 90 percent used AI to produce reports, and 80 percent used it to distribute them.
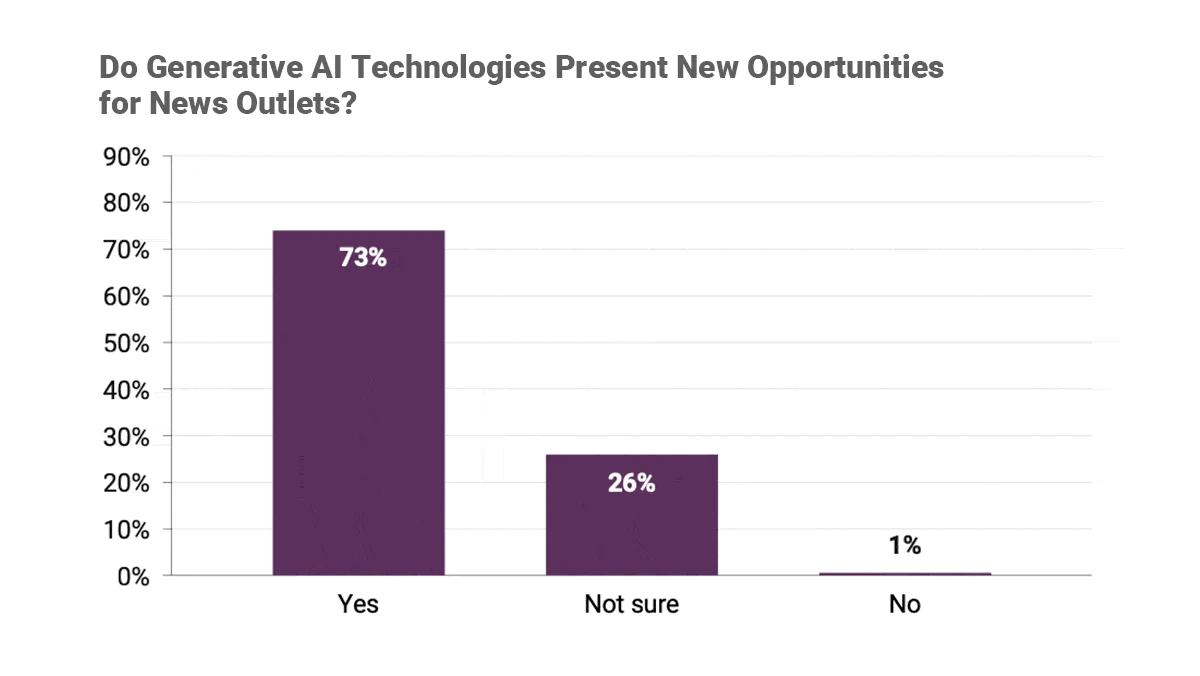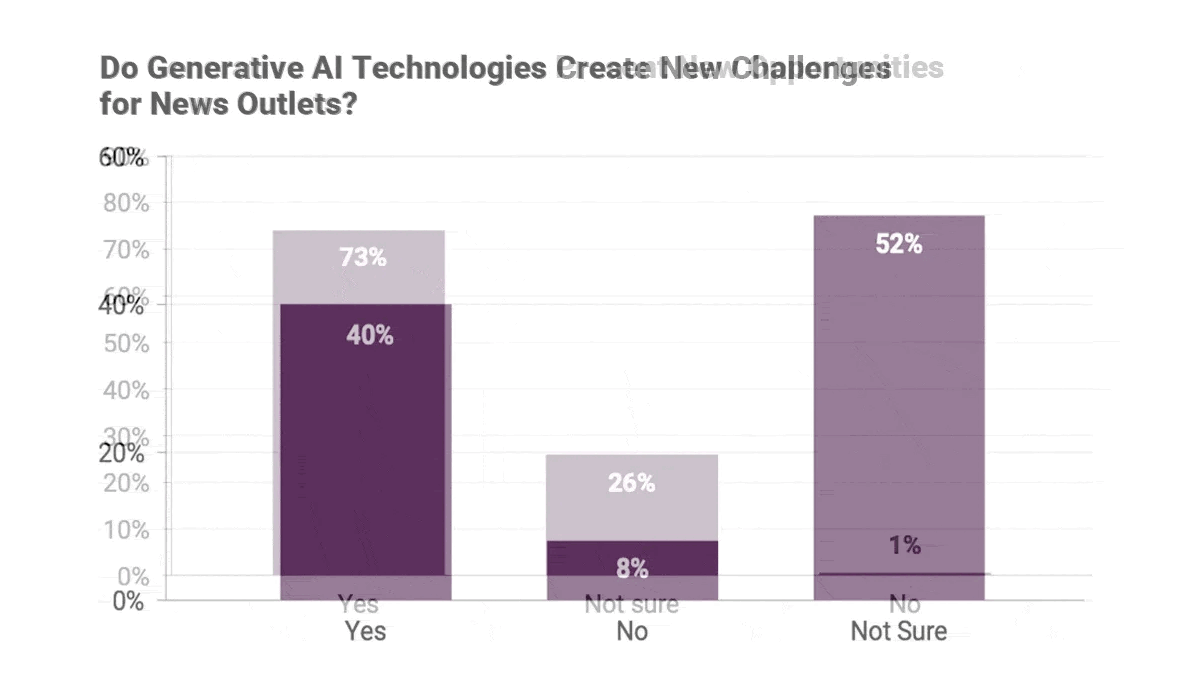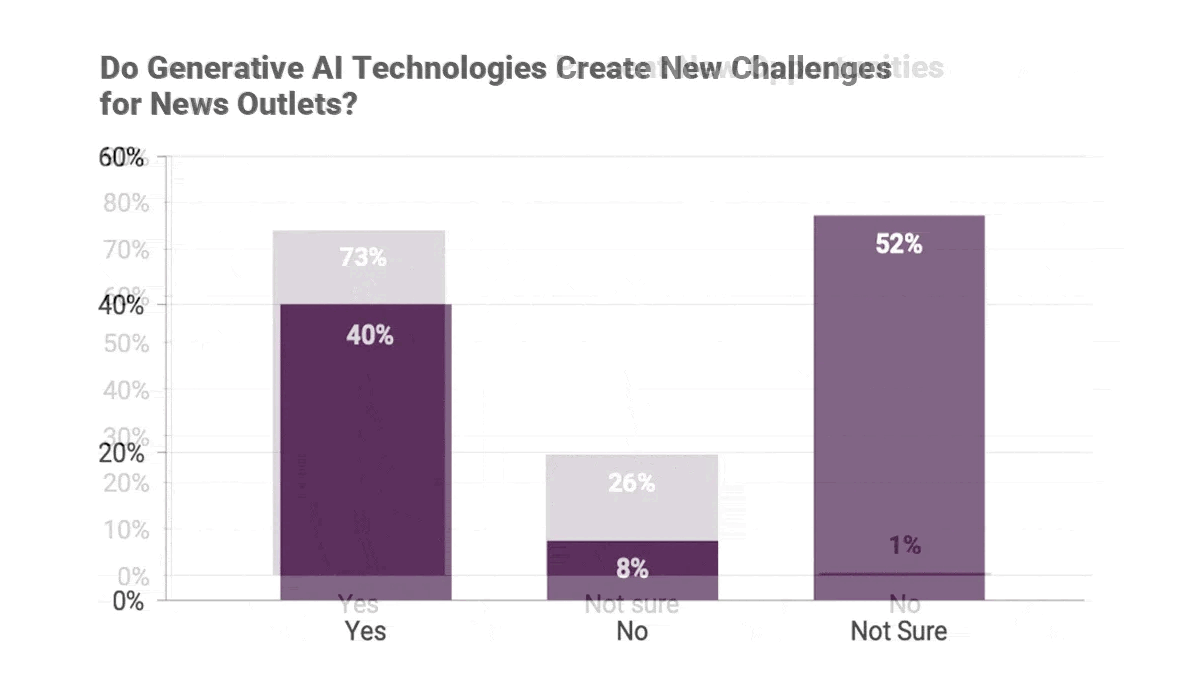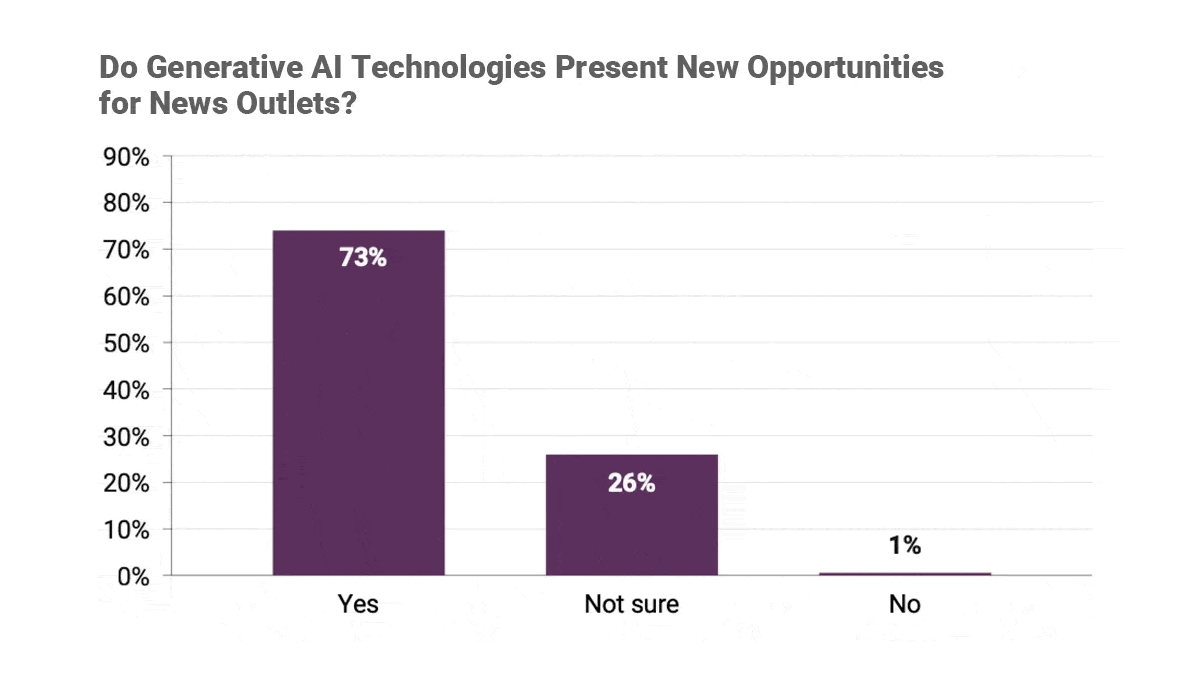
- Respondents at 73 percent of newsrooms surveyed said generative AI presented new opportunities. Some argued that generative models were more democratic than other digital technologies, because using them did not require coding skills.
- 40 percent of respondents said generative AI presented new challenges, such as its potential to produce falsehoods. 82 percent were concerned that it would damage editorial quality, while 40 percent were concerned that it would degrade readers’ perceptions of the media.
- Respondents outside Europe and North America noted that existing AI tools trained on data from those places failed to capture the cultural contexts of other regions. Others worried that independent newsrooms in poor regions did not have enough resources to deploy AI tools.
Behind the news: Publishers have been eager to take advantage of large language models, but the results so far have been mixed.
- CNET and Gizmodo published articles that were generated by AI but edited by humans. Readers pointed out factual errors and plagiarism.
- In August, The Associated Press issued guidelines for news outlets that advised them to treat generated text with caution but avoid generated images, video, or audio.
- Some efforts are widely regarded as successful. The Washington Post’s Heliograf has produced articles from structured data since 2016. The Times of London’s JAMES content management system uses machine learning to personalize the contents of its newsletters.
Why it matters: In a few short decades, journalism has suffered techno-shocks wrought by the web and social media. Generative AI is poised to bring a third wave of change and challenge, but journalists are generally confident that they can benefit from the technology.
We’re thinking: We recently distinguished between jobs and the tasks they comprise. While AI can perform some tasks at a human level, currently it rarely performs so well on all the tasks in a given job. We encourage publishers to adopt this framework and devise fruitful ways to allocate journalists’ tasks among human-only, machine-only, and human-plus-machine modes.
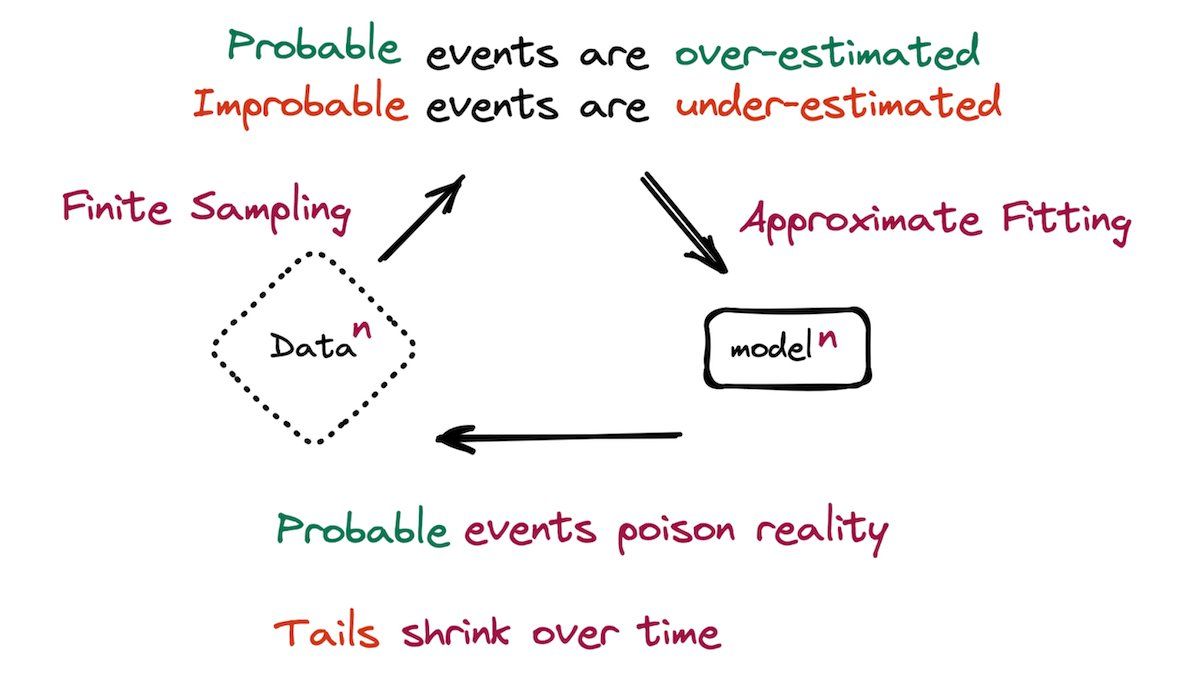
Training on Generated Data Skews Model Performance
How accurate are machine learning models that were trained on data produced by other models? Researchers studied models that learned from data generated by models that learned from data generated by still other models.
What’s new: Ilia Shumailov and Zakhar Shumaylov and colleagues at University of Oxford, University of Cambridge, Imperial College London, University of Toronto, Vector Institute, and University of Edinburgh argue — both theoretically and empirically — that models, when they’re trained almost exclusively on the output of earlier models, learn a distorted data distribution.
Key insight: Trained models are less likely to generate types of examples that appear infrequently in their training data. Moreover, they don’t model their training data perfectly, so their output doesn’t quite match the distribution of the training dataset. They may combine elements from training examples. When one model learns from another in a series, errors accumulate — a phenomenon the authors call model collapse.
How it works: The authors trained models of different types. First they trained a model on a human-collected and -curated dataset — generation 0. Then they trained generation 1 of the same architecture on the output of generation 0, generation 2 on the output of generation 1, and so on. In some cases, they replaced a fraction of the generated examples with examples from the original training set.
- The authors trained a Gaussian mixture model (GMM), which assumed that input data came from a pair of 2-dimensional Gaussian distributions and clustered the data to fit them. They trained 2,000 generations of GMMs on 1,000 examples generated by the previous-generation model, using no original data.
- They trained a variational autoencoder (VAE) to generate MNIST digits over 20 generations. As with the GMMs, they trained each successive generation only on output produced by the previous generation.
- They fine-tuned a pretrained OPT language model (125 million parameters) on WikiText-2. They fine-tuned 9 subsequent generations (i) only on examples produced by the previous generation and (ii) on a mixture of 90 percent data from the previous generation and 10 percent original training data.
Results: The first-generation GMM recognized the Gaussians as ellipses, but each successive generation degraded their shape. By generation 2,000, the shape had collapsed into a tiny region. Similarly, the late-generation VAEs reproduced MNIST digits less accurately; by generation 20, the output looked like a blend of all the digits. As for the OPT language models, generation 0 achieved 34 perplexity (which measures how unlikely the model is to reproduce text in the test set; lower is better). Trained only on generated data, successive generations showed decreasing performance; generation 9 achieved 53 perplexity. Trained on 10 percent original data, successive generations still performed worse, but not as badly; generation 9 achieved 37 perplexity.
Yes, but: The authors’ recursive training process is a worse-case scenario, and generated data does have a place in training. For instance, Alpaca surpassed a pretrained LLaMA by fine-tuning the latter on 52,000 examples produced by GPT-3.5.
Why it matters: The advent of high-quality generative models gives engineers an option to train new models on the outputs of old models, which may be faster and cheaper than collecting a real-world dataset. But this practice, taken to extremes, can lead to less-capable models. Moreover, if models are trained on data scraped from the web, and if the web is increasingly populated by generated media, then those models likewise will become less capable over time.
We’re thinking: To produce output that could be used for training without bringing on model collapse, a data generator would need access to sources of novel information. After all, humans, too, need fresh input to keep coming up with new ideas.
Data Points
Bill Gates-backed startup Likewise joins the AI chatbot race
The chatbot, called “Pix,” offers personalized recommendations for books, movies, TV shows, and podcasts. Pix uses OpenAI technology and consumer data to learn a user’s preferences over time. Pix updates its recommendations in real-time to align with the content offerings on popular streaming platforms like Netflix, Hulu, and Max. (The Wall Street Journal)
OpenAI explores in-house chip production
The company is reportedly contemplating potential acquisitions in order to develop its own AI chips. This would be a response to the global chip shortage and the high costs of keeping ChatGPT running. (Reuters)
Global survey reveals AI’s impact on scientific research
The survey, conducted by the scientific journal Nature, found a complex landscape where scientists express both enthusiasm and concerns about the growing use of AI in research. Over half of the respondents believe that AI tools will be “very important” or “essential” to their fields within the next decade. However, they also express concerns regarding issues such as bias and fraud. (Nature)
A search tool lets you find books used to train AI models without permission
The dataset, called Books3, contains around 183,000 books with associated author information. Authors and readers can now search it to discover which titles are included in the dataset, which has been used to train AI products from Meta, Bloomberg, and others. The situation highlights the challenges and secrecy surrounding AI training practices. (The Atlantic)
Adobe Firefly announces new features and enhancements
Since its launch in March 2023, Firefly has generated 3 billion images. Now it’s bringing new offerings like a Text to Vector Graphic for Adobe Illustrator, Generative Match to apply styles from a preselected set of images, and Prompt Suggestions to generate improved results. (Adobe)
App developer startup Docker introduces AI feature to its suite of developer tools
The feature will help developers troubleshoot all aspects of their apps by providing context-specific, automated guidance when editing, debugging, or running tests. Docker argues that their tools expand AI assistance from source code to front-end development, databases, and other development technologies. (Docker)
French startup Mistral AI launches open source large language model
Mistral 7B, released under the Apache 2.0 license, claims to offer competitive capabilities at a lower computational cost than more costly models available only via APIs or the cloud. While the model is open for all to use, Mistral's business plan relies on offering commercial white-box solutions and dedicated enterprise deployment. (Mistral)
A new report details the full costs of computing power
The AI Now Institute’s document examines the hardware supply chain, how the demand for computing power is shaping AI development, and how governments and other policy makers are beginning to respond to computational bottlenecks. The report also explores possible regulatory interventions that might make AI companies more competitive and less dependent on a small number of computing providers. (AI Now)