
Dear friends,
Do large language models understand the world? As a scientist and engineer, I’ve avoided asking whether an AI system “understands” anything. There’s no widely agreed-upon, scientific test for whether a system really understands — as opposed to appearing to understand — just as no such tests exist for consciousness or sentience, as I discussed in an earlier letter. This makes the question of understanding a matter of philosophy rather than science. But with this caveat, I believe that LLMs build sufficiently complex models of the world that I feel comfortable saying that, to some extent, they do understand the world.
To me, the work on Othello-GPT is a compelling demonstration that LLMs build world models; that is, they figure out what the world really is like rather than blindly parrot words. Kenneth Li and colleagues trained a variant of the GPT language model on sequences of moves from Othello, a board game in which two players take turns placing game pieces on an 8x8 grid. For example, one sequence of moves might be d3 c5 f6 f5 e6 e3…, where each pair of characters (such as d3) corresponds to placing a game piece at a board location.
During training, the network saw only sequences of moves. It wasn’t explicitly told that these were moves on a square, 8x8 board or the rules of the game. After training on a large dataset of such moves, it did a decent job of predicting what the next move might be.
The key question is: Did the network make these predictions by building a world model? That is, did it discover that there was an 8x8 board and a specific set of rules for placing pieces on it, that underpinned these moves? The authors demonstrate convincingly that the answer is yes. Specifically, given a sequence of moves, the network’s hidden-unit activations appeared to capture a representation of the current board position as well as available legal moves. This shows that, rather than being a “stochastic parrot” that tried only to mimic the statistics of its training data, the network did indeed build a world model.

While this study used Othello, I have little doubt that LLMs trained on human text also build world models. A lot of “emergent” behaviors of LLMs — for example, the fact that a model fine-tuned to follow English instructions can follow instructions written in other languages — seem very hard to explain unless we view them as understanding the world.
AI has wrestled with the notion of understanding for a long time. Philosopher John Searle published the Chinese Room Argument in 1980. He proposed a thought experiment: Imagine an English speaker alone in a room with a rulebook for manipulating symbols, who is able to translate Chinese written on paper slipped under the door into English, even though the person understands no Chinese. Searle argued that a computer is like this person. It appears to understand Chinese, but it really doesn’t.
A common counterargument known as the Systems Reply is that, even if no single part of the Chinese Room scenario understands Chinese, the complete system of the person, rulebook, paper, and so on does. Similarly, no single neuron in my brain understands machine learning, but the system of all the neurons in my brain hopefully do. In my recent conversation with Geoff Hinton, which you can watch here, the notion that LLMs understand the world was a point we both agreed on.
Although philosophy is important, I seldom write about it because such debates can rage on endlessly and I would rather spend my time coding. I’m not sure what the current generation of philosophers thinks about LLMs understanding the world, but I am certain that we live in an age of wonders!
Okay, back to coding.
Keep learning,
Andrew
News
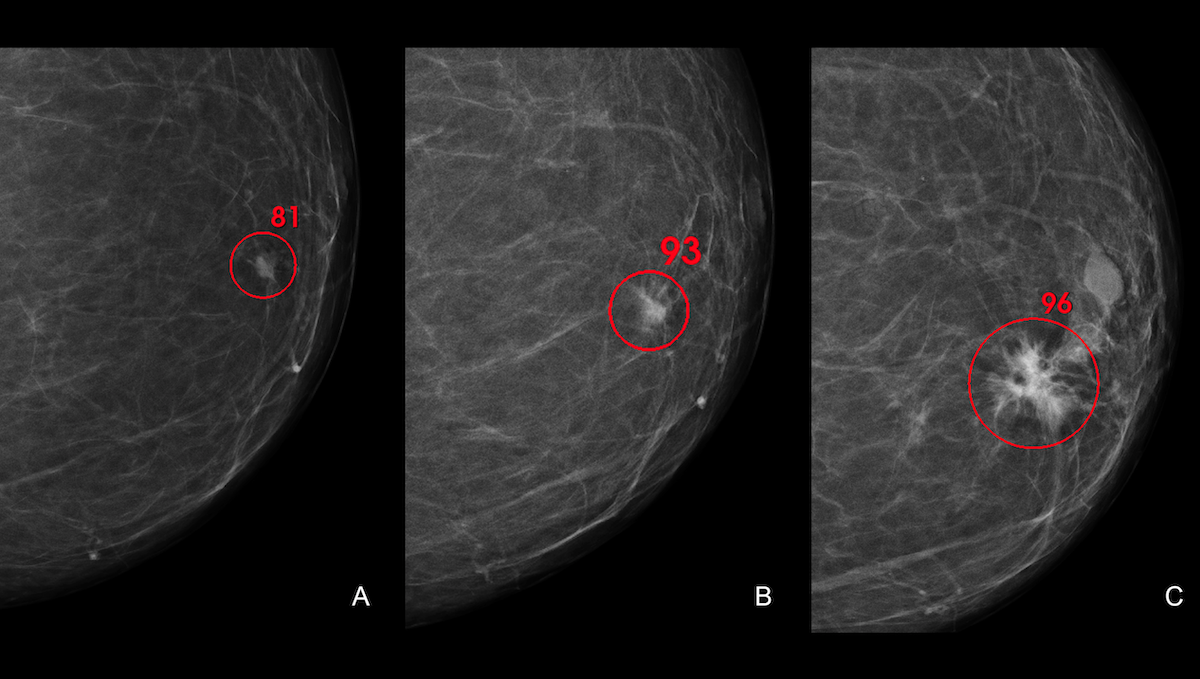
Rigorous Trial: AI Matches Humans in Breast Cancer Diagnosis
A deep learning system detected breast cancer in mammograms as well as experienced radiologists, according to a landmark study.
What’s new: Researchers at Lund University in Sweden conducted a randomized, controlled, clinical trial to determine whether an AI system could save radiologists’ time without endangering patients — purportedly the first study of AI’s ability to diagnose breast cancer from mammograms whose design met the so-called gold standard for medical tests. Their human-plus-machine evaluation procedure enabled radiologists to spend substantially less time per patient while exceeding a baseline for safety.
How it works: The authors randomly divided 80,000 Swedish women into a control group and an experimental group.
- The control group had its mammograms evaluated manually by two radiologists (the standard practice in much of Europe).
- The second, experimental group had its mammograms evaluated by Transpara, a convolutional neural network trained to recognize breast tumors. Transpara scored mammograms for cancer risk on a scale from 1 (low risk) to 10 (high risk). It added marks to mammograms that scored 8 to 10 highlighting potential cancer locations.
- Human radiologists evaluated the experimental group’s mammograms, scores, and marks. One radiologist reviewed each mammogram, unless Transpara had assigned a score of 10, in which case two radiologists reviewed it. Thus at least one radiologist examined each patient in the study.
- Finally, the radiologists chose whether or not to recall each patient for further examination. This enabled them to detect false positives.
Results: The AI-assisted diagnosis achieved a cancer detection rate of 6.1 per 1,000 patients screened, comparable to the control method and above an established lower limit for safety. The radiologists recalled 2.0 percent of the control group and 2.2 percent of the experimental group, and both the control and experimental groups showed the same false-positive rate of 1.5 percent. (The difference in recall rates coupled with the matching false-positive rate suggests that the AI method detected 20 percent more cancer cases than the manual method, though authors didn’t emphasize that finding.) Moreover, since approximately 37,000 patients were only examined by one radiologist, the results indicate that AI saved 44.3 percent of the examination workload without increasing the number of misdiagnosed patients.
Yes, but: The authors’ method requires more study before it can enter clinical practice; for instance, tracking patients of varied genetic backgrounds. The authors are continuing the trial and plan to publish a further analysis after 100,000 patients have been enrolled for two years.
Behind the news: Radiologists have used AI to help diagnose breast cancer since the 1980s (though that method is questionable.) A 2020 study by Google Health claimed that AI outperformed radiologists, but critics found flaws in the methodology.
Why it matters: Breast cancer causes more than 600,000 deaths annually worldwide. This work suggests that AI can enable doctors to evaluate more cases faster, helping to alleviate a shortage of radiologists. Moreover, treatment is more effective the earlier the cancer is diagnosed, and the authors’ method caught more early than late ones.
We’re thinking: Medical AI systems that perform well in the lab often fail in the clinic. For instance, a neural network may outperform humans at cancer diagnosis in a specific setting but, having been trained and tested on the same data distribution, isn’t robust to changes in input (say, images from different hospitals or patients from different populations). Meanwhile, medical AI systems have been subjected to very few randomized, controlled trials, which is considered the gold standard for medical testing. Such trials have their limitations, but they’re a powerful tool for bridging the gap between lab and clinic.

Robots Work the Drive-Thru
Chatbots are taking orders for burgers and fries — and making sure you buy a milkshake with them.
What’s new: Drive-thru fast-food restaurants across the United States are rolling out chatbots to take orders, The Wall Street Journal reported. Reporter Joanna Stern delivers a hilarious consumer’s-eye view in an accompanying video.
How it works: Hardee’s, Carl’s Jr., Checkers and Del Taco use technology from Presto, a startup that specializes in automated order-taking systems. The company claims 95 percent order completion and $3,000 in savings per month per store. A major selling point: Presto’s bot pushes bigger orders that yield $4,500 per month per store in additional revenue.
- Presto uses proprietary natural language understanding and large language model technology. It constrains the bot to stick to the menu if customers make unrelated comments.
- Approached by a customer, it reads an introductory script and waits for a reply. Then it converses until it determines that the order is complete (for instance, when the customer says, “That’s it”). Then it passes the order to human employees for fulfillment.
- The Presto bot passes the conversation on to a human if it encounters a comment it doesn’t understand. In The Wall Street Journal’s reporting, it did this when asked to speak with a human and when subjected to loud background noise. However, when asked if a cheeseburger contains gluten, it erroneously answered, “no.”
- Presto optimizes its technology for upsales: It pushes customers to increase their orders by making suggestions (“Would you like to add a drink?”) based on the current order, the customer’s order history, current supplies, time of day, and weather.
Behind the news: The fast-food industry is embracing AI to help out in the kitchen, too.
- In late 2022, Chipotle began testing AI tools from New York-based PreciTaste that monitor a restaurant location’s customer traffic and ingredient supplies to estimate which and how many menu items employees will need to prepare.
- Since 2021, White Castle has deployed robotic arms from Southern California-based Miso Robotics to deep-fry foods in more than 100 locations.
- In 2021, Yum! Brands, which owns KFC, Pizza Hut, and Taco Bell, acquired Dragontail Systems, whose software uses AI to coordinate the timing of cooking and delivering orders.
Yes, but: McDonald’s, the world’s biggest fast-food chain by revenue, uses technology from IBM and startup Apprente, which it acquired in 2019. As of early this year, the system achieved 80 percent accuracy — far below the 95 percent that executives had expected.
Why it matters: In fast food, chatbots are continuing a trend in food service that began with Automat cafeterias in the early 1900s. Not only are they efficient at taking orders, apparently they’re more disciplined than typical employees when it comes to suggesting ways to enlarge a customer’s order (and, consequently, waist).
We’re thinking: When humans aren’t around, order-taking robots order chips.
A MESSAGE FROM DEEPLEARNING.AI

Join our upcoming workshop with Weights & Biases and learn how to evaluate Large Language Model systems, focusing on Retrieval Augmented Generation (RAG) systems. Register now
The High Cost of Serving LLMs
Amid the hype that surrounds large language models, a crucial caveat has receded into the background: The current cost of serving them at scale.
What’s new: As chatbots go mainstream, providers must contend with the expense of serving sharply rising numbers of users, the Washington Post reported.
The price of scaling: The transformer architecture, which is the basis of models like OpenAI’s ChatGPT, requires a lot of processing. Its self-attention mechanism is computation-intensive, and it gains performance with higher parameter counts and bigger training datasets, giving developers ample incentive to raise the compute budget.
- Hugging Face CEO Clem Delangue said that serving a large language model typically costs much more than customers pay.
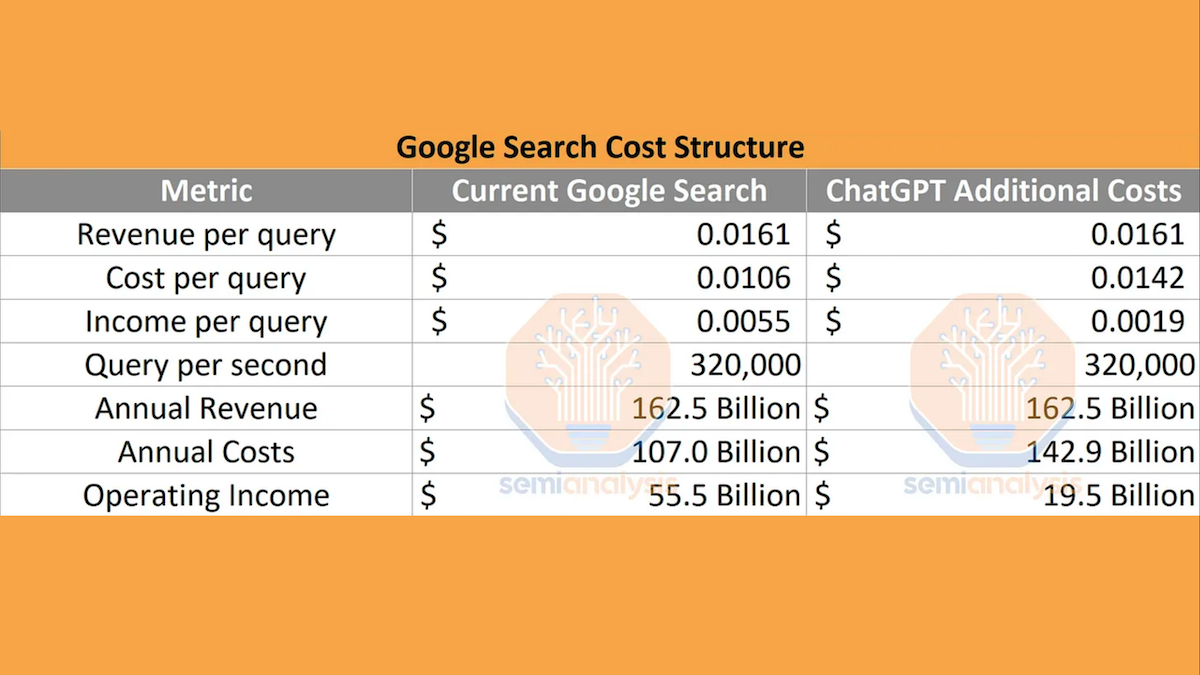
- SemiAnalysis, a newsletter that covers the chip market, in February estimated that OpenAI spent $0.0036 to process a GPT-3.5 prompt. At that rate, if Google were to use GPT-3.5 to answer the approximately 320,000 queries per second its search engine receives, its operating income would drop from $55.5 billion to $19.5 billion annually.
- In February, Google cited savings on processing as the reason it based its Bard chatbot on a relatively small version of its LaMDA large language model.
- Rising demand for chatbots means a greater need for the GPU chips that often process these models at scale. This demand is driving up the prices of both the chips and cloud services based on them.
Why it matters: Tech giants are racing to integrate large language models into search engines, email, document editing, and an increasing variety of other services. Serving customers may require taking losses in the short term, but winning in the market ultimately requires balancing costs against revenue.
We’re thinking: Despite the high cost of using large language models to fulfill web searches — which Google, Bing, and Duckduckgo do for free, thus creating pressure to cut the cost per query — for developers looking to call them, the expense looks quite affordable. In our back-of-the-envelope calculation, the cost to generate enough text to keep someone busy for an hour is around $0.08.

Diffusion Transformed
A tweak to diffusion models, which are responsible for most of the recent excitement about AI-generated images, enables them to produce more realistic output.
What's new: William Peebles at UC Berkeley and Saining Xie at New York University improved a diffusion model by replacing a key component, a U-Net convolutional neural network, with a transformer. They call the work Diffusion Transformer (DiT).
Diffusion basics: During training, a diffusion model takes an image to which noise has been added, a descriptive embedding (typically an embedding of a text phrase that describes the original image, in this experiment, the image’s class), and an embedding of the current time step. The system learns to use the descriptive embedding to remove the noise in successive time steps. At inference, it generates an image by starting with pure noise and a descriptive embedding and removing noise iteratively according to that embedding. A variant known as a latent diffusion model saves computation by removing noise not from an image but from an image embedding that represents it.
Key insight: In a typical diffusion model, a U-Net convolutional neural network (CNN) learns to estimate the noise to be removed from an image. Recent work showed that transformers outperform CNNs in many computer vision tasks. Replacing the CNN with a transformer can lead to similar gains.
How it works: The authors modified a latent diffusion model (specifically Stable Diffusion) by putting a transformer at its core. They trained it on ImageNet in the usual manner for diffusion models.
- To accommodate the transformer, the system broke the noisy image embeddings into a series of tokens.
- Within the transformer, modified transformer blocks learned to process the tokens to produce an estimate of the noise.
- Before each attention and fully connected layer, the system multiplied the tokens by a separate vector based on the image class and time step embeddings. (A vanilla neural network, trained with the transformer, computed this vector.)
Results: The authors assessed the quality of DiT’s output according to Fréchet Inception Distance (FID), which measures how the distribution of a generated version of an image compares to the distribution of the original (lower is better). FID improved depending on the processing budget: On 256-by-256-pixel ImageNet images, a small DiT with 6 gigaflops of compute achieved 68.4 FID, a large DiT with 80.7 gigaflops achieved 23.3 FID, and the largest DiT with 119 gigaflops achieved 9.62 FID. A latent diffusion model that used a U-Net (104 gigaflops) achieved 10.56 FID.
Why it matters: Given more processing power and data, transformers achieve better performance than other architectures in numerous tasks. This goes for the authors’ transformer-enhanced diffusion model as well.
We're thinking: Transformers continue to replace CNNs for many tasks. We’ll see if this replacement sticks.
Data Points
Arizona law school embraces ChatGPT
The Sandra Day O’Connor College of Law at Arizona State University now permits prospective students to use generative AI tools to draft their applications, as long as the information they submit is truthful. While the policy is limited to applications, the law school is working on guidelines for using AI in coursework and classrooms. (Reuters)
Regulators probe investment firms over use of AI
Massachusetts securities regulators sent letters of inquiry to investment firms including JPMorgan Chase and Morgan Stanley. The letters question the firms’ potential use of AI and its implications for investors. The state investigation comes in the wake of the U.S. Securities and Exchange Commission's recent proposal to mitigate conflicts of interest related to AI used in trading platforms. (Reuters)
AI dominated second-quarter earnings calls
Companies featured AI prominently in their conference calls during the second-quarter earnings reporting season. Prominent tech companies mentioned AI over 50 times, and over one-third of S&P 500 companies mentioned it at least once. (Reuters)
Kickstarter implements AI transparency policy
The crowdfunding platform, which raises money for projects like art and video games, now mandates that users seeking funds provide details about how their projects use AI to ensure proper attribution of AI-generated work. (Video Games Chronicle)
Adobe’s use of AI raises employee concerns
The integration of AI tools like Firefly in Adobe’s products prompted internal debates about the role of AI in design and creativity. Some employees worry about potential job losses, while others emphasize the benefits for efficiency and productivity. (Business Insider)
Google to revamp Google Assistant
The division of Alphabet is working on an overhaul of its virtual assistant to add generative AI features. The move marks a shift away from earlier technology. (Axios)
YouTube to introduce automatic summaries
The platform is experimenting with AI-generated video summaries and emphasizes that they are not intended to replace creators’ written video descriptions. Previous summarizer tools provided by third parties received mixed reviews. (TechCrunch and Google)
Aides reveal U.S. President Biden’s views on AI
President Biden is navigating AI with a mix of fascination and caution, according to his aides and advisers. He's personally experimented with ChatGPT for various tasks including generating descriptions of legal cases for first-graders and crafting Bruce Springsteen-style lyrics about legal matters. (The Wall Street Journal)