
Dear friends,
Internalizing this mental framework has made me a more efficient machine learning engineer: Most of the work of building a machine learning system is debugging rather than development.
This idea will likely resonate with machine learning engineers who have worked on supervised learning or reinforcement learning projects for years. It also applies to the emerging practice of prompt-based AI development.
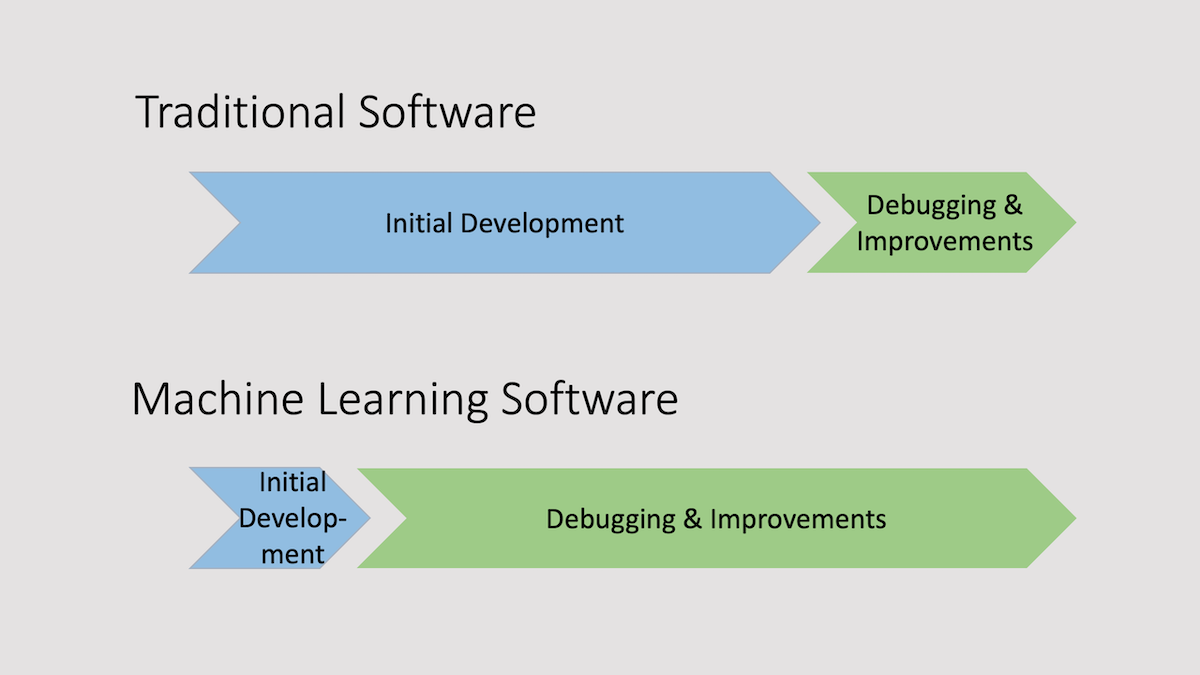
When you’re building a traditional software system, it’s common practice to write a product spec, then write code to that spec, and finally spend time debugging the code and ironing out the kinks. But when you’re building a machine learning system, it’s frequently better to build an initial prototype quickly and use it to identify and fix issues. This is true particularly for building applications that humans can do well, such as unstructured data tasks like processing images, audio, or text.
- Build a simple system quickly to see how well it does.
- Figure out where it falls short (via error analysis or other techniques), and iteratively try to close the gap between what the system does and what a human (such as you, the developer, or a domain expert) would do given the same data.
Machine learning software often has to carry out a sequence of steps; such systems are called pipelines or cascades. Say, you want to build a system to route an ecommerce site’s customer emails to the appropriate department (is this apparel, electronics, . . . ), then retrieve relevant product information using semantic search, and finally draft a response for a human representative to edit. Each of these steps could have been done by a human. By examining them individually and seeing where the system falls short of human-level performance, you can decide where to focus your attention.
While debugging a system, I frequently have a “hmm, that looks strange” moment that suggests what to try next. For example, I’ve experienced each of the following many times:
- The learning curve doesn’t quite look right.
- The system performs worse on what you think are the easier examples.
- The loss function outputs values that are higher or lower than you think it should.
- Adding a feature that you thought would help performance actually hurt.
- Performance on the test set is better than seems reasonable.
- An LLM’s output is inconsistently formatted; for example, including extraneous text.
When it comes to noticing things like this, experience working with multiple projects is helpful. Machine learning systems have a lot of moving parts. When you have seen many learning curves, you start to hone your instincts about what’s normal and what’s anomalous; or when you have prompted a large language model (LLM) to output JSON many times, you start to get a sense of the most common error modes. These days, I frequently play with building different small LLM-based applications on weekends just for fun. Seeing how they behave (as well as consulting with friends on their projects) is helping me to hone my own instincts about when such applications go wrong, and what are plausible solutions.
Understanding how the algorithms work really helps, too. Thanks to development tools like TensorFlow and PyTorch, you can implement a neural network in just a few lines of code — that’s great! But what if (or when!) you find that your system doesn’t work well? Taking courses that explain the theory that underlies various algorithms is useful. If you understand at a technical level how a learning algorithm works, you’re more likely to spot unexpected behavior, and you’ll have more options for debugging it.
The notion that much of machine learning development is akin to debugging arises from this observation: When we start a new machine learning project, we don’t know what strange and wonderful things we’ll find in the data. With prompt-based development, we also don’t know what strange and wonderful things a generative model will produce. This is why machine learning development is much more iterative than traditional software development: We’re embarking on a journey to discover these things. Building a system quickly and then spending most of your time debugging it is a practical way to get such systems working.
Keep learning!
Andrew
DeepLearning.AI Exclusive

Robert Monarch, the instructor of our new specialization AI for Good, spoke with us about how AI is being applied to social and environmental challenges and how you can join the growing AI for Good movement. Read the interview
News

Stable Biases
Stable Diffusion may amplify biases in its training data in ways that promote deeply ingrained social stereotypes.
What's new: The popular text-to-image generator from Stability.ai tends to underrepresent women in images of prestigious occupations and overrepresent darker-skinned people in images of low-wage workers and criminals, Bloomberg reported.
How it works: Stable Diffusion was pretrained on five billion text-image pairs scraped from the web. The reporters prompted the model to generate 300 face images each of workers in 14 professions, seven of them stereotypically “high-paying” (such as lawyer, doctor, and engineer) and seven considered “low-paying” (such as janitor, fast-food worker, and teacher). They also generated images for three negative keywords: “inmate,” “drug dealer,” and “terrorist.” They analyzed the skin color and gender of the resulting images.
- The reporters averaged the color of pixels that represent skin in each image. They grouped the average color in six categories according to a scale used by dermatologists. Three categories represented lighter-skinned people, while the other three represented darker-skinned people.
- To analyze gender, they manually classified the perceived gender of each image’s subject as “man,” “woman,” or “ambiguous.”
- They compared the results to United States Bureau of Labor Statistics data that details each profession’s racial composition and gender balance.
Results: Stable Diffusion’s output aligned with social stereotypes but not with real-world data.
- The model generated a higher proportion of women than the U.S. national percentage in four occupations, all of them “low-paying” (cashier, dishwasher, housekeeper, and social worker).
- For instance, Stable Diffusion portrayed women as “doctors” in 7 percent of images and as “judges” in 3 percent. In fact, women represent 39 percent of U.S. doctors and 34 percent of U.S. judges. Only one generated image of an “engineer” depicted a woman, while women represent 14 percent of U.S. engineers. (Of course, the U.S. percentages likely don’t match those in other countries or the world as a whole.)
- More than 80 percent of Stable Diffusion’s images of inmates and more than half of its images of drug dealers matched the three darkest skin tone categories. Images of “terrorists” frequently showed stereotypically Muslim features including beards and head coverings.
- The authors point out that skin color does not equate to race or ethnicity, so comparisons between color and real-world demographic data are not valid.
Behind the news: Image generators have been found to reproduce and often amplify biases in their training data.
- In March 2023, researchers at Leipzig University and HuggingFace found that both DALL•E 2 and Stable Diffusion tended to overrepresent men relative to the U.S. workforce. (The previous July, OpenAI had reported that it was addressing issues of this sort.)
- Pulse, a model designed to sharpen blurry images, caused controversy in 2020 when it transformed a pixelated headshot of former U.S. president Barack Obama, who is black, into a face of a white man. More recently, users of the Lensa photo editor app, which is powered by Stable Diffusion, reported that it sexualized images of women.
- In 2020, after studies showed that ImageNet contained many images with sexist, racist, or hateful labels, the team that manages the dataset updated it to eliminate hateful tags and include more diverse images. Later that year, the team behind the dataset TinyImages withdrew it amid reports that it was rife with similar issues.
Why it matters: Not long ago, the fact that image generators reflect and possibly amplify biases in their training data was mostly academic. Now, because a variety of software products integrate them, such biases can leach into products as diverse as video games, marketing copy, and law-enforcement profiles.
We're thinking: While it’s important to minimize bias in our datasets and trained models, it’s equally important to use our models in ways that support fairness and justice. For instance, a judge who weighs individual factors in decisions about how to punish a wrongdoer may be better qualified to decide than a model that simply reflects demographic trends in criminal justice.
AI & Banking: Progress Report
One bank towers above the competition when it comes to AI, a recent study suggests.
What’s new: A report from market research firm Evident Insights measures use of AI by the banking industry.
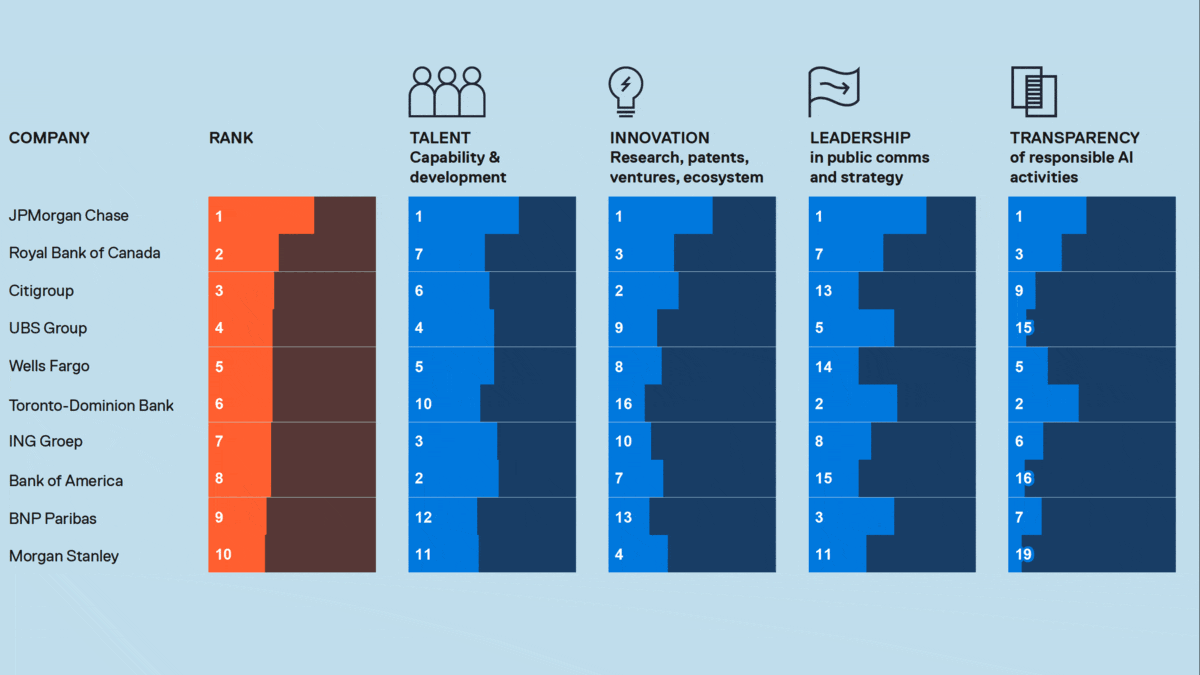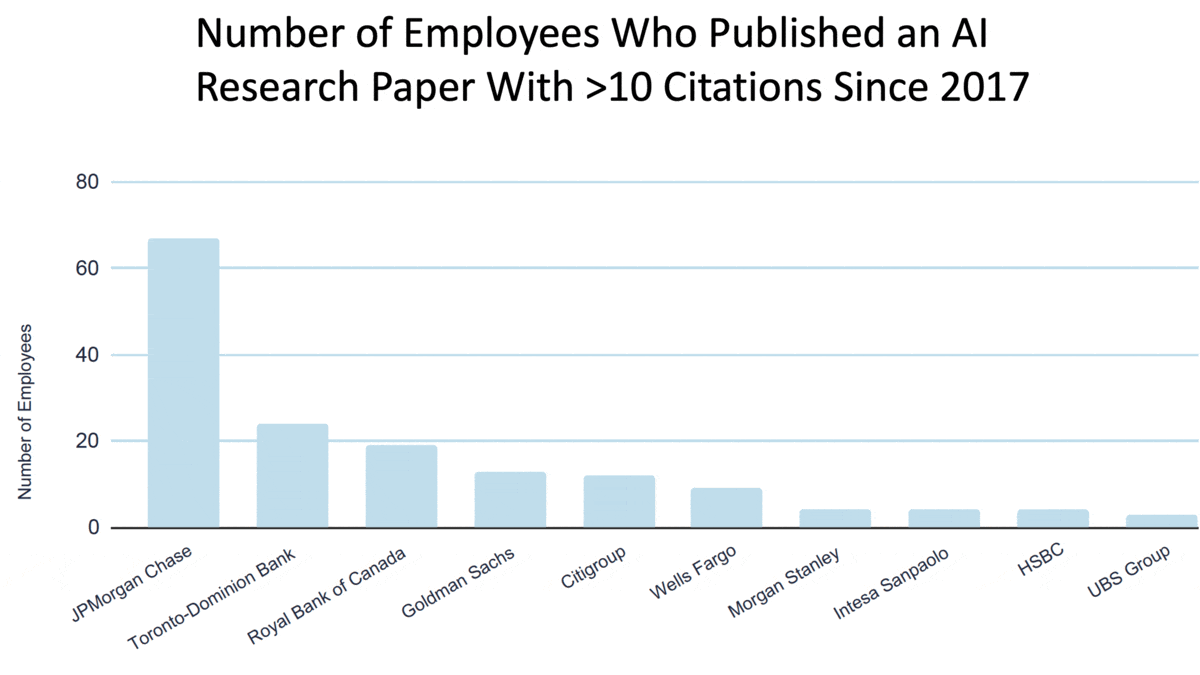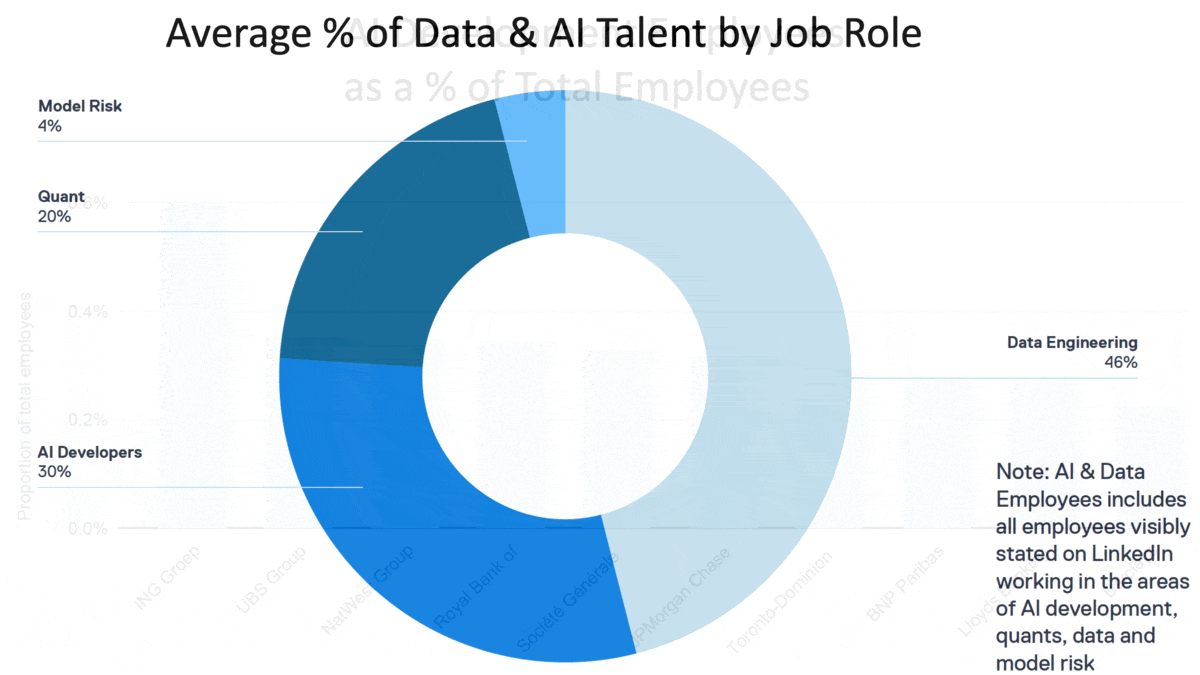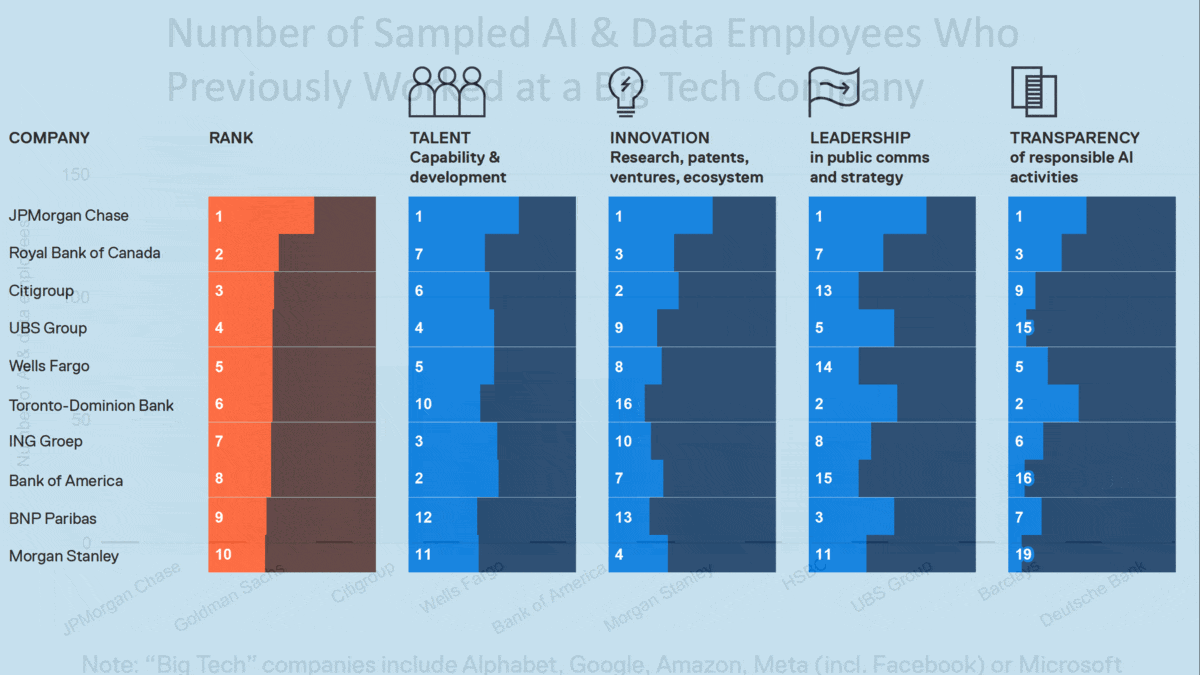
How it works: The Evident AI Index scored 23 large North American and European banks in four categories. The analysis combined the scores into a total for each bank.
- Talent accounted for 40 percent of a bank’s score. The authors quantified each bank’s talent pool according to LinkedIn pages of 120,000 bank employees who held any of 39 data-science- or AI-related job titles such as data scientist, AI product manager, or quant analyst. They considered each employee’s work history to gauge the depth and gender diversity of AI staff at each bank. The authors also analyzed bank websites, press releases, job descriptions, and Glassdoor postings for indications of how each bank prioritized AI talent; for instance, the number of entry-level roles or upskilling programs available.
- Innovation accounted for 30 percent. The authors counted AI-related research papers and patents generated by each bank, its investments in AI-first companies, academic partnerships, and contributions to open source projects.
- Leadership accounted for 15 percent. The authors examined external communications such as press releases, literature for investors, and social media posts to measure how clearly each bank conveyed its AI initiatives.
- Transparency accounted for 15 percent. The authors examined how clearly external communications conveyed policies with respect to AI ethics, risk management, and management roles.
Results: JPMorgan Chase excelled in all four categories with a combined score of 62.6 out of 100. The next-highest scorers were Royal Bank of Canada (41.4) and Citigroup (39.0). The authors credited JPMorgan Chase with successful long-term investments in AI research coupled with an openness to letting AI talent publish academic work. Other highlights:
- North American banks generally outscored their European peers, holding seven of the top 10 scores. The bottom 12 were all European banks.
- 46 percent of employees surveyed were data engineers. 30 percent were AI developers, 20 percent were quantitative finance analysts, and 4 percent worked with model risks. 34 percent identified as women.
- The authors credited JPMorgan Chase and fifth-ranked Wells Fargo with establishing AI recruitment programs similar to those at tech companies including apprenticeships, graduate roles, internships, and dedicated hiring teams.
- The authors lauded executives at JPMorgan Chase and Royal Bank of Canada for avoiding AI hype in their public communications and, along with TD Bank, hiring AI ethicists and promoting AI ethics.
Behind the news: A growing number of banks are taking advantage of generative AI.
- Engineers at JPMorgan Chase recently trained a language model on statements from the U.S. Federal Reserve, a government agency that sets certain influential interest rates, to predict the agency’s next moves.
- Morgan Stanley, which ranked 10th in the Index, adopted OpenAI’s GPT-4 to interpret financial documents.
- Financial data company Bloomberg developed a 50 billion-parameter transformer model called BloombergGPT to analyze financial documents. It outperformed the 176 billion-parameter BLOOM in tasks like sentiment analysis of financial news and documents.
Why it matters: Finance is among the few industries outside tech that can afford to hire large teams of top AI talent. It’s also a data-heavy industry where applications — fraud detection, financial forecasting, and reconciling and closing accounts — can bring a ready payoff. The combination has made banking a hotbed for AI talent.
We’re thinking: It’s interesting to see one bank so far out ahead in this analysis. We imagine that AI adoption on banking can bring significant first-mover advantages.
A MESSAGE FROM WORKERA
Introducing Skills AI, the tool that harnesses large language models for managers to develop, upskill, and retain teams at the cutting edge of competency. Join the waitlist
Language Models’ Impact on Jobs
Telemarketers and college professors are most likely to find their jobs changing due to advances in language modeling, according to a new study.
What’s new: A team led by Ed Felten, a computer scientist at Princeton University and former deputy CTO of the United States, projected the jobs and industries in the U.S. likely to be most affected by language models.
How it works: The authors calculated an “exposure” score for each of 774 occupations and 115 industries by comparing human skills to AI application areas. For the purpose of the study, exposure is neither positive nor negative; it’s a measure of how likely a job or industry would change in response to developments in language processing.
- The authors used a U.S. Department of Labor database that describes each occupation in terms of 52 human abilities. Such abilities include dynamic strength, hearing sensitivity, mathematical reasoning, and written expression, and they’re weighted according to their importance to a given occupation.
- Crowdsourced workers scored the relevance of language modeling to each ability. For instance, language modeling has little relevance to dynamic strength but great relevance to written expression.
- The authors used the scores as weighted variables in an equation that aggregated the relevance of language modeling to the human abilities involved in each occupation and industry.
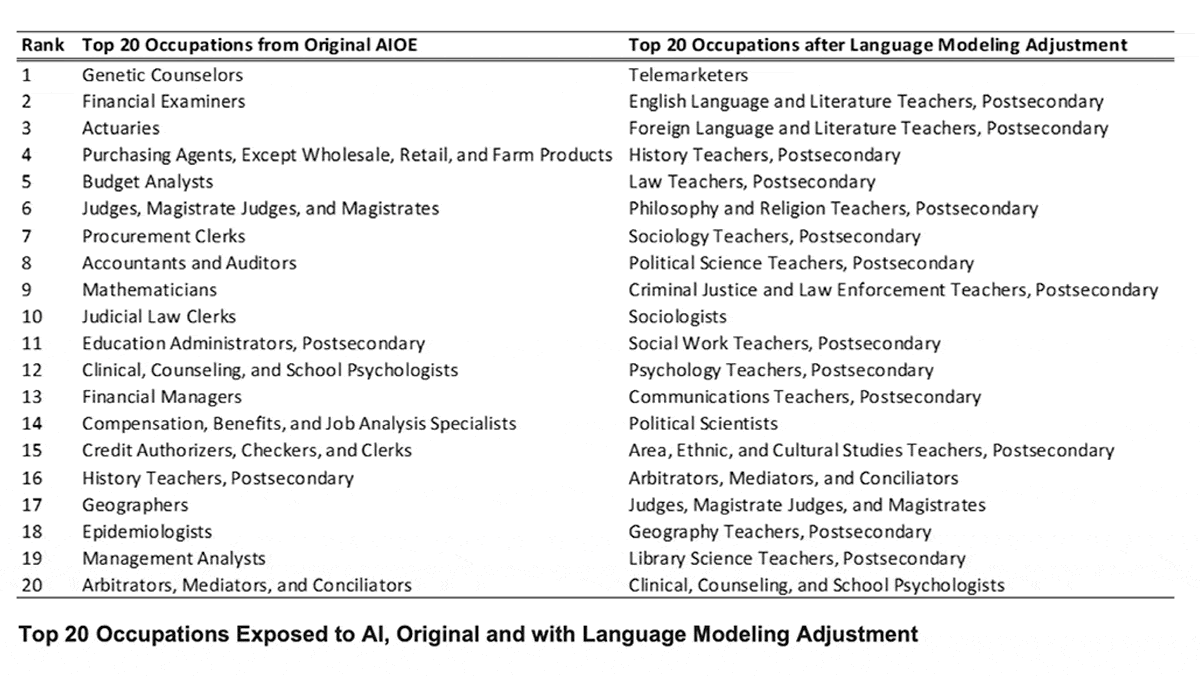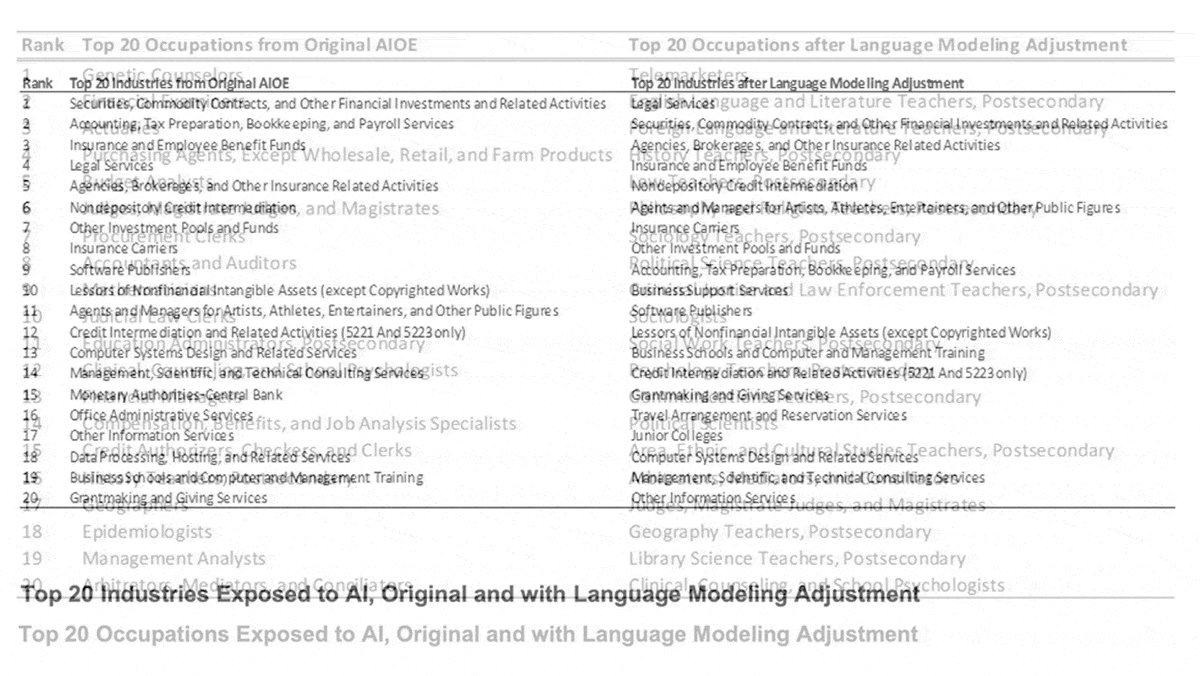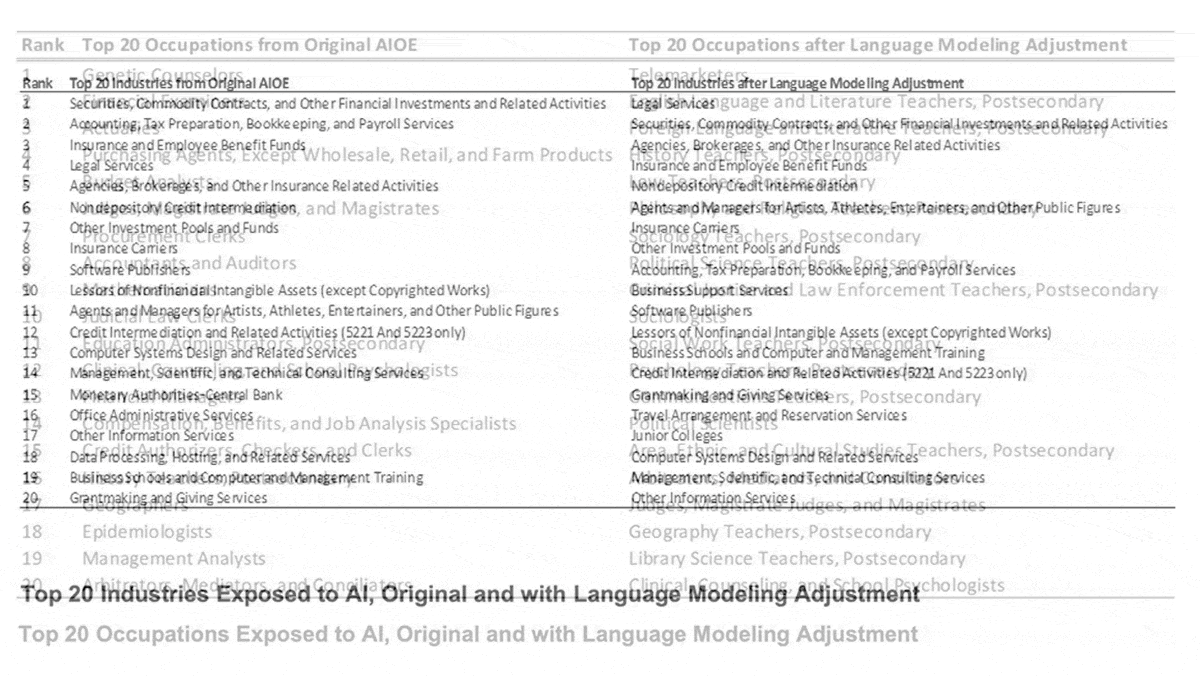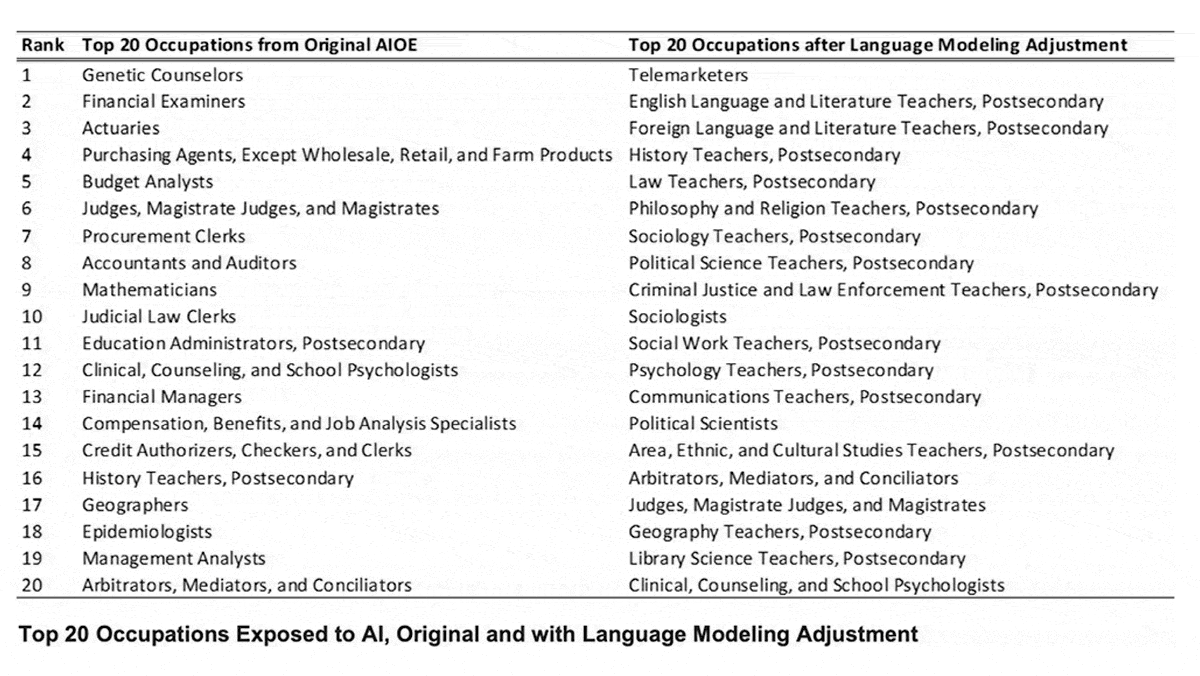
Results: The authors concluded that telemarketing was most exposed to impact by language models. Among the 20 occupations with the greatest exposure, 14 were post-secondary teaching roles including university-level teachers of language, history, law, and philosophy. The top 20 also included sociologists, political scientists, arbitrators, judges, and psychologists. Among industries, the authors found that legal services were most exposed. Of the 20 industries with the greatest exposure, 11 involved finance including securities, insurance, and accounting.
Behind the news: The authors adapted their method from a 2021 study that scored each occupation’s and each industry’s exposure to AI areas defined by the Electronic Frontier Foundation, including game playing, computer vision, image generation, translation, and music recognition. The previous study found that the most exposed jobs were genetic counselors, financial examiners, and actuaries. The most exposed industries were financial securities, accounting, and insurance.
Why it matters: It seems clear that emerging AI technologies will have a significant impact on human labor, but where and how is not yet clear (and may not be even as the effects become more pervasive). This study can serve as a heads-up to some professionals that it’s time to prepare — and a signal to AI builders what sorts of models are likely to have an impact.
We’re thinking: As the authors note, an occupation’s exposure to AI does not necessarily put jobs at risk. History suggests the opposite can happen. A 2022 study found that occupations exposed to automation saw increases in employment between 2008 and 2018. Several other studies found that countries with high levels of automation also tend to have high overall levels of employment.

Sample-Efficient Training for Robots
Training an agent that controls a robot arm to perform a task — say, opening a door — that involves a sequence of motions (reach, grasp, turn, pull, release) can take from tens of thousands to millions of examples. A new approach pretrained an agent on many tasks for which lots of data was available, so it needed dramatically fewer examples to learn related tasks.
What’s new: Joey Hejna and Dorsa Sadigh at Stanford used a variation on reinforcement learning from human feedback (RLHF) to train an agent to perform a variety of tasks in simulation. The team didn’t handcraft the reward functions. Instead, neural networks learned them.
RLHF basics: A popular approach to tuning large language models, RLHF follows four steps: (1) Pretrain a generative model. (2) Use the model to generate data and have humans assign a score to each output. (3) Given the scored data, train a model — called the reward model — to mimic the way humans assigned scores. Higher scores are tantamount to higher rewards. (4) Use scores produced by the reward model to fine-tune the generative model, via reinforcement learning, to produce high-scoring outputs. In short, a generative model produces an example, a reward model scores it, and the generative model learns based on that score.
Key insight: Machine-generated data is cheap, while human-annotated data is expensive. So, if you’re building a neural network to estimate rewards for several tasks that involve similar sequences of motions, it makes sense to pretrain it for a set of tasks using a large quantity of machine-generated data, and then fine-tune a separate copy for each task to be performed using small amounts of human-annotated data.
- The Meta-World benchmark provides machine-generated data for reinforcement learning (RL): It provides simulated environments for several tasks and trained models that execute the tasks. The models make it possible to record motion sequences along with a model’s estimate of its probability of success for each possible motion. Collecting high- and low-probability sequences provides a large dataset of good and bad motions that translate into high or low rewards.
- Humans can annotate such sequences to create a smaller number of examples of motions and rewards. These examples can be curated to highlight cases that make for more efficient learning.
How it works: The authors trained an RL agent to perform 10 simulated tasks from Meta-World such as pushing a block, opening a door, and closing a drawer. For each task, they fine-tuned a separate pretrained vanilla neural network to calculate rewards used in training the agent.
- The authors pretrained the reward model using a method designed to find weights that could be readily fine-tuned for a new task using a small number of examples. Given two motion sequences and their probabilities (generated by models included in Meta-World), the network was pretrained to decide which was worse or better for executing the task at hand.
- For six new tasks, the authors generated a small number (between 6 and 20 depending on the task) of motion sequences using their agent. Human annotators labeled them better or worse for executing the task at hand. The authors fine-tuned the reward model on these examples.
- Using a small number of motion sequences for the task at hand, the authors trained the agent to complete the task based on rewards calculated by the reward model.
- The authors repeated the loop — fine-tuning the reward model and training the agent — fine-tuning the reward model on up to 100 total human-annotated motion sequences for a task. They stopped when the agent’s performance no longer improved.
- The authors tried the same experiment substituting human annotations for Meta-World’s model-generated probabilities for the motion sequences. It took up to 2,500 total sequences for the agent to reach its optimal performance.
Results: Trained to open a window, the agent achieved 100 percent success after fine-tuning on 64 human-annotated motion sequences. Trained to close a door, it achieved 95 percent success with 100 human-annotated motion sequences. In contrast, using the same number of examples, PEBBLE, another RL method that involves human feedback, achieved 10 percent and 75 percent success respectively. Fed machine-generated examples rather than human feedback, the agent achieved 100 percent success on all Meta-World tasks except pressing a button after fine-tuning on 2,500 examples — 20 times fewer than PEBBLE required to achieve the same performance.
Why it matters: OpenAI famously fine-tuned ChatGPT using RLHF, which yielded higher-quality, safer output. Now this powerful technique can be applied to robotics.
We’re thinking: Pretraining followed by fine-tuning opens the door to building AI systems that can learn new tasks from very little data. It's exciting to see this idea applied to building more capable robots.
Data Points
Celebrity deepfake promotes investment opportunity
In a manipulated video that appeared on social media, Martin Lewis, a UK celebrity financial, appeared to endorse an investment opportunity that, in fact, he did not support. Lewis previously sued Meta for distributing scam ads that included his likeness. (TechCrunch)
Activists protest against autonomous vehicles by disabling them
In response to recurring malfunctions of robotaxis that disrupted traffic disruptions, activists who support safe streets in San Francisco disabled Cruise and Waymo vehicles by placing traffic cones on their hoods. It is not clear how many robotaxis were affected. (TechCrunch)
OpenAI to form team to control superintelligent AI systems
The independent AI research lab anticipates the arrival of AI systems smarter than humans within the decade. It aims to ensure that such systems follow human intentions by building an automated alignment researcher. (TechCrunch)
U.S. authors sue OpenAI over copyright violation
Writers Paul Tremblay and Mona Awad sued Open AI in a federal court in San Francisco. The lawsuit claims that the company violated their copyright because it trained large language models on their books without permission and enabled the models to generate accurate summaries of their works. In a separate suit also filed in a San Francisco Federal Court, comedian Sarah Silverman joined authors Christopher Golden and Richard Kadrey in suing OpenAI and Meta over similar allegations. (Reuters, New York Times)
Indiana Jones filmmakers used AI to de-age Harrison Ford
The recent Indiana Jones movie shows Harrison Ford looking roughly 40 years younger than he was when the film was shot. The effect was achieved through a combination of AI, CGI, and human artists. (Wired)
GPT-4 enhances assistive technology for blind people
OpenAI’s large language model is improving capabilities like object description and question answering in various assistive apps for people with visual impairments. (Wired)
Retailers embrace face recognition systems
British company Facewatch aids retailers in combating petty crime by alerting store managers when it detects the faces of flagged individuals This use of the technology has sparked criticism as a disproportionate response to minor crimes. (The New York Times)
New York City law that regulates the use of AI in hiring takes effect
The law, called NYC 144, requires employers to perform annual audits of AI-driven hiring tools such as resume scanners and interview bots for potential race and gender bias. The audits must be available to the public. (The Wall Street Journal).
IUntethered chatbots proliferate
Independent and volunteer developers are releasing chatbots that have little to no limit on their output, unlike chatbots made by commercial enterprises which are often designed to align with social values. These bots are free to generate offensive responses, misinformation, and information that contributes to safety hazards. (The New York Times)
Amazon taught Alexa to speak with accents
Amazon developed an accurate Irish accent for its flagship voice assistant, opening the door to a wave of voice assistants that speak in a variety of local variations. (The New York Times)