
Dear friends,
I’d like to share a part of the origin story of large language models that isn’t widely known. A lot of early work in natural language processing (NLP) was funded by U.S. military intelligence agencies that needed machine translation and speech recognition capabilities. Then, as now, such agencies analyzed large volumes of text and recorded speech in various languages. They poured money into research in machine translation and speech recognition over decades, which motivated researchers to give these applications disproportionate attention relative to other uses of NLP.
This explains why many important technical breakthroughs in NLP stem from studying translation — more than you might imagine based on the modest role that translation plays in current applications. For instance, the celebrated transformer paper, “Attention is All You Need” by the Google Brain team, introduced a technique for mapping a sentence in one language to a translation in another. This laid the foundation for large language models (LLMs) like ChatGPT, which map a prompt to a generated response.
Or consider the BLEU score, which is occasionally still used to evaluate LLMs by comparing their outputs to ground-truth examples. It was developed in 2002 to measure how well a machine-generated translation compares to a ground truth, human-created translation.
A key component of LLMs is tokenization, the process of breaking raw input text into sub-word components that become the tokens to be processed. For example, the first part of the previous sentence may be divided into tokens like this:
/A /key /component /of /LL/Ms/ is/ token/ization
The most widely used tokenization algorithm for text today is Byte Pair Encoding (BPE), which gained popularity in NLP after a 2015 paper by Sennrich et al. BPE starts with individual characters as tokens and repeatedly merges tokens that occur together frequently. Eventually, entire words as well as common sub-words become tokens. How did this technique come about? The authors wanted to build a model that could translate words that weren’t represented in the training data. They found that splitting words into sub-words created an input representation that enabled the model, if it had seen “token” and “ization,” to guess the meaning of a word it might not have seen before, such as “tokenization.”
I don’t intend this description of NLP history as advocacy for military-funded research. (I have accepted military funding, too. Some of my early work in deep learning at Stanford University was funded by DARPA, a U.S. defense research agency. This led directly to my starting Google Brain.) War is a horribly ugly business, and I would like there to be much less of it. Still, I find it striking that basic research in one area can lead to broadly beneficial developments in others. In similar ways, research into space travel led to LED lights and solar panels, experiments in particle physics led to magnetic resonance imaging, and studies of bacteria’s defenses against viruses led to the CRISPR gene-editing technology.
So it’s especially exciting to see so much basic research going on in so many different areas of AI. Who knows, a few years hence, what today’s experiments will yield?
Keep learning!
Andrew
P.S. Built in collaboration with Microsoft, our short course “How Business Thinkers Can Start Building AI Plugins With Semantic Kernel” is now available! This is taught by John Maeda, VP of Design and AI (who also co-invented the Scratch programming language!). You’ll join John in building his “AI Kitchen” and learn to cook up a full AI meal from, well, scratch – including all the steps to build full business-thinking AI pipelines. You’ll conclude by creating an AI planner that can automatically select plugins it needs to produce multi-step plans with sophisticated logic. Sign up to learn here!
News

Industrial-Strength LLM
Anthropic, the startup behind the safety-focused Claude chatbot, teamed up with South Korea’s largest mobile phone provider.
What’s new: The independent research lab, which is an offshoot of OpenAI, will receive $100 million from SK Telecom to build a multilingual large language model tailored for the telecommunications industry, VentureBeat reported.
How it works: Anthropic will base the specialized model on the technology that underpins its large language model Claude. SK Telecom plans to offer it to other telecoms firms, such as members of the Global Telco AI Alliance, a consortium devoted to building new lines of business based on AI-driven services.
- The model will be fine-tuned for telecoms applications like customer service, marketing, and sales.
- It will support six languages: Korean, English, German, Japanese, Arabic, and Spanish.
- Claude takes advantage of constitutional AI, a method designed to align large language models and human values based on a set of principles, or constitution. Initially, the model critiques and refines its own responses according to the constitution. Then it’s fine-tuned on the results via supervised learning. This is followed by a phase that Anthropic calls reinforcement learning from AI feedback, or RLAIF.
Behind the news: SK Telecom has a history of building its own machine learning models, particularly Korean-language models. The company emulated GPT-3's architecture to train models like Ko-GPT-Trinity-1.2B. An unidentified model enables A. (pronounced “a dot”), a virtual assistant for the company’s mobile users.
Why it matters: AI models have a bright future in virtually every industry, and specialized AI models have an even brighter outlook. Like BloombergGPT, this partnership represents a step toward adapting foundation models to a vertical industry, along with a new business model for good measure.
We’re thinking: Prompting a foundation model can go a long way in tasks for which it’s easy to write instructions that describe clearly what you want done. But many tasks involve specialized knowledge that’s difficult to put into a prompt; for instance, consider explaining how to draft a good legal document. In such cases, fine-tuning or specialized training can be a promising approach.

China Restricts Face Recognition
China’s internet watchdog proposed sweeping limitations on face recognition — with significant exceptions.
What’s new: The Cyberspace Administration of China unveiled draft rules that restrict the use of face recognition systems, with explicit carve-outs when national security or public or personal safety is at stake. The public can submit feedback before September 7.
Narrow limits, broad exceptions: The proposal, which will affect mainland China but not Macau or Hong Kong, applies to both public and private users of face recognition. It follows recent restrictions on generative AI and collecting personal data.
- Face recognition can’t be used to analyze race, ethnicity, religion, health status, or social class except to protect national security or public or personal safety.
- It can’t be used to identify people in public places at a distance except to protect national security or public or personal safety.
- Face recognition is allowed for verifying identity only if other methods aren't available.
- It isn’t allowed in locations where it may infringe on personal privacy, such as hotel rooms or toilets.
- Users can’t coerce or mislead the public into providing face data with excuses such as “improving service quality.”
- Institutions that use face recognition in public locations or store images of more than 10,000 faces must register their use and data-handling procedure with the government.
- Before gathering face data, users must obtain the subject’s permission, or a parent’s or guardian’s if the subject is less than 14 years old.
Behind the news: China leads the world in developing and deploying face recognition. Authorities use it widely in law enforcement, while businesses use it for authenticating payments, checking the identities of air and rail passengers, and granting access to residential buildings. Nonetheless, many Chinese residents have voiced their unease with the technology.
- In 2021, a Chinese appeals court ruled in favor of a law professor who sued a Hangzhou zoo. The plaintiff claimed that the zoo’s use of face recognition to verify its visitors’ identities was unnecessary.
- 74 percent of Chinese residents surveyed favored alternatives to face recognition for verifying identity, according to a 2019 survey conducted by Beijing’s Nandu Personal Information Protection Research Centre. 80 percent of respondents were concerned about data security, and 84 percent wanted the option to review face-recognition data that represented them.
Yes, but: The exemptions for national security and safety give China’s government authority to continue using the technology for potentially controversial applications.
Why it matters: Face recognition is a double-edged sword. It has legitimate uses for security and law enforcement, but it can also be misused to violate privacy. Such concerns motivated European Union lawmakers to insert a prohibition on face recognition in public spaces into the current draft of the union’s AI Act, which is in the final stage of revision. China’s new rules bring that country’s face recognition policy closer into line with that standard — the exceptions for national security and public safety notwithstanding.
We’re thinking: It’s interesting to see China take the lead in regulating face recognition, where it dominates the technology and market. We support stronger protections for personal privacy.
A MESSAGE FROM DEEPLEARNING.AI

Learn how to utilize Semantic Kernel, Microsoft’s open source SDK, to develop sophisticated business applications using LLMs. Sign up for free
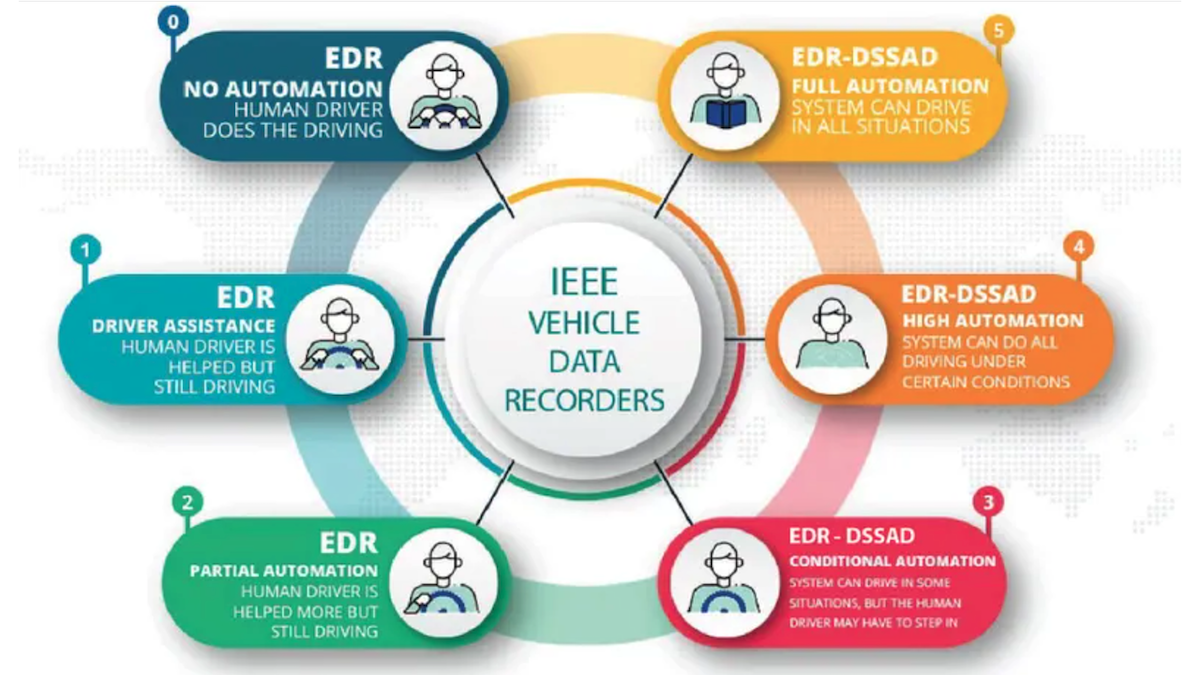
Crash Tracker
Event data recorders, also known as black boxes, got an update for the era of self-driving cars.
What’s new: The Institute of Electrical and Electronics Engineers published guidelines for internal devices that track the performance of autonomous road vehicles.
How it works: Like airplanes, cars and trucks carry event data recorders that capture their moment-to-moment behavior for examination in the event of a crash. The new specification calls for vehicles with Level 3 autonomous capabilities or higher, which can drive themselves but may require a human driver to take over, to carry a recorder dedicated to automated driving functions. The working group will meet later this year to discuss further revisions that address subjects like cybersecurity and protocols accessing recorded data.
- The autonomous-driving recorder logs when a vehicle’s self-driving function is activated or deactivated, when the driver’s action overrides it (for instance, by manually braking or turning the wheel), or when it overrides a driver’s action.
- The recorder also logs when the vehicle fails to stay in its lane, starts or ends an emergency maneuver, suffers a major malfunction, or collides with another object.
- The minimum log entry includes an event, the event’s cause, and its date and timestamp to the second.
- A tamper-resistant electronic lock restricts access to recorded data.
Behind the news: Event data recorders became a fixture in road vehicles decades ago as a way to evaluate the performance of safety airbags. Today, they record parameters such as speed, acceleration, and braking in 99 percent of new vehicles in the United States. They’ll be mandatory in new cars in the European Union starting next year.
Why it matters: As more automated driving systems hit the road, safety concerns are on the rise. Event data recorders help shed light on mishaps, and the resulting data can help authorities, manufacturers, and consumers to understand the role, if any, played by self-driving technology. Although compliance is voluntary, IEEE standards are influential and widely followed.
We’re thinking: Self-driving systems have the potential to reduce road and pedestrian fatalities dramatically. A clear picture of what goes wrong and why will enable engineers to improve self-driving technology steadily. Ultimately, we hope, accidents will become rare and relatively inconsequential.

Text-To-3D Animation
Text-to-video generation is so 2022! A new system takes in text and generates an animated 3D scene that can be viewed or rendered from any angle.
What’s new: Uriel Singer and colleagues at Meta AI proposed Make-A-Video3D (MAV3D). Lacking a corpus of matched text and animated 3D scenes, the authors used a pretrained text-to-video diffusion model to guide the training of a neural radiance field (NeRF) model that learned how to represent a 3D scene with moving elements. You can see MAV3D’s output here.
Key insight: Earlier work known as DreamFusion learned to produce a 3D scene from text by setting up a feedback loop between a pretrained diffusion text-to-image generator, which creates 2D images according to a text prompt, and a NeRF, which takes embeddings of points in space and learns to produce a 3D scene (mesh, point colors, and point transparencies) to match the 2D images shot from various angles. (NeRF can also generate images of the scene.) Basically, (i) the NeRF generated 2D images of a random 3D scene; (ii) the images — with added noise — were given as input to the diffusion text-to-image generator, which sharpened them according to the text prompt; and (iii) the NeRF used the sharpened images to sharpen the 3D scene, repeating the cycle. MAV3D worked the same way but (a) used a more computationally efficient embedding method called HexPlane, (b) swapped the pretrained text-to-image generator for a pretrained text-to-video generator, and (c) modified the NeRF to generate sequences of video frames. The resulting system takes a text prompt and learns to generate a matching 3D scene that changes over time.
How it works: MAV3D is an animated version of the earlier DreamFusion, as described above. It includes the following models: HexPlane (which efficiently represents an animated 3D scene), Make-A-Video (a text-to-video generator pretrained on LAION-5B text/image pairs and fine-tuned on 20 million videos), and a NeRF modified for video/animation.
- HexPlane learned an embedding for each point on each 2D plane in an animated 3D scene (xy, xz, xt, yz, yt, and zt) over 16 video frames. Given a point (three spatial dimensions plus time), the model projected it onto each plane, retrieved the corresponding embeddings, and concatenated them to produce a point embedding.
- Given the embeddings and a random camera position per frame, NeRF produced a video.
- The system added noise to the NeRF video and fed it to Make-A-Video. Given a text prompt, Make-A-Video estimated what the video would look like without the noise.
- The loss function minimized the difference between the NeRF video and Make-A-Video’s denoised version to update HexPlane and NeRF.
- The system cycled through this process 12,000 times using a different random camera trajectory each time, which enabled it to evaluate every point from multiple angles.
- The authors extracted from NeRF a 64-frame animated 3D scene using the marching cubes algorithm.
Results: No other system generates animated 3D scenes from text, so the authors compared MAV3D with systems that solve two sub-tasks, generating 3D static scenes from text and generating videos from text. They used CLIP R-Precision, a metric that evaluates the similarity between an image and a text description (higher is better), to measure the systems’ performance averaged across a number of images taken from different angles (for 3D scenes) or images over time (for videos). MAV3D outperformed a Stable Diffusion implementation of DreamFusion (82.4 CLIP R-Precision versus 66.1 CLIP R-Precision). However, it did worse than Make-A-Video (79.2 CLIP R-Precision versus 86.6 CLIP R-Precision).
Yes, but: Examples of MAV3D’s output include very short scenes of varying quality. The system allows only one color per point so, for instance, reflective surfaces look the same regardless of viewing angle. It’s also computationally demanding: It took 6.5 hours per scene using eight A100 GPUs.
Why it matters: Adapting NeRF for video/animation is exciting, but the larger lesson is that finding an efficient way to learn representations — HexPlane in this case — can make tasks feasible that otherwise would require impractical amounts of computation.
We’re thinking: While MAV3D’s rendering would be improved by variable colors to represent reflections, shadows, and dynamic lighting, its strong performance relative to DreamFusion suggests a way to improve text-to-3D: train on videos instead of images. Videos contain moving objects and sometimes changing camera positions, so they can depict more diverse 3D geometry than a set of static images. Learning from videos could avoid generating 3D images that look fine from only one angle at a time.