
Dear friends,
There are many great applications to be built on top of large language models, and the overhead of doing so may be lower than you think. Sometimes, I've spent all day on a weekend developing ideas only to find that I've spent less than $0.50.
Given the low cost of keeping me busy all day, It might not surprise you to find that the cost of scaling up a business based on a large language model (LLM) can be quite inexpensive. As a back-of-the-envelope calculation, let’s say:
- It costs $0.002 per 1,000 tokens, the current price of OpenAI's popular gpt-3.5-turbo conversational model. Pricing can be up to 5x lower or 30x higher depending on the model's quality, but this one is popular among developers, so let's go with it.
- A token corresponds to 0.75 words.
- A user can read 250 words per minute.
- Length of prompts and generated responses is roughly the same.
Then it costs around $0.08 to generate enough text to keep someone busy for an hour.
Here are some ways to think about this when it comes to automating or assisting a person’s work task:
- For most tasks that we might hire someone to do, the cost is significantly more than $0.08 per hour. For example, minimum wage in some places in the US is $15 per hour, and Amazon Mechanical Turk workers might work for around $5 per hour. So the cost of using an LLM to automate of most human tasks is very inexpensive.
- If you’re generating text for a person to read, the cost of the time spent reading is significantly greater than the cost of generating the text.

On the flip side:
- Up to an order of magnitude, social media companies might make around $0.10 per hour that a user spends on their sites. So if we’re generating personalized text for one person, the financial case is iffy. (I don’t think this is necessarily a bad thing. Society doesn’t need people to spend even more time on social media!)
- On the other hand, if we’re generating content to be read by a large audience, such as a news article, then the cost is amortized across the audience, and it is quite inexpensive again.
Please don’t use my back-of-the-envelope calculation for any significant business decisions, and do carry out your own calculations with careful assumptions specific to your project. But if you haven’t stepped through such a calculation before, the takeaway is that LLMs are actually quite inexpensive to use.
Granted, some models (like one version of GPT-4, at 15-30x the cost used in the calculation, leading to a cost of $1.80 instead of $0.08) are much more expensive. If your application requires a more capable model, then the calculation does change. But I’m optimistic that prices will come down over time, and these are all wonderful tools to have in your toolbox.
Keep learning!
Andrew
P.S. I’ve noticed that most LLM providers don’t have transparent pricing. If you work at an LLM provider, I hope you’ll consider urging your company to list prices on its website.
News

Battlefield Chat
Large language models may soon help military analysts and commanders make decisions on the battlefield.
What’s new: Palantir, a data-analytics company that serves customers in the military, intelligence, and law enforcement, demonstrated its chat-driven Artificial Intelligence Platform (AIP) performing tasks like identifying enemies in satellite imagery, deploying surveillance drones, and proposing battle plans.
How it works: In the demonstration, an intelligence analyst uses AIP to react to a fictional scenario. The system integrates large language models including Dolly-v2-12b (12 billion parameters), Flan-T5XL (3 billion), and GPT-NeoX-20B (20 billion) fine-tuned on an unspecified dataset.
- Having received an alert that enemies had moved into friendly territory, the user enters the prompt: “Show me more details.” AIP displays satellite imagery and uses an unspecified object detection model to locate an enemy tank.
- The user prompts AIP to deploy a surveillance drone, which streams video to the screen.
- Having confirmed the tank’s presence, the user prompts AIP to generate three courses of action. The chatbot suggests sending a fighter jet, engaging the tank with long-range artillery, or deploying an infantry unit equipped with shoulder-launched missiles.
- The user sends the suggestions up the chain of command for review. The commander approves sending in troops, and the system generates a battle plan including a route to the tank. The commander orders an electronic warfare specialist to jam the tank’s communication equipment.
Behind the news: Military forces are experimenting with AI for executing combat tactics.
- The United States Department of Defense is testing a system called JADC2 that will process early-warning radar information to identify possible threats across the globe.
- The Israeli Defense Force revealed that it had used unidentified AI tools during a May 2021 engagement to target commanders and missile units belonging to Hamas, the political party that controls the Gaza Strip.
Why it matters: At its best, this system could help military authorities identify threats sooner and streamline their responses, enabling them to outmaneuver their enemies. On the other hand, it represents a significant step toward automated warfare.
We’re thinking: This system takes the critical question of safety in AI systems to a new, terrifying level. Human battlefield analysts manage complex variables: terrain, weather, local customs, capabilities and limitations of friendly and enemy forces. This is crucial work. Delegating that work to a chatbot is a worrisome prospect considering the current state of large language models, which hallucinate falsehoods, confidently provide unworkable directions, and fail at basic math — especially smaller chatbots, like those used in this system.
OpenAI Gears Up for Business
Reporters offered a behind-the-scenes look at OpenAI’s year-long effort to capitalize on its long-awaited GPT-4.
What’s new: The company built a sales team and courted corporate partners in advance of launching its latest large language model, The Information reported.
How it works: OpenAI hired a head of sales only last June, four years after shifting from nonprofit to for-profit. She and her team began signing up corporate customers soon after.
- The sales team offered access to the GPT-4 API along with engineers to assist in developing products based on it. Customers include Khan Academy, which uses ChatGPT to drive an educational chatbot; Morgan Stanley, which uses an unspecified model to query financial documents; and Salesforce, which uses OpenAI’s technology to power Einstein GPT, a service that crafts emails, analyzes sales data, and summarizes customer feedback.
- To Salesforce and product research startup Kraftful, the team sold access to servers that process large volumes of GPT-3.5 and GPT-4 prompts. Prices ranged from $264,000 a year for GPT-3.5 to $1.584 million a year for the most powerful version of GPT-4, according to a letter to prospective customers.
- OpenAI also helped customers develop customer-facing plugins that enable ChatGPT to surf the web and take advantage of third-party services. For instance, Expedia built a plug-in that tracks travel conversations to generate offers for flights, hotels, and holiday packages. Instacart developed one that enables customers to order groceries via prompt.
Path to profit: In 2015, OpenAI started as a nonprofit research lab dedicated to transparency. In 2019, it launched a profit-seeking subsidiary to fund its research. In a series of deals between 2019 and 2023, Microsoft invested upward of $13 billion in exchange for 49 percent of OpenAI’s profit and right of first refusal to commercialize its technology.
Yes, but: Observers have criticized both the company’s pivot to profit and its shift away from transparency. In a March interview, OpenAI’s co-founder Ilya Sutskever defended the organization’s secrecy, claiming it was necessary for safety as AI becomes more powerful.
Why it matters: OpenAI saw generative AI’s commercial potential before ChatGPT sparked investments around the globe. That foresight could pay off handsomely, as the company forecasted revenue of $200 million this year and $1 billion by 2024.
We’re thinking: OpenAI is building revolutionary technology that benefits hundreds of millions of users. We’re glad to see it on a path to financial sustainability.
A MESSAGE FROM DEEPLEARNING.AI

Are you ready to leverage AI for projects that can make a positive impact on public health, climate change, and disaster management? Pre-enroll in AI for Good and learn how!
Language Models in Lab Coats
Specialized chatbots are providing answers to scientific questions.
What’s new: A new breed of search engines including Consensus, Elicit, and Scite use large language models to enable scientific researchers to find and summarize significant publications, Nature reported.
How it works: The models answer text questions by retrieving information from databases of peer-reviewed scientific research.
- Consensus uses unnamed language models that were trained on tens of thousands of scientific research papers annotated by PhD students. Upon receiving a query, the tool searches Semantic Scholar (a search engine for academic literature built by the Allen Institute for Artificial Intelligence) for papers, which it ranks according to relevance, quality, citation count, and publishing date. At the user’s request, it uses GPT-4 to generate a single-paragraph summary of the top papers. You can try it here.
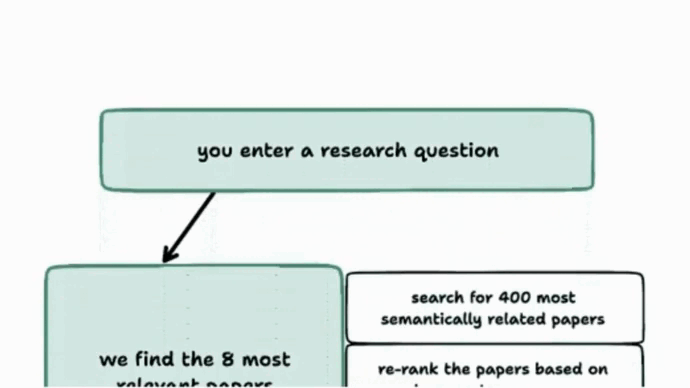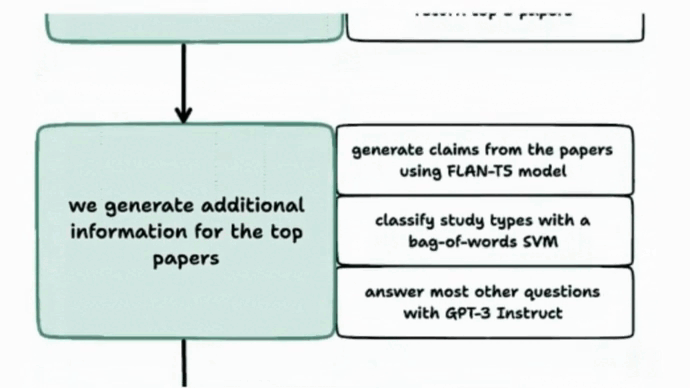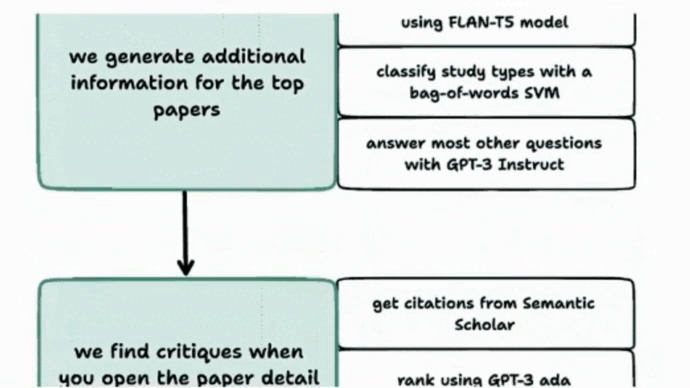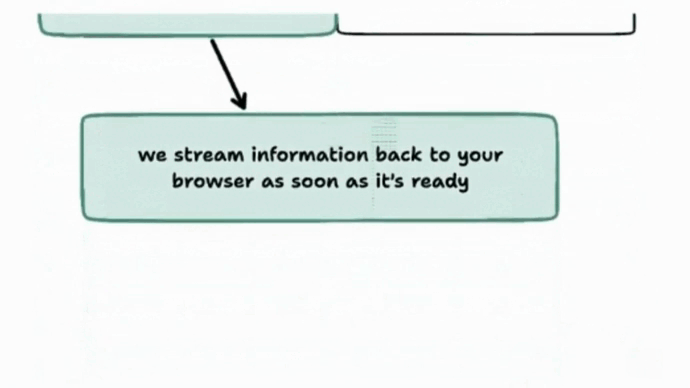
- Given a question, Elicit queries Semantic Scholar's dataset for the top 400 results. GPT-3 Babbage and monot5-base-msmarco-10k re-rank and select the top eight results. FLAN-T5, GPT-3 Davinci, and other models summarize the papers. It can also generate a summary of high-ranking critiques of the top-ranked paper. Free access is available here.
- Scite queries a proprietary dataset of over 1.2 billion citation statements extracted from scientific papers using the Elasticsearch search engine. Scite re-ranks the top 200 results using a cross-encoder trained on the MS MARCO dataset of Bing queries and answers. A RoBERTa model trained on a question-and-answer dataset extracts relevant text. Basic search is free, but detailed citations require a subscription ($20 monthly, $144 annually).
Yes, but: These tools may struggle with sensitive or fast-moving fields. For example, in response to the question, “Do vaccines cause autism?”, pediatrician Meghan Azad at the University of Manitoba found that Consensus returned a paper that focused on public opinion rather than scientific research. Clémentine Fourrier, who evaluates language models at HuggingFace, said that searching for machine learning papers via Elicit often brought up obsolete results.
Why it matters: Search engines that rank and summarize relevant research can save untold hours for scientists, students, and seekers of knowledge in general. With continued improvement, they stand to accelerate the pace of progress.
We’re thinking: These systems show promise and point in an exciting direction. When search was young, search engines that covered the web (like Google) competed with vertical search engines that covered niches such as retail (Amazon) or travel (Expedia). A similar competition is shaping up between general-purpose chatbots and vertical chatbots.

Don’t Steal My Style
Asked to produce “a landscape by Thomas Kinkade,” a text-to-image generator fine-tuned on the pastoral painter’s work can mimic his style in seconds, often for pennies. A new technique aims to make it harder for algorithms to mimic an artist’s style.
What’s new: Shawn Shan and colleagues at University of Chicago unveiled Glaze, a tool that imperceptibly alters works of art to prevent machine learning models from learning the artist's style from them. You can download it here.
Key insight: Art style depends on many factors (color, shape, form, space, texture, and others). Some styles tend not to blend easily. For instance, a portrait can’t show both the sharp edges of a photograph and the oil-paint strokes of Vincent Van Gogh. Trained models have encountered few, if any, such blends, so they tend not to be able to mimic them accurately. But the ability of text-to-image generators to translate images into a different style (by prompting them with words like “. . . in the style of Van Gough”) makes it possible to alter a photorealistic portrait imperceptibly to make some pixels more like an oil painting (or vice-versa). Fine-tuned on such alterations, a text-to-image generator that’s prompted to imitate them will produce an incoherent blend that differs notably from the original style.
How it works: Glaze makes an artist’s images more similar to images of a very different style. The difference derails image generators while being imperceptible to the human eye.
- Glaze uses embeddings previously generated by Stable Diffusion. That model’s image encoder generated embeddings of works by more than 1,000 celebrated artists. Then it generated an embedding of each artist by computing the centroid of the embeddings of the artist’s works.
- Given works by a new artist, Glaze uses Stable Diffusion to generate an artist embedding in the same way.
- Glaze compares the new artist’s embedding with those of other artists using an undescribed method. It chooses an artist whose embedding is between the most distant 50 percent to 75 percent.
- Glaze uses Stable Diffusion to translate each of the new artist’s works into the chosen artist’s style.
- For each of the new artist’s works, Glaze learns a small perturbation (a learned vector) and uses it to modify the pixels in the original work. In doing so, it minimizes the difference between the embeddings of the perturbed work and style-transferred version. To avoid changing the work too much, it keeps the vector’s magnitude (that is, the perturbation’s cumulative effect) below a certain threshold.
Results: The authors fine-tuned Stable Diffusion on Glaze-modified works by 13 artists of various styles and historical periods. Roughly 1,100 artists evaluated groups of four original and four mimicked works and rated how well Glaze protected an artist’s style (that is, how poorly Stable Diffusion mimicked the artist). 93.3 percent of evaluators found that Glaze successfully protected the style, while 4.6 percent judged that a separate Stable Diffusion fine-tuned on unmodified art was protective.
Yes, but: It’s an open question whether Glaze works regardless of the combination of models used to produce embeddings, perform style transfer, and generate images. The authors’ tests were limited in this regard.
Why it matters: As AI extends its reach into the arts, copyright law doesn’t yet address the use of creative works to train AI systems. Glaze enables artists to have a greater say in how their works can be used — by Stable Diffusion, at least.
We’re thinking: While technology can give artists some measure of protection against stylistic appropriation by AI models, ultimately society at large must resolve questions about what is and isn't fair. Thoughtful regulation would be better than a cat-and-mouse game between artists and developers.
Data Points
Wendy's is testing an AI-powered chatbot for drive-thru orders
The tool will leverage Google's natural-language models in a pilot program set to launch in June at a Wendy's location in Ohio. (The Wall Street Journal)
Hollywood writers on strike demand protection against generative AI
Along with calls for higher pay, the Writers Guild of America is asking studios to commit to regulations that limit the automation of script writing. (Vice)
IBM plans to pause hiring for jobs that could be replaced by AI
Arvind Krishna, the company’s CEO, stated that around 7,800 of its non-customer-facing roles will be either fully or semi-automated in the coming years. (Bloomberg)
Research: Machine learning could help cities meet their emissions goals
Drexel University researchers developed models that predict how zoning changes in Philadelphia could change energy consumption through 2045. (Drexel University)
A U.S. bill would require political admakers to disclose when they use AI-generated content.
The proposed legislation, which came days after the Republican Party released a commercial featuring AI-made visuals, would mandate that ads using AI include a text or audio disclaimer.. (The Washington Post)
AI startup Anthropic developed a chatbot with a built-in moral compass
The company aims to prove that their method of instilling chatbots with pre-defined principles, called “constitutional AI”, is better at steering behavior than reinforcement learning from human feedback (RLHF). (The Verge)
Meta released an open source multimodal model that processes six types of data
Meta said the model, called ImageBind, aims to mimic human learning and paves the way for multisensory content in future AI applications. (The Verge)
Microsoft is testing a ChatGPT alternative to keep data private
Azure cloud will reportedly offer a version of ChatGPT that runs on dedicated servers with protected data storage. (The Information)
The U.S. government is inspecting how companies use AI to monitor workers
The Biden administration released a request for information to gather data on how these tools are used, and what measures can be taken to protect the rights and safety of employees. (Nextgov)
An open source chatbot runs on smartphone hardware
MLC LLM is a project that can run locally on almost any device, including an iPhone or an old PC laptop with integrated graphics. (Tom’s Hardware)