
Dear friends,
AI has an Instagram problem. Just as Instagram’s parade of perfect physiques makes many people feel they don’t measure up, AI’s parade of exciting projects makes many people feel their own projects are lacking. Just as pictures of people’s perfect lives in the media aren’t representative, pictures of AI developers’ postings of their amazing projects also aren’t representative.
I’m here to say: Judge your projects according to your own standard, and don’t let the shiny objects make you doubt the worth of your work!
Over the years, I’ve occasionally felt this way, too, and wondered if I was working on a fruitful direction. A few years ago, when reinforcement learning (RL) made progress on Atari games, Alpha Go was in the headlines, and RL videos using OpenAI Gym circulated on social media, I was still focused on supervised learning. Part of me wondered if I was missing out. It certainly did not help when friends kept asking me about the cool RL work they read about in the news. Fortunately, I ignored the feeling that the grass might be greener on the other side and stuck to what I was excited about.
AI develops so quickly that waves of new ideas keep coming: quantum AI, self-supervised learning, transformers, diffusion models, large language models, and on and on. Some, like quantum AI, have had essentially no impact in applications so far. Others have already had a huge impact. Because our field evolves, it is important to keep learning and ride the waves of change. For the record, I think large language models (LLMs) like ChatGPT (and, to a significant but lesser extent, diffusion models, best known for generating images) will have a transformative impact on AI, but they are far from the only things that will be important.
Someone else’s sculpted physique does not take away from your beauty. And the emergence of a hot new technology doesn’t mean your current project isn’t also valuable, assuming it’s technically sound, has a reasonable expectation of impact, and isn’t made obsolete by newer technology (which doesn’t happen very often). Projects of all shapes and sizes can be wonderful, and what’s buzzy today is only one of the many things that will prove valuable in the future.
I'm not advising you to ignore the news. Paying attention to new developments in AI not only helps you stay on top of the field but also can inspire you. Being inspired by Instagram is fine, but changing your life because of FOMO is less helpful.
So, if what you’re working on makes sense to you, maintain your faith and keep going! Maybe you’re training XGBoost on a structured dataset and wondering if you’re missing out on ChatGPT. You may well be onto something even if XGBoost isn’t in the news.
After all, think about how all the LLM researchers must have felt a few years ago, when everyone was buzzing about RL.
Keep learning!
Andrew
News

Search War!
The long-dormant struggle to dominate the web-search business reignited in a display of AI-driven firepower — and hubris.
What’s new: Google and Microsoft announced competing upgrades powered by the latest generation of chatbots. Baidu, too, flexed its natural-language-processing muscles.
Google’s gambit: Following up on its January “code-red” initiative to counter a rumored threat from Microsoft, Google teased unspecified revisions of Search, Lens, and Maps. Google Search is the undisputed leader, responsible for 93 percent of all search-driven traffic according to StatCounter.
- The upgrades will take advantage of in-house models including the Imagen image generator, LaMDA conversation generator, MusicLM music generator, and PaLM large language model.
- Google showed off output from Bard, a chatbot powered by LaMDA. An astronomer quickly pointed out that the system had misstated the accomplishments of the James Web Space Telescope. The tech press pounced, and Google promptly lost roughly 8 percent of its market value.
Microsoft’s move: Microsoft followed up its announcement by previewing an upcoming version of its Bing search engine enhanced by text generation from OpenAI. The company did not say when the new capabilities would become available. Bing, the longstanding underdog of search, accounts for 3 percent of search-driven traffic.
- Bing as well as Microsoft’s Edge web browser, and Teams conferencing app will take advantage of a chatbot apparently code-named Sydney. The system will respond to conversational queries, summarize answers from multiple web pages, and generate text for emails, essays, advice, and so on. A layer called Prometheus is intended to filter out incorrect or inappropriate results.
- Kevin Liu, a computer science student at Stanford, prompted Sydney to reveal its behind-the-scenes guidelines. They include directions to make responses “informative, visual, logical, and actionable” as well as “positive, interesting, entertaining, and engaging.” They direct the system to avoid answers that are “vague, controversial, or off-topic,” and present them with logic that is “rigorous, intelligent, and defensible.” It must search the web — up to three times per conversational turn — whenever a user seeks information. And so on.
- While Google was caught unwittingly touting AI-generated falsehoods, Microsoft nearly got away with it. Days after the preview, AI researcher Dmitri Brereton detailed several similar mistakes in the new Bing’s output. For instance, when asked to summarize earnings reports, it fabricated numbers. When asked to recommend night spots in Mexico City, it named nonexistent bars.
Baidu’s play: Baidu announced its own chatbot, Wenxin Yiyan, based on ERNIE. The company expects to complete internal testing in March and deploy the system soon afterward. Baidu manages 65 percent of China’s search-driven traffic but less than 1 percent worldwide.
Business hitches: Search engines make money by serving ads that users may view or click. If chatbots provide satisfying information, users may stop there, depriving the search provider of revenue. Microsoft’s Chief Marketing Officer Yusuf Mehdi told Fortune the optimal way to present ads in a chatbot interface remains unknown.
Yes, but: Numerous caveats further dampen the chatbot hype.
- Large language models are notoriously prone to generating falsehoods. Ruochen Zhao, a student of natural language processing at Nanyang Technological University, wrote a detailed analysis of factual errors demonstrated by Google’s and Microsoft’s systems.
- Large language models require much more computation than existing search algorithms. The cost of enhancing Google Search with ChatGPT output would approach $36 billion a year, the hardware newsletter Semianalysis estimates. That’s roughly 65 percent of Google Search’s annual profit.
- Generated text may face stiff regulation in some countries. In January, China began to enforce new restrictions on synthetic media.
Why it matters: Google’s search engine propelled the company to the pinnacle of tech, and it hasn’t faced a serious challenge in nearly two decades. For the competitors, huge money is at stake — Microsoft recently told its shareholders that every additional percentage of market share for Bing translates into $2 billion in revenue. For users, the utility and integrity of the web hangs in the balance.
We’re thinking: The future of search depends on tomorrow’s technology as well as today’s. While current large language models have a problem with factual accuracy, outfitting text generation with document retrieval offers a pathway to significant improvement. It’s also likely that the cost of serving generated text will fall significantly over time. Thus the technology’s potential to disrupt the search business is likely to continue to grow as it matures.
News You Can Misuse
Political forces used a commercial AI service to generate deepfaked propaganda.
What’s new: Videos have appeared on social media that show AI-generated characters speaking against the United States or in favor of foreign governments, The New York Times reported. The clips feature synthetic avatars offered by the United Kingdom startup Synthesia.
Found footage: Researchers at Graphika, which tracks disinformation, discovered deepfaked videos posted on YouTube by accounts tied to a disinformation network.
- Two videos show fake news anchors who deliver commentary. One accuses the U.S. government of failing to address gun violence in the country, and another promotes cooperation and closer ties between the U.S. and China. Both clips bear the logo of a fictional media outlet, Wolf News. Neither garnered more than several hundred views.
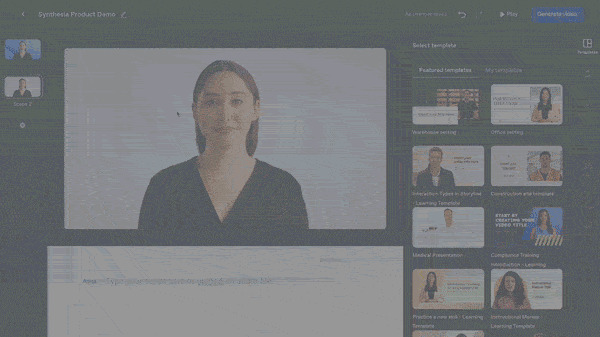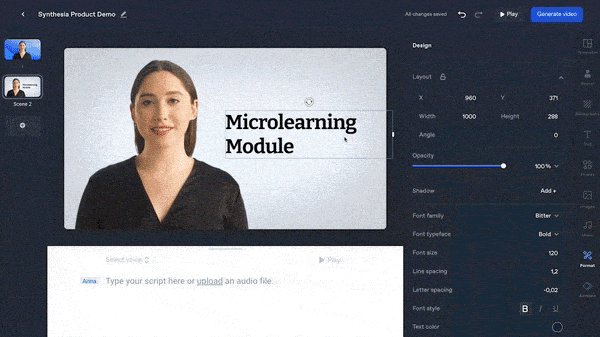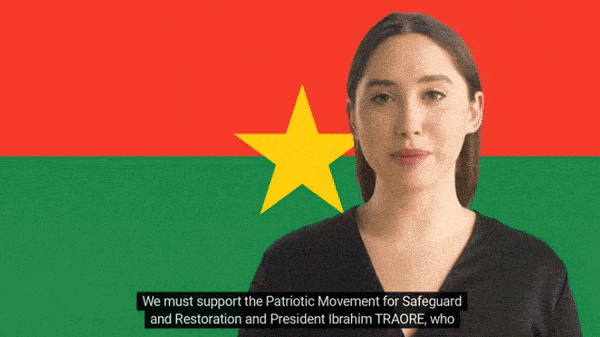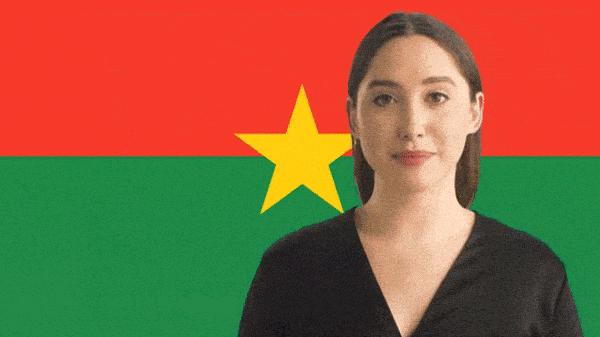
- In January, a U.S. specialist in African geopolitics found videos in which synthetic characters who claim to be U.S. citizens voice support for Burkina Faso's military leader Ibrahim Traoré, who seized power in a coup last year.
Deepfake platform: Synthesia’s website provides 85 avatars, each based on a human actor, which customers can pose and script in any of 120 languages or accents. The company’s terms of service bar users from deploying its avatars for “political, sexual, personal, criminal and discriminatory content.” It employs a team of four to monitor violations of its terms and suspended Wolf News’ account after being alerted to the videos.
Fakery ascendent: The recent clips may represent an escalation beyond earlier incidents, which appear to have been one-offs that required custom development.
- Shortly after the Russian invasion of Ukraine in early 2022, hackers posted a deepfaked video of Ukrainian president Volodymr Zelenskyy encouraging Ukrainian forces to surrender.
- Both leading candidates in the 2022 South Korean presidential election deployed AI-generated likenesses of themselves answering questions from the public.
- In 2019, a deepfaked video in which a Malaysian politician appeared to admit to a sex act fueled a scandal.
Why it matters: Experts have long feared that AI would enable a golden age of propaganda. Point-and-click deepfakery gives bad actors an unprecedented opportunity to launch deceptive media campaigns without hiring actors or engineers.
We’re thinking: Researchers at Georgetown University, Stanford, and OpenAI recently described several measures — including government restrictions, developer guidelines, and social media rules — to counter digital propaganda. The simplest may be to educate the public to recognize underhanded efforts to persuade.
A MESSAGE FROM DEEPLEARNING.AI

Want to build projects using recent AI innovations including generative AI models like ChatGPT and its lesser-known sibling, InstructGPT? Join us on Thursday, February 23, 2023, at 10:00 A.M. Pacific Time for Practical Data Science on AWS: Generative AI. Register today

Seinfeld’s Twitch Moment
AI hobbyists created an homage to their favorite TV show . . . until it got knocked off the server.
What’s the deal: The creators of Nothing, Forever launched a fully automated, never-ending emulation of the popular TV show Seinfeld. The streaming-video service Twitch banned it after its generated dialog was found to violate the terms of service, the entertainment news outlet The AV Club reported.
We need to talk: A collective called Mismatch Media created Nothing, Forever — an experience ostensibly about nothing that would last forever — using a combination of AI models and cloud services.
- The authors prompted OpenAI’s Davinci variation on GPT-3 to generate a stream of dialog. Davinci experienced outages, so the creators switched to Curie, a smaller GPT-3 variant.
- Microsoft Azure’s text-to-speech system read the script in a different voice for each of the four characters.
- The Unity video game engine generated the animation. Unspecified models drove camera motion and other scene direction.
No soup for you: Nothing, Forever launched on December 14, 2022, and by February it had gained tens of thousands of concurrent viewers. On February 6, Twitch suspended it for at least 14 days after one of the characters told hateful jokes. Co-creator Skyler Hartle blamed the off-color remarks on his team’s decision to switch from Davinci to Curie, which has looser built-in moderation controls.
Why it matters: AI assistance can unlock new approaches to storytelling, but it also makes creators vulnerable to technical issues beyond their control. In this case, a malfunction on OpenAI’s side was enough to topple a successful project.
We’re thinking: Generated content was taking a growing share of human attention even before the recent explosion of generative AI — consider text-to-speech models that read posts on Reddit. Get ready for much, much, much more.

Unsupervised Data Pruning
Large datasets often contain overly similar examples that consume training cycles without contributing to learning. A new paper identifies similar training examples, even if they’re not labeled.
What’s new: Ben Sorscher, Robert Geirhos, and collaborators at Stanford University, University of Tübingen, and Meta proposed an unsupervised method for pruning training data without compromising model performance.
Key insight: A subset of a training dataset that can train a model to perform on par with training on the full corpus is known as a coreset. Previous approaches to selecting a coreset require labeled data. Such methods often train many classification models, study their output, and identify examples that are similar based on how many of the models classified them correctly. Clustering offers an unsupervised alternative that enables a pretrained model to find similar examples in unlabeled data without fine-tuning.
How it works: The authors trained and tested separate ResNets on various pruned versions of datasets both large (ImageNet, 1.2 million examples) and small (CIFAR-10, 60,000 examples). They processed the datasets as follows:
- A self-supervised, pretrained SWaV produced a representation of each example.
- K-means clustering grouped the representations.
- The authors considered an example to be more similar to others (and thus easier to classify correctly) if it was closer to a cluster’s center, and less similar (harder to classify and thus more valuable to training) if it was further away.
- They pruned a percentage of more-similar examples, a percentage of less-similar examples, or a random selection.
Results: Tests confirmed the authors’ theory that the optimal pruning strategy depends on dataset size. Pruning CIFAR-10, a ResNet performed better when the authors removed a portion of the most-similar examples than when they removed least-similar examples, up to 70 percent of the entire dataset. In contrast, starting with 10,000 random CIFAR-10 examples, the model achieved better performance when the authors removed any portion of least-similar examples than when they removed the same portion of most-similar examples. On ImageNet, their approach performed close to a state-of-the-art method called memorization, which requires labels. For instance, a ResNet trained on a subset of ImageNet that was missing the most-similar 30 percent of examples achieved 89.4 percent Top-5 accuracy, while using memorization to remove the same percentage of examples yielded nearly the same result. A ResNet trained on a subset of ImageNet that was missing the most-similar 20 percent of examples achieved 90.8 Top-5 accuracy, equal to a ResNet trained on ImageNet pruned to the same degree via memorization and a ResNet trained on ImageNet without pruning.
Why it matters: The authors’ method can cut processing costs during training. If you eliminate examples before hiring people to label the data, it can save labor costs as well.
We’re thinking: By identifying overrepresented portions of the data distribution, data pruning methods like this can also help identify biases during training.
Data Points
Spotify founder announced an AI-powered body scanner focused on preventive health
Neko Health, the new healthtech Swedish company co-founded by Daniel Ek, plans to offer non-invasive full-body scans that use AI to analyze data points on skin, heart function, and more. (The Verge)
Actors are being asked to give up rights to their voices so AI can clone them
The voice acting community is opposing new contractual obligations as AI-generated voice services increase. (Vice)
Italy imposed a ban on Replika, an AI chatbot that promotes “virtual friendship” services
Due to concerns regarding the safety of children’s information, the The Italian Data Protection Authority ordered Replika to stop processing Italians’ data. (TechCrunch)
Anima, the company behind Onlybots digital pets, announced AI-based features
Onlybots will be able to talk to their owners (thanks to technology from OpenAI) and develop evolving personalities. (VentureBeat)
ChatGPT fever is leading cryptocurrency enthusiasts to embrace AI tokens
Many tokens listed on CoinGecko in the AI category have seen price increases up to 138% in the past few weeks. (The Malaysian Reserve)
AI-based CAD software may be able to better detect lung nodules in chest x-rays, study shows.
Research: A study performed in clinical settings found that computer-aided design (CAD) software that uses AI can significantly improve the detection of lung nodules without increasing the false referral rate. (News Medical)
Runway launched a text-to-video AI modelThe generative-AI startup’s latest model, called Gen-1, takes existing videos and produces new ones based on text prompts or images. (MIT Technology Review)
Developers used AI to generate photorealistic police sketches
Two engineers developed a hackathon project called Forensic Sketch AI-rtisthe to produce sketches of crime suspects that look like photographs. Experts warn that it could exacerbate gender and race biases that exist in police forensics. (Vice)