
Dear friends,
Many accomplished students and newly minted AI engineers ask me: How can I advance my career? Companies in many industries are building AI teams, but it may not be obvious how to join one of them.
Different companies organize their teams differently and use different terms to describe the same job. Even more confusing, job titles don’t correspond directly with common AI tasks like modeling and data engineering.
What positions are responsible for which tasks? What skills are recruiters looking for? Which opportunities are right for you?
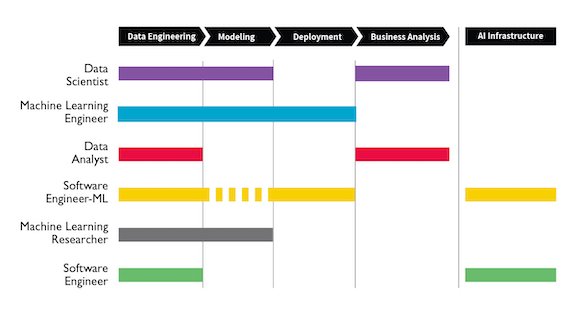
Workera, a deeplearning.ai affiliate, interviewed over 100 leaders in machine learning and data science to answer these questions. They summarized their findings in a report called “AI Career Pathways: Put Yourself on the Right Track.”
“AI Career Pathways” is designed to guide aspiring AI engineers in finding jobs and building a career. The table above shows Workera’s key findings about AI roles and the tasks they perform. You’ll find more insights like this in the free PDF.
I invite you to read Workera’s report and compare its findings with your own experience, talents, and skills. This will help you understand how AI teams work, what role might fit you best, and which skills you can develop to position yourself for a particular role. You can download it here.
Keep learning!
Andrew
News

ImageNet Gets a Makeover
Computer scientists are struggling to purge bias from one of AI’s most important datasets.
What’s new: ImageNet’s 14 million photos are a go-to collection for training computer-vision systems, yet their descriptive labels have been rife with derogatory and stereotyped attitudes toward race, gender, and sex. Researchers replaced a slew of biased labels and are working on further upgrades, according to Wired. (To be clear, the ImageNet Challenge training set is a subset of 1.2 million images and 1,000 classes.)
How it works: Scientists at Princeton and Stanford, including Fei-Fei Li, who built the first version of ImageNet a decade ago, are updating both the dataset and its website.
- ImageNet’s labels were based on WordNet, a 1980s-era database of word relations. ImageNet’s compilers took WordNet as it was, despite changes in social standards since it was compiled. To weed out slurs and other offensive labels, the Princeton-Stanford team combed through the 2,832 descriptions in ImageNet’s <person> category. They cut nearly 60 percent of <person> labels.
- ImageNet’s original army of freelance labelers also often tagged photos with subjective labels. A person standing in a doorway, for instance, might be labelled host. To clean up the data, the Princeton-Stanford researchers rated words on how easy they were to visualize. They removed low-scoring words in the <person> subtree, eliminating nearly 90 percent of the remaining labels.
- The researchers are working to address general lack of diversity in ImageNet labels. First, they labeled people featured in ImageNet according to perceived sex, skin color, and age. Correlating these demographic identifiers with image labels like programmer or nurse, the researchers found the labels were badly skewed toward particular groups. They propose automatically balancing the diversity of images in each category. The number of images tagged both female and nurse, for instance, would be reduced until it matched those tagged male and nurse.
- A website update will add a button to report offensive images or labels. The researchers are developing a protocol for responding to reported issues.
Behind the news: Late last year, a web app called ImageNet Roulette briefly enabled the public to experience the dataset’s biases firsthand. Users could upload images, and an ImageNet-trained model would classify any faces. The app went viral after users posted on social media selfies tagging them as criminals or racial and gender stereotypes.
Why it matters: ImageNet can be used to pretrain vision models for sensitive applications like vetting job applicants and fighting crime. It is well established that biases in training data can be amplified when a model encounters real-world conditions.
We’re thinking: Bias in AI has been widely discussed for years. It’s surprising that these issues in ImageNet only now are becoming widely recognized —a sign that greater education in bias should be a priority for the AI community. If such biases exist even in ImageNet, they surely exist in many more datasets.
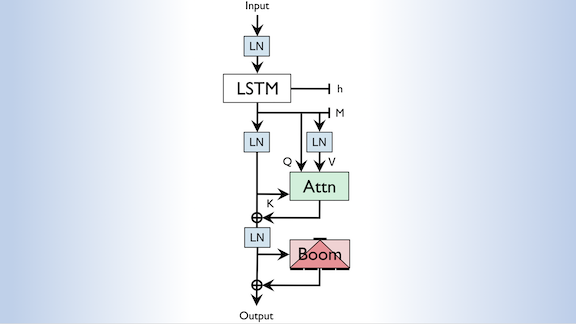
Language Modeling on One GPU
The latest large, pretrained language models rely on trendy layers based on transformer networks. New research shows that these newfangled layers may not be necessary.
What’s new: Networks such as BERT and ERNIE take advantage of multi-headed attention layers to outcompete LSTM language models. But training these layers requires lots of compute on enormous GPU clusters. Stephen Merity of d⁄dx Times Labs struck a blow for garage AI with Single Headed Attention RNN (SHA-RNN), which nearly matched state-of-the-art performance after training on a single GPU for less than 24 hours. As he puts it in a tartly worded paper, “Take that, Sesame Street.”
Key insight: The author set out to find a high-performance language model suitable for his personal computer. He used a single attention head out of skepticism that multiple heads are worth their computational cost. Simplifying the transformer’s feed-forward network enabled him to run the model on a single GPU.
How it works: SHA-RNN is built on an LSTM to represent more explicitly the sequential nature of text.
- The model reads an input text sequence token by token and predicts the next token, usually a word or root of a word. The LSTM’s memory component stores important learned features.
- The LSTM’s output layer feeds the single-headed attention layer, which models relationships between tokens across the sequence.
- The attention layer’s output feeds a so-called boom layer. This layer replaces the transformer’s usual two feed-forward layers with a single feed-forward layer plus a summing layer to maintain vector length.
Results: Merity tested SHA-RNN by compressing the enwik8 dataset. More accurate language models use fewer bits to represent a sequence because they know, to some extent, which words will occur. SHA-RNN achieved 1.068 bits per character compared to 0.99 by Sparse Transformer — slightly less accurate, but in half as many parameters.
Yes, but: An LSTM is a good choice for sequential language-prediction tasks like enwik8. In non-sequential tasks such as fill-in-the-blanks, multi-headed attention is a better choice. A version of Transformer-XL that has even fewer parameters than SHA-RNN performed better on the compression task.
Why it matters: SHA-RNN isn’t an out-and-out replacement for transformer-based networks. But it shows that LSTMs remain relevant and useful in language modeling. And if you’re looking for a way to get people to read your research, the author’s style offers pointers: This paper is a very entertaining read!
We’re thinking: Researchers like to focus on optimizing state-of-the-art methods, and media hype frequently chases the latest leaderboard topper. Yet foundational algorithms remain valuable in a variety of contexts.

Facebook vs Deepfakes
Facebook announced a ban on deepfake videos, on the heels of a crackdown on counterfeit profiles that used AI-generated faces.
What’s new: Facebook declared this week that it will remove deepfake videos it deems deliberately misleading. In December, the company took down hundreds of profiles that included AI-generated portraits of nonexistent people.
How it worked: Facebook’s security team determined that 610 Facebook accounts, 89 pages, 156 groups, and 72 Instagram accounts related to a pro-Donald Trump, anti-Chinese government website were fakes. The accounts used AI-generated faces more extensively than experts had seen before, according to CNN.
- Security researchers spotted the deepfakes based on improbable biology — an oddly-angled neck, mismatched skin tones — or muddled background imagery, as illustrated above. They also looked for telltale asymmetries in features such as glasses and earrings.
- Researchers did not determine the sources of the images. Several websites distribute deepfake portraits, and they are becoming easier to generate from scratch. Deepfaked faces are even being used to populate dating apps.
- The accounts were connected to the Beauty of Life Group, which is linked to the publisher Epoch Media Group, according to the fact-check website Snopes.
- Collectively, the pages had 55 million followers and spent $9.5 million on ads.
Behind the news: Facebook along with Amazon, Microsoft, and the Partnership on AI are running a Deepfake Challenge to spur development of technology to detect such images. Meanwhile, Google has contributed a collection of deepfakes to the FaceForensics benchmark.
Why it matters: Disinformation spread by social media played a role in recent elections from the UK’s Brexit referendum to contests in the U.S. and Philippines. It can look more credible when it’s distributed by a manufactured persona. While faces copied from, say, stock-photo databases can be discovered, deepfaked faces are more difficult to invalidate. That makes deepfakes especially pernicious in this context.
We’re thinking: It’s good to see Facebook taking proactive steps to purge generated media in what promises to be a long, uphill battle.
A MESSAGE FROM DEEPLEARNING.AI

Want to deploy a TensorFlow model in a web browser or on a smartphone? Course 1 and 2 of the deeplearning.ai TensorFlow: Data and Deployment Specialization will teach you how. Enroll now
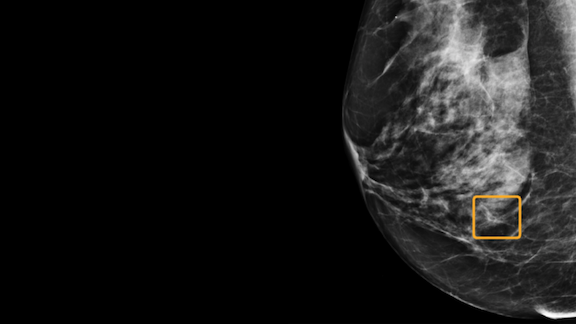
Cancer in the Crosshairs
Computer vision has potential to spot cancer earlier and more accurately than human experts. A new system surpassed human accuracy in trials, but critics aren’t convinced.
What’s new: A computer vision model for diagnosing breast cancer outperformed radiologists in the U.S. and UK, according to a study published in Nature. The announcement, however, met with skepticism from some experts.
How it works: Researchers at Google Health, DeepMind, and other organizations trained a model on 76,000 X-ray images from one U.S. clinic and 30,000 from two UK screening centers. Each image came with data from a follow up visit at least a year later, when doctors either confirmed or ruled out a tumor. The researchers graded the model’s accuracy against average diagnostic accuracy in each country’s health care system.
- A single radiologist had checked U.S. mammograms. Compared with the radiologist, the model produced 9.4 percent fewer false negatives and 5.7 percent fewer false positives.
- In the UK, two human radiologists typically screened each mammogram. Compared to that more rigorous system, the model produced 2.7 percent fewer false negatives and 1.2 fewer false positives.
- The researchers also recruited six U.S. radiologists to analyze 500 of the images. The model outperformed that panel, particularly with respect to more invasive cancers. But it also missed a tumor that all six radiologists found.
Yes, but: The study faced criticism that the dataset, model, and procedural details were not available to researchers aiming to reproduce its results. Moreover, experts said the images used in the new study didn’t adequately represent the at-risk population, according to the Advisory Board, a healthcare consultancy. Incidence of breast cancer in the sample dataset was higher than average, and the images weren’t annotated with the patients’ genetic heritage — which could skew the results, because some ethnic groups are at greater risk of developing tumors.
Behind the news: Google’s study overshadowed earlier results from NYU, where researchers trained a similar model to detect cancer in mammograms. Their model scored highly on images that had been verified independently, and it matched the performance of a panel of 12 radiologists. The researchers also found that a hybrid model — which averaged a human radiologist’s decision with the model’s prediction — outperformed either one separately.
Why it matters: Worldwide, breast cancer accounts for 12 percent of all cancer cases. The disease has been on the rise since 2008, with confirmed cases increasing by 20 percent and mortality by 14 percent. Meanwhile, the UK suffers a shortage of trained radiologists. Effective AI-driven detection could save countless lives.
We’re thinking: Google and NYU are both making strides in computer vision for medical diagnosis, though clearly Google has a much larger PR team. We urge reporters to cover a diverse range of AI projects.
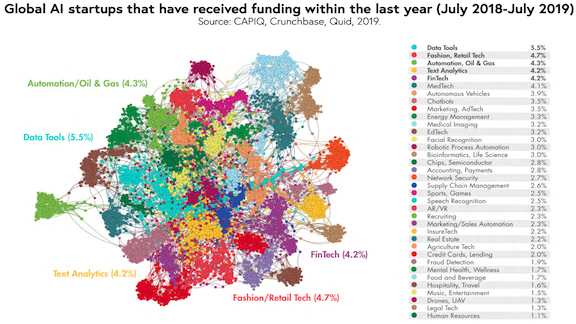
Tracking AI’s Global Growth
Which countries are ahead in AI? Many, in one way or another, and not always the ones you might expect.
What’s new: The Stanford Institute for Human-Centered Artificial Intelligence published its 2019 Artificial Intelligence Index, detailing when, where, and how AI is on the rise. The authors also launched a Global AI Vibrancy Tool, making it easy to compare countries on a number of metrics.
What it says: The report, guided by professor and entrepreneur Yoav Shoham, compiled data from all along the AI pipeline: college enrollment, journal citations, patent filings, conference attendance, job listings, and more. Some highlights:
- AI hiring is growing fastest in Australia, Brazil, Canada, and Singapore. The percentage of the U.S. workforce performing some sort of AI-related task grew from 0.26 percent to 1.32 percent.
- Argentina, Canada, Iran, and several European countries have relatively high proportions of women in the field.
- Total private investment in AI approached $40 billion in the U.S. last year, well ahead of runner-up China. Global private investment topped $70 billion, with startups contributing around half of that.
- Since 1998, the number of peer-reviewed AI research papers has more than quadrupled, and now accounts for 9 percent of published conference papers. Chinese authors published most of them. Nonetheless, U.S. papers are cited 40 percent more often than the global average.
Behind the news: The AI Index is a product of the 100 Year Study on AI. Founded in 2014, the project tracks AI’s impact on jobs, education, national security, human psychology, ethics, law, privacy, and democracy.
We’re thinking: William Gibson said it best: “The future is already here, it’s just not very evenly distributed.”
Easy on the Eyes
Researchers aiming to increase accuracy in object detection generally enlarge the network, but that approach also boosts computational cost. A novel architecture sets a new state of the art in accuracy while cutting the compute cycles required.
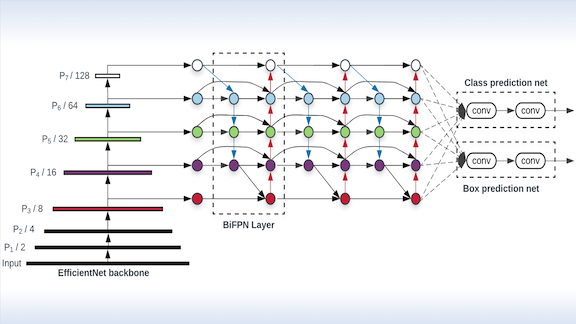
What’s new: Mingxing Tan, Ruoming Pang, and Quoc Le at Google Brain modified existing feature pyramid networks to create the lightweight Bi-Directional Feature Pyramid Network. BiFPN is the cornerstone of a new object detection architecture called EfficientDet.
Key insight: A typical feature pyramid network includes a pretrained image processing network that extracts features of various sizes and combines the information. Some break large features into smaller ones, while others connect smaller features to identify larger ones. BiFPN improves accuracy by using both techniques and increases efficiency by reducing the number of connections.
How it works: An EfficientDet network includes an EfficientNet to extract features, BiFPNs, and classifiers to identify bounding boxes and class labels.
- BiFPNs create both top-down and bottom-up connections between differently sized features.
- Each BiFPN can also function as an additional layer, so the output of one can feed another. Stacking BiFPNs in this way makes it easier for the network to learn.
- The BiFPNs apply a learnable weight to features of different sizes. The weighting enables them to avoid focusing disproportionately on the larger features.
- The researchers remove network nodes that have only one input, eliminating connections that have little impact on the output.
Results: On the COCO object detection benchmark, the largest EfficientDet network tested topped 51 percent mean average precision, which measures the accuracy of bounding boxes. That score beat the previous state of the art by 0.3 percent, yet EfficientDet had only a quarter the parameters and required 1/13 the calculations of the previous state of the art.
Why it matters: Object detection continues to advance, driven by a steady stream of new innovations. EfficientDet represents two steps forward: an improvement in both accuracy and efficiency.
We’re thinking: Google’s AmoebaNet image classifier, which was designed by a computer, usually outperforms human-designed models. Yet humans crafted the record-setting EfficientDet architecture. Flesh-and-blood engineers still excel at crafting neural networks — for now.